集成学习在短文本分类中的应用研究
2019-04-28王国薇黄浩周刚胡英
王国薇 黄浩 周刚 胡英
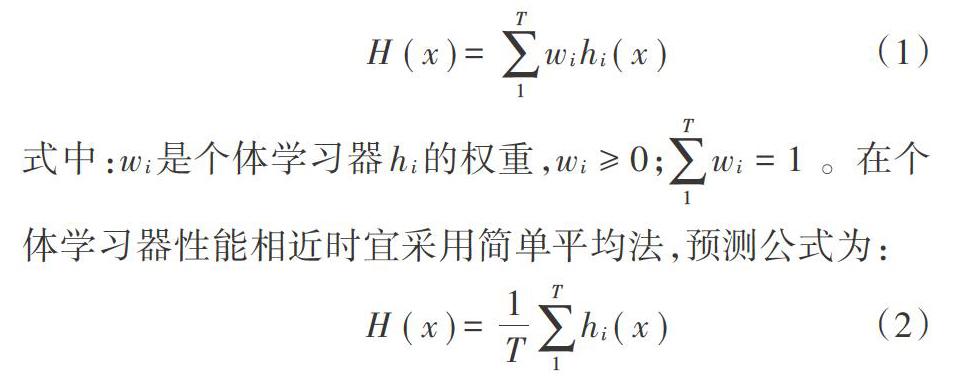
摘要:为了进一步提高基于深度神经网络短文本分类性能,提出将集成学习方法应用于5种不同的神经网络文本分类器,即卷积神经网络、双向长短时记忆网络、卷积循环神经网络、循环卷积神经网络、分层注意力机制神经网络,分别对两种集成学习方法( Bagging,Stacking)进行了测试。实验结果表明:将多个神经网络短文本分类器进行集成的分类性能要优于单一文本分类模型:进一步两两集成的实验验证了单个模型对短文本分类性能的贡献率。
关键词:短文本分类;机器学习;深度学习;集成学习;Bagging;Stacking
中图分类号:TN911.1-34;TP391
文献标识码:A
文章编号:1004-373X( 2019)24-0140-06
0 引言
近年来随着网络技术的快速发展,网络用户的数量呈现出爆发式的增长。越来越多的网络用户喜欢在新浪微博、今日头条等社交平台上发表短文本形式的言论。这些短文本包含天气、政治、经济、文化、对电影的评价等,对这些短文本进行分类从而提取出有用的信息,更好地为网络用户服务成为了关键。文本分类是用计算机对文本集(其他实体或物件)按照一定的分类体系或标准进行自动分类标记。短文本由于受字数的限制,有效信息少、特征难提取等因素与长文本分类相比难度更大。
传统的机器学习文本分类方法主要包括潜在狄利克雷分布( Latent Dirichlet Allocation.LDA)[1]、K-最近邻法(K - Nearest Neighbor,KNN)[2]、支持向量机(SupportVector Machine,SVM)[3]等。这些方法目前较为成熟,但分类效果严重依赖于所构建特征的质量和模型参数的调优,整个过程非常耗时[4]。随着神经网络在图像识别和语音识别领域取得的巨大成功,越来越多的学者把神经网络的方法应用到自然语言处理领域。文献[5]将卷积神经网络应用在句子分类上。文献[6]将循环神经网络与卷积神经网络结合应用在文本分类上。文献[7]将分层注意力机制应用在文本分类上。文献[8]将字符级的卷积神经网络用于文本分类上。在单一模型的短文本分类上,上述几种方法由于模型复杂度高,研究较为成熟,已经取得了不错的成果,但效果提升空间有限。本文提出采用结合多种最优短文本分类模型的集成学习方法来提高短文本分类的效果。集成学习[9]是将多个分类器进行组合从而获得更优性能的机器学习方法。目前广为通用的集成方法包括文献[10]提出基于Bag-glng的概率神经网络集成分类算法,该方法比传统的BP神经网络和决策树分类方法效果更好;文献[11]提出的随机森林(Random Forest,RF)算法,综合利用多个决策树进行分类;文献[12]提出基于Stacking的组合分类方法,组合了朴素贝叶斯、最大熵、支持向量机和随机梯度下降线性分类方法对中文情感分类进行研究,实验结果表明该方法能获得比基分类器结果更佳的分类效果。
上述实验表明集成学习可以通过集成多个模型来提升任务指标。文献[9]曾指出集成方法比单个学习器效果显著的三个主要原因:一是学习任务的假设空间一般很大,使用单个学习器通常不能学习到足够的信息;二是弱学习器的学习过程可能存在缺陷;三是单个学习器学习到的假设空间可能并不真实,而通过结合多个学习器可以尽可能学习到真实的假设空间。
