一种基于词级权重的Transformer模型改进方法
2019-05-05王明申
王明申,牛 斌,马 利
(辽宁大学 信息学院,沈阳 110036)
1 引 言
神经机器翻译(NMT)在大规模翻译任务中取得了良好的结果[1,2].NMT的优势在于它仅需少量的领域知识,并且其模型结构易于理解.在语言建模和机器翻译领域,通常运用长短时记忆单元(LSTM)[3]或者门控循环单元(GRU)[4]构建循环模型[5-7],研究人员一直致力于推动循环模型和编码器-解码器体系结构的优化与完善[8-10].
循环模型通过将前一个的隐藏状态ht-1以及输入和输出序列的位置信息t作为输入,在训练过程中将位置与训练步数对齐,生成一系列隐藏状态ht.这种固定的顺序计算限制了训练的并行化,当序列变得更长时,训练模型会耗费更多的时间,同时长序列会给内存带来存储压力,进一步降低训练速度,甚至会造成不可预期的错误.通过LSTM矩阵分解/分块技术[11]和条件计算[12]等方式,使得循环模型在计算效率上取得了重大进展,但是,循环模型顺序计算所带来的训练并行化约束问题依然存在.
注意力机制已成为序列化模型和转导模型不可分割的一部分,注意力机制在建立模型的依赖关系时忽略了输入或输出序列中的距离影响,消除了输入序列长度的限制.
针对上述问题,Google Brain提出了一种用于NMT的简单的Transformer模型,该模型未使用循环模型结构,而完全依赖注意力机制来建立输入和输出之间的全局依赖关系.Transformer模型允许并行化操作,并且可以在8个P100 GPU上通过仅仅12小时的训练即可达到翻译任务的最佳结果[13].
Akiko Aizawa[14]提出词频-逆文档频率(TF-IDF)算法是信息检索中最重要的发明.该算法在搜索、文献分类和其他相关领域有着广泛的应用.TF-IDF算法的基本思想是在文本分类任务中,若通过一个单词预测文本所属分类的正确率越高,该词的权重就越大,反之,权重就越小.该算法说明文本的类别信息隐藏于每个单词之中,且每个单词之间所携带类别信息量会有所不同,必须通过训练找出携带信息量最多的单词,并加大其在文本中的权重,使之能够代表该文本的类别.Shuang Li[15]等人通过研究提出了在语句中不同词性的单词所携带的信息量会有所不同,名词所携带的信息量最多,形容词的信息量次之,而动词所携带的信息量最少.
综上所述,语句中不同单词的重要程度不同,增加重要单词的权重,可以在文本分类等任务中起到关键作用.本文在此基础上提出了词级权重模型方法,并将此方法与Transformer模型相结合得到更加准确的机器翻译模型.
2 自注意力与词的权重
自注意力(self-attention),也被称为内部注意力(intra-attention),是一种注意力机制,它是在序列内部运用注意力机制来寻找序列内部的关联.Ashish Vaswani等人[13]说明了内部注意力对于机器翻译中的序列编码过程是相当重要的,特别是在Seq2Seq模型[5]中的重要性尤为明显,而之前关于Seq2Seq的研究基本只是把注意力机制用在解码器端.自注意力成功用于各种任务,包括阅读理解,自动文摘,文本蕴含任务等[16-18].
Transformer是第一个完全依靠自注意力来计算其输入和输出表示,而不使用循环神经网络或者卷积神经网络.
表1 掩盖不同词性单词的搜索准确率表[15]
Table 1 Search accuracy of the original sentences,and sentences with nouns,or adjectives,or verbs masked out

Orig.sent.w/o nounsw/o adjsw/o verbsTop-10.590.380.440.57Top-50.920.810.850.92Time(min)1.141.010.981.12
Shuang Li[15]等人在用自然语言进行图像中人物搜索时做了研究,用来调查语句中不同词性的重要性,包括名词、动词和形容词.对于这项研究,句子中的名词、形容词和动词分别被掩盖.例如,“粉红色头发的女孩”被转换为“***粉红色的***”,名词被掩盖.表1中的结果表明,在语句中名词最重要,包含大部分的信息,而动词最少.在设计神经网络模型和收集语言数据时,应该更加重视名词和形容词.
