基于网络节点文本增强的链路预测算法
2019-04-01赵海兴冶忠林
曹 蓉 赵海兴 冶忠林
1(青海师范大学计算机学院 青海 西宁 810008)2(陕西师范大学计算机学院 陕西 西安 710062)3(青海省藏文信息处理与机器翻译重点实验室 青海 西宁 810008)4(藏文信息处理教育部重点实验室 青海 西宁 810008)
0 引 言
近年来,网络中的链路预测问题已广泛受到学者们的关注,链路预测问题一直是复杂网络领域中的一个研究重点,也取得了很多的成就。网络中的链路预测一般指的是通过某种预测算法利用已知网络的节点和结构等信息,来预测下一时刻网络中不相邻的两个节点之间产生连边的可能性[1-3]。该预测包括未知预测和未来预测。常见的链路预测方法有:基于节点属性信息、基于网络结构和最大似然估计法。通常情况下,与节点的属性信息相比,更容易获得网络的结构信息,而且网络的结构信息也相对比较可靠。此类方法对于结构相似的一类网络都比较适用,并且从一定程度上减轻了对不同网络需要机器学习来获得一些特定的参数组合。文献[4]提出一种基于网络拓扑结构相似性的链路预测方法,基于网络拓扑结构的相似性指标可分为两类,分别为基于节点的相似性指标和基于路径的相似性指标,并在社会合作网络中进行了预测,分析了预测的效果。
基于网络结构的最大似然估计方法是另一类链路预测方法。2008年,文献[5]在层次结构的网络中提出了一种运用网络层次结构的链路预测方法,并在层次网络中进行了预测,结果显示预测效果确实比较明显。此外,还利用随机分块模型[6-9]对网络中的错误边和缺失边进行了预测。在文献[6-9]中首次提到网络中存在错误连边的概念,即在已知的链接中很可能存在着一些错误的链接,如人们对蛋白质相互作用关系的错误认识。
随着网络技术的不断发展,计算机性能的日益提升,仅对网络节点属性的预测不能够真实精确地反映出目标网络的特性。目前,尤其针对大规模网络,还没有较好的预测算法。近几年,深度学习在表示学习网络的特征提取上取得了非常巨大的进展[10]。基于此方法的启发,我们进一步关注到了网络表示学习算法。网络表示学习又叫作网络特征学习,它是机器学习领域里一个非常重要的研究领域,该方法的目标是通过对目标网络的特征进行学习,将网络中的每一个节点表示为一个低维向量[11]。网络表示学习方法可以更好地帮助我们理解节点之间的语义关系,且能更进一步缓解由于网络稀疏性带来的不便。现存的大部分网络表示学习算法都是基于网络结构的。例如DeepWalk[12]算法,该算法起源于Word2Vec[13-15]算法。DeepWalk算法利用随机游走获得当前节点的上下文,然后将上下文节点输入到神经网络中进行训练。
然而,现实世界中,网络的一个节点通常包含了非常丰富的信息。例如,在引文网络中,每个节点中含有该节点的论文标题、类别属性等。假设,两个节点的文本内容中含有较多的共现词语,那么,这两个节点属于同一类别的概率也较大。另外,已有研究证明了,DeepWalk算法其实质为矩阵分解,分解的目标矩阵记为M。基于此,本文提出一种基于网络节点文本增强的链路预测方法。它将网络结构和节点的文本属性信息结合起来,该算法也是基于DeepWalk算法之上。与DeepWalk算法不同的是,在目标矩阵M的分解上,考虑了网络节点的文本属性信息。因此,本文提出的TELP算法旨在通过对目标矩阵的分解的同时融入了网络节点的文本内容,使得得到的网络表示中既含有了网络的结构属性,又有了网络节点的文本属性。最后,通过三个数据集实验仿真,并将仿真结果与现存的众多链路预测算法相比较,实验证实本文算法取得了较好的预测效果。
