基于聚类算法的电量大数据分析
2019-04-17向翰丞钱瑞琦
李 昂,向翰丞,钱瑞琦,张 蕾
(1.陕西理工大学 电气工程学院,陕西 汉中 723000;2.陕西省地方电力(集团)有限公司 汉中供电分公司,陕西 汉中 723000)
0 引 言
电网公司经过数十年的积累,已储存了海量的历史数据[1]。伴随着信息化技术的高速发展和信息量的迅猛增长,电力企业开始走向信息化管理道路[2]。为此,电网公司先后建立了SG186与GIS系统来存储与展示数据[3-4]。然而,这些信息只是存储在服务器中,并没有得到有效的综合利用。文献[5]中提到,如何整理有用信息,从历史数据中提取有用的价值,是现阶段的发展方向。本文的研究内容是如探索何从历史用电量数据中找出用户潜在的关联性。具体地,通过K-means算法对用户进行聚类分析,提供良好的分类依据,实现对用户电量信息的分类统计,从而提高电量预测精确度。需要注意,同类别用户的用电量情况较为接近,不同类别用户的用电量情况相差较大。
1 数据源
本文使用的数据源是某市部分用户的用电量信息,注意包含的信息字段有表箱名称、户号、采集时间和用电量[6-7]等。
居民用电以表箱为一级单位,表箱上连接多个用户,而每户有唯一的户号。采集每月一次,对应的用电量即该用户的每月用电量。原数据中的采集时间为2017年4月至7月共四个月。该数据有表箱1 572个,连接的用户有12 573户,4个月的数据用电量信息共50 292条。
在分析收集的数据前,首先要明确数据类型、规模,初步理解数据,同时要对数据中的“噪声”进行处理。电量信息在采集和统计的过程中,会存在诸如电量数据缺失、名称不一致、电量异常等情况。由于本文要对用户进行聚类分析,不宜填充或删除大量数据,否则会导致聚类结果的不准确或不具有代表性。所以,对于缺失1~2个月用电量数据信息的用户采取均值或中位数填充法,而缺失更多信息的用户将直接剔除;名称不一致的情况,需要半自动校验半人工方式找出可能存在的问题,并把信息最终一致化;对于电量异常的情况,将采用如图1所示的箱线图法,对月用电量出现异常的用户视具体情况用均值替代或直接剔除。
