采用MPSO优化SVR的短时交通流预测方法
2019-04-19晏雨婵武奇生
晏雨婵,武奇生,白 璘,席 维
(长安大学 电子与控制学院,陕西 西安 710064)
1 概 述
近年来,随着国民经济的迅速增长,私人拥有汽车的数量逐渐增加,伴随而来的是频繁的交通事故以及严重的交通拥堵和环境污染问题。智能交通系统(intelligent transportation systems,ITS)[1]中的交通诱导和控制是解决这一系列问题的有效方法之一。
智能交通系统是从系统的观点出发,把车辆、道路、人综合起来,将先进的信息技术、数据通讯传输技术、电子控制技术以及计算机处理技术等有效地综合运用于整个交通管理体系,从而建立起来的一种在大范围内、全方位发挥作用的实时、准确、高效的交通综合管理系统。交通流预测是智能交通系统研究及应用中的基础和关键。
交通流预测是指[2]在某一区域根据当前采集的交通流数据按照一定的预测模型对未来的交通流做出估计,短时交通流预测是指对未来15分钟以内的交通流量做出的预测。如何实时、准确地做出交通流预测是实行该方法的一个关键性问题。
目前已有的短时交通流预测的方法主要分为以下几类[3]:
(1)基于统计的线性理论模型,主要包括线性统计回归、时间序列预测方法、卡尔曼滤波预测方法[4]。这些模型复杂度低、运算简单、操作也较简单,对于不确定性、随机性强的交通流特征来说,无法满足预测结果的准确性要求;
(2)非线性理论模型,主要包括基于突变理论的预测方法、小波分析预测方法、基于混沌预测方法。这些方法虽然很好地解决了交通流特征的非线性,但同时需要大量的数据样本来解决模型的复杂性;
(3)人工智能模型[5],主要包括神经网络预测方法、非参数回归预测方法、SVR预测方法。神经网络预测方法和SVR预测方法都是通过训练原始数据而形成预测模型,后者较好地解决了“局部极值”和“小样本”等问题;
(4)混合模型,主要是指将上述两种或两种以上的方法相结合形成的预测模型,至于模型之间组合的适应性需要进一步验证。
对于短时交通流预测方法,国内外学者进行了大量的研究。例如,贺国光等分别介绍了基于确定的数学模型的交通流预测方法,通过神经网络改进了卡尔曼滤波预测的模型[6]。傅贵等通过引入核函数把短时交通流的预测问题转化为高维空间中的线性回归问题,提出了基于支持向量回归机的短时交通流预测模型,获得了优于卡尔曼滤波方法的预测效果[7]。