基于Lambda架构的医学图书推荐系统设计与实现*
2019-04-25邱煜炎吴福生
邱煜炎 吴福生
(蚌埠医学院图文信息中心 蚌埠233000)
1 引言
大数据环境下医学文献数字化迅速推进,文献总量急剧增长[1]。为满足读者对文献高效查找、精准推荐和快速响应的需求,专业化推荐系统应运而生。推荐系统[2]帮助用户评估其所有未看过的产品,通过分析用户的基本信息、兴趣爱好和历史行为主动推荐符合喜好的项目。目前推荐系统已在电子商务、电影、音乐网站领域取得显著成绩。
2 相关研究情况
传统单机环境下的推荐系统无法满足大数据规模资源的存储与计算需求,Hadoop平台能够处理海量数据。对于推荐内容的计算,大量的学者将推荐系统和Hadoop进行集成,肖强[3]等改进传统的协同过滤算法,使之适应Hadoop平台上的分布式计算;李文海[4]等基于MapReduce模型实现关联规则算法,构建分布式电子商务系统;奉国和[5]等采用Hadoop平台以及Mahout引擎技术改进协同过滤算法,提高推荐系统的准确率。Hadoop平台解决海量数据计算的问题,但其还存在诸多缺陷,最主要的是MapReduce[6]计算模型延迟过高,无法满足实时、快速计算的需求,因而只适用于离线批处理的应用场景。Spark[7]在设计上充分吸收借鉴MapReduce的精髓并加以改进,同时采用先进的DAG执行引擎,以支持循环数据流与内存计算,因此在性能上比MapReduce有大幅度提升,从而迅速获得学术界的广泛关注。何胜[8]等提出一种以文献“混合关联”为主要内容的图书馆文献推荐方案及实现算法,基于Spark技术开展实证研究,优化图书馆文献推荐效果和提高统计计算性能。Lambda[9]架构由Storm项目发起人Nathan Marz提出,集成Hadoop、Kafka、Storm、Spark、HBase、Redias等各类大数据[10]组件,提供混合平台。