1 相关工作
常见的链路预测算法主要是基于节点相似性的预测算法,该类算法包括基于局部信息的相似性指标、基于路径的相似性指标以及基于随机游走的相似性指标。
基于局部相似性指标的方法通常指的是基于共同邻居CN(Common Neighbors)的相似性指标[16]。CN指标可以理解为,若两个节点拥有很多的共同邻居,则这两个节点相似,它们的共同邻居数越多,相似性也就越高。考虑节点的共同邻居,以及两端节点的度对网络的影响,可将其细分为6种相似性指标,分别为:余弦相似性(Salton)指标[17]、Jaccard指标[18]、Sorenson指标[19]、大度节点有利指标HPI(Hub Promoted Index)[20]、大度节点不利指标HDI(Hub Depressed Index)[21]和(LHN-I)指标[22]。若考虑共同邻居节点的度的信息,又可分为AA(Adamic-Adar)指标[23]和资源分配RA(Resource Allocation)指标[21]两类指标。
基于局部相似性的算法是一种比较直观、简单的算法,其计算复杂度相对较低,然而该方法只关注目标节点和其邻居节点的属性信息,并没有完全挖掘出整个网络所携带的丰富的信息,导致节点相似性分数的分布过于集中,节点对与节点对之间的区分度太低,从而导致算法的预测精度受到了一定的限制。但是,该类算法的优点是可以在大规模网络中进行链路预测。
CN指标本质上可以看成是二阶路径指标,周涛等[24]在基于共同邻居的相似性指标的基础上,考虑了三阶路径的因素,提出了基于局部路径的相似性指标。该类指标有3个,分别为局部路径指标、Katz指标[25]和LHN-II指标[22]。Katz指标考虑了网络的全部路径,其定义为:
al(Al)xy
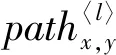
基于路径的链路预测算法考虑了节点之间的路径信息,但是由于在节点之间存在多条路径,且路径搜索算法具有较大的计算复杂度,因此,导致了这类算法计算代价大。这类算法的优点是考虑了所有的路径信息,因此,在链路预测任务重通常具有很好的性能。
基于随机游走的相似性指标可以分为基于网络全局的随机游走指标和基于局部的随机游走指标两大类,基于全局的随机游走指标主要包括平均通勤时间ACT(Average Commute Time)[26]、基于随机游走的余弦相似性(Cos+)指标[27]、有重启的随机游走指标RWR(Random Walk With Restart)[28]、SimRank指标(SimR)[29]。基于全局的随机游走指标往往计算复杂度都比较高,很难应用于大规模网络中。刘伟平[30]等提出了一种基于网络局部随机游走的相似性LRW指标(Local Random Walk),该指标不同于全局随机游走的指标,它只考虑了有限部署的随机游走过程。它包括基于局部随机游走指标和有叠加效应的局部随机游走SRW指标(Superposed Random Walk)两种指标。
