基于Hadoop大数据平台的金融产品购买行为分析
2019-04-26庞双玉
文/庞双玉
1 引言
商业银行非常重要的一项业务就是零售业务,银行零售业务成既能够提供为银行提供稳定的低成本的来源,又能对冲银行其他业务的不稳定性,同时又满足了客户的理财需求,银行零售业务迅速成为新的业务增长点。银行代销各大基金公司推出的产品,针对差异化的客户和客户需求,发售不同风险级别和不同收益区间段的产品。
银行的产品研发部门能否针对当前经济形势和客户存款状况,结合基金公司发行的产品类型研发出适应市场和客户需求的产品,是整个银行零售业务核心竞争力的来源。针对银行海量的交易数据,运用大数据框架,从交易数据中寻找规律和做出判断,为银行的产品引入决策提供支持,是一件有意义的事情。
本文讨论在Hadoop大数据框架下,利用map/reduce机制,对交易数据进行分析,分析在银行代销的各大基金公司在某个历史时间段的交易额,从交易金额数据中,判断出客户对基金公司的偏爱度。
2 数据建模和处理
银行的数据库系统中存储有大量的客户交易数据,从交易数据中,提取出下列的字段组合,(交易基金公司,基金公司产品,交易金额)以C(Company)代表交易基金公司,以P(Product)代表产品名称,以A(Amount)代表交易金额,字段组合为(C,P,A)。
在字段(C,P,A)中,有价值的字段是C和A,因为基金公司产品名称不是关心的对象,所以,在map阶段,去掉字段组合(C,P,A)中的P字段,以(C,A)作为reuduce的输入字段。map/reduce完成对字段的统计和排序,整个统计和排序字段值的变化过程如图1所示。
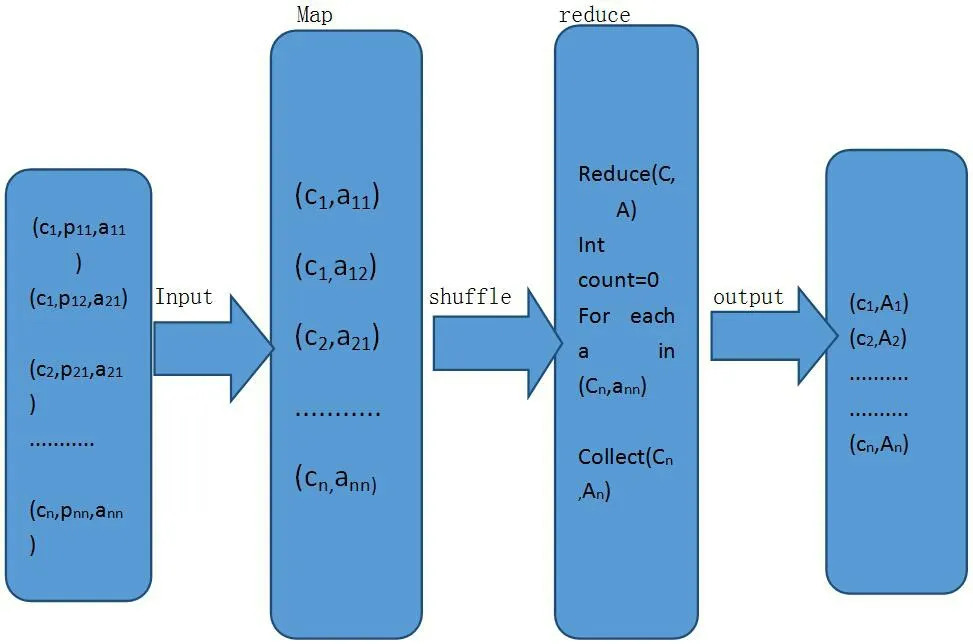
图1:map/reduce处理数据模型

图2:map/reducec处理流程图
在图1中,Cn代表基金公司ID,第n个基金公司,Pnn代表第n个基金公司的第n个产品名称,ann代表第n个基金公司第n个产品的销售金额,把(cn, pnn, ann)作为map/reduce的输入。
在map阶段,去掉字段组合中的pnn,因为某个基金公司的某个特定产品名称不是我们关心的内容,我们只关心,每个客户对于某个特定基金公司的交易金额,去掉pnn字段后,字段组合只剩下(cn, ann)。
在shuff le阶段,按照基金公司ID,进行分组排列字段(cn, ann),比如:

这样,我们就得到了一个
在reduce阶段完成对每个C下面的交易金额的累加,最后形成输出结果,每个基金公司总的交易金额(Cn, An)。
整个数据模型的变换过程如下:
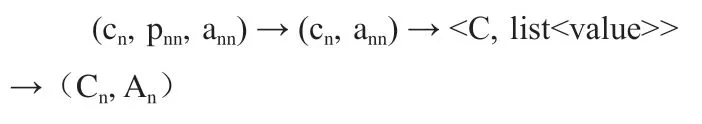
3 map/reduce作业处理流程
在Hadoop处理框架中,map/reduce作业处理流程如图2所示。
(1)MapReduce首先将资源文件进行分解,分成多个Chunk,一个chunk大概64M,同时用fork将进程拷贝到集群内其它机器上。
(2)集群中的JobTracer在TaskTracer中制定map和Reduce。
(3)被分配了Map作业的worker,开始读取第1步分解好的Trunk,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
(4)缓存的中间键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
(5)master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
(6)reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
(7)当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
4 结论
利用Hadoop平台的map/reduce流程对银行交易数据的分析,从数据规模上,可以对海量数据进行分析,从分析结果上,在足够大的客户交易数据样本上得出的每个基金公司的交易金额更能客观的反映出客户对该基金公司的偏爱度,从而为银行引入产品提供决策支持。
