一种基于推测代价评估的推测多线程并行粒度调节方法
2019-04-15李美蓉赵银亮
李美蓉 赵银亮
1(西安航空学院 陕西 西安 710077) 2(西安交通大学 陕西 西安 710049)
0 引 言
随着多核和众核技术的出现,如何利用并行技术挖掘程序中潜在的并行性已成为研究热点。推测多线程SpMT(Speculative Multithreading),也称线程级推测,作为一种自动化并行技术,能够从串行程序中抽取出多个线程,通过在多核框架中对它们进行推测并行来缩短程序的有效执行时间[1-4]。由于采用推测并行而非真正意义上的并行执行,此技术允许处于推测状态的线程间存在模糊的数据依赖关系。若在推测并行之前能准确确定所激发线程的推测时机,则能有效隐藏这些数据依赖关系,带来大幅度的并行性能提升。否则不准确的推测时机会造成线程间频繁的数据依赖违规现象,将影响后继线程分派及推测并行的速度,甚至导致并行性能下降。
一般地,循环结构在串行程序中占有较大比例的执行时间。若将每个循环迭代看作一个线程体作为推测对象,则能得到循环级推测[5-8]。本文重点对循环级推测展开研究。为了准确判定每个循环的推测时机,很多性能预测和性能优化技术得到了广泛地研究。编译器作为其中一个典型代表,因具有完整的源程序信息和相关编译优化技术等优势,常用于预测循环推测时机的首选[9]。多数基于编译端的循环级推测技术常借助于程序剖析技术预先得到一些程序执行信息,如循环迭代次数、数据依赖个数、循环迭代指令数和缓存命中次数等,再利用这些信息来预测循环并行性能,以性能预测结果作为循环推测依据。并行性能预测主要采用估算误推测代价实现。Wang等[5]主要利用线程间的数据依赖概率、值通信延迟和线程自身的创建开销三者来估算误推测代价。Liu等[7]则侧重于分析线程粒度、数据依赖距离、线程创建以及激发所带来的性能影响作用。在计算误推测时,Dou等[10]又引入了对运行时线程撤销重启和推测缓冲区溢出等因素的分析。而Liu等[11]增加了推测数据预取计算,量化了撤销线程所带来的并行收益大小。Gao等[12]利用编译时的误推测代价模型指导循环重构算法对循环迭代间的数据依赖关系进行重构,提高循环推测并行的效率。此外,Mitosis[13]采用一种预计算切片技术,在循环推测之前利用数据流分析技术计算激发线程所需的预计算片段,预先得到运行时所需的寄存器值,减少数据依赖违规发生的概率。Zhai等[14]则采用编译时激进的指令调度和指令同步技术,减少指针变量间的关键传播路径,优化循环推测性能。
除了以上编译相关技术外,还有不少研究采取编译时和运行时两者相结合的手段来判定循环推测时机。Gao等[6]先借助于编译器贪心地选择同一循环中多个不同嵌套层作为候选推测对象,然后利用运行时动态监测到的执行延迟和撤销次数来最终判定具有最优并行性能的循环嵌套层,从而指导后续推测对象的选择。Li等[15]在前者的基础上,增加了编译时的循环性能评估模型,并在运行时依据串行执行时间预测结果来选择最优的循环嵌套层,确定循环推测次序。Luo等[16]侧重于利用硬件机制构建动态性能监测框架,通过分析循环推测时一级数据缓存的行为特征变化预测循环的并行收益大小,以选择循环的推测时机。部分研究采用循环特征优化技术改善循环推测时机,文献[17]利用编译端生成的“code-bones”指导循环运行时进行动态重构生成高效的循环推测并行代码。Shen等[8]则提出采用线程间取值以及乱序提交等相关技术降低循环的各种推测代价开销。也有少数研究完全依赖硬件来判定循环的推测时机,文献[18]提出了一种名叫Cascadia的动态推测多线程框架,仅利用运行时监测到的IPC作为评估标准,用于指导嵌套循环推测对象选择。而Salamanca等[19]则采用硬件事务内存实现对循环推测框架的支持,优化循环推测对象的选择,提升循环并行性能。
