基于卷积神经网络的黑白人物图像实时着色方法研究
2019-04-12陈国栋杨志伟
田 影,陈国栋* ,王 娜,杨志伟
(1.福州大学 物理与信息工程学院,福建 福州 350116;2.福建师范大学 福清分校,福建 福州 350300)
在以前的大部分照片中,无论是重要历史人物的珍贵照片还是家庭生活照,大都是黑白的,因为那时的彩色摄影还没有普及。要想使一张人物的黑白照片变为彩色,让画面看起来更生动、真实,更能活灵活现地展示它拍摄的意义,给人更好的视觉效果,唯一的方法就是为其上色。自从有了电脑,就拥有了各种神奇的图像处理软件(最常用的就是Photoshop图像处理软件)。但这些图像处理软件的着色步骤较为麻烦,需要深入学习该软件的操作方法,使用起来会占用用户过多时间。
在计算机图形学中,存在两种广泛的图像着色方法:用户引导的编辑传播和数据驱动的自动着色。第一种方法由Levin等人[1]开创性作品普及,用户在图像上绘制彩色笔画,然后优化过程产生与用户的涂鸦相匹配的彩色图像。这样可以获得较好的结果,但通常需要繁琐的操作,因为每个不同颜色的图像区域必须由用户明确指出,选择精确的所需自然色度也是非常困难的。第二种是数据驱动着色方法。它是通过以下两种方式之一来对灰度照片进行着色:(1)通过将其与数据库中的示例性彩色人物图像进行匹配,并从该照片中非参数地“窃取”颜色,这一想法类似Hertzmann等人[2]的图像类比,(2)Aditya和Jason等人[3]通过从大规模人物图像数据中学习从灰度到颜色的参数映射。但着色结果包含不正确的颜色。
为了可以自动提取编辑传播的有效特征而无需手动选择图像特征,本文提出了一种卷积神经网络技术,训练Imagenet数据集中人物以及少量场景,自动从低级特征中提取用于人物图像的有效高级特征。系统首先从输入图像和用户笔画中学习CNN模型。接下来,使用CNN模型估计所有像素上的笔画概率,并且获得概率图。最后,概率图通过后处理来完善。每次用户更新笔划时,系统都会使用先前学习的参数有效更新CNN模型。采用大规模数据传播稀疏用户点,通过训练深层网络直接预测从灰度图像到全色图像的映射,实现人物图像快速简单的着色。
1 学习人物图像着色算法
本文提出了一种CNN体系结构,该体系结构使用卷积和完全连接的网络结构来提取人物图像中适合笔画调整的视觉特征和空间特征。所提取的两个特征的重要性也是使用特征组合器层自动确定的,并且使用soft-max层从组合特征计算出人物图像中所含笔画概率向量。
CNN是一个前馈神经网络,如图1所示具有四种结构:视觉特征提取器(VFE),空间特征提取器(SFE),特征组合器(FC)和标签估计器(LE)。

图1 卷积神经网络学习框架Fig.1 Convolutional neural network learning framework
1.1 人物图像视觉特征提取
如图2,采用视觉特征提取器(VFE)从低级视觉补丁特征p中提取高级视觉特征, 对照片进行分割,区分出标志性物体(如图像中的人物,草坪,等等)。将图片的人物以及背景分开学习,例如人脸[4](包括眉毛、眼睛、嘴巴等)的颜色,衣服帽子和少量背景的简单颜色。

