LightGBM算法在阿尔茨海默症结构磁共振成像分类中的应用
2019-04-28周文王瑜李长胜肖洪兵邢素霞
周文,王瑜,李长胜,肖洪兵,邢素霞
北京工商大学计算机与信息工程学院食品安全大数据技术北京市重点实验室,北京100048
前言
阿尔茨海默病(Alzheimer's Disease,AD)是一种常见的进行性发展的神经退行性疾病,主要表现为渐进的认知障碍和记忆功能减退以及运动障碍等[1]。在全球65岁以上老年人中的发病率为4%~6%,据最近统计数据表明,全球已经有大约4 000 万名AD 患者,到2050年,预计全球每85 人中就会有1 人患有AD[2]。我国近几年老年人急剧增加,目前AD患者已接近500 万人。AD 患者的临床表现并不明显,这给医生的早期诊断带来一定的困难。现在对于AD患者并没有准确的诊断依据,大多数研究主要针对轻度认知障碍(Mild Cognitive Impairment,MCI)阶段。MCI 是介于正常老龄和痴呆的一个过渡阶段,约80%的MCI患者在6年内将发展成AD,年转化率达10%~15%[3]。如果在早期就能诊断出MCI,并能够及时进行相关的治疗和干预,就可以避免或者减缓患者发展为AD,所以针对AD 的早期辅助诊断尤为重要。
近年来,国内外越来越多的学者将研究重心集中在AD的早期诊断上,致力于分析不同模态的神经影像或生物标志物以用来辅助AD 的诊断[4-6]。随着计算机和医疗影像技术的发展,基于核磁共振成像(Magnetic Resonance Imaging, MRI)、正电子发射型计算机断层显像等影像数据和机器学习的方法相结合可以进行MCI 转化预测以及AD、MCI、正常对照者(Normal Control, NC)的分类[7-10]。通过对结构MRI 的大量研究发现,AD 患者的大脑结构相比于NC,主要异常表现在于大脑的灰质部分,其中最为明显的异常区域为海马、海马旁回、内侧颞叶等。2007年,Li 等[11]利用机器学习的方法对海马脑区的形状进行分析;2011年,Cuingnet 等[12]通过TI加权MRI 自动检测海马体的萎缩来区分AD患者和NC;2013年,Yao 等[13]采用静息态功能MRI 研究AD、MCI 和NC大脑杏仁核连接模式的改变;2015年,Blennow 等[14]通过标记大脑脑脊液来对AD 进行辅助诊断,Riise等[15]通过大脑的突触衰竭、网络连接中断和神经变性之间的联系,发现Wnt 信号对AD 患者影响重大;2016年,Khedher等[16]利用独立成分分析来提取阿尔茨海默症神经影像(Alzheimer's Disease Neuroimaging Initiative,ADNI)数据库的MRI 样本特征,并利用支持向量机(SVM)来进行分类;2017年,Guo等[17]基于AD的功能MRI超网络的多个特征,结合机器学习的方法来进行分类;2018年,Huang 等[18]和Lee 等[19]及其他的研究利用机器学习技术和MRI技术来辅助医疗人员对AD进行前期诊断,从而得到MCI和AD的正确分类。
在前人的研究基础上,本研究尝试用机器学习方法对AD、MCI和NC进行分类的相关研究,利用ADNI数据库(adni.loni.usc.edu)的116名AD患者、116名MCI患者和117名NC数据,先通过spm软件进行预处理,并进行相关性分析,发现AD患者和NC在双侧颞叶、海马、海马旁回、杏仁核、丘脑等脑区有较大的灰质萎缩,然后通过IBASPM提取感兴趣区域体积作为样本特征,最后利用LightGBM算法来进行分类。
1 研究方法
1.1 图像预处理
从ADNI 数据库下载的图像格式为DICOM,因此本实验先通过MRIcro 软件将图片格式转换为NIFTI,再利用spm 软件进行预处理。图像预处理的流程如图1所示,对图像依次进行头动校正、配准、分割、空间标准化和平滑等预处理操作。通过spm分割可以将脑图像分割成灰质、白质和脑脊液3 部分,因为AD患者的大脑异常主要表现在灰质部分,所以主要针对灰质部分进行研究。