以上循环级推测方面的研究虽然能带来不少性能的提升,但存在的问题在于这些研究在确定循环推测时机时并未考虑硬件资源对候选循环推测对象自身特征以及不同程序阶段特征变化的影响作用,总是假定所有推测对象需求相同的硬件资源。一旦循环被推测并行,在整个推测周期内需要维护固定大小的并行粒度,即采用相同数目的处理器核推测并行,不能根据自身推测结果自适应调整处理器资源,减少不合理的推测失败带来的额外开销。
针对此问题,本文提出了一种面向循环级推测的并行粒度调节框架。此框架以推测级为单位,通过对运行在不同处理器核上的推测线程进行基于硬件的性能剖析之后,构建了一个基于推测代价的评估模型,量化各推测级的并行收益大小。并将此评估结果作为循环并行粒度选择的依据,动态调整每个循环推测对象所需的处理器核资源,优化循环推测时机的选择。
1 执行模型和整体框架
在推测系统中,每个循环都是在执行模型的支持下推测并行。一般地,执行模型中仅需维持一个非推测线程,其他都是处于推测状态的线程。其中,非推测线程负责维护程序的串行语义,通过验证和提交直接后继推测线程的数据来保证程序的正确性。验证和提交工作通常在非推测线程执行结束时进行。一旦某后继推测线程被验证和提交后,非推测线程会将自身的非推测权限传递给它,并释放所占用的处理器核资源。也就是说,在整个推测生命周期中,每个线程的状态始终在不断地变化,并且取决于当前整个循环的推测上下文环境。而处于推测状态的线程一般有多个,为了判定其推测程度,本文采用推测级来区分处于不同推测状态的线程对象,并按照线程激发和分派的次序来确定推测级。非推测线程的推测级最低,其所激发的直接后继线程次之,其他后继线程以此类推。一旦某线程被激发并分派到某个处理器核上后,在验证和提交之前并未发生任何数据依赖违规现象,则认为是推测成功;否则若出现数据读后写现象,需要撤销当前违规线程及其所有后继,并利用所得到的正确数据进行再次推测,保证程序本身的正确性。
图1给出了本文的整体框架,共分为编译时和运行时两个阶段。编译阶段负责选择候选循环推测对象,主要借助于编译时循环并行性能预测手段得到。运行阶段负责对候选循环进行并行粒度调节和处理器核的重新分派。共包含五个模块。首先,利用处理器核调度模型为每个循环分配所需数目的处理器核,在循环推测并行中,采用基于硬件的性能监测工具对循环进行性能剖析,并对剖析信息进行分析和校正。接着,利用所得到的性能分析结果,构建一个推测代价评估模型,并以推测级为单位,对当前所采用的并行粒度进行量化分析。然后,在循环并行粒度选择算法的作用下重新计算当前循环所需的最优并行粒度大小。最后,将调整后的并行粒度值传递给处理器核的动态调节模块,指导后续循环调用进行处理器核的重新分派。

图1 面向循环级推测的并行粒度调节框架
2 推测代价评估
2.1 推测级计算
通常一个循环中的所有线程在激发后总是被分派到相邻连续的处理器核上进行反复推测并行。为了标识它们,本文引入了推测级的概念。当一个刚激发线程被分派到某个处理器核上之后,其推测级的大小采用当前激发线程所在处理器核位置(即处理器核编号)与非推测线程所在处理器核位置两者之间的差值来计算:

(1)
其中:curr_cxt和non_spec_cxt分别表示当前激发线程所在处理器核编号和非推测线程所在处理器核编号;max_num_cxt表示所允许并行的处理器核数目的最大值。本文总是假定非推测线程所属的推测级的大小为0,而推测线程所属的推测级的大小取决于当前所分派到的处理器核编号。