Lambda架构,见图1。其具有高容错、低延时和可扩展的特点。本研究利用Lambda架构技术特点,融合历史数据离线计算、分布式日志采集等技术构建推荐数据及时反馈的医学图书推荐系统。实验结果表明该系统具有高可靠性和稳定性,能够满足大数据下低成本、快速响应和精准推荐的需求。
3 系统架构设计
3.1 架构
大数据环境下图书馆网站存在大量的读者隐式行为(如点击、搜索、浏览记录等),不同服务的应用接口对应不同服务器,因此系统日志文件分散存放在各个服务器上。传统Hadoop平台无法有效汇总隐式行为日志并做到及时响应。本研究基于Lambda架构充分收集读者隐式行为数据,结合显式数据(如读者借阅、预约记录)构建混合模型矩阵以解决数据稀疏问题,离线计算采用ALS推荐算法,在传统离线推荐模型基础上实时分析用户行为,以反馈最适合当前用户的推荐列表。基于Lambda架构的医学图书推荐系统架构,见图2。
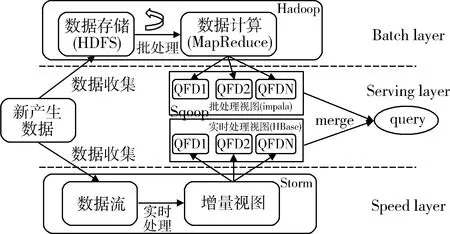
图1 Lambda架构
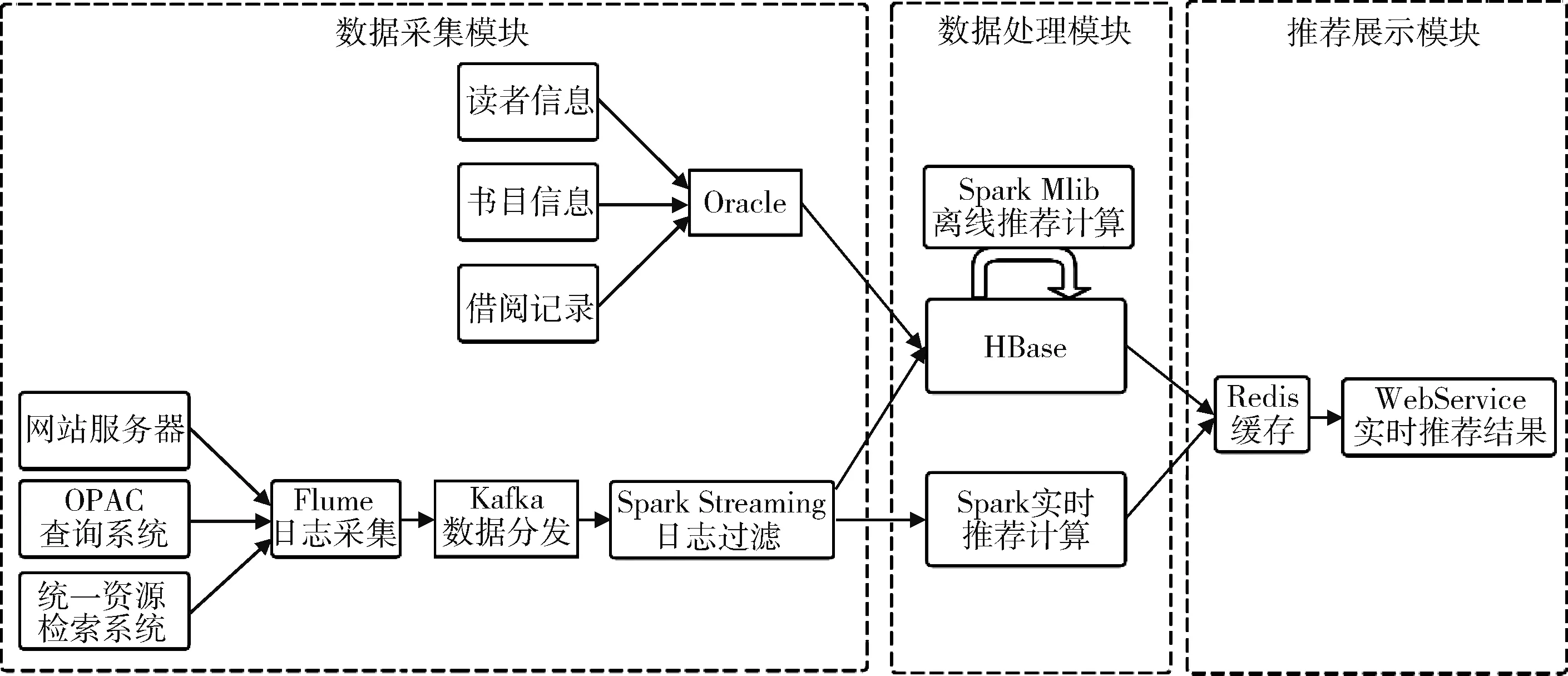
图2 基于Lambda架构的医学专业文献推荐系统架构
3.2 模块
Lambda架构分为3大模块:数据采集、数据处理和推荐展示。数据采集包括两部分:关系型数据库和日志采集系统。关系型数据库通过图书馆管理软件记录读者和书目的基本信息以及读者借阅记录信息。日志采集系统利用Flume,通过Kafka集群的消息分发中间件实现日志数据的统一下发。数据处理模块分为离线处理和在线处理两部分。推荐展示模块将所有用户推荐列表写入Redis缓存系统中,缓解图书馆网站系统压力。在离线处理前,将关系型数据库数据通过Sqoop工具加载到HBase数据库中进行离线推荐模型训练。