精准3升4G换机模型
2019-04-26王振陈天池
文/王振 陈天池
1 引言
随着通信技术的发展,4G业务的拓展,改善了未来移动用户质态,然而现在非4G用户升4G的速率趋于平缓,接近饱和,从而挖掘潜在非4G换机用户具有重要意义,能够实现整体市场的4G终端的迁转、渗透。如何细化非4G用户升4G场景,利用大数据手段精准挖掘潜在非4G目标换机用户,拓展4G业务,同时统筹各业务场景对非4G用户、4G用户价值的发展变化,实现非4G潜在目标用户换机的精准挖掘。
2 算法说明
此文基于新业务场景、及模型算法优缺点等,利用随机森林算法对模型算法进行优化。Random Forest(随机森林)是基于众多决策树、构建集成的Bagging集成学习器,同时在训练过程中引入随机特征,改进了决策树算法,即将多个决策树合并在一起,且分别依赖独立的抽取样本集,每棵树具有相同分布。特征选择采用随机方法分裂每个节点,比较不同情况下误差。通过检测内在估计误差、分类能力,决定特征的选取数目。随机产生大量决策树后,测试样品通过每棵树的分类结果经统计后选择最可能的分类结果,包括:
(1)随机样本数据选择(放回抽样)。
(2)随机特征选择。
(3)构建决策树。
(4)随机森林投票(平均)。
其中样本数据的随机选择、待选样本特征的选择更能体现其优势,前者包括放回抽样,构建子数据集;根据子数据集、构建子决策树、输出子结果,通过新输入数据对子决策树的判断结果投票,获得整个输出结果。如图 1所示。
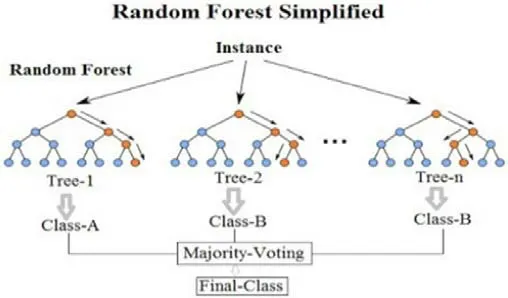
图1:随机森林算法流程图
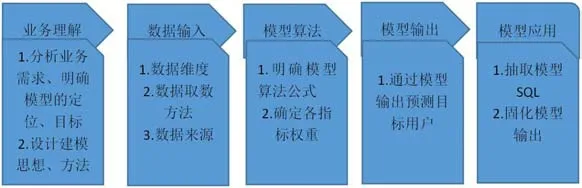
图2:模型流程图
其中随机特征选择即在树的构建中,首先从样本集特征中随机选择部分特征,然后再从此子集中选择最优特征用于划分,此随机性导致随机森林的偏差会有稍微的增加(相比于单棵树),提升了算法多样性,但由于随机森林的平均特性,使得方差减小,模型具有更好效果。随机森林通常基于Gini准则进行分裂节点纯度度量,过程如下:
(1)假设原始训练集为N,用bootstrap法有放回随机抽取k个新样本集,构建k棵分类树,每次未被抽到的样本组成k个袋外数据。
(2)设有m个变量,则每一棵树的每个节点处随机抽取n个变量,然后在n中选取一个最具分类能力的变量,阈值通过检查每一个分类点确定。
(3)每棵树最大限度地生长, 不做任何修剪。
将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别、分类,分类结果按投票多少而定,达到预测、分类目的。相比决策树算法,它是决策树算法的升级、集成,优点如下:
(1)可以并行计算、效率高;
(2)既可处理离散型数据,也可处理连续型数据,无需规范化;
(3)不易产生过拟合,抗噪能力好。
3 模型流程
3.1 业务理解
目前存量3G终端升级为4G时,往往需进行相关终端、套餐等多种升级,不同的产品升级组合对于用户的价值变化都会产生不同影响,需统筹考虑、加以引导,有效提升4G业务量,机卡匹配率,达到如下期望目标:
(1)准确定位3G升4G目标用户。
(2)估算潜在换机的目标用户数,把握市场发展动态。
(3)完成精准换机建模思路、模型设计开发。
利用已有3G升4G换机模型,充分考虑前模型的优缺点,且结合最新的业务场景,优化、丰富数据源特征标签、精细数据预处理、优化模型算法,提升模型性能。整个优化后模型框架包括业务理解、模型输入、模型算法、模型输出及模型应用等部分。如图2所示。
3.2 模型参数输入
建模中,如何获取高质量数据源,对提高模型质量、预测效果有重要影响,决定模型好坏,因此在选取数据源特征标签时,要充分考虑所选特征标签数据对模型的贡献度。
已有模型选取特征标签时,仅仅考虑用户所用终端的一些基本终端信息、所选套餐信息、相关补贴信息等,数据源特征标签有待进一步优化、丰富。随着终端设备性能的提高,使用方式变得多样性,产生一些新的特征标签来刻画用户的使用行为。首先现在用户对于手机终端的使用不仅仅局限于传统的通话、语音、短信等,更多是通过它,满足一些兴趣偏好,例如视频、直播、游戏、购物等互联网偏好;其次人们在考虑更换手机终端时,通常基于性能已不能很好满足自己的使用需求了,包括存储性能、内存性能等硬件指标;最后随着用户的换机频率、更新频率加快,需考虑终端的使用周期,即终端使用天数,终端的平均使用天数等。基于上述考虑,需针对已有数据源特征标签进行完善、优化利用优化的特征标签数据,作为模型输入。由于数据源获取中,常常含有噪声、不完整,甚至不一致的数据,需进行相关预处理,提高数据质量,主要包括:数据变量转换、缺失值处理、坏数据处理、数据归一化等数据预处理后,进入整个模型的核心,即算法部分。综合考虑,我们采用上面已详细介绍的随机森林算法。数据预处理后,并不是所有的特征标签字段都作为模型训练的输入,将利用随机森林特征重要度对数据源众多特征标签进行关联性、重要性排序,选取重要性靠前、贡献度大的特征标签作为模型输入,继而提高模型训练的效果。
