一种基于Python符号执行的自动化网络攻击流量获取方法
2019-04-01陈家浩王轶骏
陈家浩 王轶骏 吕 诚
(上海交通大学网络空间安全学院 上海 200240)
0 引 言
随着全球网络服务爆发式的增长,网络安全问题也随之而来。大量的网络攻击脚本在网上传播使用,对网络健康生态造成了极大的威胁。而在针对网络攻击的检测与防御中,网络流量样本是非常重要的研究对象和判断依据。因此对各种网络攻击脚本所能产生的攻击流量的采集工作就非常重要。
想要采集这些攻击流量主要有4种方法:(1)使用真实的攻击代码对测试靶机进行攻击,攻击流量直接由运行的攻击代码生成;(2)对各类攻击行为的特征进行整理和建模,提取关键信息,构造攻击流量;(3)从真实的网络安全事件分析与审计中获得攻击流量;(4)采用符号执行技术,对攻击脚本进行分析,提取其释放的攻击流量。
第1种方法通过直接运行攻击脚本的方式来产生攻击流量。这种方法虽然可以得到最真实的攻击流量,但存在明显的缺点:首先,不同攻击代码所使用的编程语言和运行平台各不相同,难以设计一套测试系统能够运行所有攻击代码,并释放攻击流量,这对研究人员需具备的硬件设施条件和个人能力有很高的要求;其次,一次成功的攻击不仅仅依赖于攻击方,对目标也有很多的要求,为了提取在各种场景下的攻击流量,需要模拟各种情况搭建多个满足要求的靶机环境,网络设备与网络服务种类繁多,应用场景复杂多变,搭建靶机环境的人力和物力成本非常大;再者,运行攻击代码将会对实验系统和实验设备造成难以控制的破坏,甚至可能留下后门、木马等长久性威胁。
第2种方法通过对各类攻击行为对特征进行整理和建模。这种方法需要通过各种途径采集攻击流量,才能对这些流量加以分析,提取有效数据,根据模型生成仿真的攻击流量。这个方法的缺点在于:首先,在不搭建靶机的情况下对攻击流量的采集比较困难,很难对各类攻击的流量进行完整采集;其次,这种方法生成的仿真攻击流量的可靠性取决于模型的准确性,为了模拟真实攻击流量,需要在数据包顺序、流量分布特征等多方面进行模拟,要想逼真地模仿在各种场景下的各类攻击流量难度很大。
第3种方法通过从真实的网络安全事件中获取攻击流量。这种方法不适合进行大规模的采集工作。因为并不是网络安全事件的被攻击方都愿意向研究者提供攻击事件相关的信息,有的网络安全攻击事件还会被受害方主动隐藏。并且这方法也看运气,很难在一段时间内发生种类全面的网络安全事件。
第4种方法使用符号执行技术对攻击脚本进行静态分析。这种方法也存在一定的缺点,受限于攻击脚本使用的编程语言,针对用不同编程语言编写的攻击脚本需要分别实现其符号执行引擎。该方法带来的优势就比较明显,由于是静态分析,无需搭建大量靶机环境,也无需采集各类攻击流量,符号执行技术会遍历攻击脚本的几乎所有分支,生成各种情况下完整的攻击流量,而且可以实现自动化执行,方便高效,极大地节约了人力物力成本。同时本文还发现目前很大一部分网络攻击脚本都使用Python语言作为脚本语言。
本文研究了一种对现有网络攻击脚本使用符号执行的攻击流量提取方案,通过该方案可以高效提取所需的攻击流量。本文也会进一步对其实际效果进行分析。
1 相关研究
符号执行最初提出是在20世纪70年代中期,主要描述的是静态复合执行的原理,到了2005年左右由于引入了一些新的技术让符号执行更加实用,因而开始逐步流行。Concolic执行的提出让符号执行真正成为可实用的程序分析技术,其在对桌面应用程序的测试中被广泛研究。它能以最少的测试用例达到最高测试覆盖率的特点受到广大测试研究人员的青睐,进而大量用于软件测试、逆向工程等领域。
在2005年左右涌现出很多此方面的研究成果,Berkeley 大学提出的Kudzu Javascript 符号执行平台,用于检测 Javascript中的注入漏洞;MIT提出用于检测HTML运行时错误的符号执行工具 Apollo; UC Santa Barbara 和他们的CTF团队Shellphish提出的angr二进制符号执行平台等。
目前符号执行引擎主要分为三类:第一类用来分析x86二进制机器码,例如 UC Santa Barbara 和他们的CTF团队Shellphish提出的angr等;第二类用来分析基于LLVM项目的中间代码,如2008年Cristian Cadar开发的KLEE等;第三类为专用符号执行引擎,这些引擎往往针对特定的编程语言,如Berkeley 大学提出的Kudzu和MIT提出的Apollo。有些通用的符号执行引擎虽然扩展性好,可以支持多种编程语言,但执行效率偏低;专用引擎虽然其限制较多,但是执行效率高、实用性强。
此外,符号执行技术的发展是依赖于求解器技术的发展的。求解器作为符号执行技术的关键一环,只有能够求解复杂的路径约束问题才能使符号执行技术真正有实用价值。而近年来许多求解能力出众的求解器逐渐出现,其中以2015年微软开源的Z3求解器最为著名。该求解器不但在求解能力上克服了多种原本业内无法解决的非线性问题,还支持大量的编程语言API。
目前支持Python的符号执行引擎有PyExZ3、CHEF。PyExZ3是专门针对Python的符号执行引擎,使用z3 SMT求解器,现在只支持对整数类型的符号执行,局限性较大;CHEF基于S2E引擎,由此衍生出来的符号执行引擎,CHEF引擎作为通用性平台,具有扩展性好、兼容性强的特点,但所付出的代价就是执行效率的低下。
从目前国内外的相关研究来看,基于Python语言的符号执行引擎存在局限性较大,缺乏实用价值,或者平台体积庞大,执行效率低下。因此本文介绍一套经过改进的以Python的符号执行引擎为核心的方案,可以用于对攻击流量的提取。
2 脚本预处理
本文在研究过程中发现,使用符号执行技术进行自动流量采集工作的方案并不是仅仅依靠符号执行技术就能实现的。网络上流传的Python攻击脚本形式参差不齐,需要合理统一的预处理流程把它们的结构统一到一个合理的标准上才能使得之后的符号执行过程稳定运行。因此本文的方案设计如图1所示。本节介绍的预处理部分的流程如图2所示。

