基于随机森林的FY-2G云检测方法
2019-04-03付华联
付华联,冯 杰, 李 军,刘 军
(1. 成都理工大学,四川 成都 610000; 2. 中国科学院深圳先进技术研究院,广东 深圳 518055)
遥感影像应用广泛,如资源、环境、灾害、区域、城市等各个方面[1-5]。根据国际卫星云气候计划ISCCP(International Satellite Cloud Climatology Project)提供的全球云量数据显示,云覆盖了全球60%以上的地球表面[6-7]。因此,星载遥感观测不可避免地要进行云检测。遥感影像在成像过程中受到云层的遮挡,导致原地物光谱失真,对影像的信息提取造成很大的影响[8]。因此,实现遥感影像云检测与识别具有重要的意义。
风云系列气象卫星为气象、海洋、农业、林业、水利、航空、航海和环境保护等领域作了巨大贡献。气象卫星云图中云检测、定量判别及其计算机实现是气象卫星云图信息处理的主要工作。由于风云卫星云检测方法偏少,因此需要在遥感影像云检测的基础上进行研究。目前遥感图像云检测方法众多,文献[9]总结了4种基本的云检测方法:物理法、基于云的纹理和空间特性的检测方法、模式识别检测法、综合优化方法。物理方法必须要找到合适的光学阈值[10-12],模式识别法依赖于正确的训练数据集和特征的组合来确定方法的性能优劣,纹理特征[13]则可以进一步提高云识别的性能,但是没有一种普适的特征集能识别所有的云和地面。
近年来,机器学习在生态、医学、遥感、交通及其他领域都取得了较大的成功[14-16]。在遥感影像的数据背景下,通过对遥感影像进行训练,通过机器学习思路能够发掘影像潜在的复杂而又丰富的信息[17-19]。本文提出一种基于机器学习中随机森林算法的风云卫星遥感影像云检测方法。该方法首先使用随机森林算法对国家气象卫星中心(National Satellite Meteorological Centre,NSMC)FY-2G产品的训练样本进行训练得到模型;然后,利用NSMC的FY-2G产品的测试样本来测试随机森林训练好的模型;最后,将随机森林(random forest,RF)云检测方法得到的结果与大津法(Otsu)[20]、NSMC云产品数据对比分析。
1 随机森林云检测
随机森林作为一种集成分类器,具有训练样本数量需求少、人工干预少、分类精度高的特点,可以处理高维数据并快速得到分类结果。本文充分利用NSMC的FY-2G卫星云分类结果,根据随机森林原理在NSMC分类基础上进行试验,得到理想的效果;最后将随机森林的云检测结果与Otsu云检测、NSMC的聚类的结果比对。
1.1 NSMC云检测方法
NSMC云分类生成过程分为以下几个步骤:
(1) 分割段单位,计算大像素点的均值和方差。
(2) 对于每一个段,求出抛物线模型的参数,去除抛物线外部的像元。
(3) 提取均匀像元,分析表明大像元的方差事迹反映像元分布的均匀程度。在大像元方差的直方图上,方差值小的一部分占较大比例。在一个段内做大像元方差的直方图,可以得到一个最大的波峰,找到这个波峰右侧的波谷作为阈值,如果得到的像元数大于段内总像元数的5%,即将此值作为均匀像元阈值;如果像元数小于段内总像元数的5%,将在直方图上由最小值开始累加像元数,直至得到的像元数超过总像元数的5%,以此作为阈值。根据最后得到的阈值,就可以得到段内的均匀像元。
(4) 对于均匀像元,可以用直方图进行分析、分类处理。首先分析水汽直方图,得到相应的类别;然后对每个类别用红外直方图作进一步分类,将均匀像元划分到多个类别中。直方图分析涉及直方图平滑、波峰波谷自动识别、容错处理等步骤。
(5) 使用最小距离法将剩余的像元归入相应的类别中。
(6) 根据红外-水汽散点图的斜率,将已获得的各类别标定为具体的云类。
(7) 由于按照段区域分割,可能会造成两个相邻段之间云类的不连续,因此最后要进行段间云类的重新匹配处理。
1.2 随机森林算法原理
RF算法是一种基于分治思想的集成学习策略,针对回归树(CART)的多分类器模型。RF由大量决策树构成,每棵树都依赖于一个随机向量,其中所有的向量都是独立同分布的。每棵树进行独立分类运算得到各自的分类结果,根据每棵树的分类结果投票决定最终的结果。
在RF算法中,首先需要定义两个参数n和m,其中n代表决策树的数量,m代表分裂每个节点上属性特征的数量。首先,从原始训练样本集中抽出n个样本,剩余数据对分类误差进行估计;然后,把每个样本集作为训练集生成单棵决策树,在树的每个节点处,从特征变量中随机选m个特征变量作为预测变量,从中选出一个最优的特征变量进行分类。RF采用分类与CART算法来生成决策树。在CART算法中,每个节点根据基尼指数(GINI Index)来选择最佳分裂树形,对于给定的训练集,基尼指数公式如下
