云计算技术下海量数据挖掘的实现机制
2019-04-26崔辰
崔辰
(川庆钻探工程有限公司 长庆钻井总公司, 西安 710018)
0 引言
在现代云计算、社交网络、移动通信互联网及数据自动收集技术不断发展的过程中,人类社会也出现了一定的变化,其中的数据量也呈爆发式的增长。美国互联网数据中心通过研究表示,目前世界中所产生的数据大概呈着50%左右的速度增长,每隔两年翻一倍,并且大部分数据都是最近几年所产生的,大数据时代已经到来。数据属于现代社会中尤为重要的资产,拥有的信息量已经成为制约并且决定社会发展的主要因素,人们急需要从数据中将具有价值并且宝贵的信息进行有效的挖掘,从而促进企业实现正确决策。云计算数据挖掘平台能够满足海量数据挖掘需求,此平台能够实现资源的动态分配及调度,并且具有较高的可靠性及虚拟化特点。
1 云计算和数据挖掘分析
1.1 云计算
目前对于并没有统一定义,客户端利用网络自助将运算任务为服务端发送,服务器运算之后将运算结果对客户端进行发送,此过程就是云计算。云计算的主要形式包括:
其一,软件即服务(SaaS)。软件即服务包括客户和服务供应商,应用软件在服务供应商服务器端统一部署,在客户对软件具有使用需求的时候,就可以对供应商购买应用软件,并且利用浏览器实现接收。此种模式的优势为:客户在具备软件使用需求的时候,不需要投入大量资金在软件、硬件及相应维护中;服务供应商能够实现应用额元件实现统一管理及维护[1]。
其二,平台即服务(PaaS)。在此种模式中,服务供应商提供服务属于平台,也就是对客户提供多种服务器资源、硬件资源及开发环境。用户在供应商所提供的平台中实现满足自身需求应用程序的开发,并且通过互联网和相关服务器对客户进行传递。根据此模式,用户能够实现相应数据库管理软件、应用程序的开发。
其三,基础设备服务(IaaS)。此服务模式主要是以托管型为基础的硬件方式,用户在支付费用之后,就能够使用服务供应商中的虚拟服务器及资源等[2]。
1.2 数据挖掘
数据挖掘指的是从大量数据中实现关联、变化、有意义及异常结构抽取的过程,此数据大部分都具有噪音,并且不完全,而且随机、模糊。以此表示,数据挖掘技术涉及了人工智能、统计学、模式识别、机器学习等。目前,数据技术已经被广泛应用到金融、典型、科学研究及互联网等多领域中,比如实现商品销售量预测、银行分析客户分销使用渠道等。传统数据挖掘技术是以数据仓库及关系数据库为基础实现数据计算、统计及分析,寻找其中的关系,从而使挖掘理论价值得到提高,此过程会消耗大量存储及计算资源。
在移动互联网不断发展的过程中,数据规模从传统TB级发展为ZB级,并且还在持续增加, 从而使传统数据挖掘系统无法满足此需求,主要为:挖掘效率较低;软件及硬件的成本较高,以此消耗大量资源及空间;体系架构较为薄弱,传统数据挖掘技术都是通过单一算法作为主体,没有适应普遍性[3]。数据挖掘的逻辑结构,在实现数据挖掘过程中,首先要对数据进行前处理,之后实现数据挖掘,通过相应算法得到结果评价及表达,之后将其中有价值的信息进行提取,如图1所示。
2 数据挖掘中云计算的优势
在数据挖掘中使用云计算,是因为云计算自身具备海量存储能力及分布式的并行处理能力。具体来说,云计算在数据挖掘中使用的主要优势为:
其一,云计算具备高效且实时的分布式并行数据挖掘能力。在面对海量数据实现挖掘的过程中,能够更加展现出其优越性。另外,云计算服务业能够为不同规模组织提供优质服务,并且使计算成本降低,实现大型数据快速处理,提高企业效益,还能够避免企业过于依赖大型高端机。
其二,对大部分用户来说,不需要重视使用云计算技术实现数据挖掘过程中地层实现的过程。在数据块划分、计算任务调度及加载节点的时候,都是通过系统实现自动分配[4]。
其三,云计算技术数据的挖掘门槛比较低,大众用户利用云计算服务平台就能够根据自身需求服务,为需求量较大的网络用户提供一定的个性化信息服务。
其四,基于并行化,云计算具备结点动态增删的能力,充分使用原本的设备添加结点,使海量数据处理速度及能力得到有效提高,并且使设备生命力和使用率得到有效提高[5]。
3 云计算海量数据挖掘的实现
3.1 云计算下的海量数据挖掘模型
在海量数据挖掘中使用云计算技术,能够充分展现云计算中的大容量存储及并行处理的能力,并且还能够有效解决目前海量数据挖掘过程中的难点内容。云计算下海量数据挖掘的模型。如图2所示。
通过图2可以看出来,基于云计算技术的海量数据挖掘模型主要包括三层,分别为云服务层、数据运算层及用户层。其中云服务层属于最基层,其主要目的就是实现海量数据的存储,并且具备分布并行数据的处理。云计算环境不仅要保证数据实用性,还要保证数据安全性及可靠性。在数据存储过程中,云计算技术使用分布存储方式,具备数据副本冗余存储功能,保证如果数据丢失,用户还能够正常的运转。目前,普遍使用功能的云计算数据存储技术包括开源HDFS与非开源GFS两种。另外,云计算数据充分实现数据并行处理的挖掘,能够基于多用户指令,对用户进行及时回复,还能够提供数据挖掘服务[6]。
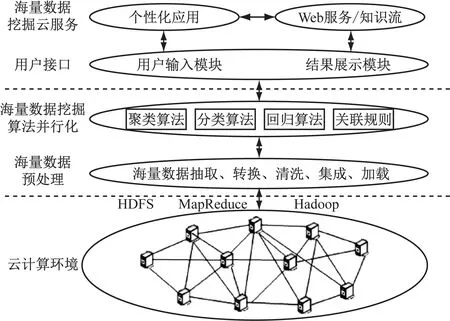
图2 云计算下海量数据挖掘的模型
数据挖掘运算层属于第二层,其主要目的就是实现数据预处理及挖掘算法并行处理。数据预处理指的是对大量没有规则数据实现预先处理,以云计算并行运算模式开展的数据挖掘,一般实现数据预处理过程中主要使用数据分类、转化、约束及抽调等。实现数据预处理,能够提高数据挖掘质量,并且提高海量数据挖掘的快速性及实时性。
用户层属于最顶层,其是直接面向用户的,主要目的就是对用户请求进行有效接收,并且使数据对下一层进行传递,使数据挖掘运算结果对用户进行反馈。另外,用户还能够利用可视化界面对任务的进度进行控制和监督,并且对任务执行结果进行实时的查看[7]。
云计算中海量数据挖掘实现的流程为:用户在输入模块中发送数据挖掘指令,并且对系统服务器进行传递,服务器就能够自动根据用户挖掘指令通过数据库实现数据的调出,并且在算法库中实现最优挖掘算法的调出,在实现数据预处理以后,到运算模块中传递,实现数据的深入挖掘,最后将挖掘结果对可视化界面进行反馈,从而便于用户的查看及了解[8]。
3.2 海量数据挖掘实现算法
3.2.1 SPRINT算法
SPRINT算法主要包括数创建及剪枝过程,因为在实现决策树创建过程中要实现多次数据遍历,但是剪枝不需要此过程。那么,对于树剪枝时间只是创建数的百分之一。所以,重点就是创建树。SPRINT算法能够将数据特征充分的展现出来,使用直方图及属性表两种数据结构。直方图是以属性表为基础,属性表在节点划分过程中分裂。其会根据不同属性性质展现出针对性的展现形式。属性表属于属性值,记录索引和类标记创建三元组,其能够在除了内存以外介质中停留。直方图能够将节点属性类分布的情况进行充分的展现,在属性术连续数值型的时候,节点就与两个直方图相关,其中Cbelow指的是已经处理样本的类型分布,Cabove指的是没有处理的样本,其能够利用不间断刷新寻找最佳分裂点。在属性属于离散型的时候,要只是需要直方图,其中具有此属性值的类分布信息,只需要对计数矩阵统计图进行维护[9]。
3.2.2 算法并行设计
算法并行与传统算法多加入了哈希表,从而对每次节点分裂以后子节点数据信息进行存储,利用此子节点信息记录,将其作为节点并行分割的基础。其中的哈希表主要包括两种信息,第一种为决策时候节点号码,使用TreeNodeID表示;第二种为目前树节点子节点号,使用ChildNodeID表示。
在算法移植的过程中,只要是实现算法MapReduce化,利用Map及Reduce函数开展。函数的N-S图,如图3与图4所示。
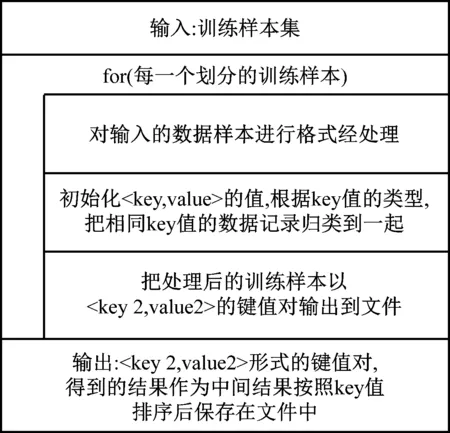
图3 Map函数的N-S图

