一种基于Multi-Egocentric视频运动轨迹重建的多目标跟踪算法
2019-04-10欧伟奇尹辉许宏丽刘志浩
欧伟奇,尹辉,许宏丽,刘志浩
(1. 北京交通大学 计算机与信息技术学院,北京 100044; 2. 北京交通大学 交通数据分析与挖掘北京市重点实验室,北京 100044)
目标跟踪是计算机视觉重要研究领域之一,在智能交通、运动分析、行为识别、人机交互[1]等方面具有广泛应用。随着可穿戴式相机的普及,基于Egocentric视频的目标跟踪引起研究人员的极大兴趣。由于单视角视野有限,当相机剧烈晃动时易造成目标丢失以至于跟踪轨迹的不连续性问题,无法进行全方位的跟踪。Multi-Egocentric视频是由多个处于同一场景中的穿戴式或手持式相机所拍摄的不同视角、不同运动轨迹的视频。多视角跟踪由于视野范围更大,视角丰富,能够根据多视角信息有效跟踪目标。相对多固定视角视频的跟踪任务,Multi-Egocentric视角随拍摄者移动,一方面带有Egocentric视频背景变化剧烈、目标尺度差异明显和视角时变性强的特点,另一方面由于继承了拍摄者的关注兴趣,能以更好的视角拍摄所关注的目标,同时多样化的视角为解决遮挡、漂移等问题提供了更为丰富的线索。
目前大多数跟踪算法致力于解决单个Egocentric视角或多个固定视角中存在的目标遮挡、跟踪漂移等问题[2-5]。为了进行鲁棒的目标跟踪,Xu等[4]基于目标表面模型和运动模型,提出层次轨迹关联模型构建有向无环图解决固定多视角下轨迹片段关联问题,将其应用于Multi-Egocentric视频鲁棒性较差,无法解决目标不连续性问题。Fleuret等[6]将颜色、纹理和运动信息3个特征相结合建立目标模型,并通过目标之间的相对位置对目标进行定位,能够有效解决多固定视角下目标遮挡问题,但是将其应用于Multi-Egocentric视频跟踪任务中,背景变化剧烈情况会对跟踪结果造成很大影响,常出现轨迹误匹配问题。另外,X.Mei等[7]提出的稀疏表示算法采用稀疏线性表示的方法使跟踪器可以应对光照变化、遮挡等问题。在线多示例学习算法[8]使用图像块的集合表示目标,使得跟踪器在目标经历光照变化和遮挡时可以有效地跟踪目标。Yuxia Wang等[9]采用粒子滤波方法,基于贝叶斯滤波理论,解决状态估计问题,再根据所有粒子的权重,利用蒙特卡洛序列方法确定状态的后验概率,对跟踪过程中噪声具有一定的鲁棒性。