图1 方案总体结构设计图
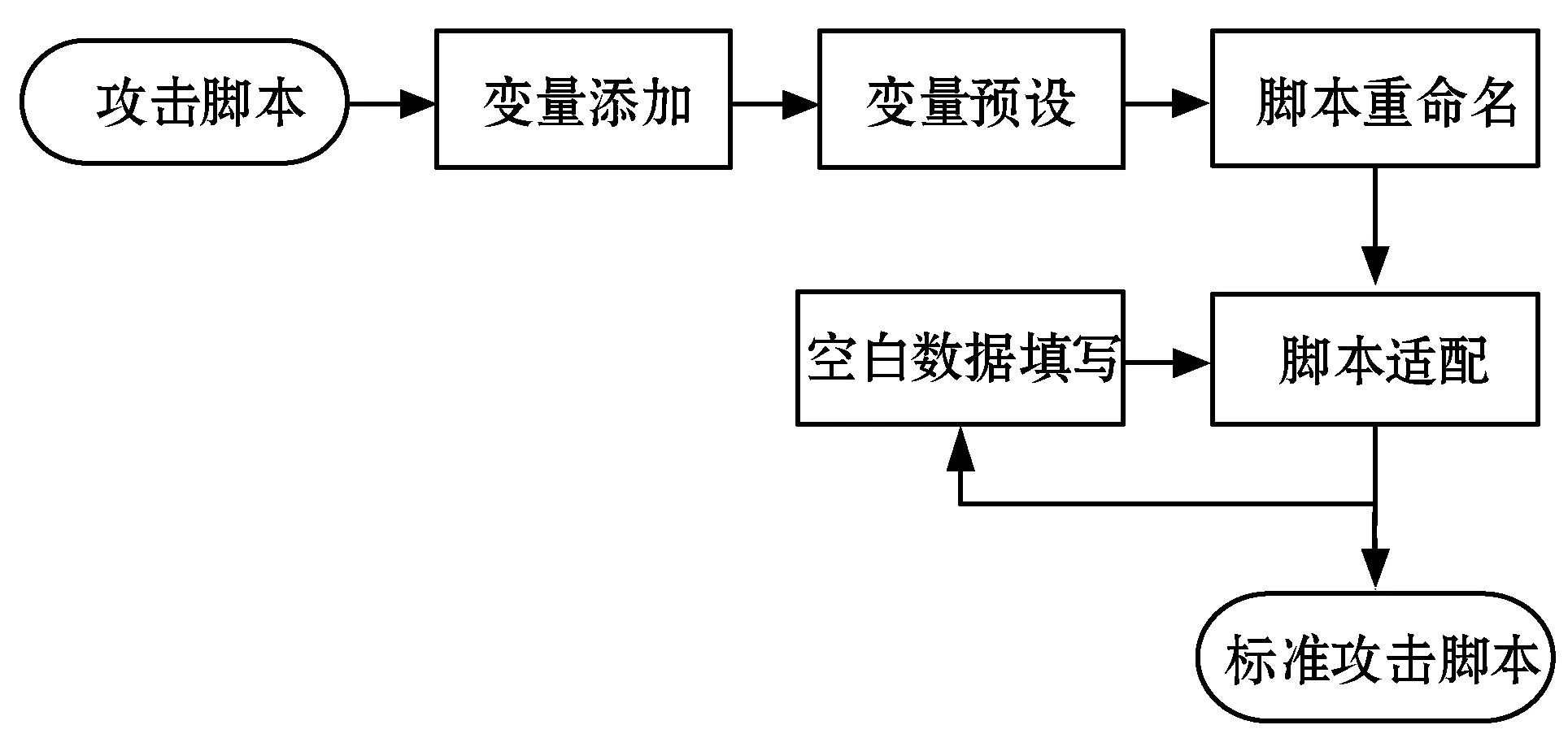
图2 脚本预处理流程图
2.1 变量添加
网络攻击脚本通常都会与目标设备进行大量业务逻辑的交互。原因主要有:
(1) 不同种类的网站服务之间业务差距巨大,交互方式的差异甚至远远超过两台不同品牌不同系统的电脑,并且能同时攻击两种不同的网络设备的漏洞少之又少。因此,针对网络服务的攻击脚本一开始需要检查目标网络设备的型号,通过向其交互后获得的反馈数据进行判断。
(2) 设备的固件版本与该设备存在的漏洞情况关系非常大,因此攻击脚本一开始需要对目标网络服务的版本进行检查,根据目标设备的返回数据来判断出目标设备是否存在漏洞。
(3) 由于大部分网络服务的漏洞存在于业务逻辑交互中,因此让漏洞点暴露出来需要一定的业务交互铺垫。这其中会涉及到在函数体内部使用变量保存反馈数据内容,再根据这些内容进行判断,进入分支代码。
基于以上原因,本阶段需要寻找到这些保存着反馈数据的变量,这些变量在后续的代码中往往会以字符串的形式进行判断跳转。因此需要将这些变量原本的获取内容进行劫持,使这些外来的数据也加入后续的符号执行。
最初本文进行如下的尝试:(1) 去除该变量获取数据的那一行代码;(2) 在目标函数中添加该变量,使其成为这个函数的一个字符串输入参数。如图3所示。