3 模型结构
一般的NMT模型都具有编码器-解码器结构[5-7].编码器将每个句子对应的矩阵 (x1,…,xn)作为输入序列映射到序列z=(z1,…,zn),即序列编码.给定z,将其中元素依次作为解码器的输入,然后生成输出序列(y1,…,ym).在每一步中,模型都是自循环的,当生成下一个输出时,会将前一个输出作为附加的输入.
本文所提出的词级权重生成器堆栈如图1中左侧分支所示,该堆栈将词向量作为输入,输出不同词的权重,将此权重与Transformer模型的输出进行点积,再经过softmax得到最终的结果.图1中间分支为Transformer模型的编码器堆栈,右侧分支为解码器堆栈.
3.1 编码器和解码器堆栈
编码器由N = 8(为了方便后续计算)相同层堆叠而成.每一编码器层都由两个子层组成,第一个是Multi-Head自注意力模型,第二个是简单的全连接前馈神经网络.在两个子层中每一子层都采用一个残差连接[19],接着进行规范化操作.每个子层的输出是LayerNorm(x+Sublayer(x)),Sublayer(x)是子层本身的输出.
解码器也由N = 8相同层堆叠而成.除了与编码器相同的两个子层之外,解码器还添加了第三个子层,该层是用于对编码器堆栈的输出执行Multi-Head注意力.与编码器类似,对于解码器的每个子层也采用残差连接,然后进行归一化操作.
3.2 词级权重生成器堆栈
由Transformer的Multi-Head注意力模型受到启发,本文提出了词级权重生成器堆栈,如图2所示.

图1 具有词级权重的Transformer模型图Fig.1 Transformer model with word-level weights
根据对不同单词类型在语句中重要性的讨论,不同的单词,特别是不同词性的单词所携带的信息量具有显著的不同.由于在每个单词上,Transformer模型所生成的注意力总是和为1,因此不能反映不同词之间的差异.本文提出在每个单词上学习词级权重这一方法,以加权对应源语句中单词和目标语句中单词之间的相近度(即Transformer模型最终输出的概率结果).

图2 词级权重生成器堆栈图Fig.2 Word-level weights generator stacks
本模型将经过词嵌入(word embedding)所得的词向量作为输入,每批词向量的维度为(b,s,v),分别代表批大小(batch size)、句子长度(sentence length)、向量长度(vector length),然后经过一层线性层,该层称为“Word-fc”,激活函数选择ReLU,词向量的维度保持不变;接着将词向量复制变换为h个向量,每个向量的维度为(b×h,s,v/h),再经过两层词级权重堆栈,进行特征提取,为防止过拟合,每层都进行dropout操作,第一层堆栈称为“Weights-L1”,激活函数为tanh,输出向量的维度为(b×h,s,W1),第二层堆栈称为“Weights-L2”,激活函数为softmax,输出向量的维度为(b×h,s,W2);最后将h个向量进行重新拼接(concat)与变换,向量的维度为(b,s,v),将向量经过最后一层的线性层,维度为(b,s,1),最后进行归一化操作后输出,获得词级权重.将所得到的词级权重与Transformer模型的最终输出进行点积,再通过softmax函数求得概率,求得最终源语句单词和目标语句单词的相近度.
3.3 注意力机制
注意力机制可以描述为一个查询(query)到一系列键值对(key-value)的映射.如图3所示,可以将Source中的构成元素想象成是由一系列的key-value数据对构成.
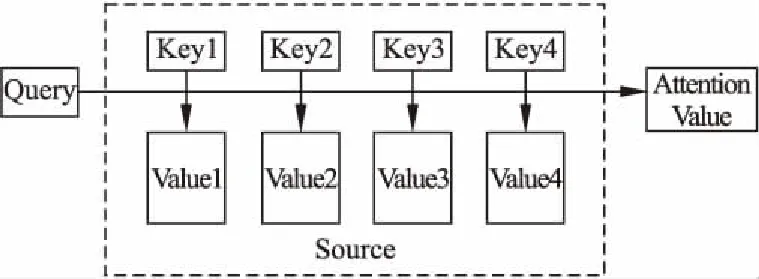
图3 注意力机制图Fig.3 Attention mechanism
计算注意力主要分为三步,第一步,将query和每个key进行相似度计算得到权重,常用的相似度函数有点积(dot-product)、拼接(concat)、感知机(perceptron)等;第二步,一般是使用softmax函数对第一步得到的权重进行归一化;第三步,将权重和相应的键值进行加权求和得到最终的注意力值.目前,在自然语言处理(NLP)研究中,key和value通常是同一个值,即key = value.上述过程如公式(1):
(1)
其中,Lx=‖Source‖,代表Source的长度.
