基于密度聚类的签到轨迹大数据分层预处理研究
2019-04-01文若晴杨伟伟
文若晴 马 昂 潘 晓* 杨伟伟
1(石家庄铁道大学 河北 石家庄 050043)2(河北省高校人文社会科学重点研究基地(石家庄铁道大学) 河北 石家庄 050043)
0 引 言
受数据获取手段、数据传输、数据存储等诸多因素的限制,数据“脏”的问题难以根治。数据质量优化的问题已成为分析数据、挖掘知识等研究的瓶颈,为研究人员带来了新的挑战。基于位置的社交网络LBSN(Location based social networks)广受欢迎,随之产生的时空-文本等高维数据呈指数式增长[1]。通过签到数据预处理技术,可以挖掘人类活动规律、兴趣爱好和行为特征等信息,研究人员可以据此为用户做推荐[2]。然而轨迹数据的数据量大、高维异构、多粒度性、不确定性、高冗余等特点[1],不可避免地对数据分析工作造成了困扰,因此亟待有一套完整的针对轨迹数据的数据预处理流程和方法。我们分析了一组由知名移动社交网站四方(Foursquare)抓取的真实签到数据集[3-4]。在分析过程中发现,签到数据除了具有上述特点外,还具有同时签到和时空跨度大等问题,导致不能直接使用现有的数据预处理流程和方法。
本文对于以上问题,提出了针对签到数据的基于密度聚类的数据分层预处理框架,能够使签到轨迹更好地为后续的挖掘工作所使用。具体来说,首先,对数据集中的属性值进行筛选,并滤除空数据,将签到数据依照用户编号和时间戳进行排列生成用户的签到轨迹;其次,通过平均化处理消除了签到轨迹中存在的同时签到数据;再次,学习基于熵的时间戳间隔阈值划分签到轨迹,解决了签到轨迹时间跨度大的问题;最后,使用基于密度聚类的方法对签到轨迹分层处理,解决了空间跨度大的问题。
1 相关工作
在轨迹数据上通用的数据预处理的典型流程包含异常点检测,轨迹压缩[5]以及轨迹分段等步骤。
轨迹数据的异常点检测是为了找出由于传感器错误或用户特殊行为导致的轨迹中明显不同的点,已经有许多的国内外学者对异常点检测技术进行综述,如Hodgw[6]、Chandola[7]、Aggarwal[8]、Zhang[9]及Gupta[10]等。典型检测方法有:均值平滑异常点方法,该方法规定一个尺寸为n的滑动窗口,将待测量点的前n-1个点的均值作为该点的估计值。粒子滤波方法[11],该方法首先初始化粒子xi(j),j=1,2,…,P,使得粒子具有0初始速度并且以高斯分布聚集在初始位置周围,然后以动态模型P(xi|xi-1)来概率地模拟粒子在一个时间步长内的变化。再根据测量模型计算所有粒子的权重ωi(j),权重越大则说明该粒子对测量的支持度越大。将这些重要粒子的权重归一化后,选择与归一化后权重成比例的一组粒子重复进行初始化,最终计算这些重要粒子的权重和,得到被修正后的轨迹。基于启发式的异常点检测方法[12],根据邻近轨迹点间的距离或根据轨迹点的行进速度,判断该距离或行进速度是否满足距离阈值d或速度阈值v,找到轨迹中的异常点并删除。异常点检测方法也可以分为对静态轨迹的检测和对动态轨迹的检测。