图1 图像预处理流程图Fig.1 Flowchart of image preprocessing
1.2 相关性分析
通过spm 软件对图像样本进行预处理得到大脑的灰质部分,并对AD-NC 样本的灰质图像进行双样本T检验,利用xjview 软件显示检验结果,设定显著性水平值p=0.05(通常p取0~1),设定p=0.05 代表出现一个异常体素的机率为5%。最后经过错误发现率校正后,把脑区图像叠加到标准脑MRI 的avg152T1模板上,从而获得AD 患者的病灶区域,并设置不同的统计阈值,设定体素集合为20个,生成的激活区最大密度透明图和伪彩图如图2所示。
根据xjview生成的报告,并结合自动解剖标记,得到AD-NC组的灰质萎缩区域的解剖位置如表1所示。
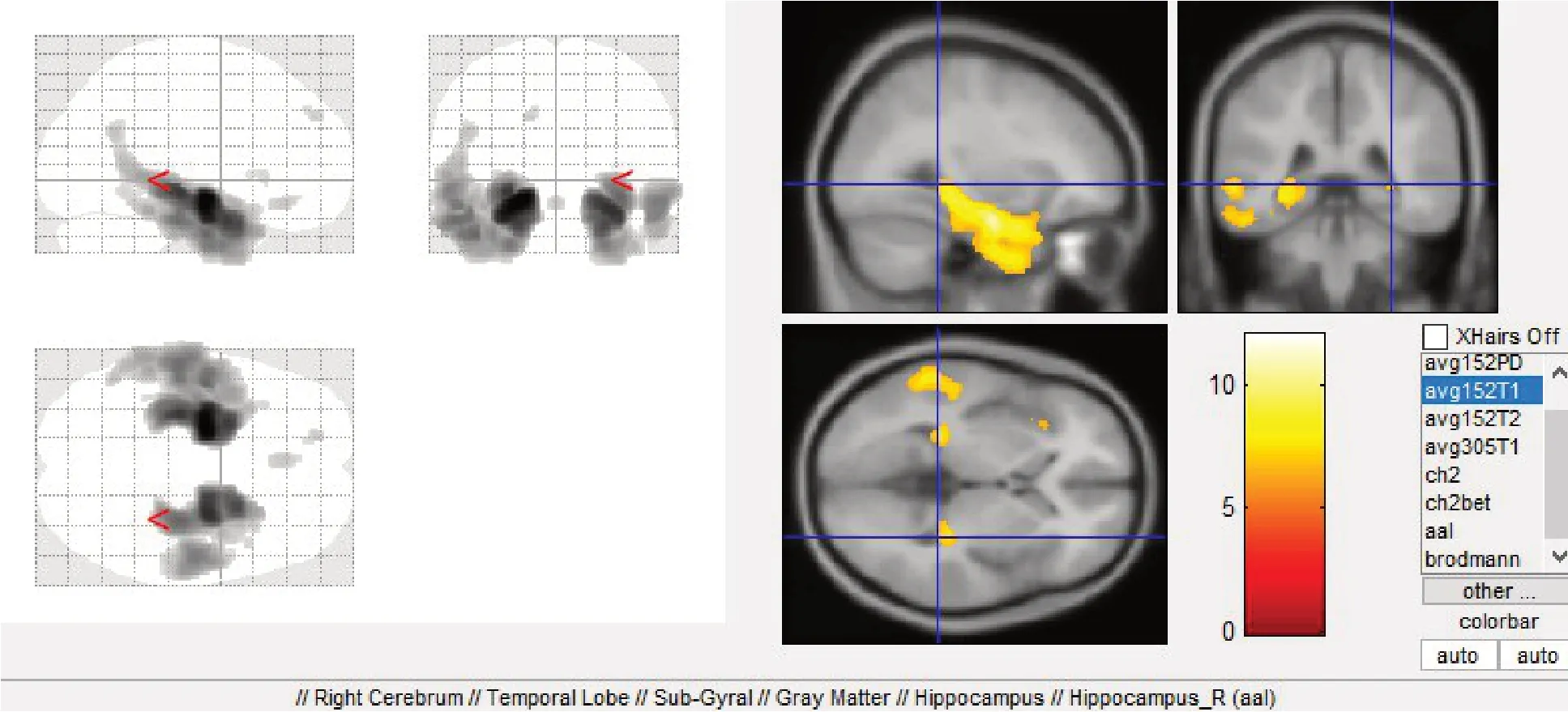
图2 AD-NC组灰质萎缩脑区分布对比Fig.2 Comparison of gray matter atrophy in Alzheimer′s disease-normal control(AD-NC)group

表1 AD-NC组的灰质萎缩区域报告Tab.1 Report on gray matter atrophy in AD-NC group
根据图2和表1的结果可以看出,AD 患者脑区萎缩最明显的是在双侧颞叶,其中包括海马、杏仁核、海马旁回。另外,在岛叶、顶下小叶、枕叶深部、丘脑、梭状回等区域也相应地出现不同程度的萎缩,本实验所得结果与文献[20-21]中AD患者的脑区结构、发生萎缩的区域基本一致,接下来本实验将对这些萎缩脑区进行重点研究。
1.3 特征选择
由数据预处理阶段可以得出AD患者在海马区、海马钩回、杏仁核区,丘脑区、双侧颞叶区、梭状回等脑区存在明显的萎缩,利用IBASPM软件提取这些脑区的体积值作为特征向量,具体的操作流程如图3所示。
2 分类器
本研究通过深入调研,选择LightGBM算法对选取的特征向量进行分类。LightGBM 算法是2016年微软亚洲研究院发布的一个开源快速、高效的算法。该算法主要基于GBDT、GBRT、GBM 和MART决策树算法的框架,并且被广泛用于分类、回归和排序等多种机器学习的任务,除此之外,LightGBM 算法支持高效率的并行训练,能利用直方图做加速。
通过数据预处理及特征选择对大脑的左右侧海马、海马旁回、杏仁核、丘脑、颞叶、梭状回、岛叶和枕叶深部共16个脑区的体积值进行提取。为了更好地实现分类,样本集用T表示,T={(x1,y1),(x2,y2),…,(xN,yN)},xi∈X ⊆Rn,yi∈{0,1,2} ,其中xi为样本,yi为标签。本实验运用LightGBM算法进行分类的步骤如下。
(1)对样本集T进行归一化。