图3 变量添加示意图一
这个方法从符号执行技术的角度来说完全可行,符号执行阶段会将该变量作为一个符号变量进行推算,从而遍历执行到受它影响的代码分支。但是,这个方法对于本文所需的流量采集目的来说是不可行的。因为去除该变量通过网络交互而获取数据的代码后,本次符号执行所得的流量中自然就会缺少这行代码原本应该产生的交互流量。因此,本文采用了新的改进方案,如图4所示。

图4 变量添加示意图二
该方案中依然保留了获取网络数据的代码,但是在其下方立刻补了一条赋值语句。将赋值语句中的右操作数变量作为函数的参数写入函数参数列表。这样一来,就依然能够执行这一网络交互动作产生相应的网络流量,但是也可以使得符号执行对该内容进行后续的推算。
同时也存在攻击脚本中没有主函数,直接使用Python代码执行的情况,此时需要先将这部分代码包裹入自定义的无参数主函数。
2.2 变量预设
通常网络攻击脚本中需要指定目标的IP与端口,有时也需要指定攻击者的IP与端口。这两种变量通常不会参与后续的条件判断,而是直接在之后的代码中被使用,因此并不需要参与符号执行。
此外,IP地址这种类型的变量虽然通常为一个字符串,但是由于脚本中缺乏对IP地址的判断约束,导致IP地址变量几乎不可能被符号执行引擎推算成“XXX.XXX.XXX.XXX”的形式。
因此,IP变量与PORT变量并不适合使用符号执行进行处理,需要在预处理阶段将其预先设定好。设定方案如下:通过匹配 “host”、“ip”、“port”、“parser”等关键字来找出脚本中的这些变量。通常它们会以3种形式出现:
(1) 函数参数列表中的参数。
(2) 全局变量。
(3) 需要用户输入的parser参数。
第一种情况下,先将这些变量从参数列表中移除,然后在函数一开始就将这些变量设定为指定的IP和PORT值,如图5所示。