图2给出了一个循环的执行流程片段。图中T1到T8相当于从循环中激发的八个线程对象。假设T1初始时处于非推测状态,处理器核[P0,P3]取值为[0,3],则利用以上计算公式可知,由T1所激发的直接后继T2的推测级为1,T3和T4的推测级分别为2和3。在第1节中提到当T1执行结束时,会向直接后继传递非推测权限,同时释放所占用的处理器核资源。此时,T4的直接后继T5会被分派到当前T1所在的处理器核上执行,依次类推。在这种情况下,随着循环迭代次数的增加,每个处理器核上会执行多个不同的线程对象,且它们在不同的上下文环境中会拥有不同的推测级。若要量化当前所选并行粒度带来的性能影响作用,很显然以处理器核为单位是不合适的,需要以推测级为单位来计算,对处于相同推测级的所有线程进行性能分析和代价评估,以寻找候选循环所需的较优并行粒度大小。

图2 推测循环的执行流程
2.2 代价模型
本文采用Luo等[16]所提出的基于硬件的性能计数器对每个线程进行执行周期分解,共分解为六个部分:提交循环体内非推测指令执行延迟(Busy)、指令本身执行延迟(ExeStall)、取指令执行延迟(iFetch)、访问数据缓冲执行延迟(dCache)、线程撤销执行延迟(Squash),以及其他推测带来的执行延迟(Others)。将分解后的结果与未并行之前的源程序的串行执行时间相比,仅需校正数据缓冲执行延迟就能得到较为准确的并行性能预测结果。为了预测每个推测级中所有线程所带来的性能开销,本文又将分解结果划分为四大类:基本正类开销(ObasicPosi,j)、基本负类开销(ObasicNegi,k)、推测正类开销(OspecPosi,l)和推测负类开销(OspecNegi,m)。ObasicPosi,j由Busy、ExeStall、iFetch以及dCache中除去所需校正的那部分执行延迟四个部分得到;ObasicNegi,k由Others中线程激发、线程提交、线程同步以及执行因推测而引入的额外指令的执行延迟得到;OspecPosi,l由校正访问数据缓冲行为中因推测而减少的那部分开销得到;Onolimitsi,m由校正访问数据缓冲行为中因推测而增加的那部分开销得到。因此,一个推测级中所有线程在推测并行中所带来的总正向开销(Onolimitsi)和总负向开销(Onegi)可利用式(2)和式(3)计算得到。
Oposi=∑ObasicPosi,j+∑OspecPosi,l
(2)
Onegi=∑ObasicNegi,k+∑OspecNegi,m
(3)
对于一个推测级来说,当利用以上分解结果得到所有的正负开销之后,则很容易对当前并行粒度下此推测级的并行性能进行评估。式(4)给出了基于推测级的推测代价模型。若一个推测级的总正向开销大于等于总负向开销时,说明属于此推测级的线程对象适合在当前并行粒度下高效推测并行,此时认为它们能带来并行收益提升;否则,说明属于此推测级的线程对象在当前并行粒度下不能高效推测并行,与得到的并行收益相比,带来了过多的额外推测代价,需要尽量减少这种推测级的存在。
(4)
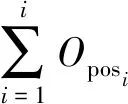
(5)
本文采用循环性能登记表来保存每个循环所有推测级的代价评估结果。表中包含以下表项信息:循环标识符、循环迭代次数、当前循环调用并行粒度大小和上次循环调用并行粒度大小、累计的总正向开销大小、累计的总负向开销大小、非推测所占比例值以及所预测的并行收益大小。当前循环调用并行粒度大小和上次循环调用并行粒度大小由第3节的循环并行粒度选择算法计算得到;循环并行收益大小主要通过预测的串行执行时间与实际得到的并行执行时间两者的差值计算得到[16],其他则利用运行时的性能剖析以及以上代价评估相关公式即可得到。
3 循环并行粒度选择