基于随机游走的链路预测算法可被高效地应用于链路预测任务中,且具有很高的精度。只是这类算法仅仅是基于节点之间的随机游走,并没有考虑节点之间的结构特征属性。如果首先挖掘节点之间的结构特征,之后再基于该结构特征进行链路预测研究,那么该算法的预测性能就会得到较大的提升。
当然,还存在一些其他的相似性算法,比如基于矩阵森林理论的矩阵森林指数MFI算法(Matrix Forest Index)[31]、自洽转移相似性算法[32]等。
虽然目前也有将文本信息融入链路预测的一些算法,但是这些算法是将文本中的词语作为一类特殊的节点考虑,其实质是构建异构网络进行链路预测。本文通过将文本信息转化为文本特征矩阵,之后通过分解网络特征矩阵步骤,将文本特征的影响因子融入到网络节点的表示向量中。文本算法的实质是基于神经矩阵分解模型挖掘网络结构特征,之后再基于该特征向量进行链路预测。因此,与传统的基于异构网络的链路预测算法有着本质的区别。本文使用的基于神经矩阵分解的链路预测算法也异于本节中介绍的3类基于节点相似性的链路预测算法,是一种简单高效的链路预测算法。与该3类链路预测算法最大的区别是先进行了网络结构特征挖掘,而非直接利用网络节点的连边信息直接进行链路预测。
2 算法设计
已知目标网络G=(V,E),其中,点集为V,边集为E,相关的节点文本信息矩阵为T∈Rft×|V|,ft为文本特征的维度。本文提出一种基于文本增强的链路预测方法(TELP),该方法不仅结合了网络的结构特征,而且也考虑了网络中节点的文本属性信息,从而更有效地挖掘到目标网络的结构特征,以便更好地理解目标网络。
2.1 基于矩阵分解的DeepWalk算法
DeepWalk算法是由Perozzi等[12]提出的一种基于深度学习的网络表示模型,该模型是一个浅层的三层神经网络,它由输入层、投影层和输出层组成。DeepWalk提供了两种实现模型,即CBOW(Continuous Bag of Words)模型和Skip-Gram模型。DeepWalk使用了层次化的softmax函数和负采样方法来优化模型的训练过程,相比于语言模型中的Word2Vec算法,DeepWalk算法将随机游走的过程中生成的节点序列当作句子,其中的节点看作文本中的词,来训练和学习目标网络的节点向量表示。由于DeepWalk算法其实质为矩阵分解,因此,DeepWalk算法的目标函数为:
(1)

Yang等[33]证明了DeepWalk算法实质上等价于分解目标网络的矩阵M,因此,在文献[33]和文献[34]中定义了式(1)中的M如下:
Mij=log2(ei(A+A2+A3+…+At)j/t)
(2)
(3)
式中:A表示PageRank的转移矩阵;ei表示从节点i开始随机游走时的初始状态,它是一个第i行为1,剩余行均为0的eiAt维行向量,ejAt中第j列值为从节点vi在t步之内随机游走到节点vj的概率的大小。j则表示节点vj在随机游走t步内出现在节点vi周围的次数。
从式(2)可以看出,当滑动窗口t不断增大时,DeepWalk算法计算矩阵M的复杂度达到了O(|V|3)。
