支持向量机在语音情感识别中的应用
2019-04-26潘涛王胜利
文/潘涛 王胜利
1 前言
语音是人类进行高效复杂信息交换的最重要通道,语音情感识别是人工智能技术的核心领域之一。情感语音当中可以提取多种声学特征,用以反映说话人的心理情感特征行为等特点。然而在过去几十年里,如何高效地从语音信号中的识别情感特征已成为研究热点话题。
语音信号中的情感信息处理因为涉及到不同语种之间的差异,发展也不尽相同。英语、德语等语种的语音情感分析处理都有较多的研究,而汉语语音的情感分析处理研究起步较晚。情感信息有一个重要的心理特点就是文化依赖性,各国各民族各地区文化习惯不同,表达信息的方式也会不同。所以,本文笔者在前人研究的基础上,利用MATLAB 编程,开展了模拟仿真训练识别语音情感信息的研究,将对在日常教学中提高学生实践能力起到一定的推动作用。
2 支持向量机应用于语音情感识别
支持向量机是由Vapnik 等人提出的一种机器学习的算法,它是建立在统计学习理论和结构风险最小化的基础之上。大量研究表明,支持向量机算法是一种非常有效的学习方法,它能够在高维特征空间得到优化的泛化界的超平面,能够使用核动技术从而避免局部最小,通过间隔和限制支持向量的个数控制容量来防止过拟合。支持向量机在语音情感识别中存在天然的工作优势,适合于小样本数据的训练。
基于支持向量机的语音情感识别流程如图1所示。整体流程分为两个阶段,在模型训练阶段,对于输入计算机的语音信号,经过预处理中的预加重、分帧加窗等操作后,进行特征提取,再使用支持向量机进行分类训练,得到支持向量机分类模型;在模型识别阶段,对于输入待识别的计算机语音信号,经过预处理、特征提取等操作,最后经过模型识别得到最终的识别结果。
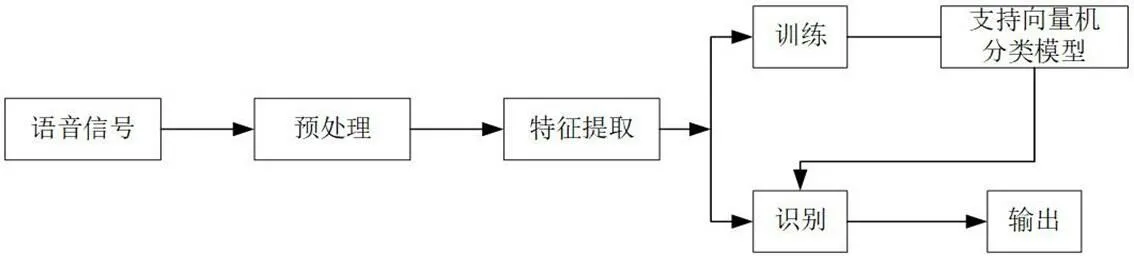
图1:基于支持向量机的语音情感识别流程
在本文中,笔者需要对生气、高兴、中性、悲伤、害怕等五种基本情感进行识别。在模型的训练过程中,我们考虑到有两种训练策略,第一种是采取“一对一”的方法进行模型训练,它的问题很明显,训练的模型比较多。如果需要识别n 种情感,那么就需要建立n(n-1)/2 个模型。第二种是采取“一对多”的方法进行模型训练,它的不足在于对于前期数据的预处理比较繁琐。
3 仿真结果
根据支持向量机分类原理,笔者编写了MATLAB 函数,采用“一对多”的方法,进行语音情感识别。函数定义格式为rate=svmc lassfiction(samples,test),samples、test 是 输 入参数,其中samples 是测试样本数据,test 是测试样本数据;rate 是输出参数,表示五种基本情感的识别率。以下是本文中编程实验的部分核心代码:

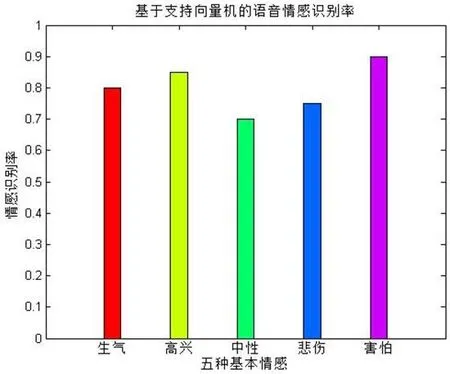
图2:基于支持向量机的语音情感识别率
识别效果如图2所示。
4 结论
本文通过基于支持向量机的语音情感建模,最终得到了其相应的情感识别结果。实验表明,在情感语音数据较少的情况下,笔者采用的方法对于相应的教学实践环节来说还是一个比较可行的方法。