Bae等[10]以及Dicle等[11]跟据轨迹片段的置信度进行轨迹关联实现多目标跟踪,但由于目标轨迹不连续,容易造成短时间的目标误匹配问题。Xiang等[12]通过构造马尔可夫决策过程求取最优策略的方法来预测目标下一刻状态。上述算法一定程度上能够解决运动视角下目标的鲁棒性跟踪问题,但对于视角时变性强的Multi-egocentric视频,容易因目标运动不连续性造成跟踪失败。近年来深度学习方法在目标跟踪领域也有广泛应用,其中MDNet算法[13]采用共享层和特定层相结合的深度模型进行目标跟踪,该方法具有很好的鲁棒性和适应性,但对多目标跟踪具有局限性。
针对Multi-egocentric视频的特点,本文从目标空间几何关系约束的角度出发,并结合卡尔曼滤波算法,提出一种基于运动轨迹重建的多目标跟踪算法。与以上算法相比,本文算法通过轨迹重建可以有效解决Multi-egocentric视频中运动目标轨迹不连续的问题。
1 基于运动轨迹重建的多目标跟踪
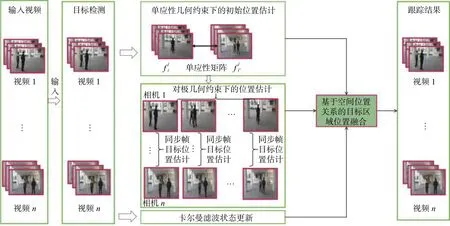
图1 基于运动轨迹重建的多目标跟踪算法流程Fig.1 Flow chart of multi-target tracking algorithm based on trajectory reconstruction
本文针对Multi-egocentric视频的特点,提出一种基于运动轨迹重建的多目标跟踪算法,算法流程如图1所示。该算法利用多视角之间目标位置和运动轨迹的几何约束关系降低了目标定位误差、目标跟踪漂移以及轨迹不连续等对多目标跟踪造成的影响,并在Multi-Egocentric视频数据集和多固定视角数据集上验证了本文算法的有效性。与单视角目标跟踪算法不同,多视角目标跟踪可以利用多视角之间目标位置的关联关系优化目标定位;本文提出基于运动轨迹重建的Multi-Egocentric视频多目标跟踪算法,首先在目标检测基础上,通过求解不同视角间单应性约束解决同一时刻目标的遮挡和丢失问题,然后基于多视角轨迹立体重建算法进行目标定位估计,最后结合卡尔曼滤波的状态更新实现基于空间位置关系的目标区域位置融合,得到最佳的目标跟踪结果。
1.1 多视角辅助下的目标初始位置估计
