基于Scrapy的网络爬虫系统框架设计与实现
2019-04-26王磊刘晓丹
王磊, 刘晓丹
(陕西广播电视大学 信息与智能技术学院, 西安 710119)
0 引言
网络上的信息随快速发展的互联网表现出指数级的增长趋势,增加了用户快速获取所需信息的难度。作为数据获取工具的一种,搜索引擎中通常会应用到网络爬虫,但针对中小规模系统的网络爬虫往往面临较多的问题,在抓取数据速度上单机的网络爬虫程序难以有效满足需求,并且网络爬虫框架大都没有实现分布化,单一的网络爬虫程序难以满足多种类型的网页结构,简单稳定的高性能分布式网络爬虫系统框架以满足中小规模系统的需求具有较高的实际应用价值。
1 系统设计目标
Scrapy能够进行屏幕抓取,且具备web抓取框架、快速、高层次的优势,提供了多种类型爬虫的基类(包括BaseSpider、sitemap等),用途广泛,用于从web站点页面中抓取并提取出结构化的数据,可用于数据挖掘、监测和自动化测试,同时用户可以根据实际需求进行修改。
不同于传统的通用网络爬虫,基于Scrapy的网络爬虫系统采集的网页信息需与用户需求相关,而无需对互联网上所有的资源进行采集。针对不同网站所具有的网页结构不仅相同,为降低资源耗费及开发成本,网络爬虫系统的设计需具有足够的灵活性,从而能够在不同环境下无需做较大改动即可应用;随着网页数量的激增,考虑到单机抓取速度的有限性,需在原有Scrapy框架基础上进行优化,完成部分组件的重写以支持分布式抓取,以降低采集时间;分布式网络爬虫在中小规模系统中的关键在于负载均衡,需确保系统分配任务量时以各爬虫节点的负荷状态为依据,使爬虫的抓取效率得以有效提高;同一时刻需限制发送到远程服务器的请求以及集群中爬虫节点对网站的访问频率;提高系统错误处理的能力,能够及时处理突发状况;降低系统操作及配置的难度,爬虫开始或停止操作简单,对集群中各爬虫速度进行实时监控。
2 系统总体设计
系统总体架构如图1所示,(1)用户交互层由爬虫管理和配置两个子页面构成,完成同用户的交互,用户提交的请求(包括查询爬虫任务状态、站点配置信息更新、查询模块状态及爬虫抓取4类请求)由配置子页面接收,为便于后续消息预处理模块解析每类请求各有其固定的格式;集群中爬虫的启动与停止以及对各节点上爬虫实时的运行状态的监控由爬虫管理子页面实现。
(2)对配置子页面传递请求消息的验证、解析由处理层完成,为有效的处理大量活跃的流数据以满足不断增加的业务需求,系统的中间缓存器使用了Kafka,保证数据流转的高性能及低延迟,其中配置子页面请求的周期性获取以及请求格式正确性的验证由消息预处理模块完成,单位时间内该模块请求成功/失败数量的记录则由状态计数器完成,如果请求的验证结果为爬虫抓取请求即存入任务队列,其余3类请求以相应格式存入到Redi中,Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。多个该模块同时运行以以确保该模块宕机对系统正常运行不会造成影响;Redis中传入的验证成功请求的周期性检测由Redis监控模块完成,然后通过相应插件的调用完成该请求的处理解析,将结果传送到kafka消息系统中,同样使用多个Redis监控模块对请求进行检测处理,从而提高系统的可靠性及请求响应速度[1]。