图4 Reduce函数的N-S图
在以上处理结束之后,属性表就已经到相应叶子节点中发送,这个时候决策树的创建已经全部结束,目前节点相关文件都已经到分布式文件系统中存储,表1为节点信息的保存格式。不管是叶子节点,或者是非叶子节点,都通过N进行表示。其中fleaf表示非叶子节点,tleaf表示叶子节点。使用此种方法,能够有效提取决策树结果,如表1所示。

表1 节点信息的保存格式
3.3 实验结果
本文实验是使用驾车风险高低预测公用数据及作为本文的训练集,其能够将参保车险车主的信息进行记录,决策树创建中的节点信息,如图5所示。
图5 决策树创建中的节点信息
为了能够对算法挖掘模式的正确性进行判断,所以在实际操作过程中要将所有样本集分割成为5个没有交集的组,从而对精准性进行测试,(此方面预测的正确数量较多,表示预测正确率较高,算法精准。)如表2所示。

表2 算法测试结果
通过测算结果表示,算法的精准率为89.25%。以此可以看出来,本文所设计的挖掘算法具有较高的精准性,实验成功,能够实现有效分类挖掘[10]。
4 总结
目前云存储平台中的数据量在不断的增加,传统数据挖掘模式已经无法和现代社会相互匹配,并且也无法实现数据中内在信息的有效挖掘。所以,其对于数据挖掘工作提出了更加全面的需求,在实现云计算和处理系统过程中,要求具备对海量信息存储及变化的能力,从而实现资源的内在有效挖掘,并且对大量数据进行有效的处理。本文所设计的数据挖掘算法挖掘进度较高,其中的用户数据性及安全性需要进一步的加强。