由于Egocentric视频视角时变性的特点,移动视角因剧烈晃动或平移等因素造成单个视角中目标消失等运动轨迹的不连续性问题。如图2所示,箭头指示两个视角下的相同目标所在位置。从Camerai视角方向来看,两个目标在同一个方向造成目标遮挡,而Camerai'的视角中各目标无遮挡问题。如图3所示,左右两视角都向两边移动时,造成单个视角只检测到部分目标,右侧扩充区域是对单个视角的视野范围的扩充,用于显示目标之间的相对位置关系。以上两种情况都会因目标丢失导致某些视角跟踪失败。
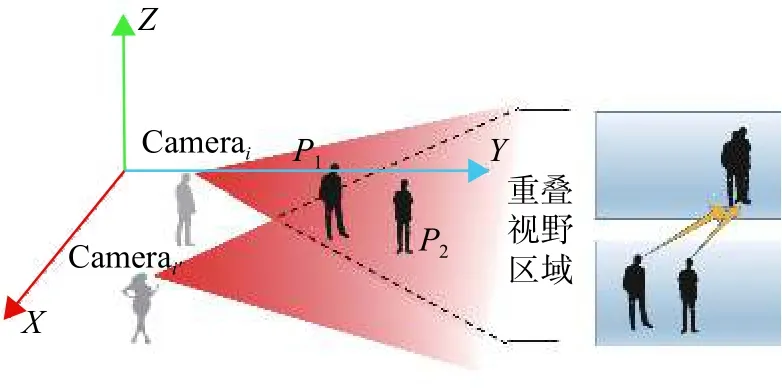
图2 多视角中目标之间相互遮挡示意图Fig.2 Multi-view of the occlusion between targets
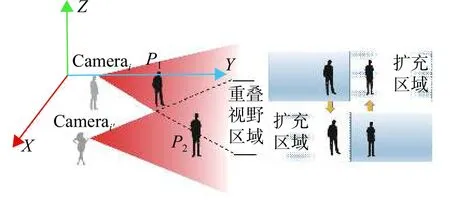
图3 多视角移动造成目标丢失示意图Fig.3 Multi-view movement causes the target to lose the sketch map
针对这种问题,本文基于具有重叠视野区域的视角之间存在平面上的单应性约束关系[14],利用多个视角之间目标的相对位置,根据Camerai第 j帧中的目标轨迹点来估计Camerai'第 j帧的目标所在位置。算法具体描述和实现如算法1所示。
算法1多视角单应性约束下的目标位置估计
输入1) Camerai第 j帧、Camerai'第 j帧、中被遮挡目标k在中的轨迹点坐标;
4) 利用匹配点构建方程(2),并利用RANSAC[15]算法剔除误匹配点求解单应性矩阵;

式中: H 为3×3的单应性矩阵。
输出的目标所在位置
通过不同视角同一时刻目标之间存在的单应性约束关系可以对遮挡和丢失目标进行重新定位,从而解决单个视角中目标的遮挡和丢失问题。同时由于特征点的检测和匹配误差使得单应性约束只能粗定位遮挡和丢失的目标,因此本文通过多视角轨迹重建进一步优化目标位置估计。
1.2 多视角轨迹重建位置估计
多视角轨迹重建位置估计是根据不同视角同一时刻帧目标的像素坐标对应位置关系做空间约束进一步对目标进行定位。根据不同视角同步帧之间重叠视野区域特征点的对应关系采用立体视觉三维重建算法实现同步帧目标位置估计。立体视觉三维算法示意图如图4所示,相机i采用张正友标定法[16]获得Camerai内参矩阵 Ki和Camerai'内参矩阵 Ki′,然后分别提取和之间重叠区域的匹配点集合和,由单应性约束得:
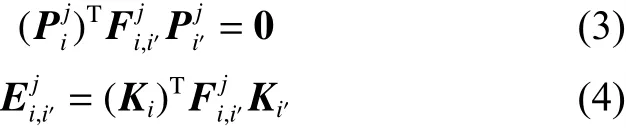