2.2 基于文本信息的DeepWalk算法
DeepWalk算法单纯的使用网络的结构特征来训练节点的向量,文献[34]在网络结构特征的基础上引入节点的文本信息,提出了基于文本信息的DeepWalk算法,简称TADW(Text Associated DeepWalk)算法[34]。该算法使用诱导矩阵补全IMC(Inductive Matrix Completion)算法对M矩阵进行分解,同时将目标网络节点的文本属性信息引入到网络表示学习中。由于log2M矩阵中含有大量的非零元,且大部分真实网络通常是稀疏的,即O(E)=O(V),这使得算法的复杂度上升。因此,在式(2)中分解矩阵M时,可去掉log进行分解。在TADW算法中,考虑了算法的时间和空间效率等因素,直接对目标矩阵M进行分解,最终得到的分解的目标矩阵为:M=(A+A2)/2。通过TADW算法,使得矩阵分解的时间复杂度从原来的O(|V|3)大大地降低到O(|V|2)。因此,在TADW算法很大地降低了矩阵分解的时间复杂度。在目标矩阵M的分解过程中,使得下式达到最小:
(4)
本文中,也拟采用网络表示学习中矩阵分解的目标矩阵为:M=(A+A2)/2。
2.3 基于文本增强的链路预测算法
通过观察TADW算法的网络中节点表示学习,发现它不但考虑了目标节点周围的网络结构信息,而且也将节点的相关文本信息作为输入,并通过深度学习的方法不断结合网络结构和节点相关的文本信息,训练得到节点的最优网络结构的特征向量表示。通过实验表明,使用TADW算法训练出网络中任意两个节点在向量空间上的分布,这也可以很好地计算目标网络中任意两个节点不仅在网络结构上而且在文本内容上潜在的相似性。受到TADW模型的启发,本文提出了基于网络节点文本增强的链路预测算法。首先基于TADW算法并结合了与目标网络相关的文本矩阵T分解目标矩阵M,得到网络中每个节点的向量表示,然后根据余弦相似性算法,计算出任意两个节点的相似度,从而构建出最终的相似度矩阵。另外,本文算法通过TADW框架训练每个节点的表示向量,故本文的算法复杂度主要来自于训练TADW模型。由于TADW算法的训练复杂度为O(|V|2),因此,本文提出的TELP算法的时间复杂度为O(|V|2)。
定义1网络中任意两个节点i、j之间的网络结构相似性为:
(5)
本文中,基于文本增强的链路预测TELP算法的具体框架如图1所示。

图1 基于网络节点文本增强的链路预测算法框架
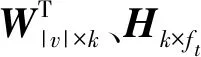
本文的算法主要由网络特征构建模块、网络表示学习模块、相似度矩阵构建模块、链路预测模块4个模块组成,每个模块的主要任务处理如下所示:
1) 网络特征构建模块:将目标网络转化成邻接矩阵的形式,然后使得矩阵M=(A+A2)/2为网络的特征矩阵。
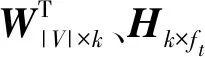
3) 相似度矩阵构建模块:对得到的目标矩阵WT矩阵中的每一行、每一列,利用定义1的余弦相似度算法计算任意节点的相似度,得到目标网络的相似度矩阵S=[Sij],其中0≤i≤|V|-1,0≤j≤|V|-1。
4) 链路预测模块:将WT矩阵分为训练集和测试集,使用AUC评价指标,评估本文算法的链路预测性能。