李颖宏等考虑了交通流的时间空间性,提出了基于组合模型的交通流预测[8]。罗向龙等利用差分去除交通流数据的趋势向,用深度信念网络模型进行交通流特征学习,提出了基于深度信念网络模型与支持向量回归相结合的短时交通流预测模型[9]。Hong等提出了连续蚁群算法SVR城市交通流量预测模型,该模型预测精度优于自回归积分滑动平均时间序列模型[10]。Sun等提出了一种基于多维尺度变换和SVM组合的交通流量预测模型,该模型提升了预测的稳定性[11]。Lv等提出了一种基于堆叠自动编码SAE模型的深度学习方法,通过设计贪婪层次无监督学习方法对网络进行预训练,而后通过微调实现模型参数更新,提高交通流预测精度[12]。
支持向量机(support vector machine,SVM)[13]通过寻求结构风险最小化来实现实际风险最小化可以解决分类和回归两种问题,文中采用支持向量回归方法来实现高速公路车流量预测。
支持向量回归模型中的惩罚系数c和核函数参数g对模型的影响非常大,惩罚系数c反映了算法对超出精度ε的样本数据的惩罚程度,其值影响模型的复杂性和稳定性。c过小,对超出精度ε的样本数据惩罚就小,训练误差就会变大;c过大,学习精度相应提高,但模型的泛化能力变差。g过大,容易欠拟合,预测精度随之降低;g过小,容易拟合过于复杂,增加训练时间,同时对样本数量需求增大。所以,选择合适的c、g,对模型的预测精度有很大的提升,目前使用最多的参数选取方法是网格搜索法[14],即通过不断地试凑来获得最佳的参数组合。
文中利用粒子群优化算法在参数寻优方面的优势,通过将标准PSO算法中的定值惯性权重用均匀分布的随机惯性权重代替,使算法中的粒子在搜索后期避免陷入局部最优,通过不断地更新惯性权重,平衡局部搜索和全局搜索能力,设计了一种基于后期随机惯性权重粒子群优化SVR模型,寻找到最佳的SVR模型参数组合,并对国内沪宁高速50108阳澄湖站点的数据进行短时交通流的预测和分析。
2 SVR模型原理
支持向量回归(support vector regression,SVR)的学习策略同支持向量机的原理类似,是通过找到一个回归超平面,让一个集合的所有数据到该平面的距离最近,即间隔最小化,最终转变成为一个凸二次规划问题求解。
假定一组训练数据集:{(xi,yi)|i=1,2,…,m},其中xi∈Rn为交通流的输入变量,yi∈Rn为交通流的输出值,m为给定训练样本的个数。构建回归超平面为:
f(xi)=ωφ(xi)+b
(1)
其中,ω=(ω1,ω2,…,ωM)T为权重向量,M为空间维数;φ(x)为非线性核函数,通过它将训练数据映射到高维空间,解决在低维空间线性不可分的问题;b为偏差项;f(x)为交通流的预测值。
间隔最小化问题可转化为求‖ω‖的最小值问题,SVR的目的是寻找与真实交通流量值相差不超过ε的f(xi),模型可表示为:
(2)
(3)
其中,C为惩罚系数。
根据对偶原理,可以将上述约束问题转化成无约束问题,构建Lagrange方程:
(4)
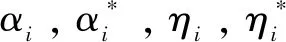
(5)
文中采用的核函数K(xi,x)为径向基(RBF)函数。
SVR预测模型的精度受惩罚系数C以及核宽度系数g两个参数的影响,所以参数在选择上至关重要。
文中通过使用带惯性权重的粒子群算法来优化这两个参数,使SVR模型预测误差尽量小且不过拟合。
3 基于MPSO-SVR的交通流预测模型
3.1 标准PSO算法
粒子群算法(particle swarm optimization,PSO)[15]中每个粒子都具有位置、速度、适应度三种特征,适应度值是所优化的目标函数,表示粒子的优劣。算法通过不断地更新自己的位置、速度、适应度来更新个体极值和群体极值,从而得到最优解。
假定由n个粒子组成的种群为X=(X1,X2,…,Xn),搜索空间设定为D维,那么第i个粒子在搜索空间的位置表示为Xi=(xi1,xi2,…,xiD)T,一个位置就代表一个潜在解,第i个粒子在搜索空间的速度表示为Vi=(Vi1,Vi2,…,ViD)T。
那么,第i个粒子在迭代k+1次的速度更新为:
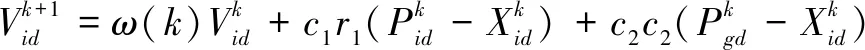
(6)
第i个粒子在迭代k+1次的位置更新为:
(7)
其中,c1、c2分别为PSO局部、全局搜索能力,即加速因子;r1、r2为分布于[0,1]之间的随机数;k为当前迭代次数;ω(k)是惯性权重,是一个分布于[0,1.4]之间的常数;d=1,2,…,D,i=1,2,…,n;Pi=(Pi1,Pi2,…,PiD)T为种群的个体极值,即根据个体位置计算的适应度值的最优位置;Pg=(Pg1,Pg2,…,PgD)T为种群的群体极值,即根据所有粒子位置计算的适应度的最优位置。为了防止粒子会盲目的搜索,将位置和速度均限制到[-Xmax,Xmax]区间中。
