变体上下文窗口下的词向量准确性研究
2019-04-04胡正杨志勇
胡正 杨志勇
关键词: 词向量; 词嵌入; 上下文窗口; 自然语言处理; 神经网络; 深度学习
中图分类号: TN912.34?34; TP391.1 文献标识码: A 文章编号: 1004?373X(2019)06?0146?03
Abstract: The word vector accuracy affects the operation of natural language processing tasks considerably. Word vectors are generated by the means of word embedding. In word embedding methods, the target words and their contexts are treated as inputs of the training. As a result, context determination has an important influence on word embedding. Therefore, the influence of variant context windows on word embedding accuracy is studied by using the word2vec word embedding method in this paper. A series of experiments were carried out according to the context windows with variant widths, offsets and weights. The experimental results show that, the variations of the context windows do not have a significant effect on the overall accuracy of training results, but have a significant effect on various specific words, so it is concluded that quite many words have their own demands in suitability of context windows, so it is difficult for a unified context window to implement the optimal training for all words.
Keywords: word vector; word embedding; context window; natural language processing; neural network; deep learning
0 引 言
近年来,深度学习在自然语言处理领域取得了诸多进展。在这些自然语言处理任务中,都将词向量作为其基础。词嵌入(Word Embedding)是一类语言建模技术,通过词嵌入可将词汇表中的单词和短语映射到n维词向量上(维度一般远小于词汇表)。2000年Bengio等人采用词嵌入并结合机器学习取得了较为突出的研究成果[1]。将词向量作为输入,可以很好地实现语法分析[2]、语义分析[3]、命名实体识别[4]等任务。词嵌入的实现方法有若干种,包括用神经网络产生[5?6]、对词共生矩阵降维[7?9]、通过概率模型计算[10]以及显式上下文表征[11]等。其共同点都是依据目标单词与上下文单词的出现概率或次数来构建词向量的。
其中word2vec是目前被广泛应用的基于神经网络的词嵌入方法,其特点是借由神经网络隐含层来发现数据特征,即产生词向量各个维度中的数据,这是一种在非监督学习中常用的特征取得方式。word2vec包含两个可选算法:Skip?gram和CBOW[5,12],所得到的詞向量不仅可以表征单词之间的相似性,亦能表征单词对之间的关系、对应关系[5]。如“man,woman”和“king,queen”,其词向量的关系可表示为:[Vecking-Vecman≈Vecqueen-Vecwoman,]即进行[Vecking-Vecman+Vecwoman]的词向量运算后,其结果最为接近的词向量是[Vecqueen]。
这种向量运算(称其为类比运算)可以在单词的类比关系、对应关系上得到很好的验证[13],一般来说其结果的正确率[11,14]可以达到40%~60%。类比运算是否正确体现了词向量表征语义是否准确。通过在各种变体上下文窗口下进行词嵌入,并使用类比运算研究其所得到的词向量的影响。
1 词向量及类比运算

2 上下文窗口