在集成学习方法中,为保证组合分类器取得比单个分类器更好的分类效果[13],在构造过程中需要遵循两个原则:一是组合分类器中的各个基分类器产生的错误是不相关的;二是各个基分类器的分类效果至少要比随机预测的效果好。因此本文采用当下较为流行的几种短文本分类方法作为基分类器,即卷积神经网络( Convolu-tional Neural Networks,CNN)、双向长短时记忆网络(Bi-directional Long Short Term Memory Networks. Bi -LSTM)、卷积循环神经网络(Convolutional - Long ShortTerm Memory Networks,C-LSTM)、循环卷积神经网络( Recurrent - Convolutional Neural Networks)、分层注意力机制神经网络( Hierarchical Attention Networks,HAN)。这5种方法有着各自擅长的领域,它们在处理同一文本集时所产生的预测效果具有相对独立的特性,满足了错误不相关且优于随机預测原则。因此本文将集成学习应用于这5种不同神经网络文本分类模型。
1 基分类器短文本分类方法
1.1 卷积神经网络
文献[5]提出用CNN进行短文本分类,CNN可以很好地提取出文本的局部特征。CNN由输入层、卷积层、池化层和输出层构成,通过反向传播算法进行参数优化。相邻两层之间只有部分节点相连。相比于全连接神经网络的参数,它的参数大大减少,便于模型的训练。
1.2 双向长短时记忆网络
文献[14]提出用Bi-LSTM进行文本分类,即当前的状态不仅仅与之前的句子有关系,还可能与之后的句子有关系。Bi-LSTM就是同时采用两个LSTM沿着序列的两个方向进行扫描,用来捕获文档所包含的所有重要信息。
1.3 循环卷积神经网络
文献[6]提出用循环卷积网络的方法进行文本分类。使用该模型进行文本分类时首先利用双向循环网络对所有词进行上下文向量表示,然后将上下文向量及当前词的词向量组合成当前词的表示,最后利用最大池技术提取重要的上下文信息得到文本表示,利用文本表示进行文本分类。
循环卷积神经网络能够较多地保留文本的词序信息[15],捕获长距离的文本依赖关系,精确刻画词的语义。
1.4 卷积循环神经网络
结合卷积神经网络和循环神经网络的优点,文献[16]提出用C-LSTM模型进行文本分类。C-LSTM利用CNN提取出短语的特征,再送入到LSTM网络获取句子的特征。
卷积循环神经网络既能获取短语、句子的局部特征也能获取全文中的时态句子语义。
1.5 分层注意力机制
文献[7]提出用注意力机制模型进行文本分类。注意力机制( Attention Mechanisms)是自然语言处理领域一种常用的建模长时间记忆机制,能够直观地给出每个词对结果的贡献。Attention的实现是通过保留GRU编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。
2 集成学习方法
集成学习(Ensemble Leaming)也被称为多分类器系统( Multi-classifier System)[17]。其主要思想是先通过一定的规则生成多个基学习器,再采用某种集成策略进行组合,最后综合判断输出结果。