个体极值与群体极值的更新由式8确定:
(8)
3.2 基于MPSO-SVR的交通流预测模型
由于惯性权重ω是一个可控制的参数,且ω表征的是粒子继承先前的速度的能力,若算法取较大的ω值,这样粒子有更好的全局搜索能力,却不利于获得精确解;若取较小的ω值,粒子具有更好的局部搜索能力,但是同时会导致收敛速度减慢且容易陷入“局部最优”。为了平衡这两种搜索能力,提高PSO算法的精确度以及寻优能力,文中在粒子搜索的后期使用(0.4,0.7)均匀分布的随机惯性权重来替代标准PSO中为定值的惯性权重。这种引入后期随机惯性权重的粒子群算法简称MPSO,相应的惯性权重更新表达式改变如下:
ω(k)=
(9)
其中,ω(k)为线性递减惯性权重;ωstart为初始惯性权重;ωend为迭代至最大次数时的惯性权重;Tmax为最大迭代数;k为当前迭代数。
随着迭代数的不断增加,惯性权重也不断地更新以适应粒子速度的更新,在算法搜索后期可以获得较大的ω,从而跳出局部极值。文中提出的MPSO-SVR算法是指通过MPSO的寻优能力来对SVR模型中的参数c、g进行寻优来不断地训练SVR模型,MPSO算法对高维函数的优化能力较强,所以对SVR中的高维核函数的参数拥有较好的优化能力,从而达到对短时交通流的准确预测。
应用到交通流预测中去优化支持向量回归中的两个参数,不仅提高了参数寻优的能力,而且更好地平衡了算法全局和局部的搜索能力,同时缩短了预测用时。
MPSO-SVR的交通流预测流程如图1所示。
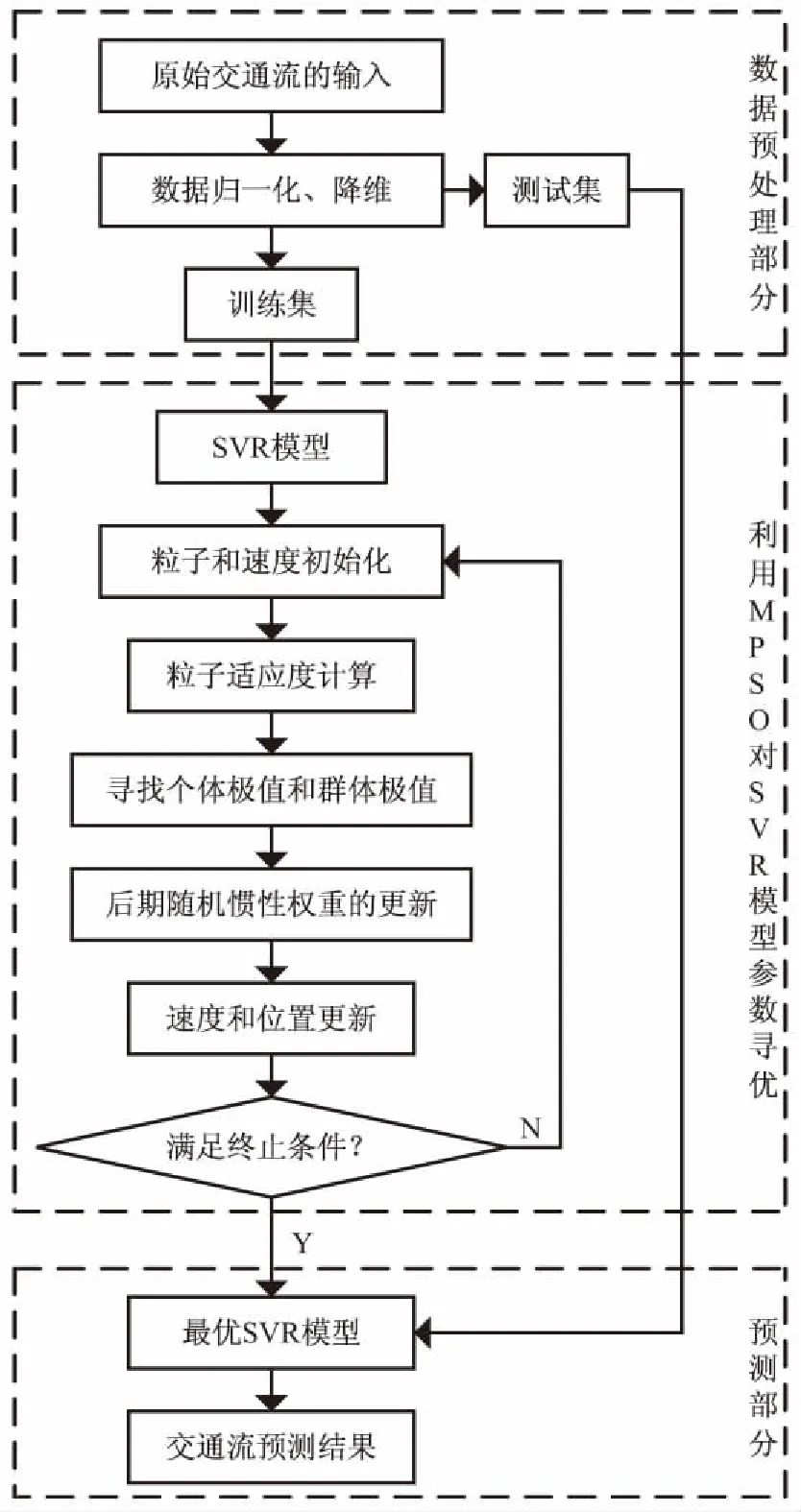
图1 MPSO-SVR模型交通流预测流程
4 实验分析
4.1 数据来源及预处理
选取沪宁高速50108阳澄湖站点出口的交通流量数据进行实验分析,沪宁高速原始交通流如图2所示。选取的时间为2015年8月1日到2015年8月30日,数据采样周期为1h,即一天为24个数据点。
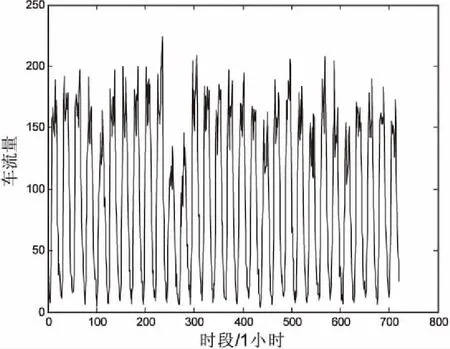
图2 沪宁高速原始交通流量
根据预测模型的要求,选取两类样本集,第一类是训练样本,用来训练SVR模型,通过MPSO不断地对其进行参数寻优,训练出最优的预测模型;第二类是测试样本,用来检验训练完成的模型是否有较高的预测能力。其中前20天的交通流作为SVR预测模型的训练数据,最后3天的交通流作为SVR模型的测试数据。总共有480个训练数据,240个测试数据。