每个循环在推测并行之前,处理器核调度机制需要根据当前循环所选定的并行粒度大小来分配所需的处理器核资源。为了寻找每个循环所需的最优并行粒度值,本文引入了一种循环并行粒度选择算法,如算法1所示。此算法共包含三种选择方案:激进递减模式、渐进递减模式和非递减模式。激进递减模式是一种快速收敛的并行粒度选择策略,主要利用基于推测级的推测代价模型对推测级的性能评估结果来判定所需的并行粒度大小。相应地,渐进递减模式是一种相对缓慢的并行粒度选择策略,主要从相邻两次连续的循环调用所估算的并行收益大小的比较结果来确定所需的并行粒度大小。而在非递减模式下,此时不再做任何并行粒度大小的调整,从而也表明本算法已经找到了循环所需的最优并行粒度值。
算法1循环并行粒度选择
输入:循环性能登记表
输出:循环所需的并行粒度大小
1.currLoop←findLoopId(loopId);
2. ifcurrLoop不存在then;
3. returnmax_num_cxt;
4. end if
5.lastAssigned←currLoop.assigned;
6. ifcurrLoop正处于激进递减模式then
7.lastRatio←currLoop.nonspecRatio;
8.currLoop.nonspecRatio←计算当前循环的nonspecRatio的值;
9. iflastRatio>currLoop.nonspecRatiothen
10.currLoop.lastAssigned←lastAssigned;
11. repeat
12.i←i+1;
13. untilcosti<0;
14. else
15.currLoop进入渐进递减模式;
16.currLoop.assigned←currLoop.lastAssigned-1;
17. end if
18. else ifcurrLoop正处于渐进递减模式then
19. ifcurrLoop.lastBenefit≤currLoop.benefitthen
20.currLoop.lastBenefit←currLoop.benefit;
21.currLoop.lastAssigned←lastAssigned;
22.currLoop.assigned←lastAssigned-1;
23. else
24.currLoop进入非递减模式;
25.currLoop.assigned←currLoop.lastAssigned;
26. end if
27. end if
28. returncurrLoop.assigned;
在为循环选择并行粒度之前,算法1需要先根据循环标识符在循环性能登记表中查找当前循环是否存在。若不存在,表明此循环从未参与过推测并行,此时系统会把所有的处理器核资源分配它,即允许该循环采用最大并行粒度值来推测并行。否则,若当前循环处于激进递减模式下并行,则需根据运行时执行周期分解所收集到的性能剖析信息,采用基于推测级的推测代价评估结果来进一步判定。如果此次循环调用拥有较小的非推测比值,表明当前所采用的并行粒度能带来性能提升,则将继续激进地对每个推测级进行代价计算,直到计算到不利于推测并行的推测级为止。显然所保留的推测级的个数即为下次循环调用时所需的并行粒度大小。反之,如果此次循环调用中非推测比值较大,与之前所得到的结果相比,证明较优的并行粒度取值应存在于两者之间,此时需要在两者之间采用渐进递减模式来逐步地逼近到最优的并行粒度结果。在渐进递减模式下,主要侧重于考虑循环本身得到的并行性能开销。每次循环调用结束时,只需与上次循环调用计算得到的并行收益大小进行比较即可。若当前循环调用具有较大的并行收益,表明在此模式下还未找到最优的并行粒度结果,则继续递减当前的并行粒度大小。否则,直接在后续循环调用中复用上次循环调用的并行粒度大小即可,此时整个循环也将直接进入到非递减模式下推测并行。