3.3.1 缩放点积注意力模型
缩放点积注意力模型是Multi-Head注意力模型的核心,如图4(a)图所示,该模型的输入由维数为dk的query和key,以及维数为dv的value组成.该模型的输出为:
(2)
其中Q∈Rn×dk,K∈Rm×dk,V∈Rm×dv,如果忽略激活函数softmax函数,则为三个维度n×dk,m×dk,m×dv的矩阵相乘,最后的输出结果为一个维度为n×dv的矩阵.
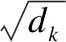
该模型可以作为一个Attention层,该层将维度为n×dk的序列Q编码成维度为n×dv的序列,对Q中的每一个子向量进行分析,根据公式(2)得到公式(3):

(3)
其中,z是归一化因子,ks和vs同样为K,V中的子向量,公式(3)是通过qt这个query与各个ks进行内积的,并经过softmax函数,得到qt与各个vs的相似度,然后加权求和,得到一个dv维的向量.

图4 Transformer中的注意力模型图Fig.4 Attention model in Transformer
3.3.2 Multi-Head注意力模型
Multi-Head注意力模型是Google提出的新模型,是注意力机制的完善,如图4(b)图所示.该模型将Q,K,V通过投影矩阵进行映射,然后再做Attention运算,把这个过程重复h次,最后将结果进行拼接.具体如公式(4)所示:
(4)
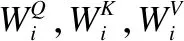
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(5)
其中WO∈Rhdv×dmodel,最后得到一个维度为n×(hdv)的序列,即为所求注意力.
在哈佛管理导师课程中,我意识到自己遇到沟通难题时在如何处理、如何说服他人并赢得认同以及如何在需要展示自己的成果时做有效的演讲等方面犯了很多低级的错误,现一一剖析如下:
3.3.3 模型中的自注意力
自注意力(self-attention)如上文所述,即在序列内部做Attention计算,寻找序列内部的联系.Google所用的是Self Multi-Head Attention,公式如下:
Attention=MultiHead(Q,Q,Q)
(6)
3.4 位置编码
上述的模型并不能捕捉序列的位置信息,举例来说,如果将K,V按行打乱顺序,即打乱句子中的词序,那么通过上述模型计算出的注意力结果是相同的,该结果与实际不符,这需要对序列的位置信息进行编码,并加入到词向量中.
在位置编码中,通常都是任务训练所得到的向量[6,9,20]作为位置向量,而Google直接构造出用于求解位置向量的公式:
PE(pos,2i)=sin(pos/100002i/dmodel)
(7)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
(8)
其中,pos表示位置,i代表维度.上述公式将位置pos映射为一个dmodel维的位置向量,这个向量的第i个元素的数值为上式中对应的值.由于三角函数具有如下的性质:
sin(α+β)=sinαcosβ+cosαsinβ
(9)
cos(α+β)=cosαcosβ-sinαsinβ
(10)
则位置pos+k的向量可以表示为位置pos向量的线性变换,这提供了表示相对位置信息的可能性.最后,将所求得的位置向量与词向量进行矩阵加和,得到具有位置信息的词向量.
4 模型训练
4.1 训练数据和训练批次
本文将运用标准的IWSLT16英语-德语平行语料库作为训练数据,其中包含了约21万个句子对.句子使用单词的词频进行编码,总共约有14万个不同的单词编码.句子对按照近似的序列长度一起进行批处理,每个训练的批次包含一组句子对,其中包含大约82000个源编码和82000个目标编码.