图5 变量预设示意图一
第二种情况下,直接将这些全局变量赋值为指定的IP和PORT值,如图6所示。

图6 变量预设示意图二
将这些变量设置为固定值也是为了帮助后续的流量采集。通过过滤指定IP和PORT的流量包来精准地采集该脚本的流量,去除别的噪声流量。
第三种情况与以上处理方法类似,直接将目标变量赋值即可。
2.3 脚本重命名
在一个Python语言写的网络攻击脚本中,通常会有许多函数,符号执行阶段需要对其中某个涵盖了全部攻击逻辑的主函数进行符号执行。寻找这个函数的任务也应当由预处理阶段来完成。
目前采用的方案是:将脚本文件名(不包括拓展名)进行统一编号和重命名。然后将目标主函数的声明处和调用处也进行重命名,并且主函数重命名后的名称和脚本文件名(不包括拓展名)保持一致。这样符号执行引擎可以根据文件名来找到该脚本中的主函数。
通常网络攻击脚本中的主函数是main()函数、run()、exploit()函数等。本项目中对其处理的策略是exploit()函数优先。方案如下:
(1) 将攻击脚本重命名为“expXXXXXXXXXX.py”的形式。
(2) 寻找是否存在exploit()函数,如果存在,则将该函数重命名为“expXXXXXXXXXX()”的名称,并相应地修改原本调用exploit()的代码,然后结束本处理。
(3) 寻找是否存在run()函数,如果存在,则将该函数重命名为“expXXXXXXXXXX()”的名称,并相应地修改原本调用run()的代码,然后结束本处理。
(4) 寻找代码中是否存在指定主函数的“if __name__==‘__main__’”语句,如果存在,则将其中唯一包含的函数重命名为“expXXXXXXXXXX()”的名称,并相应地修改原本调用该函数(通常为main函数)的代码。
此方案的效果如图7-图8所示。

图7 脚本重命名示意图一

图8 脚本重命名示意图二
2.4 脚本适配
网络上可以获得的用Python写的网络攻击脚本所使用的Python版本是不同的,有的使用Python 2,有的使用Python 3。需要将其统一为Python 3下可运行的脚本。
这一步通过使用Python 3的官方工具2to3即可实现转换化。转换过程中如果出现报错信息需要传递给空白数据填写阶段。转化成功后为了确保该脚本的正确性,需要在Python 3环境下执行一下。如果执行失败需要记录报错信息并传递给空白数据填写阶段。
本阶段与之前的三个预处理阶段只处理一次不同,其对于一个攻击脚本来说可能需要和空白数据填写操作进行反复循环,流程如图9所示。

图9 脚本适配流程图
2.5 空白数据填写
许多网络攻击脚本中是需要自定义参数的,例如IP、端口、地址偏移等。有些脚本会有默认的参数使得该脚本在没有被用户根据实际情况修改前依然可以正常运行。但依然有相当一部分脚本中没有默认值而导致脚本无法正常运行起来。
没有默认值的变量在代码中的形式通常有如下两种:
(1) 这些变量的预设值在代码中是一串字符,用来提示使用者修改这里。如:“offset=YOUR_TARGET_OFFSET”
(2) 预设值是提示符如:“a=*****”。
本文的处理方法是使用“循环报错法”。这个方法涉及到脚本适配和空白数据填写两个阶段的循环执行。通过脚本适配阶段的报错信息来发现以上的两种情况:
(1) 当报错中含有error type 36等信息时,说明是变量赋值时遇到了如“****”的提示符。此时,将产生报错信息代码行的右操作数改成合法数值即可。
(2) 当脚本适配的尝试运行中出现报错,如果报错信息是“undefined”相关,则说明是遇到了“offset=YOUR_TARGET_OFFSET”这类赋值。此时Python执行环境会误将右操作数理解成了一个未定义的变量。因此,根据报错信息中的问题代码行数即可自动修改该行代码的右操作数为实际数值,从而使得脚本运行无误。
由于报错是一个个出现的,因此本阶段会与脚本适配阶段循环执行,直到脚本适配阶段不报错后,该脚本的预处理即处理完成,流程如图10所示。

图10 空白数据填写流程图
2.6 效果样例
为了更好地展示预处理阶段对整个方案的重要性和突出的实践效果,本文在此挑选出一个需要用到上文全部预处理手段的实际攻击脚本来对比其预处理前后的变化。预处理前的攻击脚本如图11所示。

图11 预处理前的样例攻击脚本
由图11可知,该攻击脚本原本的文件名称为“CVE-2018-18067-Exploit.py”,使用Python2进行编写。在该攻击脚本中存在着等待修改的目标IP变量,等待预设的用户TOKEN变量,还有涉及网络交互的变量。
而图12中则是预处理后的脚本,此时其已经被翻译成了符合Python3语法标准的脚本。上文提到的各类变量都已经在预处理的各个阶段被处理,图中的方框指出了修改的部分,脚本的文件名也已经与符号执行的目标函数名保持了一致。预处理后的脚本就可以顺利进入之后的符号执行步骤。