算法1中currLoop表示当前采取并行粒度选择的循环对象,loopId表示相应的循环标识符,函数findLoopId用于在循环性能登记表中查找当前循环所需的并行粒度大小;currLoop.assigned和currLoop.lastAssigned分别指当前所选择的并行粒度值和上次循环调用得到的并行粒度值,两者可以从循环性能登记表中直接得到。而currLoop.nonspecRatio和costi指非推测所占比例值和第i个推测级的代价计算结果,则可从第2.2节中计算获取到。最后,currLoop.benefit和currLoop.lastBenefit分别表示当前循环调用和上次循环调用所计算得到的并行收益大小。
当一个循环的循环迭代次数随着循环调用次数的增加而不断变化时,而又由于同一循环在不同循环迭代次数下经常展现出不同的并行收益结果,若仅在算法中包含某次循环调用的循环迭代次数,将会影响系统对并行粒度大小的正确判定。因此,本文又进一步扩展了循环性能登记表,在表中包含了每个循环在所有可能的循环迭代次数下的相关性能表项信息。每次循环调用时,先通过查表确定所属的循环迭代次数,再进行并行粒度大小的选择。而对于每种循环迭代次数所需的最优并行粒度值,可利用循环并行粒度选择算法计算得到。
4 处理器核的动态调节机制
从循环并行粒度选择算法得到所需的并行粒度大小后,需要根据此结果来调整处理器核资源,保证每个循环所分派的线程对象能在所允许的推测级上正确地推测并行。算法2给出了相应的处理器核映射位置计算流程。若当前循环的某个线程对象要激发并分派其直接后继对象时,需要先查循环性能登记表获取到当前循环的并行粒度大小。若不存在,从第3节可知,系统会默认当前循环分配到了最大数目的处理器核资源,即该循环中所有线程将在所有的处理器核资源推测并行。此时当前线程对象所在处理器核的下一个相邻处理器核,将认为是即将分派的具体位置。由于处理器核数目有限,一旦处理器核资源被释放之后,会立即被后继其他激发线程所占用,也就是说,所有的处理器核排成循环队列进行资源的循环利用。
算法2计算激发线程映射位置
输入:循环性能登记表
输出:所映射的处理器核编号1.currLoop←findLoopId(loopId);
2. ifcurrLoop不存在then
3. return(curr_cxt+1) modmax_num_cxt;
4. else
5.currAssigned←currLoop.assigned;
6.startID←currLoop.startID;
7.dist←curr_cxt-startID+max_num_cxt;
8.dist←distmodmax_num_cxt;
9.nextDist←(dist+1) modcurrAssigned;
10. return(startID+nextDist)modmax_num_cxt;
11. end if
在算法2中,若当前循环在查找之前已被调用过,则可在表中找到当前循环所需的并行粒度大小。在这种情况下,刚激发线程即将映射到的处理器位置需要依据表中登记的信息来进一步确定。首先,从表中得到当前循环所分配到的起始核编号,即当前循环第一个线程所执行的处理器核编号,用于确定处理器核的边界范围。接下来,利用当前线程所在处理器核和起始核两者距离的差值来判定推测程度,即获取到当前线程所属的推测级。再结合当前循环的并行粒度大小,很容易计算出其后继对象所属的推测级。在此基础上,有了起始核的边界限定,再加上当前后继对象的推测级大小,则能很快得到最终所要映射到的处理器核位置。在处理器核映射过程中,至于那些未分派出去的处理器核,本文仅让其处于空闲状态即可。其主要原因在于,这些处理器核并不会对处于推测状态的其他核带来任何性能影响。