词嵌入将目标单词及其上下文作为训练的输入,上下文所在的连续文本区间也就是上下文窗口。在训练中,一般对各个上下文词向量赋予一个权值[p∈0,1],且权值随着距离目标单词的距离变大而变小。目标单词一般位于窗口的中心,设目标单词的上文或下文单词数[w]为上下文窗口宽度。则包括目标单词在内,上下文窗口内的单词数为[2w+1]。在word2vec中,窗口内单词的权值[p]与其距离[d]的关系为:[p=w-dw],且[d∈[0,w-1]]。当它与目标单词相邻时:[d=0,p=1;]而距离最远时[d=w-1]且[p=1w],这样的窗口称为递减权值窗口,如果权值不变则称为固定权值窗口。
在词嵌入中,确定了语料库和上下文窗口也就确定了训练的输入,因此上下文窗口的选择将对词嵌入的结果起到至关重要的影响。在各种变体窗口下,词嵌入训练结果的变化是主要研究内容。本文在一系列不同的上下文窗口宽度和形态的条件下进行了词嵌入训练,并且通过类比测试来评价词向量的准确性。
3 测试内容
本文使用目前广泛采用的维基百科英文语料库进行词嵌入,其开放性使得相关研究的可重复性较好。语料库是在对维基百科英文页面备份进行文本无关信息筛除得到,其文件大小为12.1 GB,包含2 113 849 195个单词。
使用基于Python语言的word2vec来进行实验,词汇表为语料库中出现次数不小于10 000的单词所构成。采用的测试数据为word2vec项目的类比数据集,共19 545个类比。该数据集是词向量中广泛被使用的一个测试数据集,其中的类比关系包含:首都与国家(如:“Athens,Greece与Beijing,China”),角色关系(如:“boy,girl与brother,sister”),形容词与副词(如:“amazing,amazingly与happy,happily”)等14个类型。
4 测试结果
本文测试了在不同窗口宽度下的词向量准确性。采用递减对称窗口时,词向量的准确性随着窗口宽度的增加而增加,且增幅逐渐减小直至逐渐下降见图1。这主要是由于距离越远的单词与目标单词逐渐失去关联。

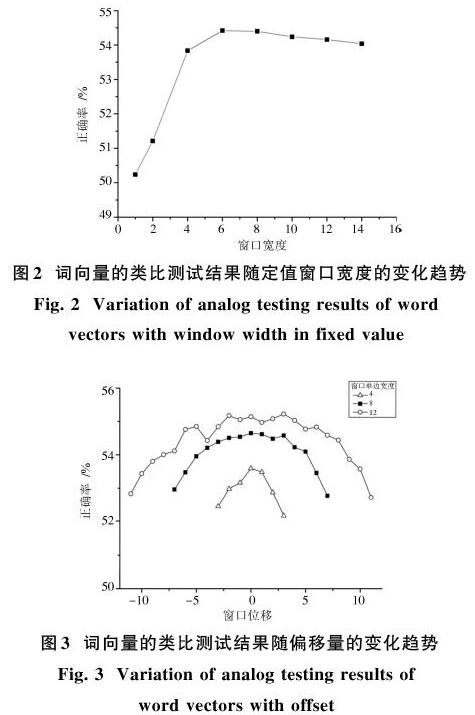
而采用定值窗口与递减窗口相比,它在较快增加后更快地进入下降过程,如图2所示。这主要是因为距离过远的单词与目标单词之间关联度过低,而较高的权值加大了噪声信息。如果考虑窗口宽度无限大这一极限情况,每个单词的训练输入将是其他所有单词,词向量将失去意义。
本文还进行了非对称窗口下的测试,对于不同宽度和不同偏移量的窗口进行测试,偏移量大于0代表窗口向下文偏移,反之向上文偏移,实验结果如图3所示。在采用非对称窗口时,词向量的准确性在相对偏移量较小时没有明显变化,而相对偏移量较大时略微降低。例如在窗口单边宽度为8,偏移为0时,正确率约为54.649%。而窗口偏移为-7时,其正确率约为52.960%;窗口偏移为7时,其正确率约为52.769%,两者略低于偏移量为0的情况且彼此非常接近。从实验结果可以看出:训练结果的好坏与输入的文本内容本身基本无关,而与偏移量的绝对值有关。例如,在窗口偏移分别为-7和7时,窗口内容仅有12.5%是相同的,而两者的训练效果相近。
以上的測试观察和对比了词向量准确性的高低。对于类比测试的具体差异,本文进一步观察了7种不同宽度对称窗口的测试结果与宽度为1窗口的测试结果的具体比较,如图4所示。
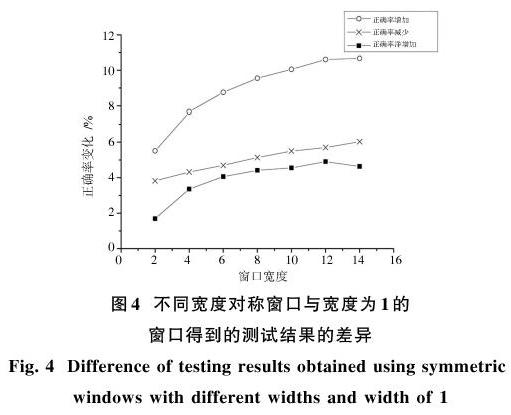
通过测试可知:结果的正确率并非随着窗口宽度的增加而单纯的增加,而是在增加大量正确测试结果的同时,也增加了大量的错误结果。可见,在以上过程中并非对于所有单词有一致的上下文窗口寻优方法。
5 结 论
通过测试可知,上下文窗口的选择对于词嵌入的结果有较大影响:递减窗口能够得到的词向量准确性高于定值窗口;在合理的范围内(上下文窗口包含的单词与目标单词可能存在相关性的范围),窗口越大得到的准确性越高;窗口偏移量较小时的训练效果比偏移量较大时得到的准确性更高。通过进一步的测试发现各种上下文窗口只对词汇表中某些单词有更好的训练结果,即大量的单词拥有各自不同最优上下文窗口。
参考文献
[1] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model [J]. Journal of machine learning research, 2003, 3: 1137?1155.
[2] SOCHER R, BAUER J, MANNING C D, et al. Parsing with compositional vector grammars [C]// Proceedings of 51st Annual Meeting of the Association for Computational Linguistics. [S.l.: s.n.], 2013: 455?465.