图2 CNN人物特征提取模型Fig.2 CNN character feature extraction model
VFE使用具有模型参数θv的函数Gv从p中计算高级视觉特征fv∈R256。Gv由两个卷积函数fconv1和fconv2、一个最大池化函数fmp和一个整流器线性单元(ReLU)的激活函数组成:
fv=Gv(P;θv),
(1)
Gv(P;θv)=
(2)
fmp(fReLU(fconv2(fmp(fReLU(fconv1(P;θconv1)));θconv2)))。
其中fconv1应用128种类型的3×3×c滤波器内核k,偏置b输入补丁特征p。也就是说,fconv1通过用不同的滤波器内核k和偏置b来卷积输入图像补丁特征p得到128个滤波映射(k*p+b)。然后,将ReLU激活函数fReLU(v)= [max(0,v1),max(0,v2),…,max(0,vm)]T应用于卷积补丁(其中下标v表示向量的元素索引)。接下来,使用步长为2的2×2最大池化功能函数fmp,该函数在贴片上产生位置不变性。另外应用3×3×128内核和激活函数fReLU的卷积fconv2。最后,再次使用步长为2的2×2最大池并获得256维特征矢量fv。θv表示滤波器参数(即,滤波器内核k和偏置项b),并且使用人物图像中的用户笔划作为训练数据来学习。
1.2 人物图像空间特征提取
空间特征提取器(SFE)从空间像素坐标s中提取抽象特征fs∈R256:
fs=Gs(s;θs),
(3)
Gs(s;θs)=fReLU(Wss+bs)。
(4)
其中θs={Ws,bs} 是SFE的模型参数,Ws∈R256×2和bs∈R256是权重矩阵和偏差项。输出特征向量的维度设置为256,以便它们具有与视觉特征相同的维度。同样,特征组合器可以公平地处理图像视觉特征和空间特征。
1.3 图像特征提取的功能组合
特征组合器(FC)的函数Gc将由VFE和SFE提取的fv和fs转换成单个特征向量fc∈R256:
fc=Gc(fv,fs;θc),
(5)
Gc(fv,fs;θc)=fReLU(Gcv(fv;θcv)+Gcs(fs;θcs)),
(6)
Gcv(fv;θcv)=Wcvfv+bcv,
(7)
Gcs(fs;θcs)=Wcsfs+bcs。
(8)
其中θc= {θcv,θcs}是FC的模型参数(其中θcv= {Wcv∈R256×256,bcv∈R256}并且θcs= {Wcs∈R256×256,bcs∈R256})。与FC相似的网络结构也被引入用于结合图像和音频等多种功能[5,6]。这种网络结构可以通过捕获两种模式之间的相关性来确定两个特征的重要性。在本文中利用这种结构来结合视觉特征和空间特征。
1.4 人物图像特征的标签估算
标签估算(LE)的函数Gl根据由FC提取的特征向量fc估计人物图像中用户笔划概率向量y:
y=Gl(fc;θl),
(9)
Gl(fc;θl)=fsoftmax(Wlfc+bl) 。
(10)
其中fsoftmax(v)=fsoftmax(v)
是softmax函数,θl={Wl∈Rn×256,bl∈Rn} 是LE的模型参数。LE基于图像笔画上的像素之外的相似笔画的相似性,为每个笔画像素确定每个笔画的分数权重。这是使用soft-max层完成的,该层用作概率多类分类的标准回归函数[7]。
如图3,CNN的学习策略是:首先使用反向传播在包含VFE,FC和LE的网络上预训练视觉特征,然后与SFE一起学习整个网络。
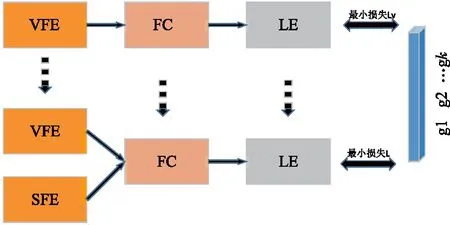
图3 CNN学习策略Fig.3 CNN Learning Strategy
2 学习卷积神经网络
2.1 人物图像笔触学习CNN
本节介绍如何使用训练数据学习CNN的模型参数(θv,θs,θc,θl)[8], 在笔划区Ω上用户笔画GΩ和图像输入特征x∈XΩ。学习模型参数的直接方式是最小化由CNN估计的概率向量与从用户笔划获得的二进制向量gi∈GΩ之间的误差函数E
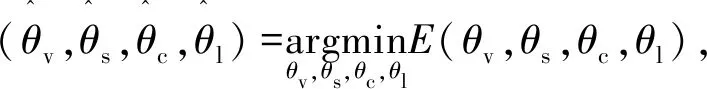
(11)
Gs(si;θs);θc);θl),gi)。
(12)
其中L表示定义为的交叉熵损失函数