利用PnP[17]和RANSAC算法求出基础矩阵和本质矩阵;当中目标k在Camera中没i'有对应位置,把目标轨迹点代入式(3)可以求解目标在中的扩展匹配坐标位置,并把和分别加入和。对作SVD分解,可得 Camera相对于Camera的旋转矩阵和平移向量i'i。然后计算得到目标轨迹点的三维空间坐标位置集合={|k=1,2,···,m}。
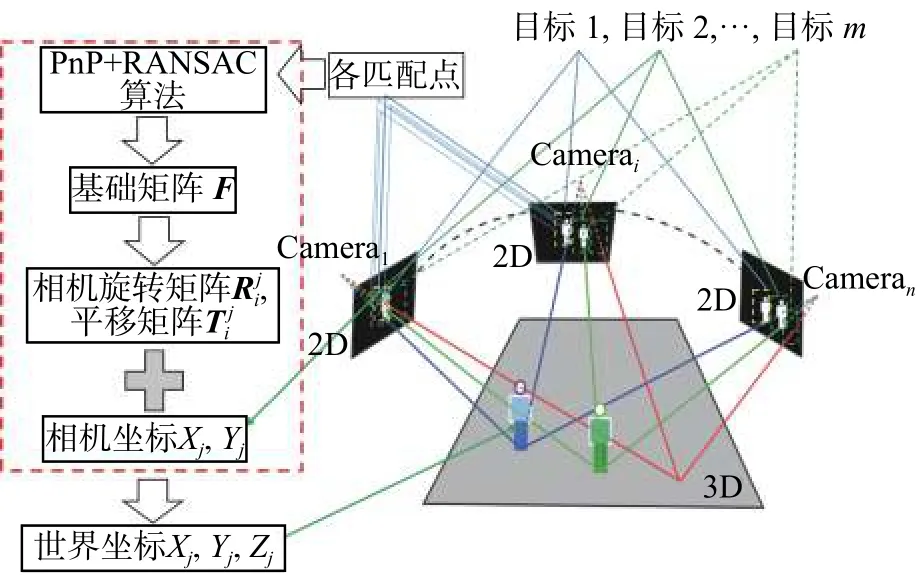
图4 同步帧目标位置估计算法图Fig.4 Sketch map of synchronous frame target location estimation algorithm
1.3 基于轨迹重建的多目标跟踪
设置目标的运动状态参数为某一帧目标的位置和速度。定义卡尔曼滤波[18]第k个目标在j时刻状态是一个四维向量 rk(j)=),分别表示目标在x轴和y轴上的位置和速度,设单位时间T内假设目标是匀速运动、初始位置为初始速度设为0、rk(0)=(s 0,yk,pos,0)T;其中下一步预测方程为
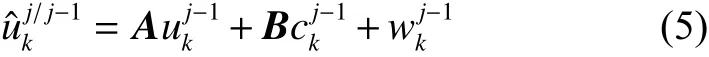

由系统方程和观测状态定义矩阵 B为

卡尔曼滤波状态更新方程为
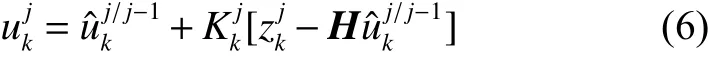
1.4 基于空间位置关系的目标区域位置融合
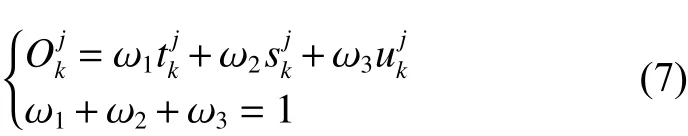
式中 ω1、ω2和ω3分别表示和的权重。
2 实验结果与分析
本文提出的基于Multi-Egocentric视频运动轨迹重建的多目标跟踪算法是针对Multi-Egocentric视频的,目前尚无针对此任务的公开评价数据集,为了验证算法的有效性,设计并拍摄了针对多目标跟踪任务的Multi-Egocentric视频数据集BJMOT。由于数据集采集规模所限,该视频数据集包含两个视角的视频,由两个拍摄者佩戴相同规格的运动相机拍摄,场景中有两个以上的自由运动目标,各视频经同步后,每个视频时长为45 s,帧率为每秒25帧,并从每个视频各提取220帧进行了人工标注作为ground-truth。同时为了验证本文算法的适应性,还在固定多视角的数据集EPLF-campus4进行了跟踪实验,表1为两个数据集的相关信息。