本设计首先利用用户基本信息,如专业系部和书目信息,还用Spark计算模型进行主题提取,构建基于内容的用户与书目相似度矩阵,融合Spark Mlib机器学习库提供的ALS算法库[11],建立基于文献资源内容过滤及相似用户协同过滤的离线推荐模型。
4 关键技术
4.1 分布式数据收集
推荐系统需要将各种数据收集到一个中央化的存储系统中,有利于进行集中式的数据处理、统计分析与数据共享。而用户行为是多样化的,包括基本属性数据、访问日志、搜索记录、收藏日志、文献信息等。其收集难点在于数据分散在各个离散设备上,保存于各种传统的存储设备与数据库系统中。针对传统的关系型数据库信息,可以利用Hadoop生态系统中Sqoop组件,将数据导入到分布式数据库HBase中,实现传统数据库与Hadoop同步。而针对基于浏览器访问的日志数据,可以借助分布式日志采集框架Flume进行数据收集。Flume系统植入在应用网关处的日志监控可以实时监控日志文件变化,根据偏移量,读取来自联机公共目录查询系统(Online Public Access Catalogue,OPAC)以及统一资源检索系统的最新日志信息,然后将日志记录输出到HBase数据库中。
4.2 离线计算推荐模型
利用读者行为分析其对每本图书的兴趣程度,通过Lambda平台采集数据,涉及行为包括搜索、点击、预约、正常借阅、盲目借阅、续借、超期借阅。笔者参考相关文献,结合医学专业特点,构建读者图书兴趣模型。针对读者各种行为做如下评分:在关键词搜索列表中,如果对某一图书项目进行点击则表示读者对该图书兴趣为正分,加1分。如果点击后并进行在线预约则表示更强的兴趣度,加2分。研究发现[12-13]读者对某种图书兴趣度与借阅时间有关,见图3。