图12 预处理后的攻击脚本
3 符号执行阶段
本节为整个方案的核心阶段,脚本代码的遍历执行、流量的采集都在本阶段进行。
本文虽然有高效的Pyexz3项目作为支撑,但是该项目在Python字符串的符号执行技术方面完全是空白,故本文进行了大量的改进与研发。
3.1 Pyexz3框架分析
本文参考并使用了微软公司所开发的一套Python 3符号执行引擎。该框架是Python符号执行领域开源项目中的佼佼者。
Pyexz3引擎的效率很高,但是文档和代码的可读性较差。该引擎底层使用的求解器是微软的另一个开源项目Z3求解器。该求解器几乎是领域内效果最好的求解器,但是文档管理依然糟糕,3.3节中的求解示例由本文总结,并未出现在官方文档中。
目前Pyexz3只能对整数变量进行符号执行,不支持字符串变量的符号执行计算。而本文对于字符串变量的符号执行需求远远高于整数变量。因此本文在保留Pyexz3基本架构的情况下对其进行了大量改进,以增添字符串符号执行的能力,改进后的项目命名为Pyexz3P。
3.2 改进设计
根据Pyexz3现有的架构,Pyexz3P项目对字符串符号执行功能的设计结构如图13所示。

图13 字符串符号执行系统架构设计图
本结构最大程度地利用了Pyexz3项目本身在处理整数符号执行时的结构,继承了其高效、层次分明的优势。
本结构中使用SymbolicStr类来参与本符号执行引擎的约束条件计算。当约束条件计算完成后,会集中整理并保存进入新的代码分支所需要的全部约束条件集合Predicate实例中。
本结构中使用Z3String类来对之前整理保存的约束条件集合进行转化。把现有的约束条件转化为一条条Z3求解器可以理解的求解判断规则。如此一来,求解器的接口和符号执行逻辑就能分离开来,方便以后拓展更多高性能的求解器。
PathToConstraint类一方面是收集约束条件的核心类,另一方面也是选择代码路径的核心选择器。在微软原本的项目中使用的是BFS树结构遍历算法。这个选择对于普通大型Python项目来说是合理的,因为这类项目的代码逻辑中分支代码之间有大量并列关系,随着约束分支深度的上升,求解的约束集合也会增大,此时求解器求解失败导致符号执行引擎失败的概率也会上升。因此使用广度优先算法来处理约束树可以优先探索并列的代码逻辑,较快测试到各个并列的功能。
对本文而言,BFS算法则并不适合,因为Python攻击脚本普遍逻辑简单,并列的功能分支较少,主要攻击逻辑相比于其他检测逻辑在深度上要高出许多。因此,需要优先使用DFS算法来更快地进入真正的攻击逻辑分支。故本文对约束遍历的算法进行了改进。
本文使用了FunctionInvocation类与ExplorationEngine类进行实际的脚本代码执行。这就使得符号执行引擎在遍历代码分支的同时已经真正地执行了攻击脚本的代码并产生了对应的攻击流量,而无需根据符号执行所得的求解去重新执行采集。
3.3 功能实现
根据以上设计,本文将其中各个部分所需要的代码实现后,就可以使得Pyexz3P对字符串相关的判断约束语句进行识别和加载。接下来所要做的就是在各个约束条件被加载后的分析并转化成Z3求解器能理解的形式。
3.3.1 字符串长度的约束处理
在网络攻击脚本中由于存在payload这样的对于数据长度敏感的内容,因此对于数据长度的要求有时会比反馈数据的内容更加重要。
要想实现对于字符串长度的约束条件计算,首先要先弄清最后的转化目标——Z3求解器中相应的求解表达式。经过查阅官方文档和代码后,本文总结了一个示例如图14所示。

图14 字符串长度约束Z3构造示例图
由此可见,需要将代码中长度相关的约束条件转化为一个操作数数量为1,操作符为“str.len”的expression类实例。然后转化成Z3表达式阶段将其转化为“Length(z_l)”,其中z_l代表字符串取长度操作中唯一的左操作数。
3.3.2 字符串内容的约束处理
在一些关键数据的判断上,攻击脚本会严格进行字符串对比,这时候需要对字符串内容的约束条件进行求解表达式的转化。
本文总结了两个Z3求解器中关于字符串内容的约束求解示例,如图15所示。

图15 字符串内容约束Z3构造示例图
3.3.3 子字符串内容的约束处理
在字符串的对比判断中,子字符串占了一个很重要的角色。网络数据中存在大量需要判断数据格式、开头的情景,因此,实现了对于从字符串中截取子字符串并进行符号执行的功能需求。
由于官方文档在子字符串处理方面完全空白,本文总结了一个Z3求解器中关于子字符串内容的约束求解示例,第一个示例如图16所示。

图16 子字符串内容约束Z3构造示例图一
图16的示例步骤在实际符号表达式解析时会过于繁琐,因此,本文总结了另一个更适合符号执行技术需求的示例,如图17所示。

图17 子字符串内容约束Z3构造示例图二
该示例中可以精确控制子字符串在原字符串中的位置和长度,从而使求解器求解的答案更加精准。并且从示例中argv1和argv2的关联中可以看出,本方法能解决字符串变量传递的问题。
3.3.4 正则表达式的处理
在字符串的对比判断中,有时会出现正则表达式的匹配判断。目前网上已开源的针对各种语言的符号执行引擎中,大部分都没有处理正则表达式约束的能力。
本文先使用正则表达式反向推导来获得一个符合该正则表达式的字符串,将这个正则匹配约束转化为一个3.3.2节的字符串内容约束或者3.3.3节的子字符串内容约束。这样一来就可以解决这一类正则匹配约束了。Python下有一个开源库名叫xeger,该库可以根据正则表达式来反向推算符合该正则的字符串。步骤如图18所示。