本文算法的主要流程由以上4个模块组成,为了更进一步详细展示本文算法,下面提供本文算法的伪代码:
输入:
目标网络G的邻接矩阵:A
数据集的训练率:training ratio
向量表示长度:k
输出:AUC
1. 计算邻接矩阵A:A=[aij]
if(i,j)∈E,aij=1/di
elseaij=0
2. 网络特征矩阵M:
M=(A+A2)/2
3.1 获取每个节点的标题
3.2 删除标题中的停用字
3.3 为每个词赋一个向量,并构建词表D
3.4 使用循环控制生成文本特征矩阵T|V|×ft:
(1) 若标题中的词出现在词表D中:
将该位置设置为1,否则设置为0
(2) 直到最后一条标题
4. 使用IMC算法分解:M
(W,H,time)=IMC(E,M,T,k…)
5. 将WT作为目标网络的节点向量:
[ei]←WT
6. 构建相似度矩阵S:
S=[Sij]=sim(i,j)
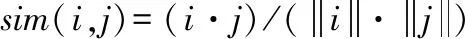
7. 计算测试集的AUC值:
7.1 将网络G分成测试集和训练集:
7.2 AUC←[training set,testing set]
结束
3 实验结果与分析
3.1 数据集和实验参数设置
本文所采用的三个数据集均为真实的科研合作网络,通过比较本文所提出的算法和现存的多种链路预测算法,进一步验证本文所提算法的有效性。本文所使用的数据集分别为Citeseer数据集、DBLP数据集和Cora数据集,有关数据集的详细信息如表1所示。
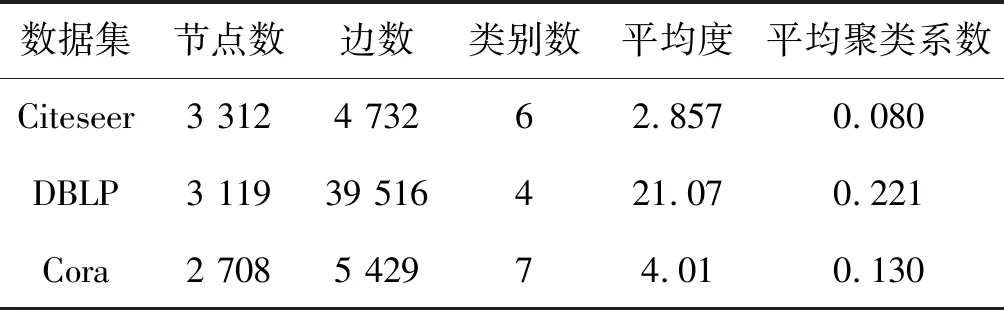
表1 数据集描述
通过表1可以看出,这三个数据集中的节点数大概都在3 000个左右,然而这三个网络中的边数却大不相同。其中,DBLP数据集中的边数最多,几乎为Citeseer和Cora 中边数的7倍多。显然,在网络节点数几乎相同的情况下,网络中的连边数S直接影响了该网络的稠密度、平均度以及平均聚类系数的大小。正因如此,三个数据集中,相比其他两个网络,DBLP网络的密度最大,平均度也最大,网络直径和平均聚类系数也最大。
在本文中使用的Citeseer、DBLP和Cora三个引文网络数据集不仅包含了节点之间的连边关系,同时也包含了每个节点的标题文本,该节点文本为引文网络中的论文题目。本文引入的TELP算法不仅建模了节点之间的连接关系,同时也建模了节点与节点文本之间的关系。因此,TELP算法训练得到的节点表示向量中既含有连接因子,也含有文本影响因子。
3.2 评价指标
链路预测算法精确度的衡量指标通常有AUC[32]、精确度和排序分等。本文采用的是AUC评价指标来衡量本文算法的准确性。AUC指标将实验数据随机地独立划分为测试集和训练集两部分,其中90%作为训练集,10%作为数据集。通过在测试集中随机地选择一条已经存在的连边的分数值比一条不存在的连边的分数值高的概率。即,每次随机地从测试集中选一条连边,再从不存在的连边中随机选一条。若测试集中的连边分数值大于不存在连边的分数,就加1分;若两者相等就加0.5分。通过独立地比较n次,若有n′次测试集中的连边分数值比不存在连边的分数值大,有n″次两者分数值相等,则AUC的值可以表示为:
AUC=(n′+n″)/n
(6)
一般而言,AUC评价指标的值应至少大于0.5,但不超过1。训练集越大,对应的AUC的值越高,算法的精确度也就越高。
3.3 对比分析
本文将目标网络的邻接矩阵分解为三个低维矩阵的乘积:M=WT×H×TT。然后基于余弦相似度方法构建网络的相似度矩阵,最后在Citeseer、DBLP和Cora三个数据集上做了仿真实验。为了进一步验证本文所提算法的有效性,用所列出的现存的多种预测方法与我们所提出的方法进行了对比。在本实验中,设置训练比例分别为0.7、0.75、0.8、0.85、0.9和0.95,以及经过训练所得到的向量长度为200,实验结果如表2所示。
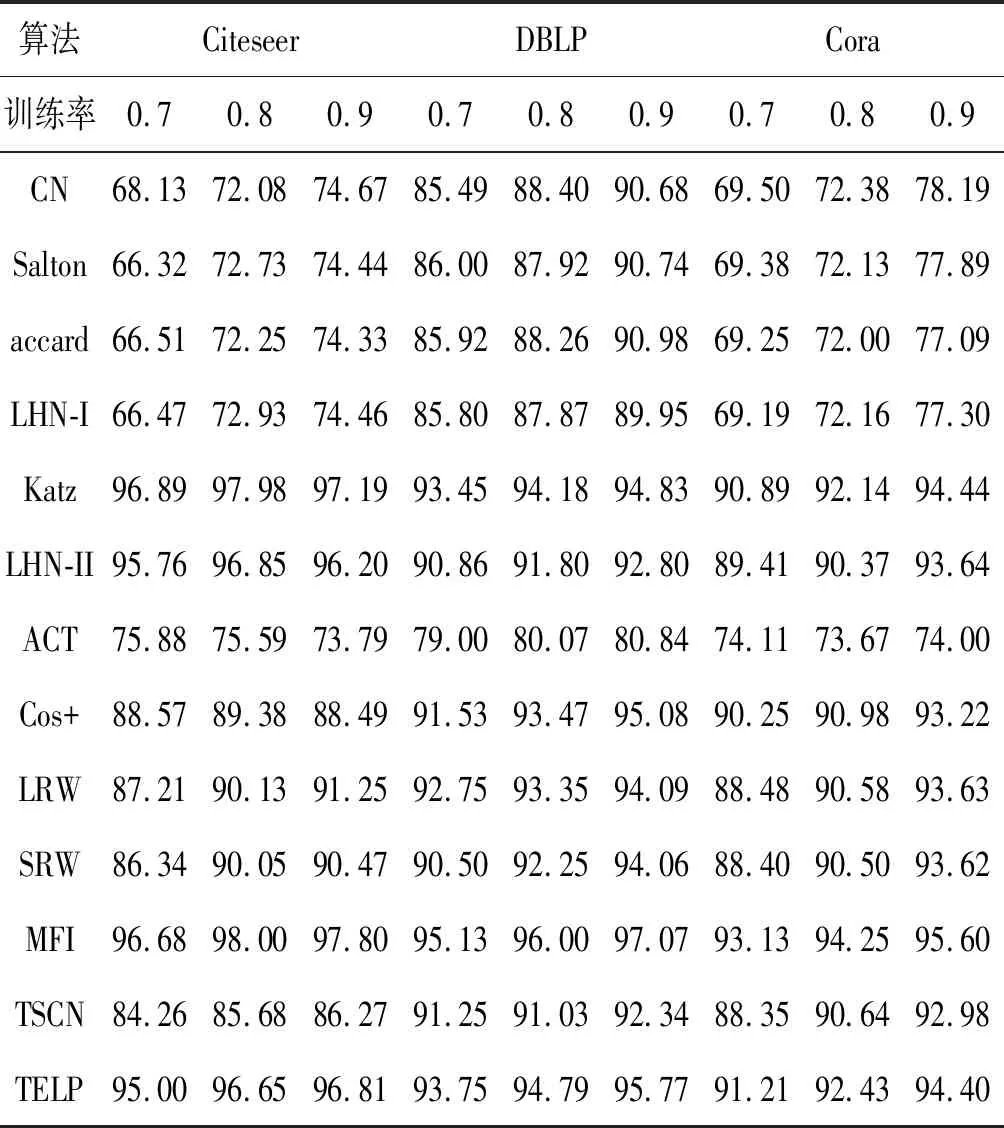
表2 Citesser、DBLP和Cora数据集上的链路预测结果
从表2中看到,本文所提出的TELP算法和现存的多种常用的链路预测方法进行了比较,通过对实验结果分析发现MFI算法在Citeseer、DBLP和Cora三个数据集上都表现出了最优的性能,Katz算法在这三个数据集上的表现基本相同,尤其在Citeseer数据集上表现较优。本文提出的TELP算法其性能也优于表2中剩余的多种算法,尤其是在Citeseer数据集上表现得比较明显。根据上述分析可知:本文所提出来的TELP算法的性能优于现存的绝大多数链路预测算法,是因为本文算法使用了基于浅层神经网络的方法,并且充分地考虑了已知网络的结构和丰富的文本信息;通过对目标网络进行无监督学习来训练网络的节点表示向量,有助于快速地从目标网络中提取信息,便于更加准确和深入地理解学习目标网络呈现其特征。
3.4 度分布
度分布是对一个网络中节点度数的总体描述,网络的度分布通常指的是网络中节点的度的概率分布。现存的绝大多数复杂网络都具有无标度性,即其度分布服从幂律分布的网络。可以看出,研究网络的度分布指数可以基本确定一个网络的类型。通过研究复杂网络的度分布,可以帮我们更好地认识、分析目标网络的拓扑结构和动力学行为等。可见,度分布是复杂网络中的一个非常重要的参数,对网络的度分布研究也具有十分重要的研究价值。本文通过Matlab编程计算出Citeseer、DBLP和Cora三个数据集网络中每个节点的度分布及频率,如图2所示。
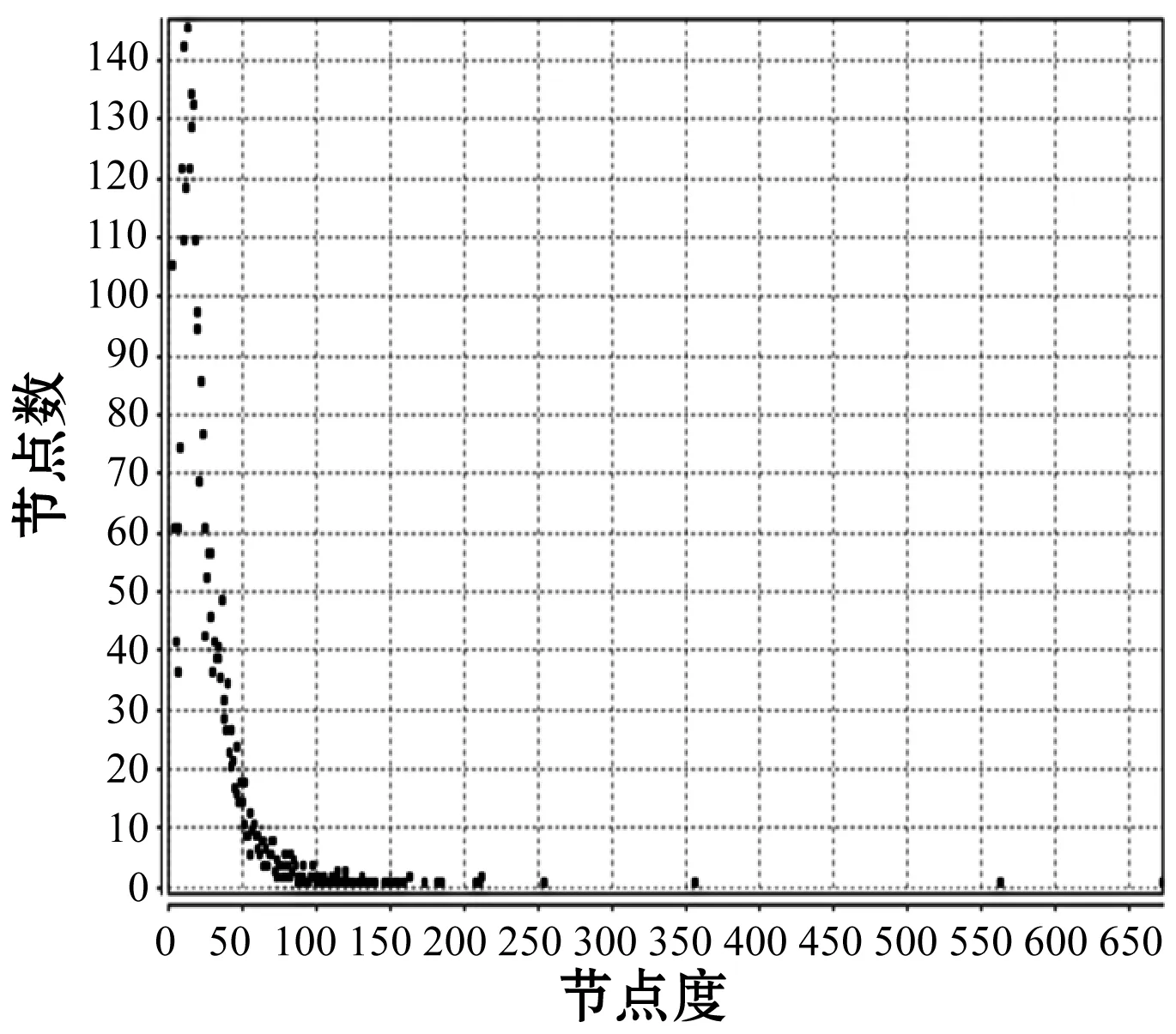
(a) Citeseer 数据集
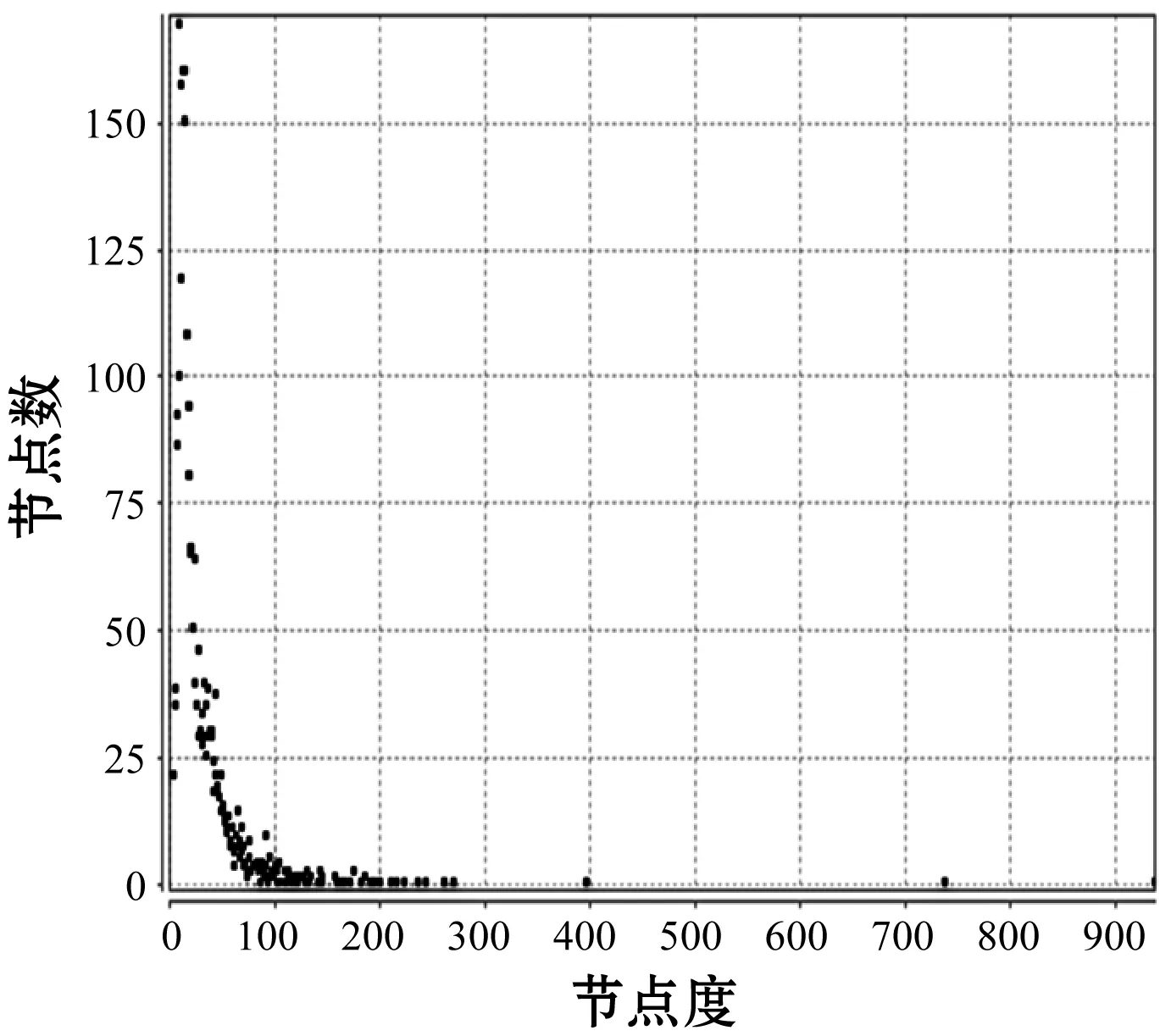
(b) DBLP数据集
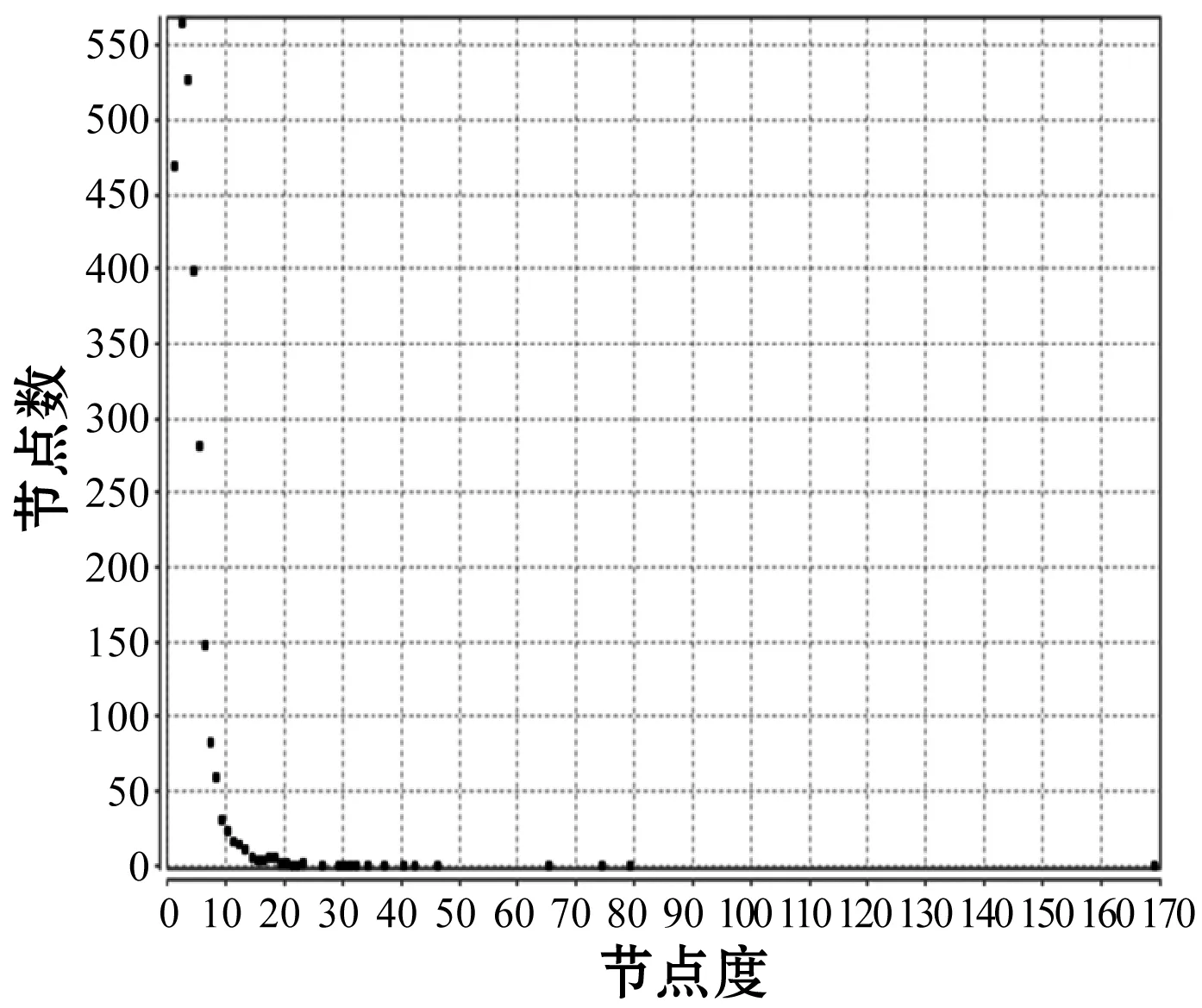
(c) Cora数据集图2 在Citeseer、DBLP和Cora数据集上的度
图2中的横坐标表示数据集中该节点度的大小,纵坐标表示数据集中该度值对应的节点个数。根据这三个数据集的度分布可以看出,Citeseer数据集和DBLP数据集中大度节点相对较多,但大度节点出现的频率却明显很低,反之,小度节点有较高的出现频率,其最高次数可达170余次。而Cora数据集则恰好与之相反,在Cora数据集中,虽然节点的度值都相对较小,但其度值出现的频率却明显高于前两个数据集,其度值出现的频率最高可达560余次。可见Citeseer数据集、DBLP数据集和Cora数据集并不是一个高稠密的网络。