如图1所示,箱线图有n个数据,第一四分位数Q1所在位置为(n+1)/4,第二四分位数即中位数Q2所在位置为2(n+1)/4,第三四分位数Q3所在位置为4(n+1)/4。此时,令IQR=Q3-Q1,则上边界位置为Q3+1.5IQR,下边界位置为Q1-1.5IQR。确定好上下界限的位置,按位置查找对应数值,即可得到上下界限,其中超出界限的即为异常数据值。
图2为本文选用数据源的箱线图,上下边界分别为377和0。经统计,超出上下界限的数据有3 815个,涉及956个表箱上的1 496户;3 781个为用电量较高的用户,不属于异常数据;34个数据较其相邻月份用电量增幅达60%以上,可能存在统计错误的情况,需以相邻月均值替换该数据。
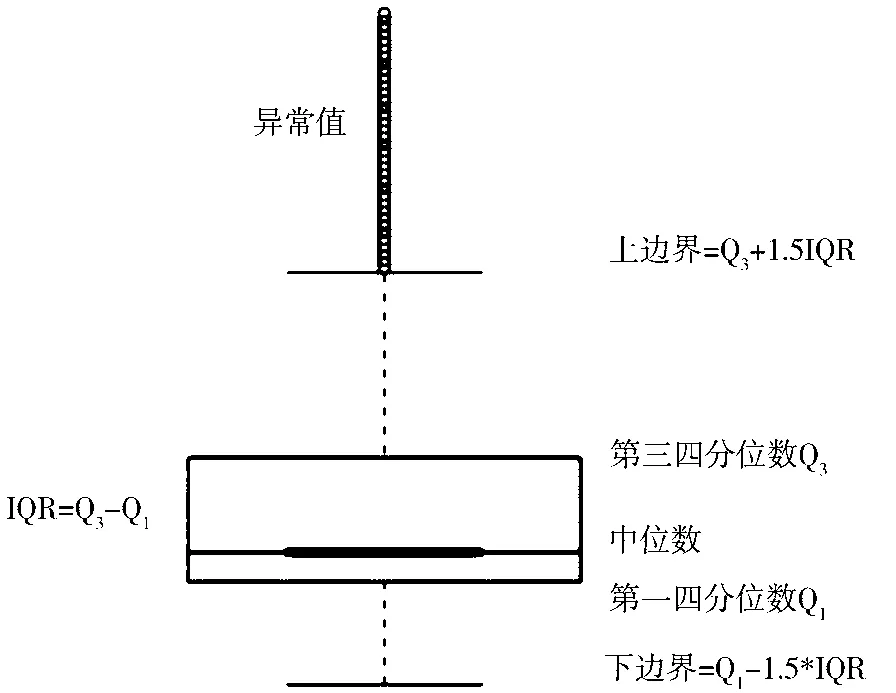
图1 箱线图法
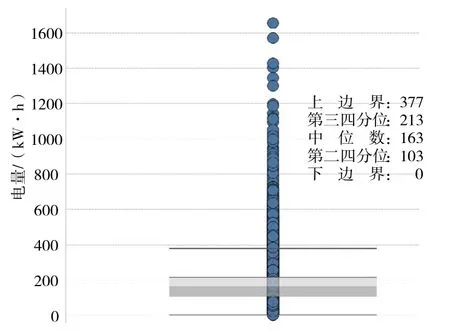
图2 数据源箱线图
2 聚类分析
2.1 K-means算法
本文采用K-Means算法对用户进行聚类。算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使同一个聚类中的样本相似度较高,而不同聚类中的样本相似度较小。
K-Means模型一般采用平方误差准则,定义为:
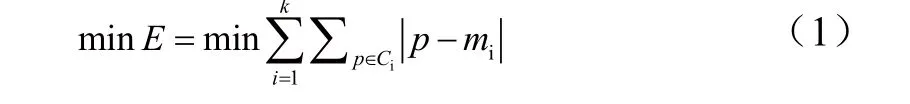
这里E是数据集中所有样本的平方误差的综合;p是空间中的点,表示每月的用电量;mi是聚类Ci的平均值,即同类别的月用电量平均值。该准则使生成的聚类结果尽可能紧凑和独立。
K-Means算法中,对于样本点属于哪一类,是依据该点到类质心的距离确定的。样本点会被划分到距离最近的一类中,距离函数采用欧氏距离:

其中,xi是样本x的第i个变量值,yi是类质心y的第i个变量值。
2.2 模型搭建
模型搭建如图3所示,从左往右依次是数据源、替换缺失值、K-means聚类和输出excel四个模块。其中,缺失值并非统计结果的缺失,而是由于某用户上月用电量为0,本月用电量为正数,导致本月的电量变化率无法计算,记为缺失。
计算步骤如下:
(1)训练样本{x1,x2,…,xn}∈Rn,选取k=3个类心;
(2)用式(2)计算其余各点与中心点的距离;
(3)根据距离最近原则,将各点归属于不同类别,
(4)重新计算中心点,
(5)重复步骤(2)~步骤(4),直至类心不再发生变化或变化量小到对分类无影响。

图3 模型流程图
2.3 聚类结果
对本文所使用的数据源,以电量、电量变化量和电量变化率为变量值,按电量的最大值、中间值以及最小值为初始聚类中心,经过64次迭代后,聚类中心内不再变化,终止迭代。初始聚类中心和最终聚类中心,分别如表1和表2所示。
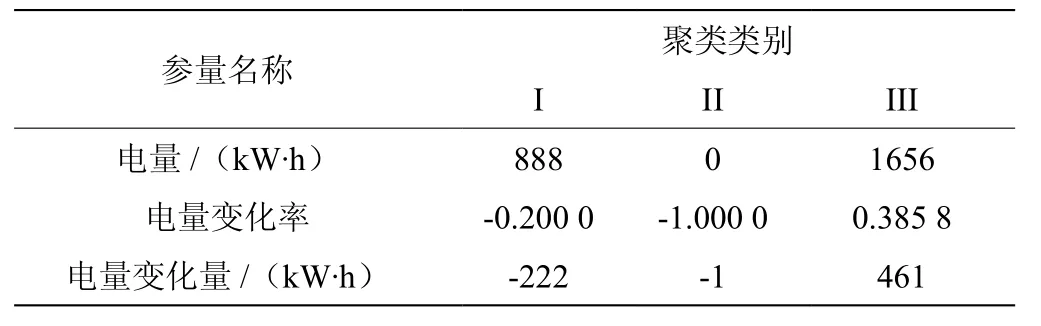
表1 K-means初始类心

表2 K-means迭代结果
聚类结果显示,I类用户数量最多,用电量居中;II类用户数量次之,用电量最小;III类用户数量最少,用电量最大。此外,数据显示,有效聚类用户数50 264,缺失28。各类别电量等信息关系如图3所示。
图3(a)为各类电量箱线图,展示了各类别的用电量情况。I类用户箱线图的上边界为327 kW·h,下边界为139 kW·h,有少量用户超出范围;II类用户箱线图的上边界为142 kW·h,下边界为0 kW·h,所有用户都在范围内;III类用户箱线图的上边界为620 kW·h,下边界为324 kW·h,有部分用户超出边界。综合看来,I类用户的用电量居中,聚类效果较好,超出界限的用户占I类总用户的3.12%;II类用户的用电量最小,但聚类效果最好,无超出界限用户;III类用户的用电量最大,聚类效果较好,超出界限用户占III类总数的3.58%。
图3(b)展示了电量与电量变化量的关系。可以看出,I类用户电量变化量范围最大,浮动较大,极端值甚至出现-100 kW·h的变化;II类用户的电量变化量范围最小,基本维持在±50 kW·h之内,属于最稳定的一类用户;III类用户电量变化量相对居中,较为稳定。
图3(c)展示了电量与电量变化率的关系。可看出,I类与III类用户的变化率无较大差异,基本符合正常生活用电习惯;但是,有的II类用户的用电变化率出现了极大波动。
图3(d)展示了各类别的电量变化量与变化率的关系。可以清晰看出,II类用户的电量变化量不大,但变化率出现异常。查看这些用户的数据得知,这些用户多为上月用电量很少甚至为个位数,而本月用电量正常,遂导致电量变化率激增。
聚类结果总结如表3所示:

图4 聚类结果图

表3 聚类结果总结
利用综合用电量、用电变化量以及用电变化率对用户聚类,将用户按其用电特性分类,从而为电量管理、电量预测提供数据支持。其中,电量预测中最重要的一步聚类,而具有代表性的聚类将提高预测精度。例如,本文中将用户分为I、II、III类,在预测中对不同的类别建立不同的预测模型,再将预测电量综合,即可得到更高精度的预测结果。
3 结 论
本文基于K-means算法分析计算用户用电量、电量变化量以及电量变化率等数据,将用户聚类为三种不同的类型。每个类别都有其特点,各类别间相差较大,对数据管理具有重要意义,如利用海量的历史数据发掘其特点,对电量预测和阶梯电价的制定等具有一定的指导意义。综上所述,一个合理的聚类结果,将大大提高电量预测的准确度,从而对阶梯电价的制定提供合理的理论依据。