对静态轨迹的检测可以对轨迹进行特征建模[13],从而将轨迹片段与特征库进行匹配,比较判决阈值。对动态轨迹的检测通常是基于历史轨迹挖掘所有的频繁模式,从而据此识别异常轨迹,Lei等[14]提出的MT-MAD方法可用于海量航海船只轨迹数据的异常检测,Zhu等[15]提出的TPRO方法可以应用于出租车轨迹数据,从而检测是否有司机欺诈绕路的异常轨迹。本文采用一种基于统计的四分位异常点检测方法处理签到数据。
轨迹压缩的目的是节省不必要的存储空间、通信、计算开销。现有的两种轨迹压缩策略为离线压缩和在线压缩。离线压缩(批量模式)是在轨迹完全生成后,减小轨迹大小的方法。该方法通过丢弃具有可忽略误差的点得到与原始轨迹近似的轨迹,这与计算机图形学和制图学研究领域的线简化问题相似[16]。利用垂直的欧氏距离,以首尾轨迹点作为压缩点,通过其连线与其他各个轨迹点的垂线距离,找到误差最大的轨迹点作为压缩点,并使用新的压缩点集合递归上述方法,直到找到的最大误差值小于指定的阈值则停止递归[17]。在线压缩,即在对象移动时实时进行轨迹压缩[18]。不同于离线压缩方法,在线压缩方法不需要得到整条轨迹,而是在轨迹増长的过程中,计算垂线距离,得到最大误差值,当轨迹增长到出现某个最大误差值超过指定阈值时,将尾轨迹点作为压缩点,并将其作为新的首压缩点,继续寻找新的压缩点,最终在轨迹完全生成后得到以所有压缩点形成的压缩轨迹。
轨迹分段的提出是由于整体轨迹的计算复杂性高,轨迹分段后能减小计算量,并且可以挖掘出更丰富的知识。现有的轨迹分段方法大致可分为三种:基于时间间隔的轨迹分段[19],该方法根据给定的时间间隔经验阈值划分轨迹;基于轨迹形状的轨迹分段,该方法通过轨迹中的转向点来划分轨迹,或使用线条简化算法(如Douglas-Peucker算法)确定保持轨迹形状的关键点;基于语义的轨迹划分,该方法考虑数据的应用场景[20]或者不同的交通模式[21],根据轨迹点的速度和加速度判断移动物体的运动方式(步行/骑行/公交/驾车……),从而据此划分轨迹,旅游者的经验和POI(Point Of Interest)停留点的学习也可以作为语义的一种,从而划分原始轨迹[22-23]。本文采用基于时间间隔的轨迹分段方法,其中轨迹点间的时间间隔的划分阈值通过基于熵的学习获得。
2 签到轨迹的生成
在本节中,我们对Foursquare数据集的格式与内容,以及签到轨迹的生成方法进行介绍。
2.1 Foursquare数据集
Foursquare网站是目前流行的LBSN之一。本文使用的实验数据集是微软研究院发布的从Foursquare网站上抓取的真实签到数据[3-4]。该数据集分别包括洛杉矶和纽约用户的签到数据,统计信息如表1所示。

表1 Foursquare数据集的统计信息
数据集中共包含5个文件:
(1) Venue(地点) Venue文件中描述的是用户签到地点的相关信息,文件中包括地点编号、名称、创建时间、经纬度和地点类别编号,我们在生成签到轨迹时使用了该文件中“地点编号”、“经度”和“纬度”,形式化地表示为关系venue(v_id,lat,lon)。