以概率的形式给出,例如原始价值量、视频偏好、购物偏好、总流量对模型的贡献度较高,均超过10%,其次游戏偏好、套餐流量赠送量均超过5%,从而选取重要性靠前的若干Top特征标签作为模型输入,少用或舍弃重要性靠后的特征标签。
3.3 模型算法
基于现有各分类算法的特点,采用随机森林算法作为模型算法、进行目标用户预测,整个随机森林算法的伪代码如下所示:
(1) For b=1 to B:
(a) Draw a bootstrap sample Z*of size N from the training data.
(b) Grow a random_forest tree Tbto the bootstrapped data by cursively repeating the following steps for each terminal node of the tree, until the minimum node size nminis reached.
i. Select m variable at random from the pvariables.
ii. Pick the best variable/ split-point among the m
iii. Split the node into two daughter nodes.
(2) Output the ensemble of trees
To make a prediction at a new point x:
整个过程包括数据选择、模型训练、模型验证、模型测试、模型调优等部分,采用沙箱模式,整个算法及常见算法包已封装,重点关注于数据源、特征标签选取、模型参数调优等,其中这里三个主要参数需调优:
(1)结点规模:随机森林不像决策树,每一棵树叶结点所包含的观察样本数量可能较少,即生成树时,尽可能保持小偏差。
(2)树的数量:根据实践,往往根据实际情况,选择相适应的树的规模。
(3)预测器采样数:一般来说,如果我们一共有D个预测器,那么我们可以在回归任务中使用D/3个预测器数作为采样数,在分类任务中使用D^(1/2)个预测器作为抽样。
3.4 模型评价
模型训练、固化完毕,如何评价模型性能,现有一系列模型评价指标对其进行评判,包括准确率、召回率、F1-Score值,平滑曲线、混淆矩阵等。所谓混淆矩阵即用矩阵中真实的与预测的因变量1的变化,来直观观察模型的质量。通常以关注类为正类,其他类为负类,分类器在测试集上进行正确与否的预测,4种情况总数分别记作:Tp—将正类预测为正类、Fn—将正类预测为负类、Fp—将负类预测为正类、Tn—将负类预测为负类。
从而可得出模型另外的一系列评价指标,准确率p、召回率R、F1-Score值分别定义如下:

下面为特征标签优化前后,模型混淆矩阵的优劣程度对比,从而得出特征标签、算法优化后模型的准确率、召回率、F1值分别为80%、26%、19.7%,具有明显提高。
由于正负样本比例问题、模型参数的优化等综合考虑,我们采用正负样本比例1:5的进行模型固化,全量预测4月3G用户在未来5、6、7三个月换机情况,818076万总量目标用户7月换机情况,如下表3.5所示,预测的换机目标用户数为13220,进一步查看8月真实3G换4G成功的用户为2258,真实换机成功率为17%左右,模型优化明显。
相比已有模型,模型质量、效果有所提高,但也存在着不足,具有进一步提升空间,将来将基于下面内容对模型进一步优化:
(1)目前特征标签仅基于终端基本信息、互联网偏好、补贴基本信息,套餐使用情况等方面进行优化,尚有不足,后期可以基于时间跨度等方面构造新的特征标签。
(2)数据源正负样本比例近1:6.3,虽采用了采样方式来规避样本不均衡问题,但也存在诸多弊端,如何平衡正负样本比例,是后期优化的一个方向。
(3)此次模型采用了随机森林算法,后期可以考虑算法融合、或引入新算法,对模型进一步优化。
4 总结
综上所述,分析已有模型的优劣,进行相应处理,包括数据源特征标签优化、数据源预处理、模型算法的选择、模型参数优化等方面,提升模型效果,提高目标用户换机成功率。此过程中,我们通过大数据、数据挖掘手段精准挖掘潜在的非4G换机目标用户,并分析潜在目标用户的终端偏好、渠道触点偏好、终端信息偏好、互联网兴趣偏好、套餐业务偏好等,针对性开展终端推介和渠道引导,指导用户换机、提升潜在目标用户换机成功率,拓展业务,达到智慧营销目的。