基学习器一般有两种选择:第一种称为同质学习器( Homogeneous),即所有的学习器都是一个种类的;第二种称为异质学习器( Heterogeneous),即所有的学习器不全是一个种类。常见的结合策略有平均法、投票法、学习法。本文使用常见的Bagging和Stacking两种流行的集成学习方法。
2.1 基于Bagging的集成学习方法
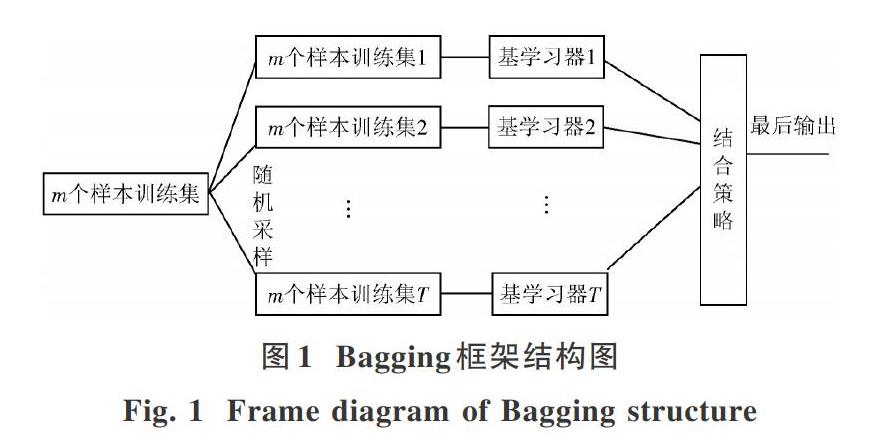
Bagging集成学习方法是Bootstrap Aggregating的缩写。1996年,Breima提出Bagging方法[9]。Bagging方法框架结构图如图1所示。
对于给定的包含m个样本训练集,采用有放回的随机抽取,抽取出T个含有m个样本的训练集,初始训练集中样本在整个迭代过程中可能出现多次,也可能不出现,每轮迭代用于训练的样本之间互相独立。然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。一般而言,在基学习器性能相差较大时宜采用加权平均法,如果每个个体学习器有一个权值w,则最终预测为:
实验中基学习器分别为:CNN,RNN,CRNN,RCNN,HAN。由于这几种基分类器性能相近,故本文选用平均法作为结合策略。
2.2 基于Stacking的组合分类方法
基于Stacking的组合分类器方法是目前比较主流的组合分类方法[18]。Wolpert最早提出了Stacking思想,介绍了Stacking是一种估计和修正偏差的工具,可以用来减少模型的泛化误差[19]。其后Beriman使用交叉验证,大大提高了训练的效率[9]。Stacking框架结构图如图2所示。
Stacking方法由样本训练集m利用Ⅳ种算法L1、L2…,LN处理所得。样本训练集m包含实例集m i=(xi,yi),其中,xi为特征向量矩阵,yi为其所对应的标签。在第一阶段,基学习器C1,C2。…,CN由各个分类算法训练产生,即Ci=Li(m)。在下一阶段则将基学习器预测的结果拼接起来作为元特征,输入一个新的分类算法再次学习出一个分类器,该分类器即为元分类器。实验中选用N=5,基学习器分别为:CNN,RNN,CRNN,RCNN,HAN,元分类器为Logistic Regression。
在训练时,使用k -fold交叉验证法产生元分类器的训练集,即将训练实例分成大小相等的k份,其中一份用作验证集合,其余k一1份用作对Ⅳ个分类器的训练集合。本文中k=5,即5-flod交叉验证法进行训练。
3 实验分析与比较
3.1 实验数据及评价指标
为了验证本文方法的有效性,实验数据为Kaggle中Machine Learning Homework 4- Text Sentiment Classifi-cation的20万条训练数据用于消极和积极两种情感分类,每条句子进行了消极/积极情感标注。训练集,验证集和测试集按照8:1:1的比例划分。为了验证实验结果的泛化性,又采用文献[5]提供的电影评论MR数据集进行测试。MR数据集有10 662条句子,为用户对该电影积极和消极的评论两类。
实验中,使用准确率( Precision)作为评价标准。定义如下:
Ac=分类正确的文本数/总的文本数 ×100%
(3)
3.2 词嵌入向量的生成
首先对数据进行预处理,对全英文單词中字母重复的最大次数超过2次的进行清除,然后使用word2vec工具生成用于训练词向量的语料库。对短文本进行词向量的训练,每个单词Wi。用训练好的词向量表示,如下:
Wi=(w1,w2,…,wk)
(4)式中:k表示通过word2vec训练后形成词向量的维度;w1表示词向量中第i维度上的权重。句子S可以用单词级联进行表示:
式中:“0”为级联操作符;Ⅳ表示该句子中单词的个数。同理文本把相应的句子串联在一起如下:
式中,m表示文本T中句子的个数。
由此可得句子的矩阵表示,该矩阵将作为各个模型的输人数据。实验中词向量的维度设为200。
3.3 损失函数
文本使用最大熵损失函数,损失函数为:式中:N为训练样本数;c为数据集包含的类别数;pi为第i个类别的概率。这里使用时序后向传播(Back Prop-agation Through Time,BPTT)来对网络进行训练。
3.4 模型方法与环境配置
本文的实验环境:操作系统Ubuntu 16.04,内存128 GB,CPU为两颗Xeon2630V4,GPU为GTX1080TI。深度学习开发环境为Python 3.6.4+Tensorflow l.5.0。
训练中的所有权重随机初始化为标准差为0.1的正态分布随机数,偏置项初始化为0.1。在实验中,采用Momentum优化方法来训练模型,丢弃率为0.3,学习率为0.1,学习率衰减系数为0.9,最小学习率为0.005,早停止(Early Stop)为30,词向量维度为200,批训练样本数为128。各模型中的参数如表1所示。Bagging集成方法如第3.1节中介绍。Stacking集成方法如第3.2节中介绍。
3.5 实验结果与分析
3.5.1 词嵌入方式
本文主要目的在于进一步提高基于深度神经网络短文本分类的性能。文献[5]中CNN模型数据有四种不同方式的词向量输入:
1)所有的詞向量都是随机初始化的,同时当作训练过程中优化的参数(rand);
2)所有的词向量直接使用word2vec工具得到结果,并且是固定不变的(static);
3)所有的词向量直接使用word2vec工具得到结果,在训练的模型中也当作可优化的参数( non-static);
4)将static和non-static结合(multichannel)。
利用上述4种方式分别进行测试,结果如表2所示。
从表2看出,CNN-non-static的准确率为0.816 9优于其他模型,因此选用CNN-non-static模型来进行下面的实验。
3.5.2 集成学习的有效性
根据上述的实验设计,主要实验结果如表3所示。基学习器中RCNN的效果最优,准确率为0.823 0。将集成学习应用于这5种神经网络文本分类方法后,可以看出Bagging方法的准确率为0.829 8,相比最优的基分类器RCNN,准确率提高了0.83%;Stacking方法的准确率为0.823 8,相比基分类器实验准确率提高了0.10%。
为了进一步验证实验的泛化性,将训练好的模型在MR数据集上进行测试,结果如表4所示。从表中可以看出,单一模型中,RNN的准确率最高为0.585 4。Bag-glng方法的准确率为0.586 5,相比最优基分类器RNN准确率提高了0.1 8%,Stacking方法准确率为0.593 4,相比基分类器将实验准确率提高了1.37%。