(2) Categories(类别) Categories文件是地点所属类别的信息,包括类别编号和类别名称。我们使用各个类别名称,作为签到位置的语义,形式化地表示为关系categories(c_id,c_name)。
(3) Tips Tips文件中记录的是每个用户的签到数据。Tips文件中的一条记录无时序地包含一个用户的所有签到数据,其中每一条签到数据包含签到时间、地点编号、地点类别编号等信息。其中一条签到数据形式化地表示为关系tips(u_id,v_id,createdTime,c_id0,c_id1,…,c_idn)。
(4) User(用户)和Friendship(朋友) 用户文件包含用户编号、名字、姓氏、头像、性别和籍贯。朋友关系文件中存储了用户间的好友关系,包含u_id1和u_id2两列。本文对签到轨迹的预处理不涉及这两个文件。
2.2 签到数据特点
通过对上述数据集分析发现,签到数据具备数据冗余、数据缺失、同时签到、时空跨度大等特点。
(1) 数据冗余 数据冗余是指数据重复存储的现象。例如,Foursquare数据集中的Venue文件记录了洛杉矶和纽约用户访问过的地点编号、名称、经纬度、地点类别等信息。Tips文件是用户的签到数据文件,包含用户编号、地点编号、签到文本、签到时间与地点类别等信息。很明显,两个文件都重复存储了地点类别信息,可能会导致数据的不一致。
(2) 数据缺失 数据集中存在值缺失的现象。例如,Venue文件中经度和纬度(longitude,latitude)两列,如图1所示,缺失值占0.87%。Users数据文件中的姓名、性别和家乡等列缺失值占1.94%。

图1 Venue文件中地点编号及其对应经纬度
(3) 同时签到 签到服务允许用户同时在多个地点连续签到。因此,存在用户在相同时间在多个地点签到的现象。如图2所示,u_id是用户编号,时间戳(createdTime)是从1970年1月1日00:00:00开始以秒计算的时间偏移量。图2中共有5条签到记录,这5条记录中地点编号(v_id)是不同的,但是后三条签到数据的时间戳是相同的。用户的实际位置可能仅是其中的某一个签到地点,或是与签到地点临近的某一个点。

图2 用户169961的同时签到数据
(4) 时空跨度大 签到数据跨度大主要表现在时间和空间两个方面。时间方面,数据集中包含了2008年5月6日05:47:27至2011年7月12日06:07:30的用户签到记录。我们将同一用户相邻签到数据的时间戳跨度分布进行统计,见表2(LA:洛杉矶NYC:纽约)。可以发现将近3/4的相邻签到数据时间跨度在半个月内,剩余1/4的相邻签到数据时间跨度在半个月至两年半不等。

表2 相邻签到数据时间戳跨度分布表
空间方面,数据集中的签到数据几乎覆盖全球,在以这些签到数据中最小和最大的经纬度所形成的矩形范围内,对角跨度约为398.20度,约4.4万公里。而根据不同用户形成的签到轨迹的对角跨度分布不均,统计签到轨迹空间跨度分布见表3。图3中记录了某用户的27条签到数据,图中左侧的签到数据共3条与其余的签到数据距离较远。放大图3中右侧的签到数据到图4,其中有24条签到数据,可以看到签到轨迹中被圈出来的1条签到数据与其余23条签到数据不在同一个城市而且相距很远。