借阅时间低于一定阈值(小于3天,α值为2天)则表示读者对该图书实质上并不感兴趣,借阅该图书的行为可能属于盲目借阅,减2分。读者在一定期限(3~29天,β值为30天)内正常借阅,则表示读者兴趣为正分,加2分。读者续借某本书则表示读者借阅兴趣达到饱和,加2分。期借阅虽然达到时间饱和度,但并不代表读者很感兴趣,超期借阅时间与兴趣也成反向趋势,超期时间在1个借阅周期内(β值为30天)为短期超期,减1分,此后超期两个β值后为长期超期,减2分。此外整时间到期归还的借阅历史记录(1个β天数)可以假设读者对图书的兴趣成相反方向,减1分。用户行为评分影响,见表1。
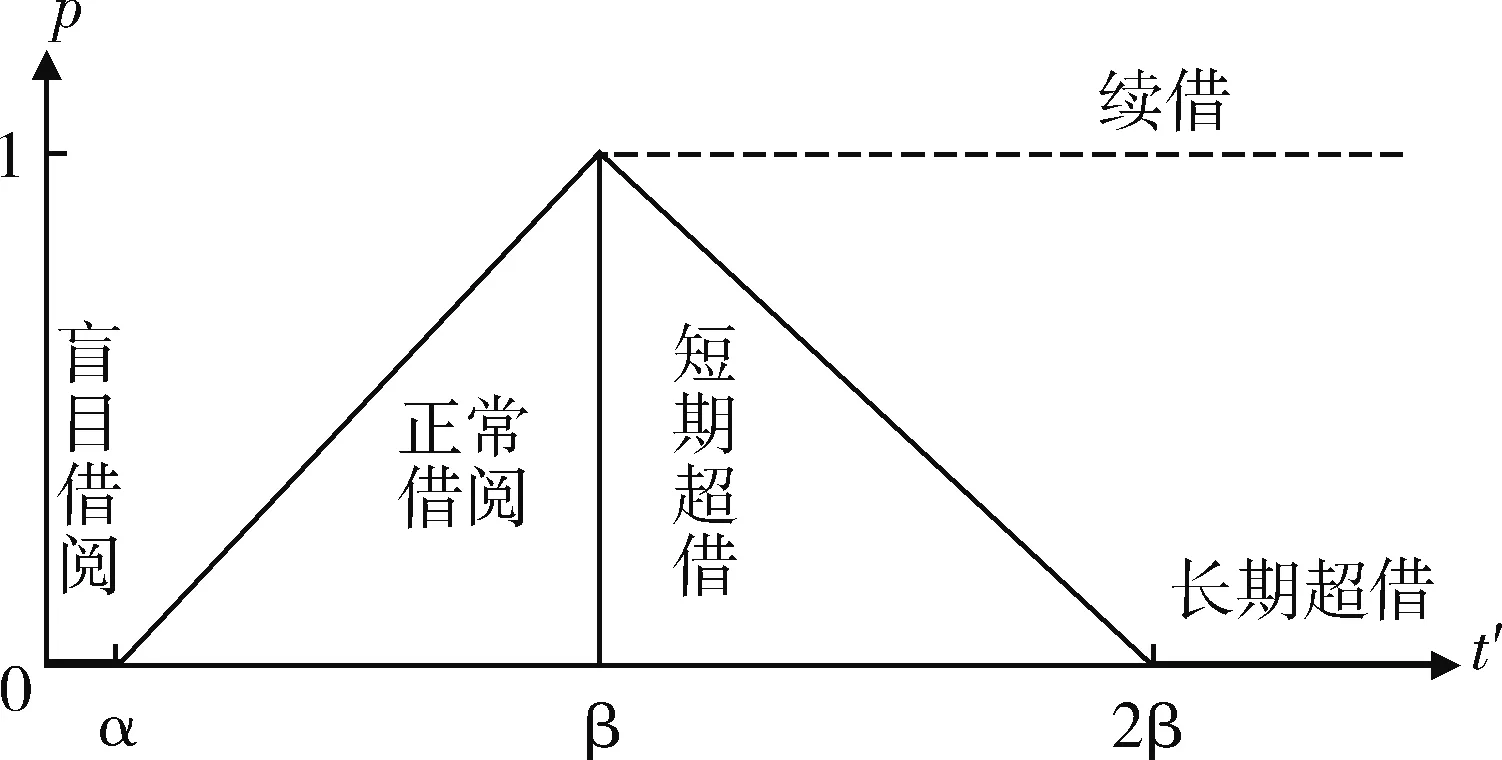
图3 读者兴趣度与借阅时间关系
表1 用户行为评分影响
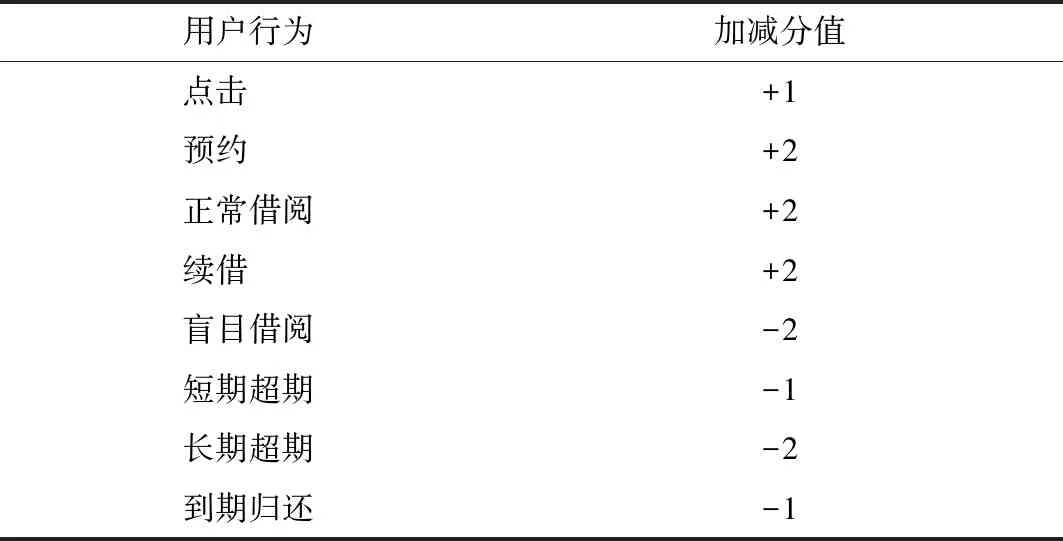
用户行为加减分值点击 +1预约 +2正常借阅+2续借 +2盲目借阅-2短期超期-1长期超期-2到期归还-1
初始化评分值为5分,根据表1,构建读者图书评分矩阵,得到读者-图书-评分3元组作为离线推荐模型数据源,利用Spark Mlib机器学习库提供的交替最小二乘ALS[14]推荐算法进行建模。交替最小二乘ALS是求解隐语义模型隐因子参数的优化算法,隐语义模型是奇异值分解方法的一种,具有较好的理论基础,优化一个设定的指标建立最优模型,其核心思想是通过隐含特征联系用户兴趣和物品,利用降维的方法解决评分矩阵稀疏的问题。对于R(m×n)的矩阵,ALS旨在找到两个低维矩阵X(m×k)和矩阵Y(n×k),来近似逼近R(m×n),即:
其中R(m×n)代表用户对商品的评分矩阵,X(m×k)代表用户对隐含特征的偏好矩阵,Y(n×k)表示物品所包含隐含特征的矩阵,T表示矩阵Y的转置。对于矩阵X、Y的计算采用最优化目标损失函数,目标损失函数用均方根误差(Root Mean Square Error,RMSE)定义,如下所示:
上式中的 λ‖xu‖2+ λ‖yi‖2是用来防止过拟合的正则化项,通过交替最小二乘算法优化目标损失函数,算法如下:初始化随机矩阵Q中的元素值;将Q矩阵当做已知的,直接用线性代数方法求得矩阵P;得到矩阵P后,将P当做已知参数,再返回求解矩阵Q;上述两个过程交替进行,一直到误差收敛到可以接受为止。研究发现[15]在不是很稀疏的数据集合上,交替最小二乘通常比随机梯度下降要更快的得到结果。设置ALS迭代次数以及相关参数,ALS算法会对读者-图书评分矩阵进行分解,利用隐语义进行表达,计算出隐式因子,填补读者与书目的预测评分,然后训练离线推荐模型。
4.3 实时推荐模型
首先利用Spark Streaming技术将Kafka集群推送的日志信息过滤出日志点击流,从中抽取读者产生行为对应的图书ID和用户ID。然后根据离线推荐模型进行图书相似度排序,与离线模型进行混合处理,重排序,使得图书馆在线网站可以感知到用户最新行为,提升推荐系统的准确率。笔者随机抽取临床医学专业读者登录图书查询系统,以“麻醉学”作为搜索关键词,显示结果界面左边是OPAC系统根据检索词通过图书管理系统展示的麻醉学图书,右边是实时推荐结果,根据系统设定,共计显示10条推荐结果,其中前5条显示与麻醉学相似的图书,如“麻醉意外”,“麻醉并发症”;后5条是根据该读者历史行为显示离线推荐结果,如“临床诊疗学”,“临床医学多用辞典”等。
5 实验分析与结果
5.1 数据来源
以蚌埠医学院2014年6月-2017年12月之间所有医学类(中图法R类)图书借阅记录作为实验数据,包含图书86 022本,读者12 030人,1 806 212次借阅服务,其中借阅564 399 次、续借 149 507 次、预约102 505次。
5.2 实验环境