两种方法集成后的准确率相比基分类器均有不同程度的提高,验证了集成学习方法的有效性。在Kaggle数据上Bagging方法准确率的提升较为明显,在外部数据上Stacking分类准确率的提升较为明显,说明Stack-ing具有较好的泛化性能。
3.5.3 基学习器的贡献率
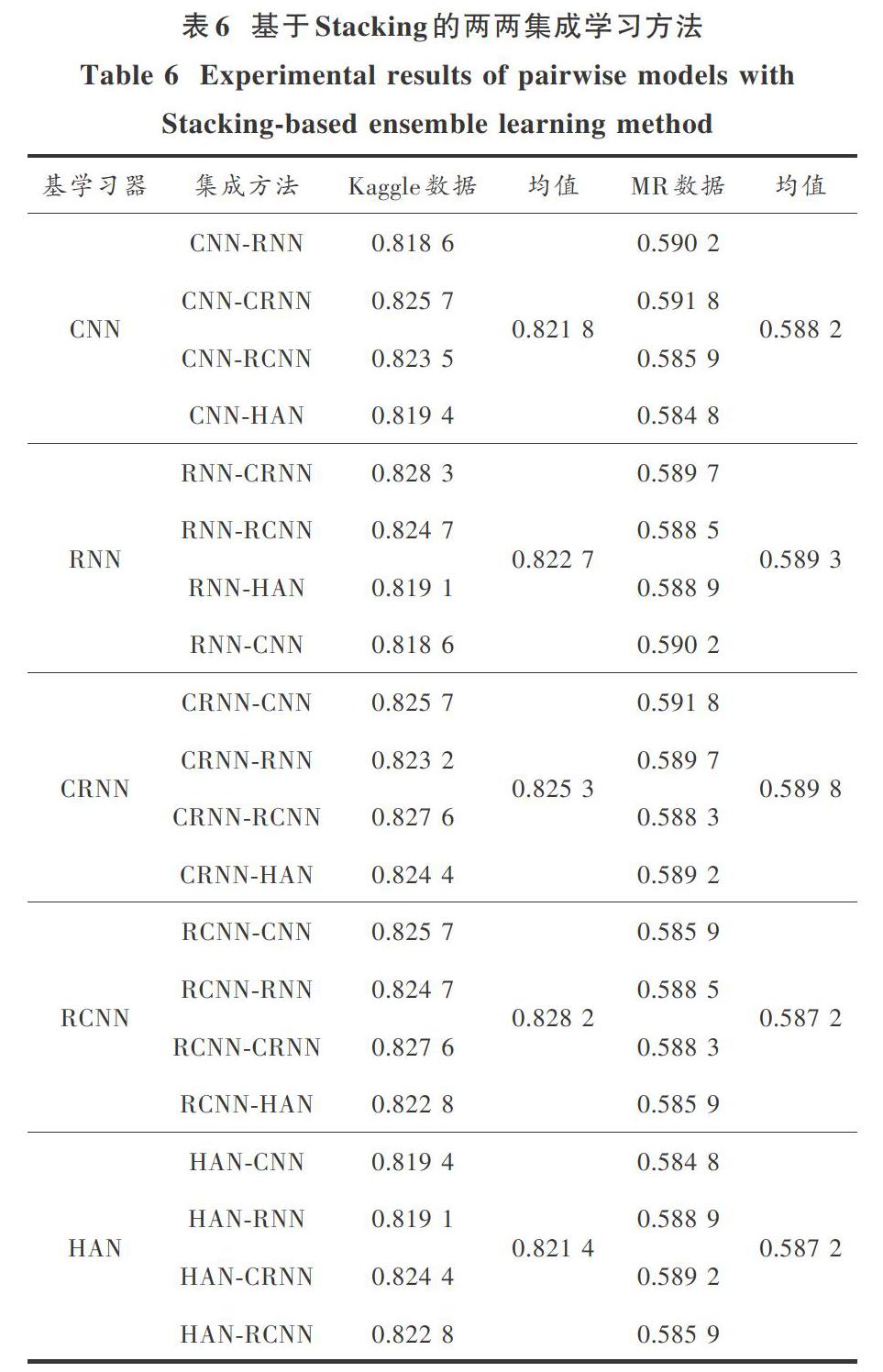
为了进一步验证基分类器在集成学习中的贡献率,将这些方法进行两两集成,对每一个基分类器与其他4种基分类器集成的准确率进行求均值。Bagging方法的结果如表5所示。Stacking方法的结果如表6所示。
从表5中看出,在Kaggle数据上CNN与其他4种基分类器集成的准确率均值最低,仅为0.810 7。其中RNN与其他4种基分类器集成的准确率均值最高为0.828 7,且优于5种方法一起集成的准确率。在外部数据MR中CNN与其他4种基模型进行集成的准确率均值为0.576 6,也低于其他4种模型。RCNN与其他4种模型集成准确率的均值为0.588 7,优于其他4种模型,且优于5种方法一起集成的准确率。
从表6可以看出,在Kaggle数据上HAN与其他4种模型集成的准确率均值最低为0.821 4,RCNN与其他4种模型集成的准确率为0.828 2,优于其他4种模型,且优于5种方法一起集成的准确率。在外部数据MR上,RCNN和HAN与其他4种方法集成的准确率为0.587 2,低于其他3种模型。CRNN与其他4种模型集成的准确率均值为0.589 8,优于其他模型。
从表5、表6可以看出,在Bagging方法中,RNN在Kaggle数据上的贡献率最大,RCNN在MR数据集上贡献率最大;在Stacking方法中,RCNN在Kaggle数据上的贡献率最大,CRNN在MR数据上的贡献率最大。
4 结语
在两种数据集上,本文使用Bagging和Stacking的方法与目前较为成熟的CNN,RNN,CRNN,RCNN,HAN文本分类实验结果相比,证实了该方法的有效性,并讨论了模型的贡献率。未来的工作考虑将其他不同的集成学习方法,如Boosting算法等,用于短文本分类,进一步提高实验的准确率。
参考文献
[1] PAVLINEK M. PODGORELEC V.Text classification methodbased on self-training and LDA topic models [J]. Expert sys-tems with applications, 2017. 80: 83-93.
[2] BIJALWAN V. KUMARI P,PASCUAL J,et al.KNN basedmachine learning approach for text and document mining [J].International journal of datahase theory&application, 2014,7(1): 67-80.
[3]高超,许翰林.基于支持向量机的不均衡文本分类方法[J]现代电子技术,2018,41(15):183-186.