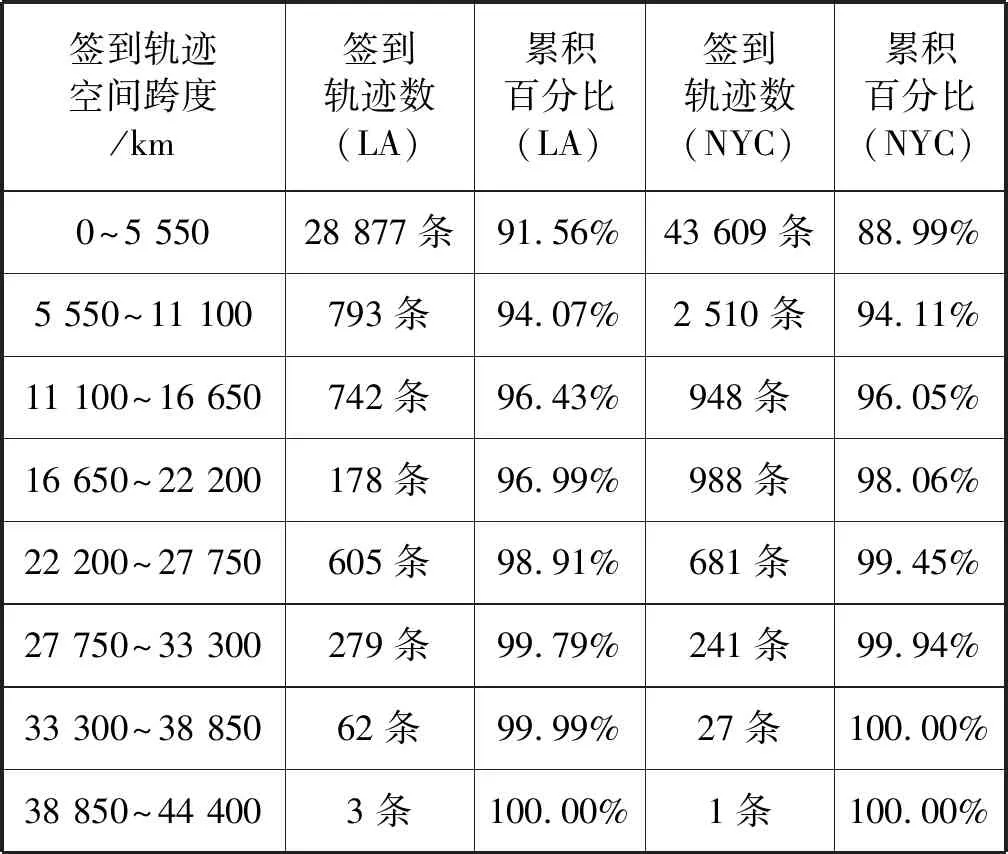
表3 签到轨迹空间跨度分布表

图3 用户100140的签到轨迹(共27条签到数据)
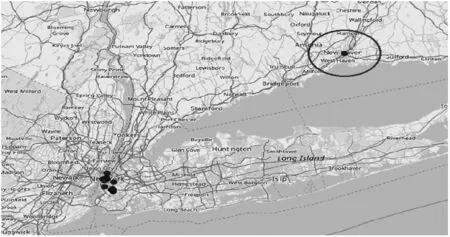
图4 用户100140的部分签到轨迹(共24条签到数据)
2.3 签到轨迹
将关系categories、venue和tips,通过v_id连接得到签到数据的经纬度信息,通过c_id连接得到签到数据的文本信息以便于生成签到轨迹后计算轨迹的文本相似性,可获得用户的一条签到数据,定义如下。
定义1签到数据。一条签到数据p=(u_id,createdTime,lon,lat,c_name0,c_name1,…,c_namen),其中,根据表1统计信息,n=0,1,…,18。
利用用户签到数据生成用户签到轨迹,即,将同一用户的签到数据按时间戳排序形成一个序列,以用户编号命名该用户的签到轨迹,定义如下。
定义2签到轨迹。一条签到轨迹Tu_id=(u_id,loc_list,word_list),其中loc_list={(p1.lon,p1.lat),(p2.lon,p2.lat),…,(pm.lon,pm.lat)}是同一个用户的所有签到数据按时间顺序排列的地理坐标对序列,且pi.createdTime-pi-1.createdTime≥0。签到轨迹的word_list是所有签到位置的类别名称的并集,并以空格隔开形成的一个字符串。
3 签到数据预处理
3.1 签到数据预处理总流程
签到数据的预处理主要包括:数据清理与数据转换、签到轨迹划分、签到轨迹分层,其流程见算法1。
算法1签到数据预处理流程
输入:原始签到数据
输出:分层的签到轨迹集
1 选择有用属性,减少冗余
2 选择完整信息,滤除含有缺失值的数据
3 生成签到轨迹
4 FOR every签到轨迹{
5 平均化同时签到点
6 检测并删除每条轨迹的离群点
7 }END FOR
8 学习时间戳阈值,划分签到轨迹
9 计算签到轨迹间的相似性,聚类并分层签到轨迹
对于签到数据因被存储在多个文件所造成的数据冗余以及数据缺失的问题,首先进行初步数据清理,然后将签到数据转换为签到轨迹,并对每一条轨迹中同时签到数据和离群签到数据进行清理。由于签到轨迹数据时间、空间跨度大的特性,还要对签到轨迹进行划分和分层,采用基于熵的方法学习用于划分签到轨迹的时间间隔阈值,分层采用基于密度的DBSCAN聚类算法聚类签到轨迹。
(1) 选择有用属性和完整信息 Foursquare数据集中存在数据冗余和缺失。对于冗余,选择各个文件中的有用维度生成签到轨迹,避免同一信息多处存储;对于缺失值,选择使用包含完整信息的数据。
(2) 生成签到轨迹 将Tips文件中各用户的签到数据按签到时间排序,并与venue连接得到签到数据的经纬度信息、与categories连接得到签到数据的文本信息,以方便后续计算签到轨迹的时空和文本相似性。