3.5 调参与分析
在本文实验中,需要设置向量长度k值和训练比例的值。通过调整训练比例可以将已知数据分成两部分,一部分为训练集,一部分为测试集。我们对训练集中数据的邻接矩阵使用本文提出的算法进行分解,从而得到目标网络矩阵存储形式。实验的训练率对算法预测结果的影响如图3所示。
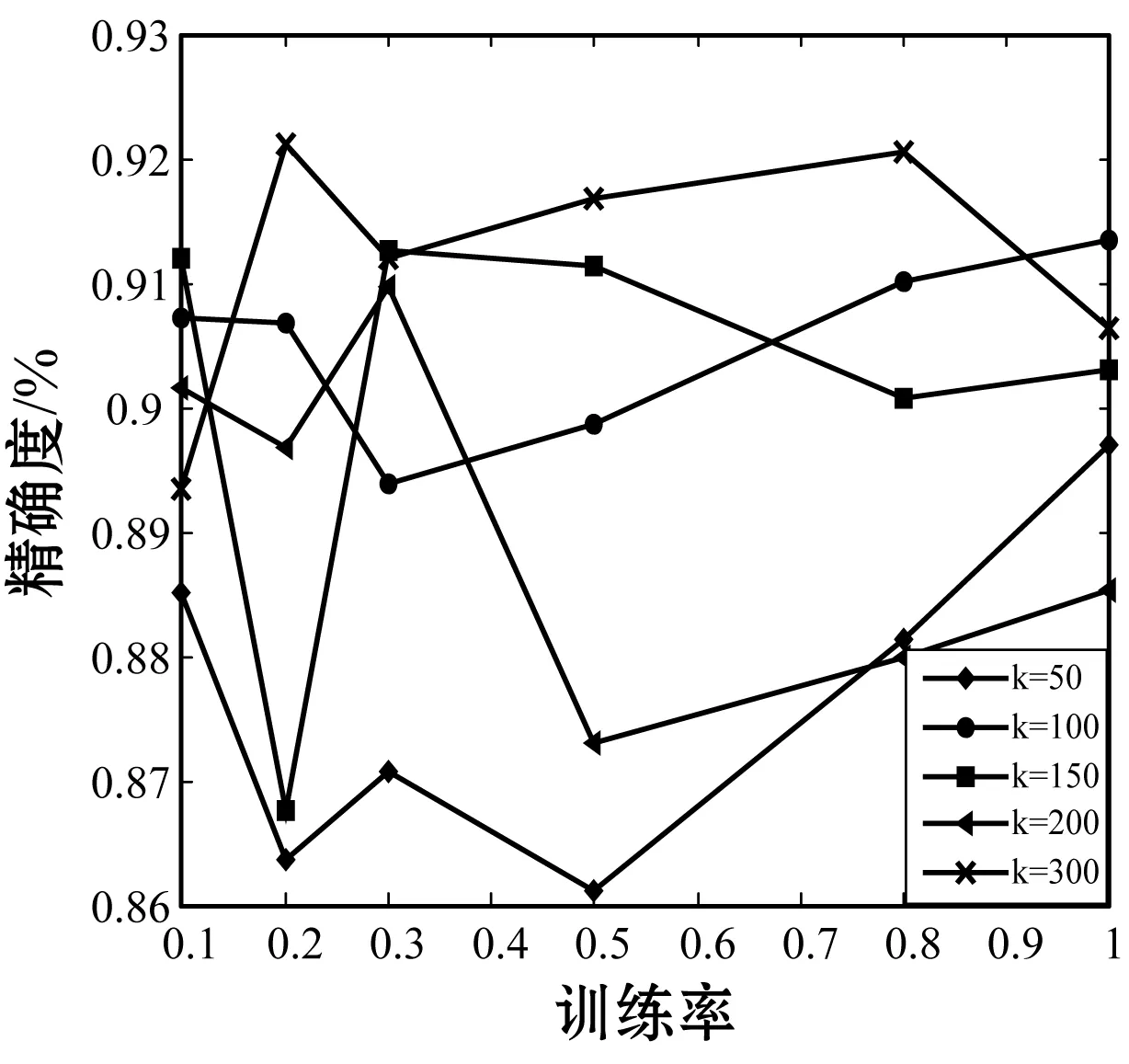
(a) Citeseer数据集

(b) DBLP数据集

(c) Cora数据集图3 训练率与预测结果之间的关联关系
从图3中可以看到,设置的向量长度分别为:50、100、150、200、300,其相应的训练集比例为:0.75、0.8、0.85、0.9、0.95。通过分析图3可以得出,由于Citeseer数据集和Cora数据集是一个相对稀疏的网络,当向量长度为100时,且对应的训练比例为0.75时,AUC获得了较好的性能;当向量长度增大到300时,且对应的训练比例为0.95时,AUC获得了最优的性能;然而DBLP数据集是一个相对稠密的网络,当向量长度大于100时,其训练比例在0.75和0.95之间,AUC的变化幅度相差都不大。因此,对于稀疏网络而言,向量长度和训练集比例的大小对AUC的影响比较大,而对于越稠密的网络,影响相对较小。
3.6 网络表示可视化
本文从Citeseer、DBLP和Cora三个数据集中,分别随机地选取3个类别,并随机地在每个类别中选取150个节点,使用T-SNE(T-distributed Stochastic Neighbor Embedding)可视化降维算法[35],将数据集中的450个节点投影到2维坐标平面上,用3种不同的形状分别表示每个数据集中的3个不同类别。本算法的网络表示可视化的投影结果如图4所示(说明:图4中横纵坐标的值为降维到2维后在坐标轴上的值,该刻度值无单位,随着可视化算法的降维效果而不断地发生变化)。
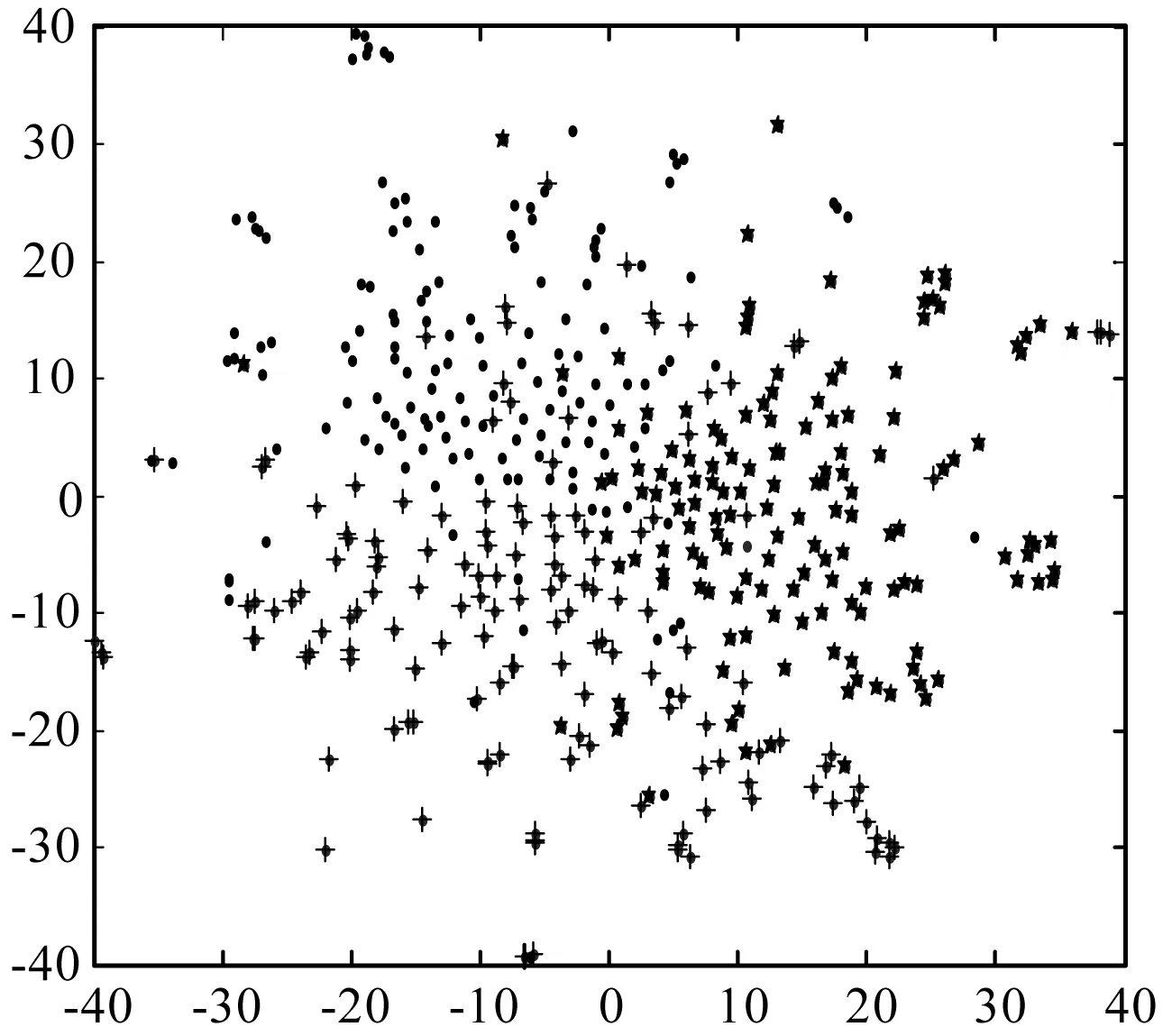
(a) Citeseer 数据集的可视化
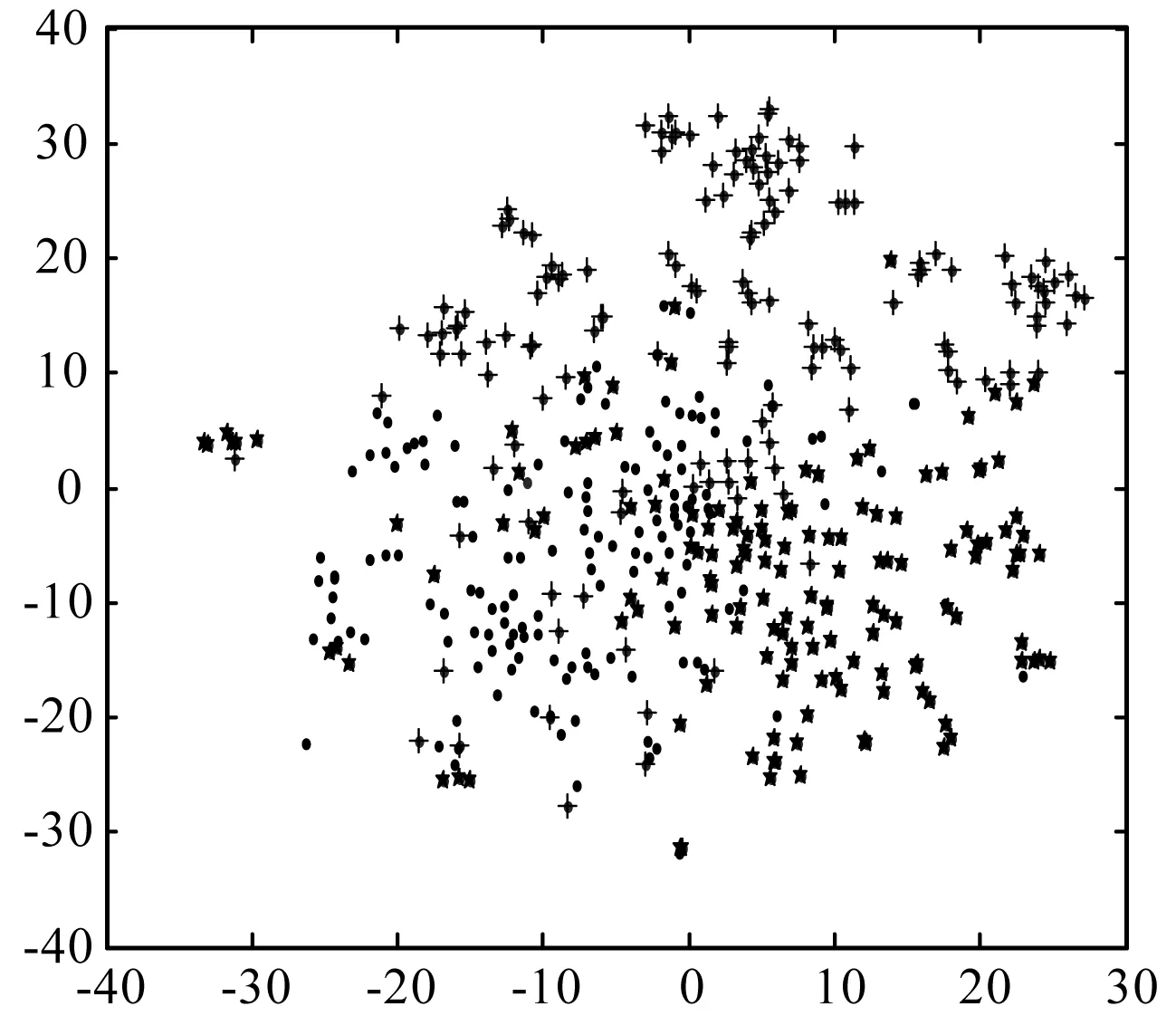
(b) DBLP数据集的可视化
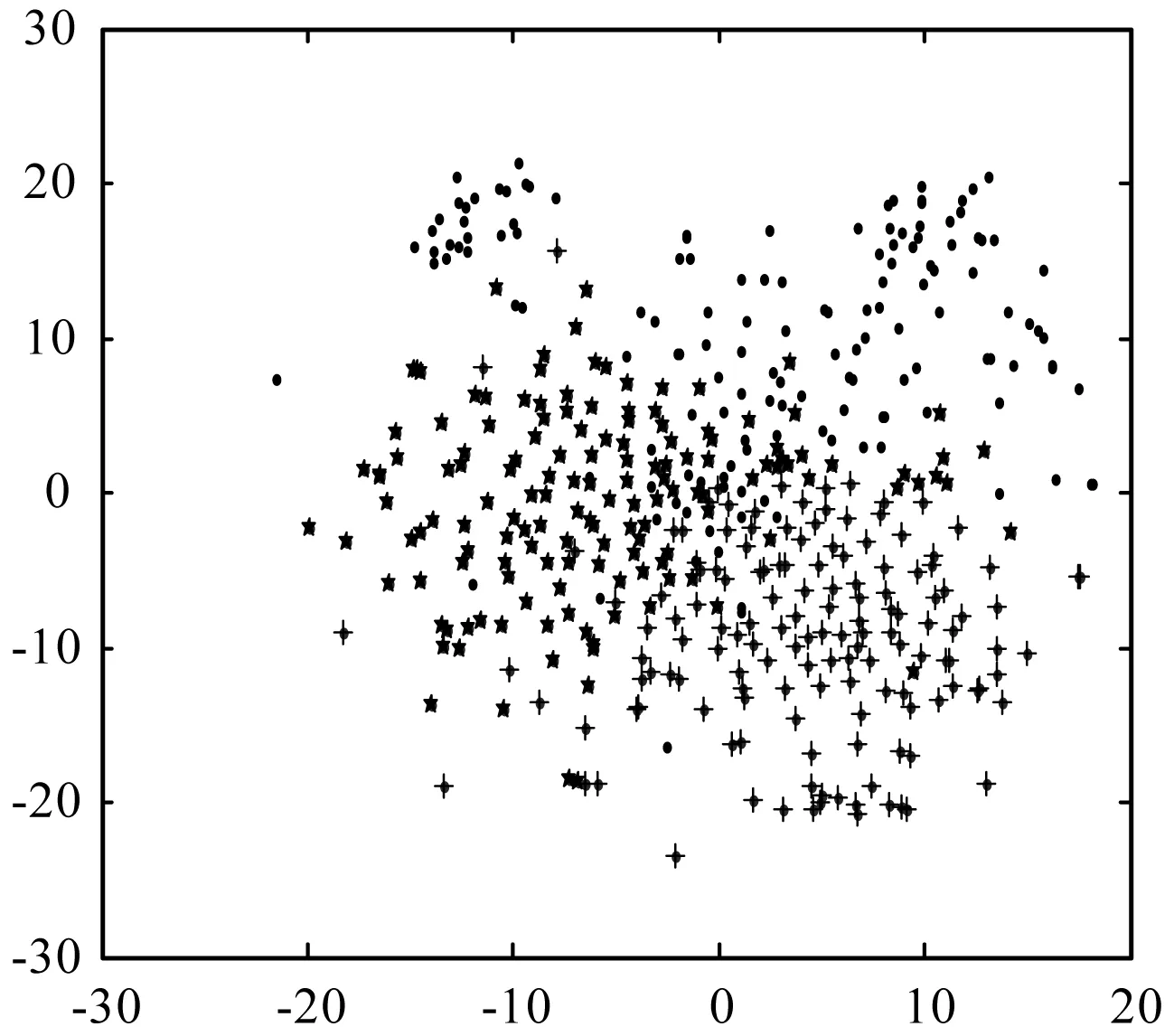
(c) Cora数据集的可视化图4 三个数据集上的网络表示2维可视化
通过观察图4可以看出,网络的2维可视化结果表现出了很好的区分能力。因此,基于网络节点文本增强的链路预测算法表示的网络节点具有很好的标签分类性能。从可视化结果中可以看出,同一种线型表示具有同类标签的节点的集合,对同类标签节点的归类之后,再使用降维T-SNE算法,将其投影到同一个2维坐标平面上。从图4的3个数据集的可视化结果中可以看出,相同形状的节点具有很明显的聚类现象,且它们表示在二维平面上的距离也比较近。因此,可以进一步表明,基于网络节点文本增强的链路预测算法可以很好地将目标网络的结构信息和节点的文本结合起来,通过预测将具有相似的网络结构节点聚集到一个相对较近的距离空间中,体现了很好的聚类性能;反之,也可将相差较大的网络节点表示到较远的距离空间中。因此,基于聚类性质的网络节点文本增强的方法可以很好地应用于链路预测领域。