由图2可以看出,交通流不是很平滑,有的数据比较突出,如果直接用于模型训练,会增加训练时间,导致收敛速度缓慢甚至无法收敛。为了解决这一问题,在训练模型之前首先对原始交通流数据进行归一化预处理,将所有数据限制在一定区间内,不仅缩短了运算时间,也提高了运算的规范度。
文中采用的是基于极值的归一化,将数据归一化到[0,1]之间,公式如下:
(10)
其中,Xmin、Xmax为训练样本的最小值、最大值。
4.2 参数选择
设置PSO算法和MPSO算法的最大种群数量N=10;最大迭代数量Tmax=100;加速因子c1=1.5、c2=1.7;初始惯性权重ωstart=0.9,迭代至最大的次数时的惯性权重ωend=1.4;SVR模型中参数c的取值范围为[0.1,100];参数g的取值为[0.01,1 000]。两种算法的适应度曲线如图3所示。
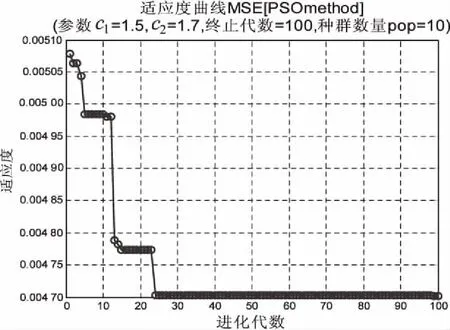
(a)PSO-SVR模型适应度曲线
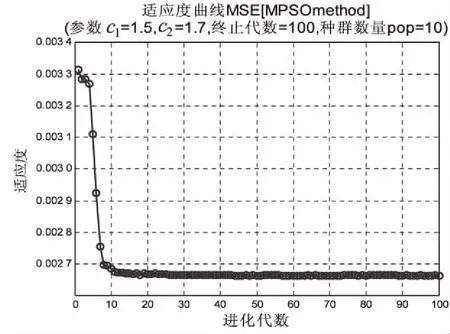
(b)MPSO-SVR模型适应度曲线 图3 适应度曲线
可以看出不加惯性权重的PSO算法在进化代数为5时,陷入了局部最优,在之后也不断陷入局部最优,最终在23次进化稳定在0.004 71;而MPSO算法在进化初期就具有较大的斜率,并且在12次进化时趋于稳定,稳定在0.002 68。可见MPSO算法寻优速度快,且不易陷入局部最优,总体性能优于PSO算法。
4.3 预测结果及精度分析
为了进一步验证MPSO-SVR模型的性能,通过对PSO-SVR模型进行交通流预测与提出的方法进行对比。图4、5分别是PSO-SVR模型、MPSO-SVR模型对沪宁高速50108阳澄湖站点出口车流量的预测结果和相应测试集的残差图。
由图4、5可以直观地看出,PSO-SVR模型在训练数据上表现较好,但是由于算法本身在参数寻优时容易陷入局部最优,以至于搜索出的SVR模型的参数不是很好,在测试数据上还是表现欠佳,一些峰值没有完全拟合出来,尤其是在沪宁高速测试数据后四天峰值预测较差,误差较大;MPSO-SVR通过引入了后期随机惯性权重很好地解决了这一问题,无论是训练还是测试数据都和实际交通流基本完全拟合,并且从MSE误差直方图中可以看出MPSO-SVR预测方法的误差波动最小,说明文中设计的预测方法更加平稳,泛化能力更强。