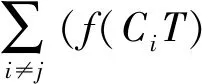
(1)
式中,T为学习器{h1,h2,…,hT}集合的个数;f(CiT)/T为所选类属于Ci的概率。
GINI指数可以衡量类间差异性,当GINI指数增加时,类间的差异性增加;反之,类间差异性减少。如果子节点的基尼指数小于父节点,则分裂该节点。当GINI指数为0时,终止分裂,一类被分离出来。当n个决策树生成森林时,用这n个决策树的预测结果来预测新的数据集。
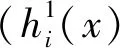
(2)
1.3 基于随机森林的云检测
在FY-2G卫星云检测中,首先从NSMC云检测结果中随机选取一定数量具有代表性的像素点组成总训练样本集,利用自举重采样(boot-strap)方法,随机产生训练集(即采用有放回的方式从总训练集中抽取N次组成新的训练集);然后选取合适的特征作为分类属性,利用每个训练集,生成对应的决策树用于分类;最后将影像的所有像素点作为测试样本,组成测试样本集,利用每个决策树对各个像素点进行分类。采用式(2)的投票方法,将决策树输出最多的类别作为测试机样本所属的类别。
1.3.1 数据获取
本文采用从NSMC下载的2015年6月3日8:00—11:00时刻FY-2G卫星的HDF5格式全圆盘图。试验中使用其可见光波段、红外1波段、红外2波段、红外3波段、红外4波段5个波段的数据,其中可见光波段的波长范围为0.55~0.9 μm,星下点分辨率为1.25 km;红外1波段的波长范围为10.3~11.3 μm,星下点分辨率为5 km;红外2波段的波长范围为11.5~12.5 μm,星下点分辨率为5 km;红外3波段的波长范围为6.3~7.6 μm,星下点分辨率为5 km;红外4波段的波段范围为3.5~4.0 μm,星下点分辨率为5 km。
1.3.2 随机森林的参数选取
随机森林在处理FY-2G影像云检测时两个主要的影响参数为:生成一棵决策树所随机选取的属性特征数量(简称特征数量)m和最终生成的决策树数量n,选择最佳的分类影响参数,可以提高分类的准确性。实现随机森林算法,m的大小关系到遥感影像分类时构建出的决策树能力强弱及决策树之间的相关性。随机森林中决策树的数量n决定了随机森林得票数和准确率,依据大数定理,当n增加时,模型泛化误差收敛。随机森林选择属性特征的过程为:①计算每个特征的重要性,并按降序排序;②确定要剔除的比例,依据特征重要性剔除相应比例的特征,得到一个新的特征集;③用新的特征集重复上述过程,直到剩下m个特征(m为提前设定的值);④根据上述过程中得到的各个特征集和特征集对应的袋外误差率(out of band,OOB),选择袋外误差率最低的特征集。
本文为了找到最佳的m和n值,选择了多个参数的组合进行试验,在抽样过程中,采用袋外数据进行内部误差估计,产生OOB误差,OOB被用来预测分类的正确率。通过比较不同组合的OOB(准确度),来选择最佳的属性特征数量值和决策树数量。
1.3.3 训 练
本文基于NSMC的云检测结果,采用随机森林进行训练的步骤如下:
(1) 选取样本。训练样本是整个待分类区的具有代表性的样本,样本的选择影响分类的精度,为了避免选择的样本对分类精度的影响,训练样本不但要保证典型性,还要保证随机性。本文从NSMC云分类产品中随机选取200 000个有云像素点和200 000个无云像素点作为训练的原始训练样本。
(2) 选取训练特征。为了提高随机森林的模型预测能力,本文对训练样本作了一定的增强处理,即除了选取当前像素点外,还选取了该像素的3×3邻域内的所有像素构成训练样本。这样做的理由是本文认为样本点附近的3×3邻域的点与样本点有一定的亲和性,具有很大程度的可信度。最终选取样本的5个波段像素点的灰度值、5个波段灰度值对应的均值和方差,以及云和非云的标记作为训练特征。
对于第i个样本点,其对应的训练样本格式如下
〈x1,x2,…,x45,x46,…,x55〉i,yi
(3)
式中,x1~x45为5个波段中每个样本点3×3邻域9个像素的灰度值;x46~x55为5个波段样本点灰度值对应的均值和方差;yi为该样本点为云或非云的标记。
1.3.4 测 试
将测试样本数据作为输入,输入到训练完成的随机森林模型,测试其分类的结果。选取测试数据时,首先对FY-2G数据每幅影像的5波段影像的每一个像素点选取其邻域的灰度值,构成测试数据的输入;其次基于随机森林训练得到的模型,判断该测试数据的输入所属的类别,0表示无云,1表示有云;最后对所有像素点遍历执行上述操作,得到最终的云检测结果。
2 试验与结果分析
2.1 试验数据与评价准则