图18 正则表达式约束Z3构造示例图
3.4 流量的采集
在预处理中,本文将脚本中的IP和端口都设置为特定的值,这么做就是为了方便这个阶段的流量采集工作。通过流量的目标IP、目标端口、本地IP和本地端口来过滤流量并抓取保存。由于符号执行过程中几乎每个代码路径都被执行了一次,因此一个脚本中会产生多次流量。
本文对于每条执行的代码路径进行了代码覆盖率统计,并且还综合考虑了该条路径最终产生的流量数据大小和Python调用API的次数,通过加权计算的方式挑选出所需的流量。
3.5 路径遍历策略
由于代码路径搜索策略的选择对符号执行的最终效果有很大的影响,因此本文还需要考虑当前需求下深度优先搜索和广度优先搜索之间的选择。
本文发现Pyexz3项目使用的路径遍历策略为深度优先搜索,经过仔细研究代码发现该策略不是有意为之,而是该项目在路径遍历功能实现中很自然地优先将新发现的分支约束加入约束栈,产生了先进先出的效果。本文考虑到客观情况:网络攻击脚本大多逻辑较为简单,分支复杂的地方大多为攻击脚本中反复发送或请求数据包的部分以及目标环境检测部分。
在反复发送或请求数据包的部分代码中会出现循环次数较高的分支代码,如果使用深度优先策略会使得本方案难以跳出该循环从而引起路径爆炸。这类情况一般DDOS、数据库拖库相关的攻击脚本中出现较多,需要使用广度优先策略来解决这一问题。
在目标环境检测部分代码中会出现大量的同级分支,类似于C语言中的switch逻辑。这时候使用广度优先策略会比深度优先策略的效率低。但是本文在实践中发现这并不会导致整个系统卡死,只是降低了平行跳转逻辑的执行效率而已。相比于上面的第一种情况中深度优先策略会使整个系统困死在死循环中要好得多。
因此,本文中还改进了这个深度优先的遍历效果,将其改为广度优先,从而使得本文的方案在可接受的性能牺牲下快速跳出一些容易导致路径爆炸的循环分支,进入真正的攻击代码逻辑中。
4 强制执行阶段
本阶段为符号执行阶段的一个补救方案,并不是所有的攻击脚本都会进入本阶段,只有当符号执行阶段失败后,才会将第一阶段预处理后的标准脚本传递入本阶段进行最后的自动采集流量尝试。
4.1 基本理念
由于符号执行技术与求解器技术的发展限制,一些约束的求解是无法完成的,比如许多非线性问题、涉及HASH反推的问题。这些问题的求解方法在如今数学学科发展中依然是使用暴力枚举的手段,会大大降低求解器的效率甚至超出其求解能力范围。因此,符号执行阶段对某些攻击脚本可能无法顺利运行。
只有遇到这样的情况时,才会进入最后的自动化获取流量尝试,对脚本进行强制执行处理。通过这种“伪符号执行”的方法来代替特殊情况下的符号执行需求,以此来扩大可自动化获取攻击脚本流量的覆盖范围。
4.2 具体设计
强制执行方法虽然较为粗暴,但是其在本项目中是为了弥补符号执行技术的不足而设计的最后自动化措施。故依然希望能够尽可能保留代码的执行顺序。于是本阶段将会采用一个代码树的结构来保存代码段,并以父子节点的关系来表示前后执行顺序。
强制执行的基本步骤归纳如下:
(1) 将攻击脚本中的代码以跳转分支指令为分割点,把脚本中的代码分解成一个个代码块。
(2) 将这些代码块按照执行顺序存储为树结构。
(3) 运用树的遍历算法来根据代码树中的一条条代码路径生成新脚本并执行采集流量。
代码树样例如图19所示。

图19 代码树样例图
4.2.1 条件语句结构
这类语句中存在着一段需要满足一定条件才能执行的语句。在强制执行阶段会将这段代码取出后填入代码树中进行强制执行。结构转化如图20所示。

图20 条件语句结构转化图
4.2.2 循环语句结构
这类语句中存在着一段需要满足一定条件就能反复执行的语句。在强制执行阶段会将这段代码取出后填入代码树中进行强制执行。结构转化如图21所示。