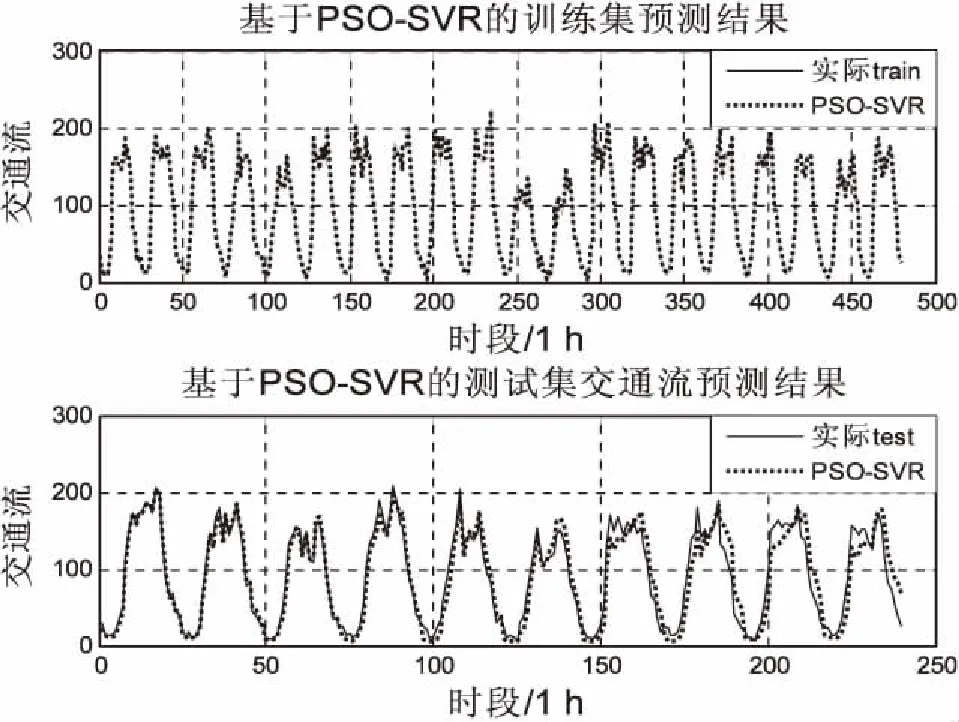
(a)训练集和测试集的交通流预测图
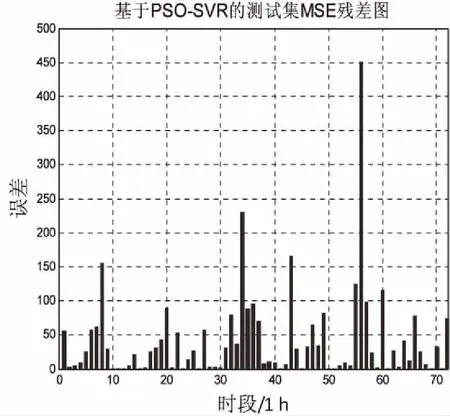
(b)测试集MSE残差图 图4 PSO-SVR模型交通流预测结果(沪宁高速)
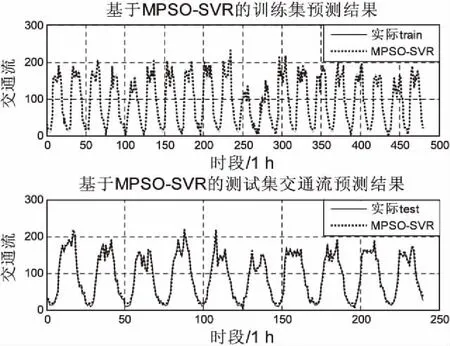
(a)训练集和测试集的交通流预测图
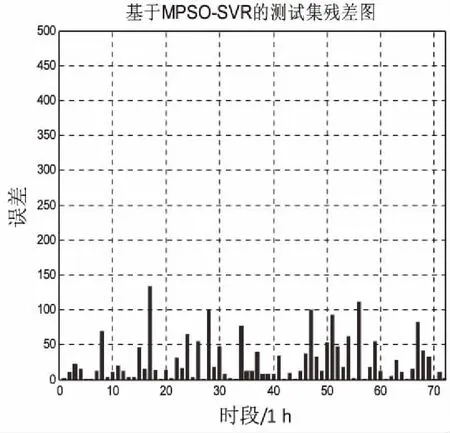
(b)测试集MSE残差图 图5 MPSO-SVR模型交通流预测结果(沪宁高速)
为了更进一步体现各种预测模型预测性能的优劣,选取均方误差(mean square error,MSE)和平均绝对百分比误差(mean absolute percent error,MAPE)作为评价指标,公式如下:
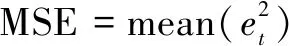
(11)
MAPE=mean(|pt|)
(12)
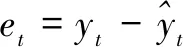
MPSO-SVR模型与其他模型的性能比较以及耗时见表1。
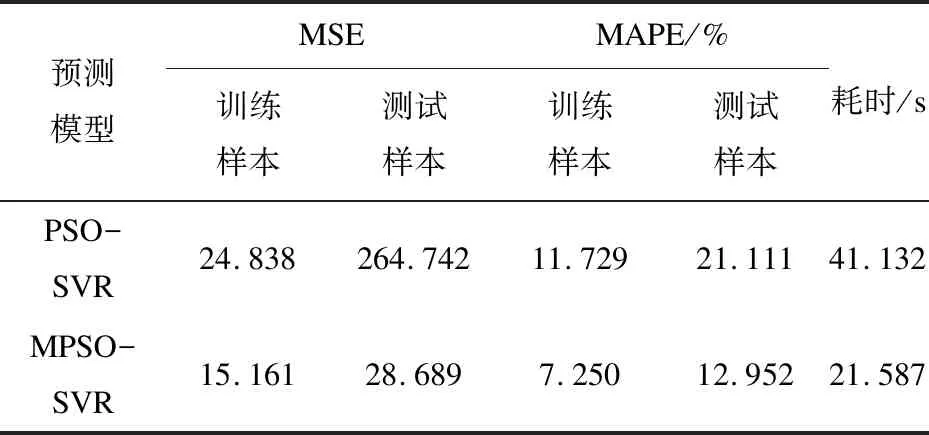
表1 MPSO-SVR模型与PSO-SVR模型的性能对比
可见,MPSO-SVR预测模型的性能指标和耗时均优于PSO-SVR预测模型。文中提出的方法的预测均方误差相对于PSO-SVR模型降低了236,耗时分别缩短了25.55 s,预测精度有了明显提高。
5 结束语
在粒子群优化算法的基础上,用均匀分布的随机惯性权重代替了原算法中不变的惯性权重,提出了一种后期随机惯性权重粒子群优化SVR模型,通过不断更新惯性权重来更新粒子的位置,使算法在搜索后期能够获得较大的ω值,避免了陷入局部最优,从而找到SVR模型的最优参数组合。通过对沪宁高速交通流量进行预测实验,并且与PSO-SVR预测方法进行对比,表明MPSO-SVR预测方法在训练、测试数据上均能良好拟合,误差波动幅度较小,稳定性更强,且MSE和MAPE的值分别为28.689和12.952%,在用时最短的情况下,预测精度达到最高。