试验使用的遥感数据来源为NSMC的FY-2G卫星的HDF5格式全圆盘图,计算机配置为Intel(R) Core(TM) i5-6300HQ CPU @2.3 GHz 2.3 GHz,4 GB内存。FY-2G云检测的分类结果以国家气象卫星官方公布的云分类产品数据为准。由于目前没有完全真实的云检测结果,本文以NSMC的云检测结果作为真值,将试验结果与NSMC的云分类结果进行对比。
本文使用命中率(probability of detection,POD)、误报率(false alarm ratio,FAR)和临界成功指数(critical success index,CSI)来评价该试验效果。各个评价指标的计算公式为
(4)
式中,NH表示FY-2G的云检测结果和NSMC云产品中都为云的像素点频数;NM表示FY-2G云检测结果中无云而NSMC云产品中有云的像素点频数;NF表示FY-2G云检测结果中有云而NSMC云产品中无云的像素点频数。
2.2 云检测结果分析
图1为FY-2G卫星2015年6月3日的9:00的图像及各个方法的云检测结果图。图中,白色表示云,黑色表示非云。将图1(a)、(b)与(c)对比可知,Otsu云检测结果存在大面积的错检、漏检,造成错检的原因是没有选取到合适的阈值,将部分非云区域错判为云。图1(d)是随机森林云检测结果,从图像上看很接近NSMC云检测结果,由图像的C区域可以看出,NSMC的云检测结果存在部分水体误判为云的情况,随机森林能够正确地标识误判区域。
图2(a)—(d)为图1(a)中A区域可见光通道图像、NSMC云检测图像、Otsu云检测图像、RF云检测图像;图2(e)—(h)为图1(a)中B区域可见光通道图像、NSMC云检测图像、Otsu云检测图像、RF检测图像;图2(i)—(l)为图1(a)中C区域可见光通道图像、NSMC云检测图像、Otsu云检测图像、RF检测图像。
将图2(a)—(d)对比可知,Otsu云检测存在大面积的错检和漏检,部分非云区域误判为云。基于RF云检测方法与NSMC云检测结果基本一致,且能将一些含云量较小、薄云低云部分正确标记出来;将图2(e)—(h)对比可知,NSMC云检测将含云量较稀疏的地方标记成连续成片云,而RF的结果能正确标记;由图2(i)—(l)可知,NSMC云检测将部分水体误判为云,随机森林能较好地正确区分云和水体。
图3为FY-2G卫星2015年6月3日11:00图像的各个云检测方法得到的结果图。将图3(b)、(c)、(d)对比可知,Otsu云检测结果相比NSMC云检测结果存在误判,而RF云检测结果与NSMC云检测结果接近,说明本文的方法可行。
图4(a)—(d)为图3(a)中A区域可见光通道图像、NSMC云检测图像、Otsu云检测图像、RF云检测图像;图4(e)—(h)为图3(a)中B区域可见光通道图像、NSMC云检测图像、Otsu云检测图像、RF云检测图像;图4(i)—(l)为图3(a)中C区域可见光通道图像、NSMC云检测图像、Otsu云检测图像、RF云检测图像。
图4(b)—(d)中,RF云检测与NSMC云检测结果比较接近,RF云检测将部分少检的区域标记出来;图4(f)—(h)中,Otsu云检测将部分非云区域错判为云,NSMC云检测将部分非云区域误判为云区,RF云检测能够比较准确地标记NSMC误判的区域;将图4(j)—(l)比较可知,RF云检测在部分区域优于NSMC的云检测结果。
计算Otsu、RF云检测结果的命中率(POD)、误报率(FAR)、临界成功指数(CSI)3个评价指标,见表1。
由表1可知,FY-2G卫星在2015年6月3日上午8:00—11:00,Otsu云检测的命中率(POD)比较低,误报率(FAR)偏高,临界成功指数(CSI)均在50.31%以下,而且Otsu云检测结果和NSMC云检测结果的临界成功指数为30%~50%。而RF云检测误报率(FAR)相比Otsu云检测的误报率(FAR)较低。RF云检测结果和NSMC云检测结果的临界成功指数(CSI)为78.16%~80.14%,比Otsu云检测结果提升了很多。试验结果表明,该方法提高了云检测的精度,有效解决了云漏检、错检。
3 结 语
本文提出了基于随机森林的云检测方法,并应用于FY-2G影像,而且将其云检测结果、大津法云检测结果与国家气象卫星中心云检测结果进行比较。从整体来看,随机森林算法能够在一定程度上标识国家气象卫星云检测产品中的错检区域。试验结果表明,该方法具有一定的优势:准确率高,对于不同类型的云均有较好的检测结果。本文方法能在一定程度上改善云的错检和漏检,提高云检测精度。但笔者仅仅将FY-2G影像有限的邻域灰度值特征用于训练,取得了较好的云检测结果,下一步的研究将集中于完善随机森林模型,更进一步提高云检测精度。