(3) 平均化同时签到 数据中存在很多如图2所示的同时签到数据。具有多条同时签到数据的用户可能只在其中一个地点或者都不是。为了使签到轨迹更合理,本文将这些相同时间戳的签到数据进行平均化处理。
具体来讲,对于每一个用户的签到轨迹,若用户的n个签到数据的时间戳相同,则将这n个签到数据的经度和纬度分别取均值,以得到的新经纬度作为该时间戳的签到地点。对于n个签到数据的文本,将其去重后以空格分隔合为一个字符串,作为该时间戳的文本。例如用户169961在同一时刻对6个地点进行签到,基本信息如表4所示,各个地点的经纬度都不相同。计算得到经度和纬度的平均值分别为-79.028 9和36.146 3,最终得到该用户在这一时刻的签到数据如表5所示。

表4 用户169961的部分签到数据

表5 用户169961的部分签到数据平均化结果
(4) 检测并处理签到轨迹离群点 根据统计知识,一个序列上如果有值在序列上所有值的上下四分位的1.5倍四分位距以外的范围,这样的值是离群的。将用户签到轨迹可视化后,我们发现用户的轨迹存在如图3、图4的情况。对于这样的签到轨迹我们提出一种基于统计的四分位检测离群签到数据的方法处理用户的签到轨迹,算法基本思想是将每条待处理签到轨迹的经度和纬度分别排序并计算分别的四分位数(Q1,Q2,Q3)、四分位距(IQR=Q3-Q1)和内限(Q3+1.5×IQR,Q1-1.5×IQR),并分别找到并标注经度和纬度上的离群值,最后将签到轨迹上被标注为离群的签到数据删除。
(5) 划分签到轨迹 签到轨迹的相邻签到数据中约1/4的时间戳跨度分布在半个月至两年半不等,这使得在原始签到轨迹上直接计算的结果没有意义。基于时间阈值的轨迹划分将一条轨迹划分为了几条轨迹使相邻签到数据的时间戳跨度在一定合理范围内。我们通过基于熵的方法学习适用于划分签到轨迹的时间间隔阈值,从而划分签到轨迹,具体方法见3.2节。
(6) 分层签到轨迹 签到轨迹分层用以解决签到轨迹空间跨度大的问题。通过计算签到轨迹间的相似性,对签到轨迹根据轨迹的时空文本相似性进行聚类,并通过调整聚类参数,得到不同层次粒度的签到轨迹集合。
3.2 基于熵的签到轨迹划分
轨迹划分中最常用的方法是按时间阈值将轨迹分段,但该方法中时间间隔阈值难以确定,这也是签到数据预处理流程中的一个难点。我们使用Cui[24]提出的基于熵的轨迹时间阈值学习方法,确定一个较客观的轨迹划分阈值,具体方法如下。
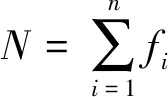
(1)
设t是时间间隔阈值,则小于t的间隔分布的熵的定义如下:
(2)
大于t的时间间隔分布的熵的定义如下:
(3)
签到轨迹划分的目标是在多个t中找到使得熵E1和熵E2的和最大的阈值θ,公式如下,当两个连续的签到轨迹时间间隔大于阈值θ时,则将划分该签到轨迹为两条签到轨迹。
(4)
4 基于密度聚类的签到轨迹分层
在本节中,将对签到轨迹的分层处理做详细说明,包括对用户签到轨迹进行相似性定义和基于时空文本相似性的聚类方法。