GAO Chao, XU Hanlin. Unbalanced text classification methodbased on support vector machine [J]. Modern electronics tech-nique, 2018, 41(15): 183-186.
[4]蔡慧苹.基于卷积神经网络的短文本分类方法研究[D],重庆:西南大学,2016.
CAI Huiping. Research of short - text classification methodbased on convolution neural network [D]. Chongqing: South-west University.2016.
[5] KIM Y.Convolutional neural networks for sentence classifica-tion[C]//Proceedings of 2014 conference on empirical methodsin natural language. Doha: EMNLP, 2014: 1746-1751.
[6] LAI Siwei. XU Liheng, LIU Kang, et al.Recurrent convolu-tional neural networks for text classification[C]//Proceedingsof Conference of the Association for the Advancement of Artifi-cial Intelligence.[S.1.]:AAAl. 2015: 135-142.
[7] YANG Z,YANG D, DYER C, et al.Hierarchical attentionnetworks for document classification[C]//Conference of theNorth American Chapter of the Association for ComputationalLinguistics: Human Language Technologies. San Diego Califor-nia: ACL. 2017: 1480-1489.
[8] ZHANG X. ZHAO J,LECUN Y.Character-level convolutionalnetworks for text classification [J]. Neural informational process-ing systems, 2015(1):649-657.
[9] DIETTERICH T G.Ensemble methods in machine learning [C]//,International Workshop on Multiple Classifier Systems. Berlin:Springer, 2000: 1-15.
[10]蔣芸,陈娜,明利特,等.基于Bagging的概率神经网络集成分类算法[J]计算机科学,2013,40(5):242-246.
JIANG Yun. CHEN Na. MING Lite.eC al.Bagging-basedprobabilistic neural network ensemble classification algorithm[J].Computer science,201 3,40(5):242—246.
[11]BREIMAN L.Random forests,machine learnin9 45[J].Jour—nal of clinical microbiology,2001,2:199—228.
[12]李寿山,黄居仁.基于Stacking组合分类方法的中文情感分类研究[J],中文信息学报,2010,24(5):56—62.
LI Shoushan,HUANG Juren.Chinese setiment classificationbased on stacking combination method[J].JournaI“Chineseinformatio“processi“g,20lO,24(5):56—62.
[13]何跃,赵书朋,何黎.基于情感知识和机器学习算法的组合微文情感倾向分类研究[J]情报杂志,2018(5):193—198.
HE Yue,ZHAO Shupeng,HE Li.Micro—text emotional ten一dentious cIassification based on combination of emotion knowl—edge and machine—Ieaming algorithrm[J].JournaI of intelli—gence,2018(5):193—198.
[14]万圣贤,兰艳艳,郭嘉丰,等.用于文本分类的局部化双向长短时记忆[J]中文信息学报,2叭7,31(3):62—68.
WAN Shengxian,LAN Yanyan,GUO Jiafeng,et al.Local bi—directional long short term memory for text classification[J].Journa1 0f Chinese information processing,2017,31(3):62— 68.
[15]徐立恒,刘康,赵军,等.一种基于循环卷积网络的文本分类方法:CNl04572892A[P]2015一07一l3.
XU Liheng,LIU Kang,ZHAO Jun,et al.Recurrent Convolu—tionaI
Neural
Networks
for
Text
Classification:CNl04572892A[P].2015一07—13.
[16]ZHOU C,SUN C,LIU Z,et al.A C—LSTM neural networkfor text classification[J].Computer science,2015,1(4):39— 44.
[17]周志华.机器学习[M].北京:清华大学出版社,2016.
ZHOU Zhihua.Machine learning[M].Beijing:Tsinghua Uni—versity Press,2016.
[18]DzEROSKI S,之ENKO B.Is combining classifiers with stack—ing better than selecting the best one?[J].Machine Iearning,2004,54(3):255—273.
[19]WOLPERT D H Stacked generalization[J]Neural networks,1992,5(2):241—259.
作者简介:王国薇(1994-),女,河南商丘人,硕士,研究领域为自然语言处理、文本分类。
黄浩(1976-),男,新疆乌鲁木齐人,博士,教授,研究领域为语音识别、多媒体人机交互技术。
周 刚(1981-),男,新疆乌鲁木齐人,博士,副教授,研究领域为机器学习与模式识别。
胡英(1975-),女,新疆乌鲁木齐人,博士,讲师,研究领域为语音及声信号处理。