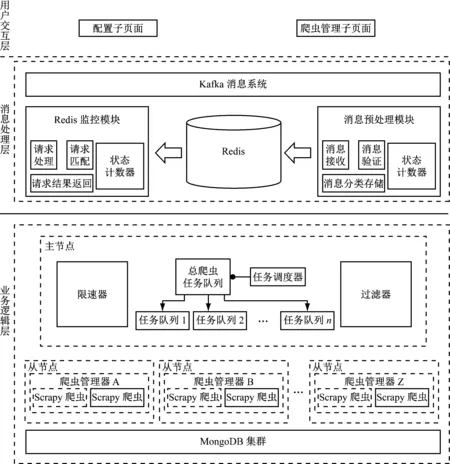
图1 系统总体架构
(3)系统的关键在于业务逻辑层,其构成为主节点一个及从节点若干个,物理结构如图2所示。

图2 物理结构图
各爬虫节点的任务调度交通过此种结构由主节点负责统一执行,降低了任务调度的难度,以爬虫节点实时运行状态为依据完成最优调度决策的制定。主节点中的爬虫任务队列分为总爬虫和节点两种,爬虫抓取请求(由配置子页面中传入)及新的爬虫抓取任务(由后续爬虫节点在网页中抽取)存放于总爬虫任务队列中;各爬虫节点待抓取的爬虫任务存放于节点爬虫任务队列中,待抓取爬虫任务的存放选用内存型数据库Redis,以确保快速获取与提交爬虫任务。
该层中爬虫任务由总爬虫任务队列到各节点队列中的分发由任务调度器完成,以爬虫节点实时状态为依据任务调度器采用动态反馈任务调度策略分发爬虫抓取任务,以确保集群中各爬虫节点负载均衡;集群中爬虫节点对某个网站的访问频率(在固定时间段内)的控制由限速器完成,避免被网站屏蔽以实现数据的抓取,降低远程服务器的压力;为使整体的抓取效率提高,需通过过滤器模块避免重复抓取相同的URL,海量URL去重通过布隆过滤器算法实现[2]。
爬虫节点启动、采集及存储数据的任务由从节点完成,其中爬虫管理器分布放置在各个从节点中,从而有效降低管理器的负载,爬虫的启动或停止及对节点中各爬虫运行状态的监控由其完成;数据采集则由Scrapy爬虫负责完成,该模块主要由5个子模块构成:由调度器子模块完成爬虫抓取任务的周期性获取,将任务以规定的格式进行处理后(即封装成Request请求)交给中间件,按照既定格式将从数据采集子模块接收到的URL完成新的爬虫抓取任务的封装并提交给总爬虫任务队列(主节点);为确保抓取过程中的稳定性,Request请求中IP地址的动态改变由中间件子模块完成,从而能够应对网站的反爬虫策略;向目标网页发起访问及对应网页内容的下载由下载器子模块负责完成,然后将下载内容传输至数据采集子模块完成相应网页数据及URL链接的提取(需以用户自定义的抽取规则为依据),接下来数据管道子模块会对网页数据(主要包括网页正文提取、编码转换、数据清理等操作)进行处理,调度器对需跟进的URL链接进行处理;存放最终抓取数据则通过MongoDB集群实现,集群模式能够满足业务增长数据量突增的需求。
3 系统框架的实现
系统整体运行数据流图如图3所示。
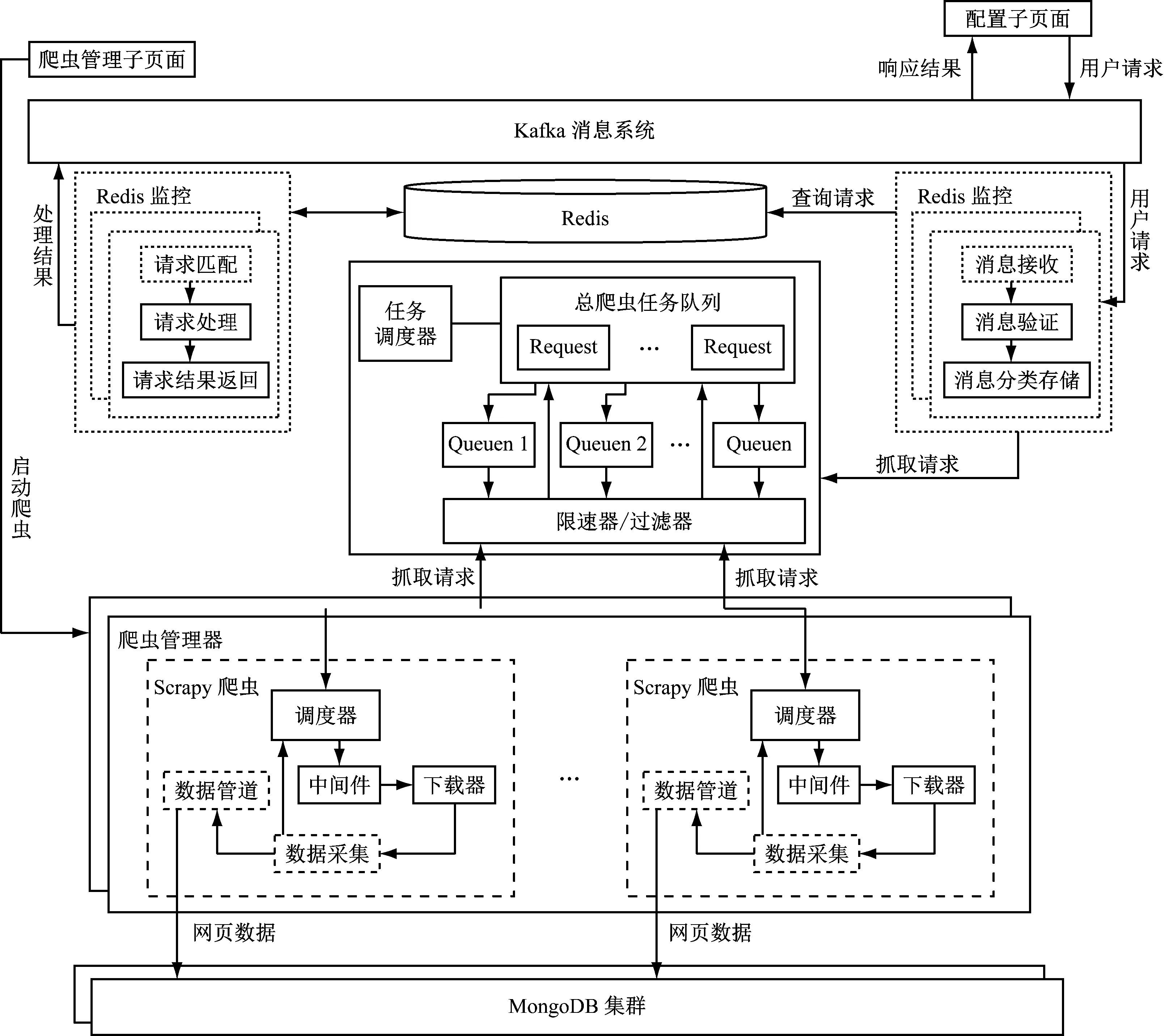
图3 系统运行数据流图
(1)用户先提交待抓取的URL及相关信息并启动相应的爬虫,后台接收到爬虫抓取请求后即时将其存入Kafka中,当新的抓取请求被消息预处理模块检测到后,在总爬虫任务队列中存入将符合系统定义格式的请求,将不符合的请求记录到失败日志中。