表1 实验采用的数据集Table1 Experimental data sets information
本文采用的目标检测方法为ACF算法[19],并将算法与MDP算法[12]和CMOT算法[10]进行了对比说明。实验评价指标采用中心位置误差和重叠率两种度量方式。中心位置误差是跟踪结果和实际情况中心点间的欧式距离,重叠率是PASCAL中目标检测的评分标准[20],即对于给定的跟踪目标框为 rt和 ground-truth为 rg,定义中心位置误差为
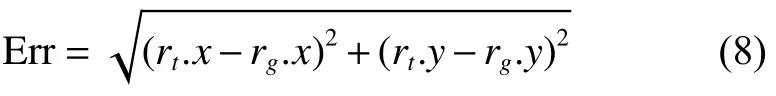
式中: rt.x 和 rt.y 分 别表示 rt的中心横坐标和纵坐标, rg.x 和 rg.y 分 别表示 rg的中心横坐标和纵坐标,定义目标框的重叠率为
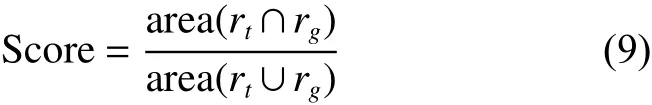
2.1 在BJMOT数据集上的实验结果
本文算法在BJMOT数据集上的平均中心误差如图5所示,表2为平均重叠率和平均中心误差的统计结果,对于部分目标丢失的情况不在计算中心误差范围之内。实验过程中,对 ω1、ω2和ω3分 别 取 值 为 ω1=0.64,ω2=0.23,ω3=0.13。 相 比缺少单应性约束条件的实验结果,结合单应性约束的目标初始位置估计和多视角轨迹重建的方法下,本文算法实验结果的平均重叠率在第一个视角和第二个视角分别提高了13%和9%,能够有效降低遮挡或部分丢失等因素造成的不连续因素对跟踪的影响。
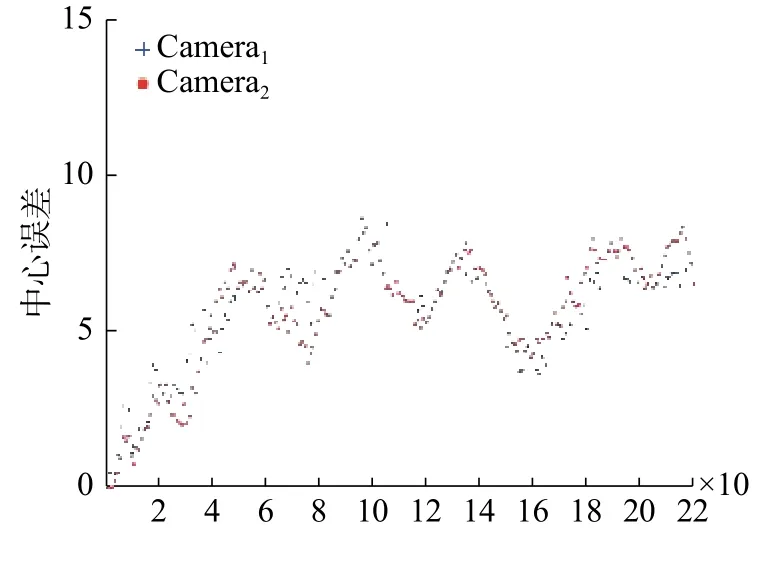
图5 本文算法在BJMOT数据集的中心误差曲线Fig.5 The central error curve of the algorithm in BJMOT dataset
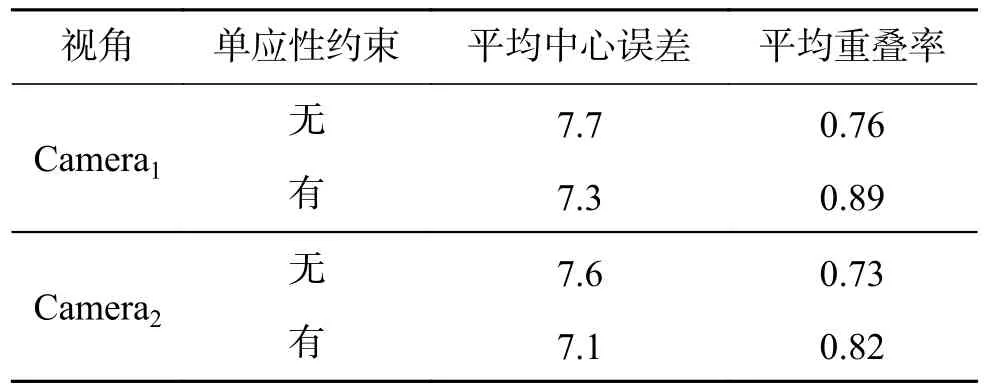
表2 本文算法在BJMOT上的平均中心误差和平均重叠率Table2 The mean center error and the average overlap rate of the proposed algorithm over BJMOT