[3] SOCHER R, PERELYGIN A, WU J Y, et al. Recursive deep models for semantic compositionality over a sentiment treebank [J/OL]. [2017?03?13]. https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf.
[4] SIEN?NIK S K. Adapting word2vec to named entity recognition [C]// Proceedings of the 20th Nordic Conference of Computational Linguistics. Vilnius: Link?ping University Electronic Press, 2015: 239?243.
[5] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [J]. Advances in neural information processing systems, 2013, 26: 3111?3119.
[6] BARKAN O. Bayesian neural word embedding [J/OL]. [2016?03?21]. https://arxiv.org/ftp/arxiv/papers/1603/1603.06571.pdf.
[7] L?BRET R, COLLOBERT R. Word embeddings through Hellinger PCA [J/OL]. [2017?01?04]. https://arxiv.org/pdf/1312.5542.pdf.
[8] LEVY O, GOLDBERG Y. Neural word embedding as implicit matrix factorization [J]. Advances in neural information processing systems, 2014, 3: 2177?2185.
[9] LI Y T, XU L L, TIAN F, et al. Word embedding revisited: a new representation learning and explicit matrix factorization perspective [C]// Proceedings of 24th International Conference on Artificial Intelligence. Buenos Aires: AAAI Press, 2015: 3650?3656.
(上接第148页)
[10] GLOBERSON A, CHECHIK G, PEREIRA F, et al. Euclidean embedding of co?occurrence data [J]. Journal of machine learning research, 2007, 8(4): 2265?2295.
[11] LEVY O, GOLDBERG Y. Linguistic regularities in sparse and explicit word representations [C]// Proceedings of Eighteenth Conference on Computational Natural Language Learning. [S.l.: s.n.], 2014: 171?180.
[12] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [J/OL]. [2013?09?07]. https://arxiv.org/pdf/1301.3781.pdf.
[13] ZHILA A, YIH W, MEEK C, et al. Combining heterogeneous models for measuring relational similarity [C]// Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. [S.l.: s.n.], 2013: 1000?1009.
[14] MIKOLOV T, YIH W T, ZWEIG G. Linguistic regularities in continuous space word representations [C]// Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Atlanta: Association for Computational Linguistics, 2013: 746?751.