(2)任务调度器对总爬虫任务队列采用动态反馈任务调度策略(依据运行中各爬虫节点负荷状态)分发爬虫抓取任务,当有新的爬虫抓取任务被爬虫节点的调度器检测到后,集群中的爬虫节点的访问频率需先由限速器进行判断,超过系统设定频率则获取其它爬虫抓取任务,从队列中取出未超过设定频率的爬虫抓取任务并将其封装成Request请求(需按照Soapy规定的格式)后传给中间件,中间件子模块会在Request请求中装载随机取出的一条高匿IP后传给下载器,下载器据此向目标网页发起访问并对网页进行下载,数据采集子模块完成所需网页数据及URL链接(后续待跟进)的提取,数据采集子模块将URL链接提交给调度器,调度器通过过滤器对当前URL链接进行判断,丢弃己经抓取过的,对判断结果为未抓取过的URL链接进行封装(需按照系统定义的格式),使其成为新的爬虫抓取任务,然后提交给总爬虫任务队列。
(3)最后将采集到的网页数据通过数据管道子模块进行相应处理后(主要包括编码转换、正文提取及数据清理)存入MongoDB集群[3]。
4 数据库设计
爬虫系统内部使用了MongoDB(存储爬虫最终抓取的数据)及Redis(存储爬虫抓取请求)两类数据库,整个系统的正常运行离不开MongoDB或Redis数据库的性能及可靠性,因此本文使用集群完成数据库的搭建。
4.1 MongoDB集群
为满足数据量不断增长的需求,通过分片技术的使用实现数据在多台机器中的存放,MongoDB集群中各组件如图4所示[4]。

图4 MongoDB集群组件
Mongos(路由控制器)需对所有的数据库集群的请求进行协调,并完成数据请求到对应Shard分片服务器上的转发。
Config Servers(配置服务器)对所有路由、分片的配置进行存储,mongos则从该服务器中加载配置信息。
最终数据存储由Shard (分片)完成,并提供方便的数据访问接口,各分片可以是replica set(副本集),以避免数据丢失从而确保数据的安全。
本系统中的mongos和config server配置了3个,以确保存储查询能够顺利完成,MongoDB集群的结构图5所示。
4.2 Redis集群
作为内存型数据库,Redis引入哈希槽概念,各节点负责一部分哈希槽(集群划分为16 384个槽),提供多个程序集,有利于多Redis节点间数据的共享,进入的Redis的键值对key-value会通过散列分配到某个槽中,使数据库占用的单台机器内存得以显著降低,系统Redis集群结构如图6所示。

图5 MongoDB集群结构图
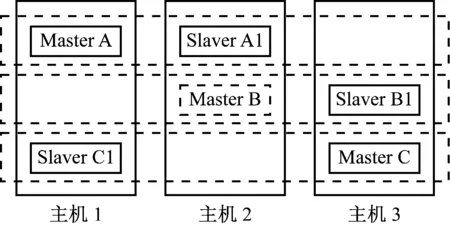
图6 Redis集群结构
集群提供主从复制机制,各主节点(负责客户端的读写请求)对应从节点(对主节点中的数据进行备份)若干个,以保证集群在节点出现宕机时仍能够正常运行,集群可通过在从节点中选取一个节点代替宕机的主节点作为新主节点继续工作,以防单点故障问题,本系统包含Redis主节点三个,分配在3台物理机上,哈希槽的具体分配为:1到5500号由节点A负责,5501到11000号由节点B负责,11001到16384号由节点C负责,各主节点都配备一个从节点[5]。
5 总结
本文主要研究了基于Scrapy网络爬虫系统框架,以设计目标为依据对网络爬虫所需具备的功能特性进行了详细分析,完成了系统总体框架的设计,该框架采用主从结构,并介绍了各层主要模块的功能,详细阐述了完整的抓取过程,为促进网络爬虫系统框架的实现,综合MongoDB及Redis完成了系统数据库方案的设计,从而提高用户获取信息的速度和质量。