部分典型帧在Camera1和Camera2上的实验结果分别如图6~7所示,图6~7中给出正常情况、部分遮挡情况、完全遮挡情况、部分消失和完全消失情况等5种典型情况下的目标跟踪实验结果。其中第1行表示目标检测结果或单应性约束目标位置估计结果,行中实线框表示目标检测结果,虚线框表示单应性约束计算结果;第2行中虚线框为多视角轨迹重建估计结果;第3行中虚线框为卡尔曼滤波当前时刻的最优估计值;第四行表示最终结果。第5列中由于目标缺失,在跟踪过程中通过运动一致性可以有效定位目标所在位置,算法计算出的结果在扩展视野区域;并且从图6中第2行第3列也可以看出,通过轨迹重建得到的目标位置误差较大,实验结果容易受到目标检测算法和单应性计算结果的影响;当目标检测误差较大时,该部分所产生的误差也较大,而通过融合对这类误差进行了较好的修正。

图6 本文算法在BJMOT数据集第1个视角视频中的分步实验结果Fig.6 The experimental results of ours algorithm in the first video sequences of the BJMOT datasets

图7 本文算法在BJMOT数据集第2个视角视频中的分步实验结果Fig.7 The experimental results of ours algorithm in the in the second video sequences of BJMOT datasets
2.2 在EPLF-campus4数据集上的实验结果
本文算法与MDP算法、CMOT算法在EPLF-campus4数据集上的平均重叠率结果对比如表3所示。表4为3个跟踪器在EPLF-campus4数据集上的平均中心位置误差。从表3中看出,相比其他两种算法,本文算法在Camera1中的重叠率更高,而在Camera2中的重叠率较低于CMOT算法,其原因是在CMOT算法中目标跟踪框不会随着目标大小进行变化,在目标较远时,检测框与目标真实范围重合率较大。从表4可以看出本文的算法的平均中心误差较小。因此从整体来看本文算法在该数据集上优于其他两种算法。图8~9是3种算法在EPLF-campus4数据集中两个视角的中心误差变化趋势。
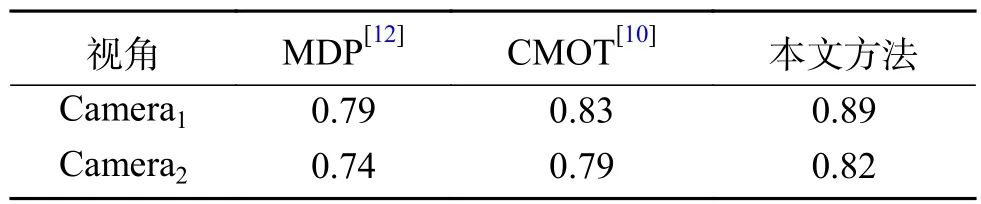
表3 3个跟踪算法在EPLF-campus4上的平均重叠率Table3 The average overlap rate of3tracking algorithms on EPLF-campus4

表4 3个跟踪算法在EPLF-campus4上的平均中心误差Table4 Average center error of3tracking algorithms on EPLF-campus4