(2)计算初始梯度值(初始值设置为0)。


图3 病灶区体积提取流程图Fig.3 Flowchart of volume extraction in the lesion area
(3)建立树。
a.计算直方图。

其中,

b.从直方图获得分裂收益,选取最佳分裂特征G,分裂阈值I。

c.建立根节点。

d.根据最佳分裂特征,分裂阈值将样本切分。

其中,bp1…k,s≤Is,bpk+1…n,s >Is。
e.重复a~c 选取最佳分裂叶子,分裂特征,分裂阈值,切分样本,直到达到叶子数目限制或者所有叶子不能分割。
f.更新当前每个样本的输出值。
(4)根据之前得到的树更新梯度值。
(5)重复步骤(3)和(4),直到所有的树都建立好。
(6)调节参数,进行分类实验。
3 实验结果与分析
为了证明LightGBM 算法在分类效果上的优越性和鲁棒性,本实验采用了SVM、XGBoost算法作为对比试验。实验硬件环境为个人PC 机,处理器为Intel®CoreTMi7-4710MQ,CPU@2.7 GHz,内存为8.00 GB。实验的编译环境为Matlab2017b,Python3.7,编译语言包括MATLAB、Python,图像预处理所涉及到的软件包括SPM8、MRIcro、xjview 以及IBASPM[22]。
3.1 实验数据介绍
本实验使用的MRI 数据是从ADNI 数据库获得的,ADNI 库的工作人员对ADNI 数据库的设计和实现提供了帮助,但没有参与本实验的分析或撰写。本实验使用的数据包括349 名被试者,其中AD 为116名、MCI为116名和NC为117名。研究对象的基本统计信息如表2所示。
利用SPSS软件对AD和MCI、AD和NC、MCI和NC 这3 组患者的年龄进行F检验和t检验,得到方差。对性别进行皮尔逊和卡方检验,结果均显示这3组实验数据之间不存在显著差异。

表2 被试者统计分析结果Tab.2 Characteristics of the participants enrolled in this study
3.2 实验设计
通过提取感兴趣脑区的体积值作为分类的特征向量,为了更好地体现本实验的完备性和LightGBM算法的优势,利用SVM 算法和XGBoost 算法来做对比实验。由于这些算法涉及较多的参数,并且参数的设置对于分类结果也起着举足轻重的影响,因此参数的优化就显得尤为重要。本实验将训练集和验证集按4:1的比例进行分配,利用交叉验证和网格搜索的方法来对参数进行调优。LightGBM 算法使用直方图简化计算,基于直方图的决策树算法,多线程优化;XGBoost 分类算法包括很多参数,主要参数分为通用参数、booster参数、学习目标参数3大类;SVM选择sklearn 中的SVC 函数,核函数选择径向基核函数(Radial Basis Function,RBF)。各算法主要参数取值如表3所示。

表3 各分类算法参数取值Tab.3 Parameter of different classification algorithms
3.3 实验结果与分析
根据分类算法的各参数,调节分类模型,并利用分类准确率ACC 和Kappa 系数来评价分类结果。ACC是最常用的分类评价指标;Kappa系数是一种衡量分类精度的指标,计算公式为为观测精确性,pe为偶然性一致。Kappa 计算结果通常为0~1,并且可分为5 个阶段来表示不同级别的一致性:极低的一致性为0.0~0.20,一般的一致性为0.21~0.40,中等的一致性为0.41~0.60,高度的一致性为0.61~0.80和几乎完全一致为0.81~1.00。各个分类算法获得的最佳分类结果如表4所示。
根据表4的实验结果可知,对于同一MRI图像数据集,LightGBM 算法相比于SVM 和XGBoost 分类准确率最高,可达到83%,Kappa 系数可达到0.815。SVM的分类准确率最低,为75%;XGBoost的分类准确率为78%。由此可见,对于处理MRI数据,针对本实验提取的特征向量,LightGBM 算法的高效性、稳定性以及避免过拟合的能力比其他算法更为优秀,在分类准确率上更高,对于机器消耗的内存也相对更低。

表4 各分类算法结果对比Tab.4 Comparison of results obtained with different classification algorithms
4 结论
本实验通过利用SPSS软件统计分析被试者年龄和性别的无差异性,并通过spm软件对样本数据进行预处理,利用双样本t检验的统计学方法找到AD 患者的病灶脑区,并提取病灶脑区体积值作为分类的特征向量,最后利用机器学习算法SVM、XGBoost和LightGBM 来进行分类,实验结果表明LightGBM 算法对于特征向量具有更好的分类效果、更快的训练速度和更低的内存占用,可以更好地辅助医生对AD进行诊断,更有效地发挥计算机辅助诊断作用。