5 实验结果
为了验证所提出方法的有效性,本文共采用了两种循环推测系统,分别是基于CMP的循环推测系统和基于SMT的循环推测系统。两者均采用Open64编译器来选择循环,循环选择的策略是性能预测[5],首先利用程序剖析技术得到循环嵌套信息,控制依赖和数据依赖信息,接着根据这些信息来估算循环推测并行中所产生的同步代价和推测失败代价,以预测循环的并行性能大小,最终以此预测结果作为多层嵌套循环选择的依据。由于编译时很难得到准确估算结果,本文对所有循环嵌套层进行贪心选择。表1分别给出了CMP和SMT这两种循环推测系统的处理器参数配置信息。基于CMP的循环推测系统采用SimpleScalar模拟器框架,而基于SMT的循环推测系统则采用SMTSIM模拟器框架。前者最多允许16个线程同时在CMP处理器核上推测并行,即在此推测系统中循环并行粒度的最大值为16。而后者则最多允许6个线程同时在SMT处理器核上推测并行。原因在于,在SMT处理器核上并行的所有线程总是共享相同的处理器核资源,过多的线程数目会造成激烈的资源竞争,影响整体性能提升。

表 1 处理器配置信息
本文共采用了SPEC CPU基准测试程序集中的8个测试程序,分别将它们运行在这两种循环推测系统中,图3和图4分别给出了相应的程序加速比计算结果。Only Compiler Used指仅采用编译端的循环性能预测结果作为循环选择的依据,不允许出现多个循环嵌套的现象。被选择的循环在整个推测并行期间总是采用相同数量的处理器核资源直到并行结束。Compiler Hint允许在编译端贪心地选择多个循环嵌套层,真正的并行目标则依据运行时循环性能量化结果来进一步判定[16]。Compiler Hint+Benefit Guided指在前者的基础上,仅可采用循环并行粒度选择算法中的渐进递减模式依据循环并行收益大小调整处理器核资源的数目。而Ours则采用循环并行粒度选择算法中的三种选择方案共同调整处理器核资源的数目。Oracle指在理想情况下假定每个循环总是在最优的并行粒度作用下所得到的加速比性能。

图3 基于CMP的循环级推测的加速比性能比较

图4 基于SMT的循环级推测的加速比性能比较
从图3和图4可以很容易看出,Only Compiler Used是五种方法中性能提升最少的,此方法主要取决于编译时循环性能预测的准确性。由于编译时尚未真正并行所有循环,若选择不合适的循环会产生严重性能影响,甚至加速比小于1,即并行执行时间大于串行执行时间。在此方法下crafty、gzip、perlbmk和vortex这四个程序的加速比值均小于1。而Compiler Hint侧重于利用动态性能评估手段来确定真正的推测对象。由于运行时很容易监测到较准确的循环推测特征,且贪心地选择多个循环嵌套层会允许更多的循环成为候选推测对象。因此,与前者相比,整体性能有了较显著地提升。Compiler Hint+Benefit Guided在此基础上能依据每次循环调用的并行收益计算结果动态调节所分配的处理器核资源的数目。主要目的在于减少不合适的并行粒度分配带来的额外推测代价开销,经过多次并行粒度调整后,基于SMT的循环推测系统均有较大幅度的性能提升。而基于CMP的循环推测系统由于处理器核的数目较多,递减速度较慢,性能提升有限。而Ours则采用了激进递减、渐进递减和非递减三种方案的组合来选择并行粒度大小,一方面采用激进递减能有效地加速并行粒度的搜索过程得到快速收敛,另一方面也可以采用渐进递减逐步逼近将要到达的最优并行粒度值。采用此方法后,gcc、mcf、gzip和perlbmk等多数程序都能取得较高的加速比值。与Compiler Hint相比,CMP和SMT这两种推测系统在增加了并行粒度调整后平均加速比值分别提高了约9.43%和20.04%。