(13)
该算法在梯度误差充分传播到VFE的深层之前落入局部最小值。也就是说,SFE的学习速度比VFE的学习速度快得多,因为SFE较浅而VFE更深。当使用反向传播同时优化整个网络的模型参数时,由于梯度消失问题本章开发了一个学习算法,用于分两步有效地优化模型参数:
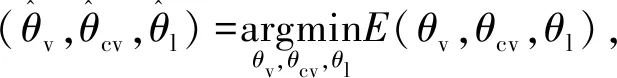
(14)
θl),gi)。
(15)

2.2 估计图像着色概率图
现在使用学习的CNN模型将信息从用户笔划传播到输入图像中的所有像素。给定人物图像每个像素的贴片(补丁)特征和坐标特征,前馈神经网络使用所学习的参数输出笔画概率向量。然而,

表1 使用CNN对人物图像着色算法
由于对一个数据点的前馈计算包括卷积滤波的许多应用,所以逐个处理图像中所有像素需要很长时间。所以采用超像素传播来减少计算时间。对于每个超像素,计算中心像素,然后使用来自仅在中心像素处计算的特征的CNN模型来计算人物图像的用户笔划概率。最后,将相同的笔画概率分配给相应超像素中的所有像素,给予人物图像适合的着色效果。为了生成超像素,我们使用简单的线性迭代聚类(SLIC)[9],因为该算法可以生成规则形状的超像素,可以减小超像素和色块形状之间的差距。
2.3 图像着色后期处理
本文通过后处理来改进估计结果,图4展示了处理前和处理后的对比效果。后处理主要有两个角色,即平滑和插值。首先,我们可以通过平滑超像素来改善图像着色结果。其次,内插可以缓解沿着物体边界的噪声和晕圈失真[10,11]。类似于[11],我们通过解决以下优化问题从CNN模型估计的结果Z中获得最终的着色U:
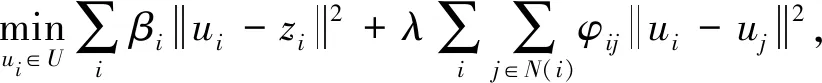
(16)
βi=Θ{ei=0}。
(17)
其中zi∈Z表示正被后处理的数量,ei是输入图像I中像素i处的二进制边,Θ是形态侵蚀算子。λ确定平滑的程度,N(i)是像素i的一组邻近像素。在实验中,所有图像的λ都设置为5。

图4 后期处理之前与后期处理之后对比Fig.4 Comparison before and after post-processing
3 实验环境以及结果
3.1 实验环境
本文用到的深度学习框架是caffe深度学习框架,主要依赖软件有OpenCV、scikit-learn、scikit-image、Python 2.7、Qt4以及重要的caffe文件。环境配置的系统使用Ubutun 16.04。为了实现卷积神经网络学习着色,该系统在显卡为1.NVIDIA GeForce GTX 670MX (99)和2. Intel(R) HD Gr(49),处理器为 Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz 双核以及内存为8 G的PC上运行。
3.2 实验结果
通过利用卷积神经网络为黑白人物图像着色实现这些结果。用户从输入到输出仅使用不到一分钟的时间就可以大大提高图片质量。实现系统的实时着色,产生了很好的彩色图像输出。无论是家里的古老照片还是珍贵的黑白照片,都可以实现几秒钟的实时着色结果。
4 总结
为了达到较好的色彩效果和更真实的人物图片颜色还原,本文使用了卷积神经网络对灰度人物图像实时着色。通过对数据集人物照片的训练,提取特征,采用估计概率图对图片实现较为准确的着色效果。通过CNN的整体前馈网络完成识别到自动着色过程。本文实现了较为真实的色彩效果图。但对于每个图片实现颜色的更改,人工选择多种适合的颜色会在今后的研究中进一步探讨,从而实现对人物黑白图像着色的多样性。