基于Lambda架构的医学图书推荐系统搭建6台Linux服务器,版本CentOS6.5;每台服务器配置8核CPU,16GB内存和1TB硬盘。其中3台服务器用来搭建Lambda平台,另外3台服务器分别用来进行数据采集、数据缓存以及前端展示。软件配置,见表2。
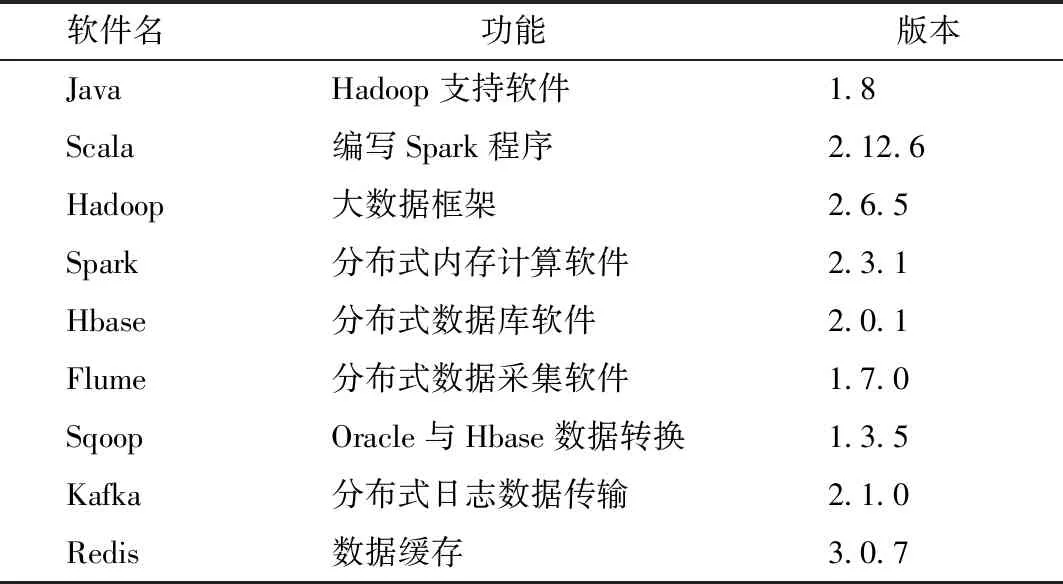
表2 Lambda架构软件配置
5.3 结果
为验证兴趣度模型以及推荐系统的有效性,邀请10位不同专业的读者进行评价。利用推荐系统结合读者在线行为,为每人推荐20本书,对推荐结果进行打分。采用信息检索领域广泛使用的查准率来评价实验效果。评估结果,见表3。结果显示10位读者评价查准率差别很大,均值为44.4%。虽然系统初始设置为每位读者推荐20本专业图书,但由于读者专业、借阅量、借阅行为等不同,实际推荐的数量也不同。通过表3可以看出借阅数量对推荐效果影响很大。但是随着读者借阅图书的数量不断增加,推荐效果也越来越好。值得注意的是读者专业对推荐结果影响较大,如临床医学本科生对结果评价明显高于其他专业,说明临床专业学生数量多,借阅行为数据量与推荐准确度成正相关关系。此外研究生由于借阅量相对本科生大,借阅目的性相对较强,准确率普遍较高。
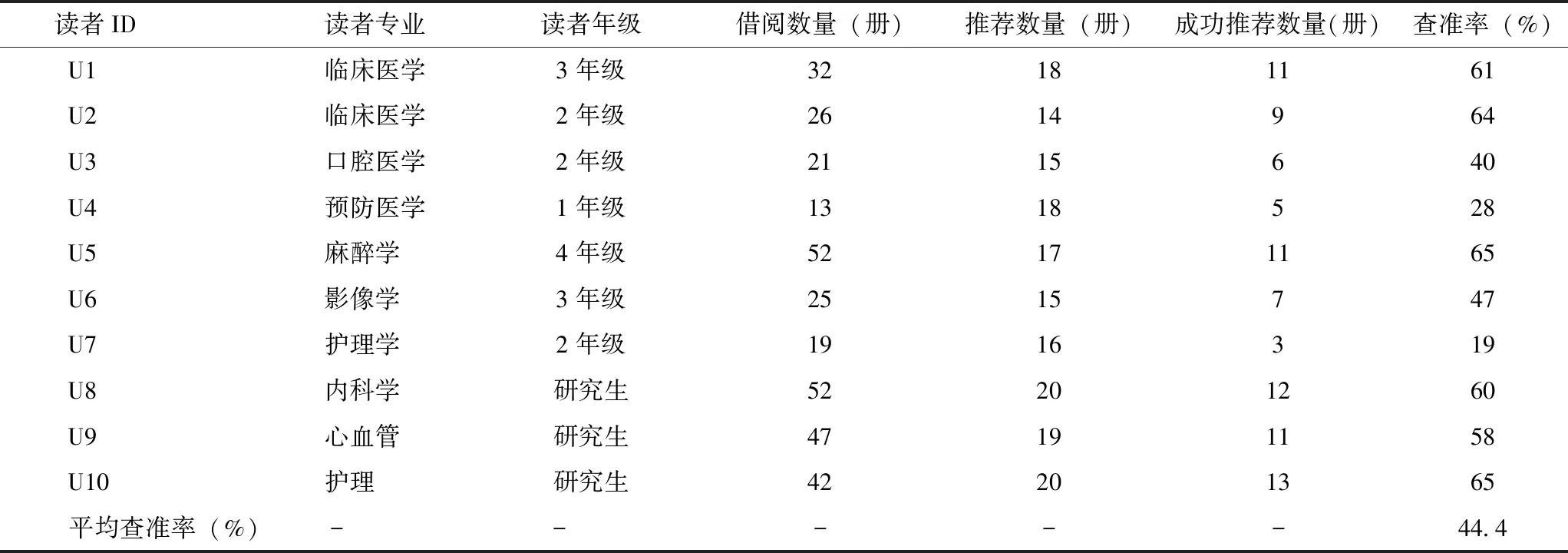
表3 推荐系统评估结果
6 结语
本研究设计和实现大数据环境下基于Lambda架构的医学图书推荐系统,提出基于读者行为的评分模型,将隐式行为数据应用到评分模型中,优化模型结构。实验证明在充分采集用户行为数据后,推荐系统的准确率和召回率有明显提升。鉴于Lambda架构获取的数据具有数据量大、实时性强、多样性的优势,下一步将引入书本信息及用户基本信息的特征,设计多模型数据处理方式,进一步提升推荐效果。