并行粒度调节方法不仅能有效改善并行循环的加速比性能,而且对其能耗开销也有显著的影响作用。图5和图6分别给出了CMP和SMT这两种循环推测系统的能耗计算结果。能耗大小主要通过在模拟器端集成Wattch能耗分析模型[20]计算得到。且将收集到的能耗值与原始未并行之前的串行结果做归一化对比。
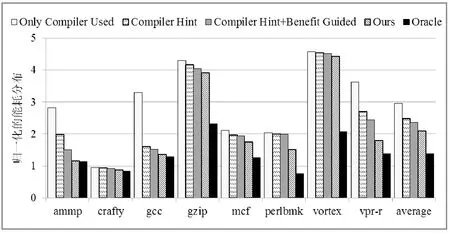
图5 基于CMP的循环级推测能耗开销比较
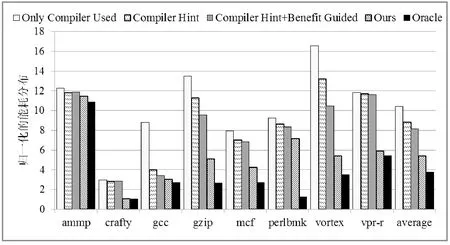
图6 基于SMT的循环级推测能耗开销比较
从整体上看,由于线程同步、推测指令执行延迟以及推测失败等原因,以上方法计算得到的能耗值都相对较大一些,且随着循环推测性能的改善,明显呈现递减的趋势。结合图3和图4可知,程序的加速比性能和能耗开销两者之间还存在密切的关系。Only Compiler Used是以上所有方法中性能估算最不准确的,因此,它的加速比值最小,能耗开销相对来说是最大的。Compiler Hint次之,虽然它能利用动态性能量结果总能选择到性能较优的循环嵌套层,有效地减少了不必要的推测代价,但却不能保证所选推测对象在当前给定并行粒度作用下充分发挥了自身潜在的并行性。而Compiler Hint+Benefit Guided和Ours在前者基础上增加了并行粒度调节方法,允许推测对象根据自身性能自适应地调整并行粒度的大小,优化资源配置,减少了不合理的资源分配得到的额外能耗开销。与Compiler Hint相比,Ours采用激进递减模式能在较短时间内快速搜索到较优的并行粒度值,因此,能较大幅度地降低能耗开销。此外,所有程序在CMP框架下的能耗值要大于其在SMT框架下的能耗值,主要原因在于,基于CMP的循环推测系统中具有较大的线程基数,搜索时间相对较长,且当搜索到较优并行粒度值时,处于空闲状态的处理器核的数目较多,也会产生一定的能耗开销。
图7对ammp程序的某个循环在基于CMP的循环推测系统中的执行情况展开分析。对于当前循环ammp-200来说,按照并行粒度选择算法的要求,首先为其分配的默认值为16,让它在最大并行粒度值下推测并行。当它运行结束时,根据推测代价评估模型计算性能的正向开销和负向开销。从图中可知,很明显在这种情况下总负向开销所占比值具有较大值,需要采用激进递减模式立即调整并行粒度大小。重复此过程,当并行粒度值取10时,总正向开销和总负向开销所占比值相当,且非推测所占比值下降到最低点,此时加速比值取得最大值。若继续递减,可从图中观察到非推测所占比值会逐步上升,而加速比值却在快速下降,表明当前循环中很多激发线程因缺乏足够的处理器核资源不得不推迟推测时机,降低了其本身的并行性。因此,合理选择循环并行粒度大小在整个循环推测过程中至关重要。

图7 ammp-200的并行粒度调节结果
6 结 语
本文提出一种基于推测代价评估的推测多线程并行粒度调节方法。此方法不以处理器核为单位,而是以推测级为单位,依据基于硬件的性能剖析技术所得到的循环性能剖析结果,构建推测代价评估模型用于量化不同推测级在所选并行粒度作用下所带来的正向和负向性能代价开销。并将此代价评估结果作为循环并行粒度选择的重要判定依据。在激进递减、渐进递减和非递减三种选择策略共同作用下,实现循环并行粒度的自适应调整和处理器核资源的动态调节。实验结果表明,自适应的并行粒度选择不仅能揭示出程序潜在的并行性,而且能有效地减少不必要的推测失败所带来的额外能耗开销。