4.2 硬件环境和训练时间
本文使用一台搭载4块GTX 1080(每块GPU的显存为8G)和2片至强四核E3 CPU的机器上进行模型训练,每个训练步骤花费大约0.08秒,总共训练了34060步,训练用时为46分钟.
4.3 模型优化方法
本次训练使用Adam优化器[21]进行模型参数优化,优化器各参数设置为:β1=0.9,β2=0.98,ε=10-8.训练过程中学习率固定为0.0001,因为本次训练的数据集较小,这样,训练速度能够足够快.同时,本次训练为防止过拟合,采用了Dropout,概率为0.1.
5 训练结果
5.1 词级权重生成器网络层的最佳选择
为了评估词级权重生成器中各网络层输出维度和网络层类型对训练结果的影响,本次训练以不同的方式改变模型,并在IWSLT16.TEDX.tst2014数据集上做测试,计算BLEU得分.结果如表2所示(未填写的与best一行相同,None代表未添加这一层).
表2 改变网络层类型或输出维度的BLEU得分比较表
Table 2 Comparison of BLEU scores to change the network layer type or output dimension
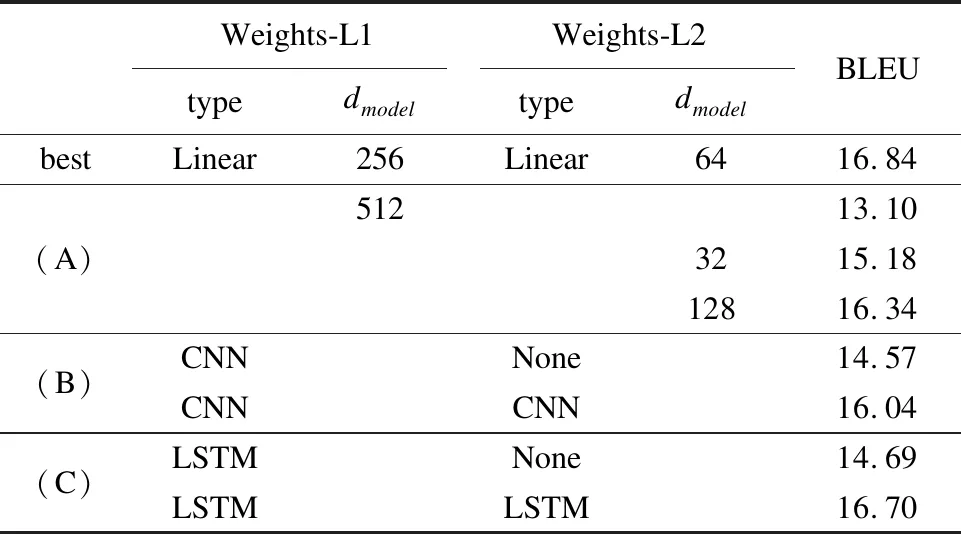
Weights-L1Weights-L2typedmodeltypedmodelBLEUbestLinear256Linear6416.84(A)51213.103215.1812816.34(B)CNNNone14.57CNNCNN16.04(C)LSTMNone14.69LSTMLSTM16.70
在表2的(A)行中,改变了网络层的输出维度,保持网络层的类型不变.从结果中可以看出,两个网络层的输出维度分别为256和64,BLEU得分最高.
在表2的(B)行中,尝试用CNN代替线性网络层,第一次只使用一个卷积层,效果不理想,第二次使用两层卷积,虽然BLEU得分也达到了16分以上,但是还是不及最佳结果,同时也增加了训练耗时;在(C)行中,同样改变了网络层的类型,步骤与CNN相同,虽然用两层LSTM的BLEU得分为16.70,与最佳结果不相上下,但是训练所需的时间要比CNN还要长.
综上所述,将词级权重生成器堆栈中网络层输出的维度设置过低或者过高都会降低整个模型的准确率.同时,改变网络层类型不仅会降低准确率,更主要的是大大增加了训练用时,因此,词级权重生成器的网络层应如表2中best行设置最为合适.
5.2 模型比较
本节将通过训练的准确率、训练的平均损失,以及BLEU得分三个方面将改进后Transformer模型与原始的Transformer模型进行对比(以下曲线图皆用TensorBoard绘制).