图21 循环语句结构转化图
由于本文更注重代码执行的覆盖率,因此循环的语句在代码树中仅需被执行一次。这样其中包含的攻击流量就会顺利生成并被采集,故无需反复执行。
4.2.3 函数调用结构
Python语言中通常的函数调用可以分为自定义函数调用和非自定义函数调用。非自定义函数是通过引入编程库来调用的,本文无需关心这类函数的内部实现。自定义函数是攻击脚本中,脚本作者为了提高代码模块程度与可读性而写的,本文需要将这部分函数调用也在代码树中进行分段存储。结构如图22所示。

图22 函数调用时的代码树基本结构
由于自定义函数中也可能因存在条件跳转等结构而产生代码树分支。因此,自定义函数的子节点可能存在多个,每个子节点后都连接着调用函数接下来的代码段节点,结构如图23所示。
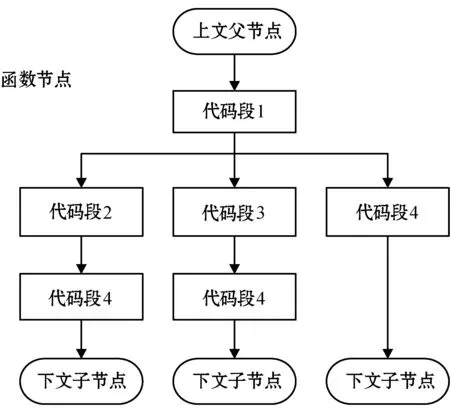
图23 函数调用时的代码树详细结构
4.3 代码树设计分析
从4.2节可以看出,代码树中存储的代码量在分支较多时,会出现在不同节点上重复存储同一代码段的情况。这样无疑会使得代码数的存储代码量超过原本攻击脚本的代码量。
但是这些重复代码段的情况对于本项目来说开销并不大。因为网络攻击脚本的代码量普遍较短,并且条件、循环结构的使用较少,通常都是在检测目标设备型号时使用一次,其他部分使用较少。因此由上述条件、循环结构产生的重复代码存储并不会造成存储空间和代码可能路径的爆炸式增长。因此,本文使用以上方案是完全合适的。
5 流量特征测试
5.1 测试方法
通过在Exploit-DB等公开网站上获取的网络攻击脚本来测试本套系统的运行效果。
用于测试的攻击脚本集需要能够完整测试到符号执行和强制执行的功能而不能集中在序号执行功能上。
在测试过程中采集到的流量需要与本项目研究人员针对相同脚本手工嗅探到的流量进行对比。在对比过程中需要对流量的关键特征如数据包的时序特征、数据包内容特征等进行仔细比对,对于其中的差异要进行分析。
5.2 测试结果
本次测试使用下载到的一个针对MS08-067的攻击脚本。先搭建一个运行着未更新安全补丁的Windows7操作系统虚拟机作为其攻击的靶机环境。
通过配置虚拟机网络环境,将攻击者IP和目标IP分别调整至特定内网IP。在攻击端开启Wireshark等网络数据包嗅探工具,使用其自带的过滤器对IP进行过滤。手动使用攻击脚本对靶机进行攻击,从而获得其在真实攻击中所发出的攻击流量,如表1所示。
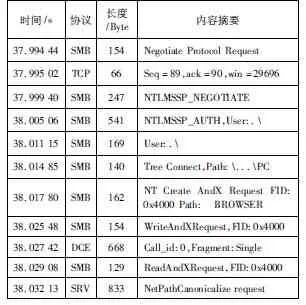
表1 真实攻击所捕获的流量
接下来将此脚本通过本系统进行处理,处理完成后,选择了流量最多的那条代码路径。其所对应的流量特征如数据表2所示。

表2 通过符号执行所捕获的流量
5.3 结果分析
本系统产生的流量与真实攻击过程中产生的网络流量相似度很高,数据包之间的先后顺序和数据内容都与真实攻击相符。
在数据包内容和时序上已经高度相似的基础上,接下来进一步查看其整体的流量特性。根据表1、表2中的数据进一步画出本系统产生的流量和实际攻击中攻击方产生的流量的时域分布图,如图24、图25所示。

图24 本系统采集的攻击流量时间分布

图25 实际攻击流量的时间分布
5.3.1 误差分析1
由图24、图25可看出,本系统产生的流量整体相似度非常高。这是因为符号执行过程中带入求解答案进行执行时运行的代码与真实攻击中的代码是完全一样的。因此,产生的攻击流量在内容特征和时间特征上的相似度也会非常高。
不过可以看出,时间分布上有少量偏差。进一步计算各个包的偏差值发现其具有明显随机性,故认为这是由于网络传输环境的变化而造成的正常误差。
从两幅图的对比也可以看出,有少量折线点分布不同,即图24中的第11点和图25中的第12点附近。进一步分析流量内容可知,这部分数据点为双方网络连接正常产生的数据包,与攻击流量无关,故可以忽略。
5.3.2 误差分析2
由图24、图25可看出,本系统产生的流量在时域分布上虽然顺序相同,但是时间间隔上出现了明显的偏差。
于是本文更换了一个攻击脚本进行了多次对比实验,在数据包内容特征上依然相同,但是这次在时间间隔上出现了较大不同,如图26-图29所示。