4.1 签到轨迹的时空-文本相似性
签到轨迹相似性包含三个方面:空间、时序和关键字(即类别名称)。离散弗雷歇距离是目前被广泛用于计算不同多边形轨迹曲线间距离的方法,它动态地考虑了轨迹点的时序和空间相似性,因此本文选用离散弗雷歇距离计算用户签到轨迹间的时空距离。同时,在关键字相似度方面,Jaccard系数是基于字符串语义相似性度量中常用的方法之一,其对于两个用于计算相似性的向量的维度没有限制。因此,本文结合二者优点提出了签到轨迹的时空文本相似性度量方法。
定义3离散弗雷歇距离。设任两条签到轨迹T1、T2,T1有m个签到点,T2有n个签到点生成。T1和T2的离散弗雷歇距离为:
(5)
当m=0,n=0时,DFD计算方法如下:
DFD(T1.p0,T2.p0)=Dist(T1.p0,T2.p0)
(6)
当m>0,n=0时,DFD计算如下:

(7)
当m=0,n>0时,DFD计算如下:
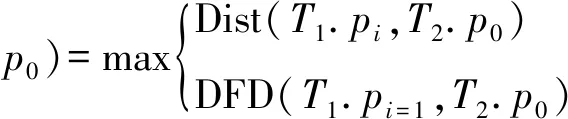
(8)
式中:Dist(pi,pj)是任意两个签到数据pi与pj间的欧氏距离。
下面用一个简单的例子解释离散弗雷歇距离的定义。现有两条签到轨迹T1={(0,0),(1,0),(2,-10),(3,0),(4,0),(5,0)},T2={(0,0),(1,0),(2,0),(3,0)}。轨迹T1和T2的DFD值根据定义3可以得到一个如图5所示的二维矩阵,签到轨迹T1和T2的离散弗雷歇距离为10。若两条签到轨迹的离散弗雷歇距离越大则说明它们在时空上距离越远。
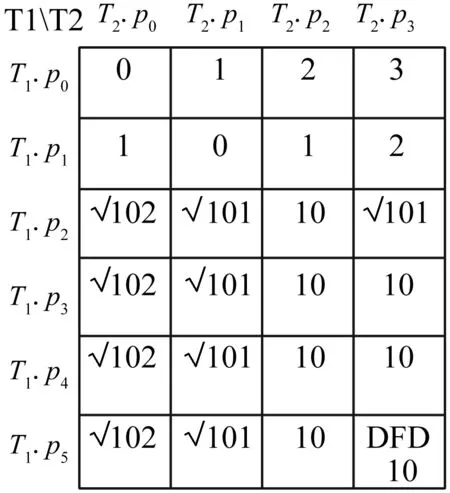
图5 签到轨迹T1和T2的DFD二维矩阵
定义4基于Jaccard系数的文本相似性。签到轨迹T1和T2的类别集合的文本相似性定义如下:
(9)
可见SimJCD∈[0,1],越接近于1表示两条轨迹的文本方面越相似。
定义5签到轨迹相似性。对于给定的两条签到轨迹T1、T2,签到轨迹相似性形式化的表示为:
SOT(T1,T2)=α×SimDFD+(1-α)×SimJCD
(10)
(11)
式中:SimDFD是基于离散弗雷歇距离的时空相似性,SimDFD∈[0,1],越趋近于1表示两条轨迹的时空方面越相似;参数α∈[0,1],为轨迹的时空相似性的权重。SOT∈[0,1],越趋近于1,则两条签到轨迹在时空-文本方面越相似。在同一个用户签到轨迹集D内,不同的α,可以得到不同的SOT值和轨迹相似性矩阵M。
4.2 基于DBSCAN的签到轨迹分层
4.1中已经得到签到轨迹间的相似性,现在要据此对签到轨迹进行聚类,从而得到分层的签到轨迹簇。算法2的输入包括签到轨迹集D,任两条用户签到轨迹的轨迹相似性矩阵M,最小簇轨迹数阈值MinTrs和聚簇半径Eps。