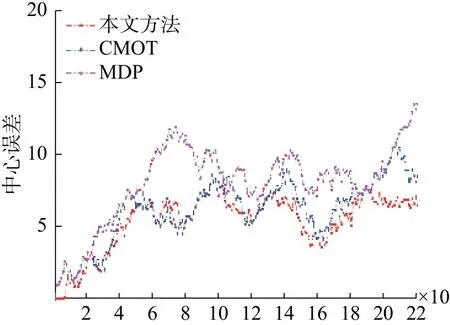
图8 3种算法在Camera1视频中的中心误差曲线Fig.8 The center error of three tracking algorithms on camera1
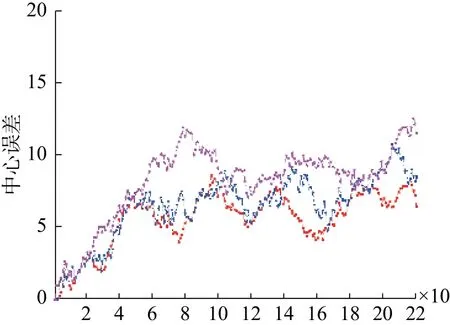
图9 3种算法在Camera2视频中的中心误差曲线Fig.9 The center error of three tracking algorithms on camera2
在EPLF-campus4数据集上Camera1和Camera2的典型帧跟踪结果分别如图10~11所示。同样选取五种典型情况下的目标跟踪实验结果进行分析。其中虚线框表示单应性约束计算结果。第五列中由于目标缺失,算法结果在扩展视野区域,椭圆区域为不同跟踪算法产生的差异性结果对比。从椭圆区域可以看出,本文算法能够根据视角之间的位置信息更好定位到目标,MDP算法在遮挡情况下出现目标丢失,CMOT虽然能跟踪到目标,但是其偏离目标中心位置,误差较大。
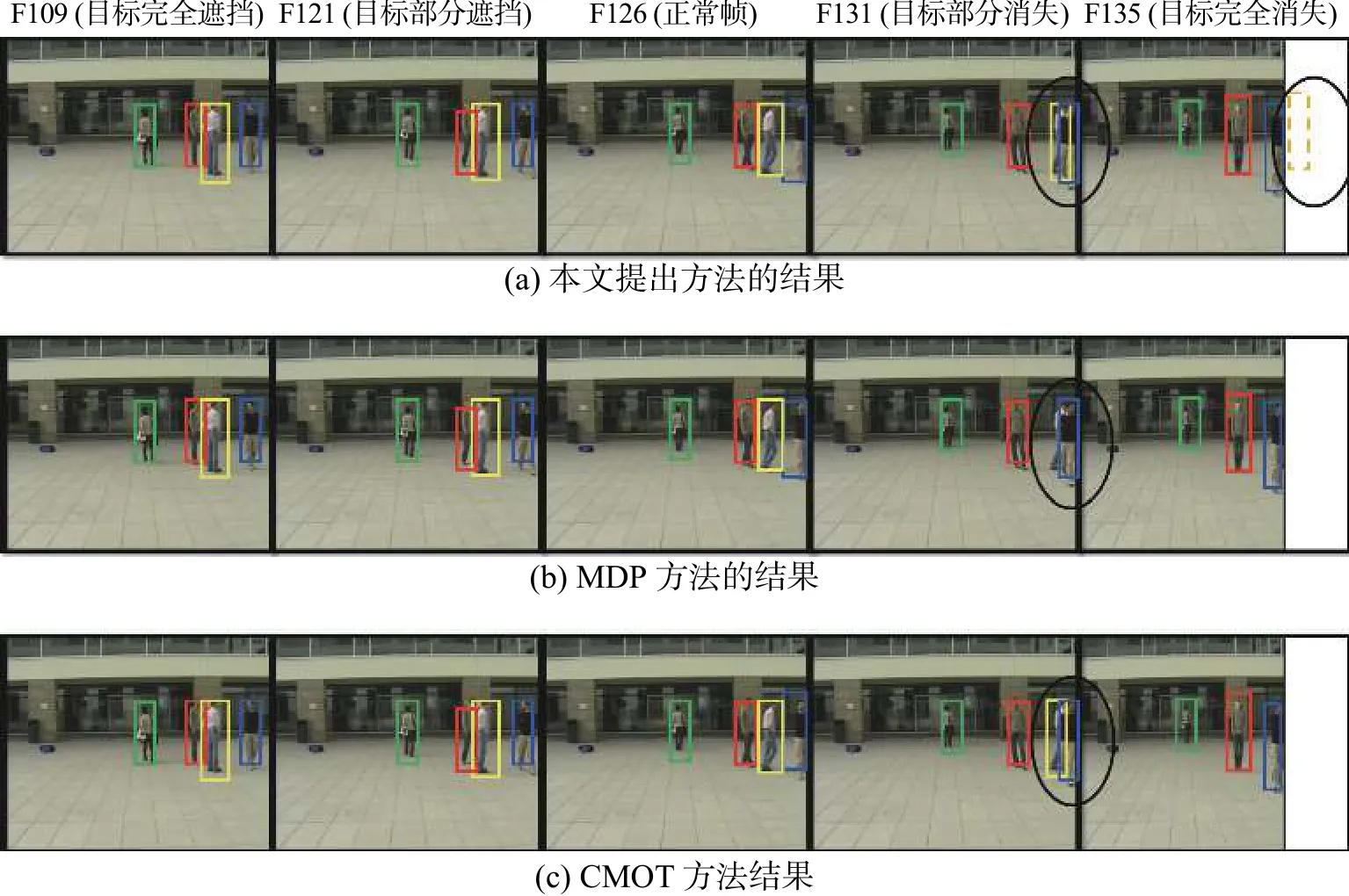
图10 3种算法在EPLF-campus4数据集第一个视角视频中的跟踪对比结果Fig.10 Tracking results of three algorithms in the first video of EPLF-campus4 datasets

图11 3种算法在EPLF-campus4数据集第二个视角视频中的跟踪对比结果Fig.11 Tracking results of three algorithms in the second video of EPLF-campus4 datasets
3 结束语
本文针对Multi-Egocentric视频中的目标遮挡和丢失问题,提出了基于多视角运动轨迹重建的多目标跟踪算法,利用多视角之间单应性约束和空间位置约束关系,结合卡尔曼滤波解决目标在不连续情况下的跟踪问题。与相关算法的对比实验结果表明,本文利用多视角的信息更加有效地解决了多目标跟踪不连续性问题。本文在单应性估计和轨迹重建方面仍然有改进空间,可以通过提高特征点匹配的准确性进一步提高本文算法的准确性。