3.7 案例研究
为了更好地理解基于文本增强的链路预测算法的有效性,在DBLP数据集中做了实验,DBLP数据集是一个引文网络,根据该数据集中论文的方向可将其分为4个领域,分别为计算机视觉领域、数据库领域、人工智能领域和数据挖掘领域。在该数据集中,设置目标节点的向量表示长度为200,其训练比例为0.9,并随机选取一个标题为:“Factorial Hidden Markov Models”的目标节点,分别使用DeepWalk 算法和本文所提出的TELP算法计算其对应的余弦相似度值。通过统计得到该标题中5个相似度值最高的邻居节点,最终分别筛选出了5条标题与目标标题“Factorial Hidden Markov Models”所对应。使用两种预测算法筛选出的5条标题的具体的信息如表3和表4所示。
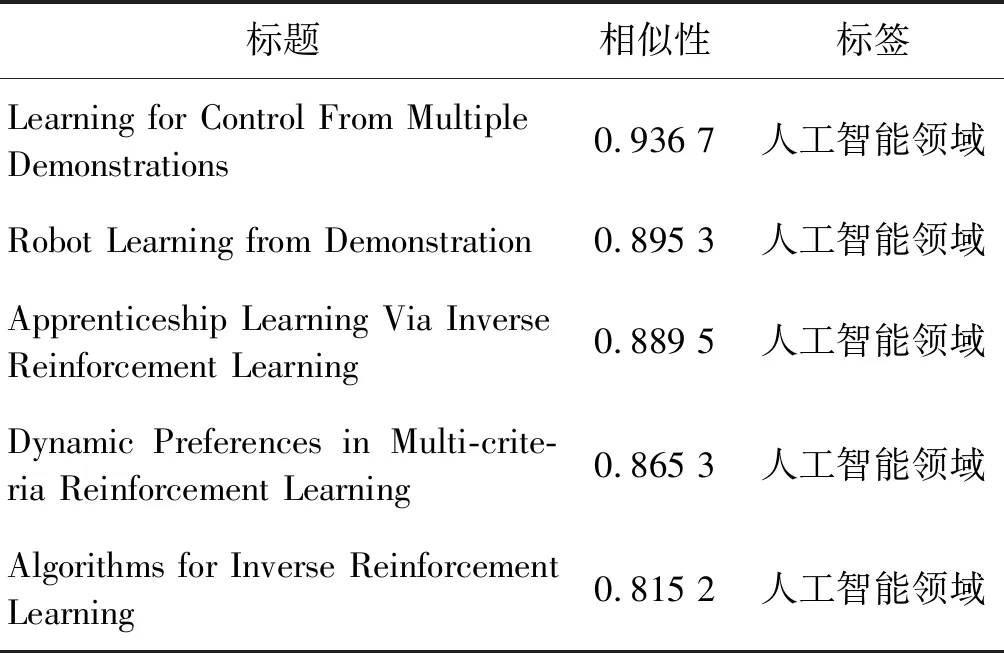
表3 DeepWalk算法案例实证研究

表4 本文算法案例实证研究
在表3和表4中,通过对网络表示的相似度计算,分别用DeepWalk算法和TELP算法返回了5条与目标标题最相关的标题。通过比较可以发现,本文提出的TELP算法要比已有的DeepWalk算法相似度高。通过计算对应的余弦相似性,发现DeepWalk算法预测出来的5条标题虽然与目标标题能达到结构上的相似,但是不能够达到文本上的相似。而在表4中,使用TELP算法预测出的5条相关标题与目标标题之间不仅在结构上而且也在文本上达到了很高的相似性。每个相关标题几乎都包含了目标标题中的关键字“Markov Models”或“Hidden”。在该实例中,本文算法显然优于DeepWalk算法。其中,使用本文算法预测出的5条标题中,第一条标题里几乎包含了所有的关键字,可以看出,这条标题与目标标题“Factorial Hidden Markov Models”的相似性达到了最高。因此,基于文本增强的链路预测算法可以有效地将网络的结构信息和节点的属性信息结合起来,从而更好地学习并挖掘网络的内部结构关联性,达到更好的预测效果。
4 结 语
针对目前链路预测问题研究中的研究方法主要是基于已知网络的结构信息,没有考虑到与已知网络相关的文本信息,本文提出了一种基于网络文本增强的链路预测算法,并应用到了三个真实的科研合作网络Citeseer、DBLP和Cora中,运用基于浅层神经网络的无监督学习方法对其进行预测。实验结果表明,在真实的网络环境中,本文算法表现出了较为优异的预测性能。通过进一步对目标网络的可视化研究发现,基于本文算法,在实验过程中,所训练得到的网络节点也具有十分明显的聚类现象,即该方法可以很好地应用于分类任务中。最后通过对实验案例的研究,充分地证明了具有相似结构和内部相似的网络节点之间的空间距离相比其他节点而言更为相近。因此,综上所述,本文算法是一种新的且行之有效的链路预测算法,它能够在真实的网络环境中表现出较为优异的预测性能。在今后的研究过程中,我们将把该方法扩展到大规模的复杂网络中进行预测分析及验证,同时,还会进一步研究更多的链路预测指标以适应更为复杂的网络结构。