从图5可以看出,未改进的模型在训练过程中,准确率的变化波动较大,而改进后,即增加词级权重后,准确率变化更加平稳.虽然,图5(a)中准确率最高可达到0.9,但是由于准确率波动较大,说明未改进的模型没有改进后的模型稳定.如图6所示(由于横坐标尺度变大,以至于曲线没有图5(b)图平滑),增加改进后模型的训练步数,可以看到准确率最高可达0.95.
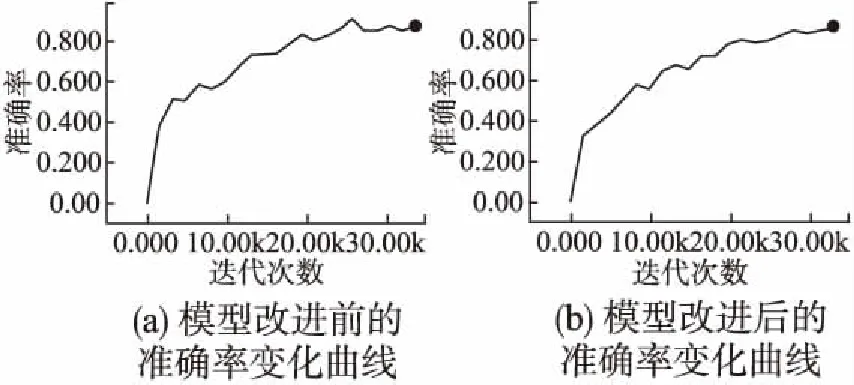
图5 模型改进前后准确率变化曲线对比图Fig.5 Comparison of the accuracy curvers
通过训练的平均损失进行模型比较,如图7所示.
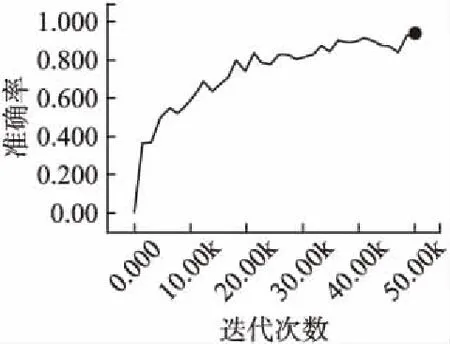
图6 增加改进后模型的训练步数得到的准确率变化曲线图Fig.6 Accuracy curve of the improved Transformer model after increasing the training steps
与准确率曲线的情况相似,改进前的模型在训练过程中,平均损失曲线变化波动较大,改进后的模型平均损失曲线平稳,同时,两者的平均损失皆趋近于2.00,可以看出,改进后的模型更加稳定.
最后,将两个经过训练的模型经由IWSLT16.TEDX.tst2014数据集进行测试,并计算BLEU得分.改进前模型的BLEU得分为15.30,而改进后的模型如表2中所示,BLEU得分为16.84.
综上所述,改进后模型的训练准确率和平均损失变化曲线更加平稳,BLEU得分更高.因此,通过增加词级权重改进模型的方法不仅可以使Transformer模型更加稳定,而且提高了模型的准确率.
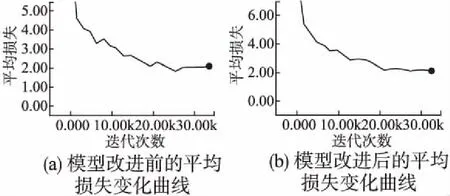
图7 模型改进前后的平均损失变化曲线对比图Fig.7 Comparison of the mean loss curves
6 总 结
本文通过运用Akiko Aizawa[14]和Shuang Li[15]等人的结论,并结合Google的Multi-Head注意力机制,提出了词级权重生成器堆栈模型,并将该模型与Google Brain提出的Transformer模型进行结合,不仅提高了原始模型的稳定性,同时也使得原始模型在翻译任务中更加准确.
本文的不足之处在于,因训练成本,以及时间所限,未能够在诸如WMT2016等大型数据集上进行模型测试,所以,接下来的工作是通过在大型数据集上进行训练测试,不断对模型进行改进.同时,计划将词级权重模型应用到其他翻译模型,以及自然语言处理模型,对实际结果进行评估,并根据结果对模型进行完善.