图26 对比实验一

图27 对比实验二

图28 对比实验三

图29 对比实验四
经过仔细分析,其原因为:真实攻击中经常需要等待被攻击方的反馈来进行下一步的攻击,而本系统中将反馈变量符号化进行求解计算,无需等待真实靶机反馈,故流量产生较快。
然而本文认为攻击数据包发送时间间隔缩小并不会影响其在各类安全产品中的测试效果。因为当前大部分威胁情报系统、防火墙等都主要根据数据包内容进行特征匹配,而数据包间隔受客观网络环境好坏影响而无法确定,故几乎不考虑。因此,本文采集的攻击流量依然有相当高的研究价值。
6 符号执行效果测试
6.1 测试方法
本文收集了50个网络上公开的Python攻击脚本进行测试,挑选这些脚本时,尽可能优先选择较新的脚本。漏洞的种类涵盖了远程破解、网络应用攻击、拒绝服务攻击等各个方面且数量平均。
用本文提出的方案对这些测试攻击脚本进行处理,观察其符号执行的实际效果。并且使用本文改进的Pyexz3P项目与原本的Pyexz3项目进行性能对比。
6.2 测试结果
经过测试,本文统计了各种特征的50个攻击脚本的符号执行效果,如表3所示。

表3 通过符号执行所捕获的流量
表3中,总共50个攻击脚本,Pyexz3P成功执行了49个,仅仅在其中一个包含特殊形式参数的攻击脚本上执行失败,但是强制执行成功。而Pyexz3原项目则有20个攻击脚本符号执行失败,个别脚本上还出现了多个错误。最终统计出由于路径爆炸而失败2次,由于关键变量形式特殊而失败4次,由于没有主函数而失败17次,由于没有字符串符号执行能力而失败2次。
6.3 结果分析
从结果数据中可以看出,本文的方案由于使用了广度优先算法而成功跳出了测试脚本中的2个包含100次以上循环结构的攻击脚本。而使用深度优先策略则在这样的大量循环结构中难以逃脱。
本文在第2节中的预处理使得本文的方案在避免特殊形式参数、不规范的主函数上的能力大大提升。这也是直观数据上本方案对原项目效果最明显的改进,甚至超越了符号执行技术本身。
虽然原项目仅仅因为字符串符号执行的问题失败了两次,但是测试脚本中涉及字符串约束计算的攻击脚本也只有两个。因此其实本文在字符串符号执行能力上的改进是从无到有的大改进,并且也使本方案达到了工业可用的水平。
7 结 语
本文提出了一整套自动化提取网络攻击Python脚本的流量收集方法。相比于一般针对脚本的符号执行项目,本文注意到了对脚本的预处理在整个自动化分析中的关键作用并详细阐述了这个预处理过程中需要进行的各项处理,从而使得本项目的稳定性大大提高。
此外本文以符号执行为自动化提取流量的核心,同时也注意到了这项技术当前客观发展的不足而提出了强制执行作为候补方案,从而极大地提高了本系统提取攻击流量时的稳定性与成功率。
在测试阶段,本方案展示出了不俗的提取效果,所提取的网络攻击流量真实度很高,攻击特征保留完好。并且符号执行功能上的改进也使得本方案的通用性和健壮性大大增强。对于之后的安全研究工作有着积极的推动作用。
由于求解器技术的发展限制,一些约束问题的求解方法在当前客观的计算机算法科学或者数学科学发展程度下是无法求出合适答案的。因此,希望之后符号执行领域或者求解器领域相关研究工作可以加入最新的求解算法来增强符号执行引擎的求解能力,扩大其可以处理的约束条件范围。这个方向的发展进步无疑可以在日后提高本项目中顺利使用符号执行进行流量生成的脚本比例,同时降低生成流量效果较为逊色的强制执行比例。
本文解决的是使用Python语言编写的网络攻击脚本。尽管Python的确是大部分网络攻击脚本所使用的编程语言,但是也有许多网络攻击脚本使用了别的编程语言如Ruby语言。故希望有别的项目可以参考本文,对更多编程语言的攻击脚本进行自动化分析与流量采集。
由于本文针对的对象是网络攻击脚本,因此其跳转逻辑往往并不复杂,判断语句所产生的约束条件也十分易于被当前的求解器解决。因此,作为符号执行引擎的补救方案——强制执行,实际用到的比例较低。故对于这个补救方案并没有做过多的优化,因为这在本项目中的回报并不明显。但是对于目前许多符号执行引擎技术依然是空白的新编程语言来说,强制执行是一个很好的候选方案。这个方案的技术入门门槛低,建设成本小,并且效果也能满足大多数测试需求。因此,希望这个方案可以被其他项目参考选用并被优化。