如算法2所示,初始状态下,任选一个未被访问的签到轨迹T,找出与T间的签到轨迹相似性SOT大于等于阈值Eps的所有签到轨迹,记为N。如果N中签到轨迹数量小于阈值MinTrs,则T被标记作为噪声舍弃(第2~6行)。如果N中签到轨迹数量大于等于阈值MinTrs,则T与其N中的签到轨迹形成一个簇c,并且T被标记为已访问(第7~12行)。以相同的方法处理该簇内所有未被标记为已访问的签到轨迹,从而对簇进行扩展(第13~16行)。如果簇充分地被扩展,即簇内的所有签到轨迹被标记为已访问,则用同样的算法去处理未被访问的签到轨迹。
算法2签到轨迹的DBSCAN聚类
输入:D,M,MinTrs,Eps
输出:簇集合C
1 初始化簇集合C=null
2 FOR every没有被访问的轨迹T in D{
3 标记T为已访问
4 N={T′|SOT(T,T′)≥Eps}
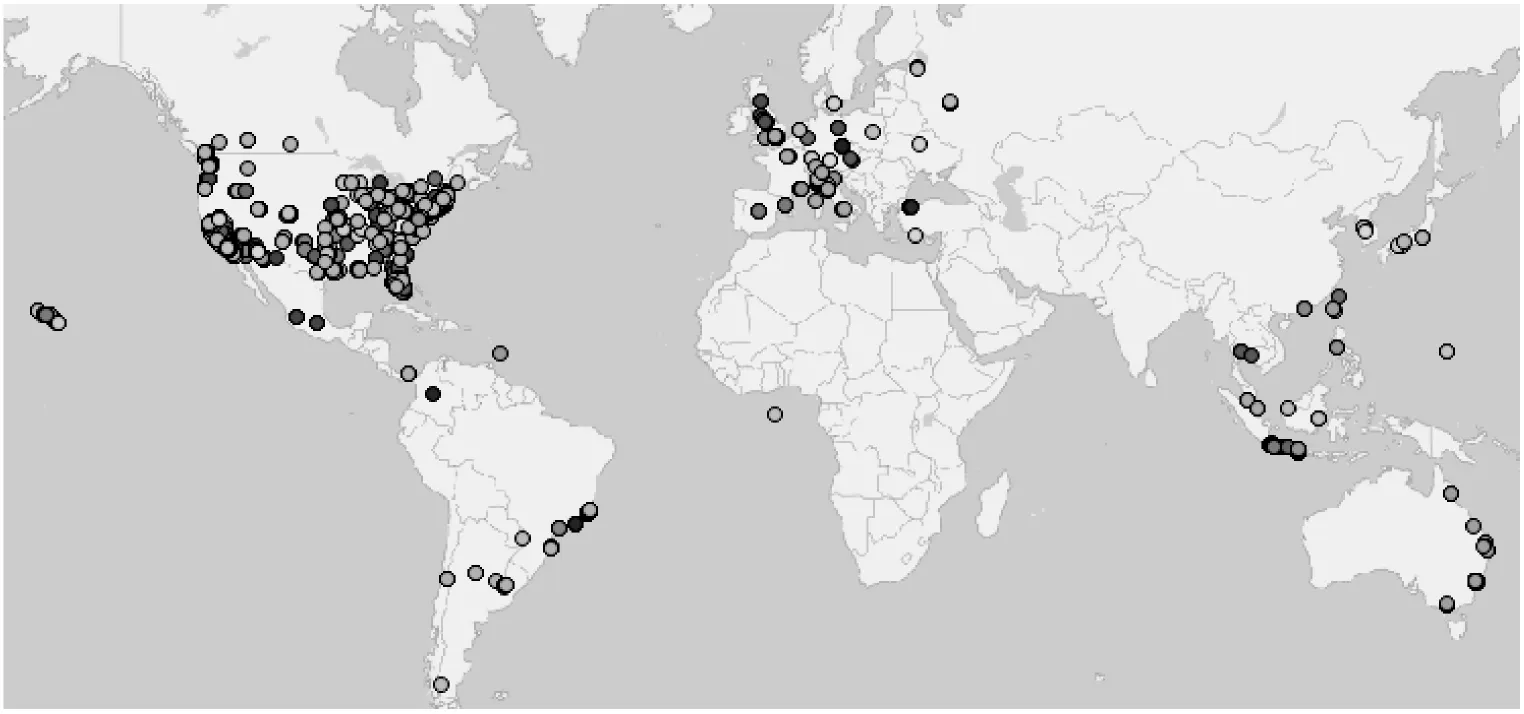
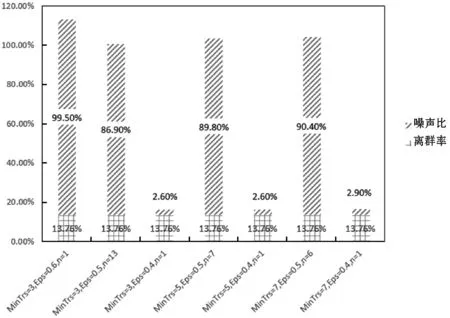
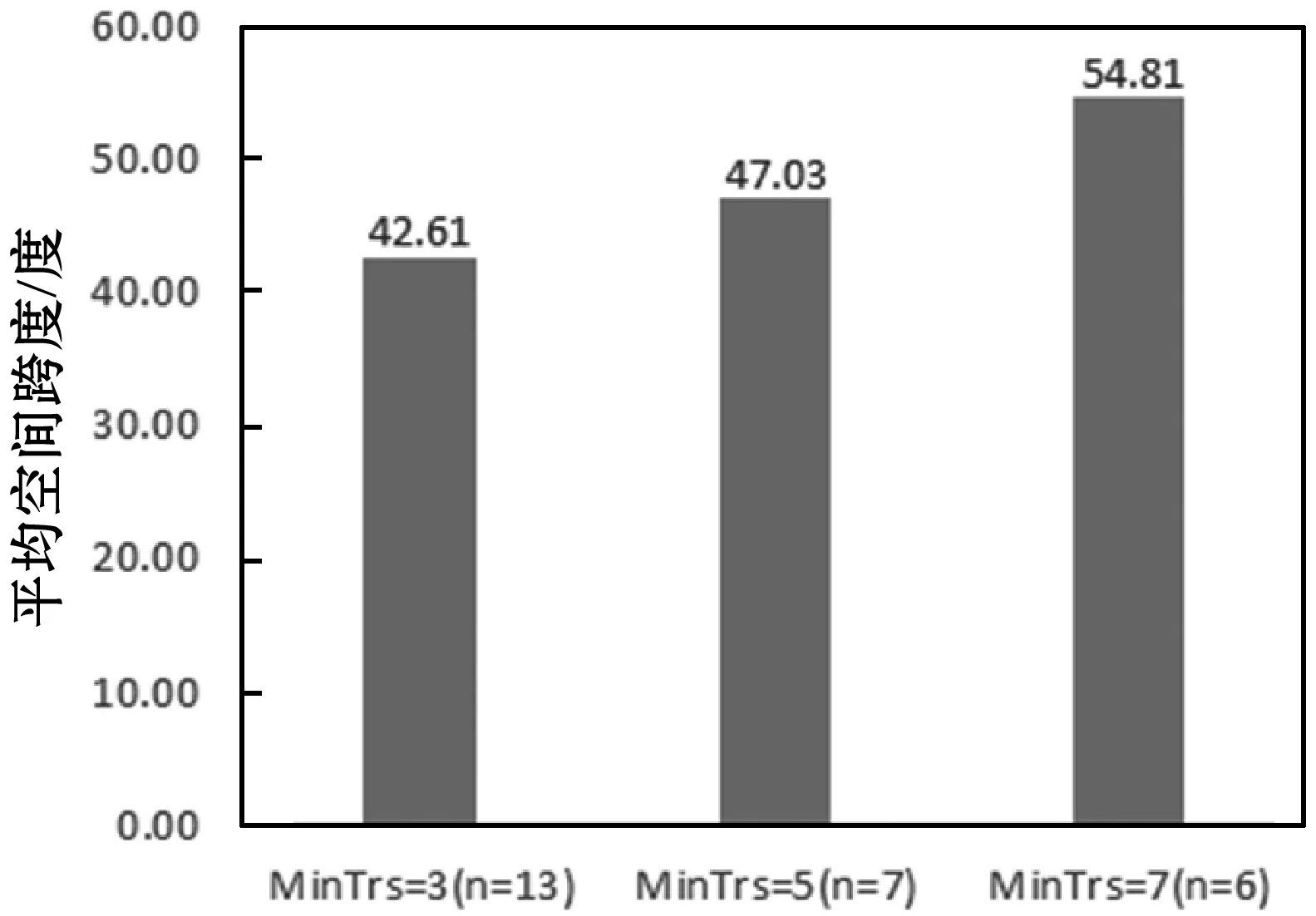
5 IF(Size(N) 6 将轨迹T标记为噪声 7 } ELSE { 8 新建一个簇c加入到簇集合C中 9 扩展以T为核心对象的簇c{ 10 将T加入到c中 11 FOR every T′ in N{ 12 标记T′为已访问 13 N′={T″|SOT(T′,T″)≥Eps} 14 IF(Size(N′)≥MinTrs){ 15 N=N+N′ 16 } 17 IF T′不是任何簇的成员{ 18 将T′加入到簇c中 19 } 20 }ENDFOR 21 } 22 } 23 }ENDFOR 在一个给定的α下,通过对聚类参数MinTrs或Eps的调整可以改变签到轨迹的层次粒度。逐渐减小参数Eps,形成的簇的层次范围将逐渐扩大(由街区到城市到国家等)。若Eps较小,则有更多轨迹被认为是相似的,使得聚簇的结果可能是一个洲上的所有签到轨迹,层次粒度很大。反之,高相似性要求使得很少有签到轨迹被认为相似,甚至难以成簇。参数MinTrs的变化往往影响同一个层次内的签到轨迹簇数,但随着MinTrs的增大,簇的扩展效果被放大,使得簇的层次粒度提升。当寻找城市层次的相似签到轨迹时,小的MinTrs会使得到的结果出现很多个簇,且一个簇中的签到轨迹很少,反之由于没有足够多的签到轨迹满足Eps,将会无法成簇。Eps和MinTrs都对分层效果有一定的影响,好的分层结果需要通过对两个参数进行多次调节。 实验运行于Inter(R) Core(TM) i7-7500U @ 2.7 GHz处理器、12 GB内存的Windows10计算机上。实验程序采用Java语言进行编写。由于基于时空-文本相似性的密度聚类的签到轨迹分层方法主要完成了签到轨迹中离群签到数据的去除以及签到轨迹的分层,所以实验中对离群签到数据和签到轨迹分层分别进行了评价。 在签到数据预处理流程中,要进行两次的离群点检测:一次是在生成签到轨迹后,对每一条签到轨迹进行基于四分位的离群点检测;另一次是在签到轨迹分层阶段,使用DBSCAN算法聚类时,在不同的参数下得到的噪声轨迹。下式计算了签到轨迹集中的离群率和分层处理过程的签到轨迹离群率。 (12) 其中,一个签到数据集生成的签到轨迹是固定的,对于每条签到轨迹检测出的基于四分位的离群点也是不变的,因此针对一个签到数据集,其基于四分位离群率是固定的。图6展示了1 000条签到轨迹的原始分布和经过基于四分位的离群签到数据检测过滤了离群签到数据的签到轨迹分布,不同深浅颜色点表示不同的签到轨迹,整体可见经过处理的签到轨迹集中少了很多孤立的点,该部分的离群率(即根据式(12)的前半部分计算所得)为13.76%,如图7网状阴影部分。分层阶段中DBSCAN算法的参数变化时,得到的噪声签到轨迹数量也相应变化,该部分的离群率如图7斜线阴影部分,一般情况下,满足参数条件的签到轨迹数并不多,因此由分层处理过程得到的离群率会较高。 (a) 未处理离群点的签到轨迹 (b) 去除离群点后的签到轨迹图6 1 000条签到轨迹分布图 (a) α=0.1 (b) α=0.5 (c) α=0.9图7 签到轨迹数据预处理的离群率 该部分对三个参数α,MinTrs和Eps进行调节,我们研究了不同参数在时空-文本的影响下对轨迹分层结果所带来的变化,以下式计算签到轨迹分层的平均跨度,从空间方面来评价分层效果。 (13) 图8展示了不同参数(签到轨迹的时空相似性权重α,最小簇轨迹数阈值MinTrs和聚簇半径Eps)对签到轨迹的平均空间跨度的影响,平均跨度越大,所划分的层次就越高(如国家),平均跨度越小,则所划分的层次越低(如城市)。如图8(a)所示,时空和文本的权重各占一半,聚簇的最小成簇轨迹数为3条,随着聚簇半径Eps逐渐减小,同一个簇内的签到轨迹在时空-文本上越来越不相似,使得该条件下的平均空间跨度增大。但实际上当Eps分别为0.6和0.4时,所得到的簇中包含了一条本身空间跨度就十分大的签到轨迹,使得在这两个参数下的簇个数n只有一个,其平均空间跨度被高度影响。如图8(b)所示,在时空和文本的权重各占一半,聚簇半径Eps为0.5时,随着最小簇轨迹数的增多,聚簇的最小范围变大,簇的个数减少,使得平均空间跨度有增大的趋势。如图8(c)所示,当时空相似性占签到轨迹相似性比重提高时,得到的签到轨迹间的相似性不同,因此计算得出的平均空间跨度没有相关性。 (a) α=0.5,MinTrs=3 (b) α=0.5,Eps=0.5 (c) MinTrs=3,Eps=0.5图8 不同参数对签到轨迹的平均空间跨度的影响 随着定位技术的精准与社交软件的普及,人们更加频繁地在网络上留下自己行走过或者停留过的地点痕迹,并赋予文本描述。然而,海量数据的质量问题是所有研究工作的重要前提。本文针对Foursquare签到数据集提出了一套数据预处理流程和方法,对签到轨迹进行基于四分位的离群签到数据检测,通过学习时间间隔阈值对签到轨迹划分解决了签到轨迹时间跨度大的问题,通过基于签到轨迹时空文本相似性的密度聚类方法对签到轨迹进行了分层,解决了空间跨度大的问题。通过对聚类参数的调整可以将签到轨迹集分层到洲、国家甚至城市,为将来更富有意义的签到数据挖掘工作提供了便利。5 实验结果与分析
5.1 离群点检测




5.2 轨迹分层


6 结 语
