基于多粒度建模的海量AIS数据三维可视化索引方法研究
2019-03-25武玉国
杜 莹,武玉国
(郑州师范学院,河南 郑州 450044)
为了适应当前航运事业蓬勃发展的新形势,提高航运的安全性,改变以往的船舶通信方式,国际海事组织(IMO)、国际电工委员会(IEC)以及国际电信联盟(ITU)等相关组织共同研究并推出了以信息和电子技术为核心的技术:船舶自动识别系统(Automatic Identification System,AIS)。该技术通过周期性地在固定的甚高频频率上广播静动态信息,实现船舶之间以及船舶和岸站间的信息交互,在船岸之间建立起一个固定的通信网络,以实现自动识别船舶、提升船舶避碰能力[1-2]。
AIS数据由船舶行驶过程中周期性广播自身位置产生,其广播的每一帧AIS报文通常由及静态信息(船名、呼号、船的大小、目的港等)和动态信息(如船的经纬度坐标、航速、航向等)构成。虽然单条AIS信息的数据量不大,通常在数十字节范围内,但其更新频率非常高(如表1所示,为AIS船位报告的频率)。正常情况下,船舶每隔2~360 s就会广播1次AIS信息,大量船舶不停广播,导致海量AIS数据产生[5]。仅我国海事部门搜集近海船舶动态数据,单日数据量峰值就高达千万条,3个月信息总量超过亿条,其它船舶相关信息总量也在万条以上[4]。这些海量AIS数据同时具有时空特性与大数据特征,即数据体量巨大、数据类型繁多、价值密度低、处理速度快。这就迫切需要一种有效的可视化方法来动态直观表达大量船舶随时间变换而发生的位置和状态改变,以从中挖掘出船舶交通流中的潜信息。

表1 AIS船位报告的频率
目前关于海量AIS数据可视化方法的研究,不少学者进行深入而有效地探讨。文献[1]和文献[6]研究AIS与电子海图ECDIS之间的串口通信,并在此基础上实现AIS信息与ECDIS电子海图的集成。文献[3]对时空立方体模型进行改进,在传统轨迹可视化模型的基础上增加时间坐标轴并利用颜色通道对船舶航速进行编码,使得分析者对异常数据识别,船舶停泊处识别及过弯行为模式更深刻的认识。文献[7]针对目前船舶排污监测系统面临的问题,对AIS系统提供的船舶信息的特点进行研究,根据船舶排污模型计算出各船舶实时排污情况,在电子海图上显示出港区船舶实时排污情况。文献[8]为解决海量AIS航迹数据在ECDIS平台上显示效率低、实时性差等问题,设计一种基于Douglas-Peucker算法的AIS航迹数据压缩算法。文献[4]以船舶为对象建立时空立方体模型,采用改进的时空索引结构,在现有三维可视化组件的基础上构建一个海上应急搜救信息查询平台,实现船舶属性信息的查询,以及船舶航行轨迹在球面三维环境中的显示。
本文针对AIS数据数量多、位置及状态更新频繁等特点,利用基于“视点选择法”的多粒度建模方法,构建面向移动对象的高效的空间索引,实现海量AIS数据的三维可视化。
1 面向AIS数据的多粒度建模
随着AIS技术的飞速发展,实时接收到全球范围内船舶的AIS数据已经完全成为可能,因此用户有可能在不同情况下关注不同层面的AIS数据可视化效果,而多粒度建模恰好能契合这一需求。
多粒度建模的关键问题在于两个方面:一是分析系统构成并选择基本建模单元,即分析模型的粒度;二是针对不同粒度的建模单元实现多粒度模型的集成,即选择多粒度建模方法[10-11]。
1.1 面向AIS数据的模型粒度分析
AIS是一种由岸基台、船载台、转发台、助航台、机载台组成的广播式自动报告系统,它按照相关协议,把船舶名称、呼号等静态信息,以及航向、航速、位置等动态信息广播至整个邻近的海域,使得附近的其它船舶和岸站能够获取周围海域所有船舶的信息,同时能够自动接收附近移动台站以及岸台所发送的数据报文。这就意味着每一条AIS数据都可能被不同层面接收方进行解析和可视化。因此,需要根据可视化的目标和条件来选择适宜的模型粒度。本文设计了粗、细两种粒度的模型,它们在AIS数据可视化的运用中主要有如下两种典型情况:
1)基于粗粒度模型的大范围AIS数据可视化:一般而言,对大范围甚至全球范围内的AIS数据进行可视化的主要目的,是通过在宏观层面上反映船舶密度和历史轨迹,为航运管理部门实施有效管控和合理避让提供科学的参考信息;
2)基于细粒度模型的局部AIS数据可视化及船舶信息查询:若以局部范围内或单个船舶的AIS数据为可视化和查询对象,往往需要准确展现船舶在指定时刻的位置和状态,这样才能有效实施诸如应急搜救、紧急避让等精细化操作。
那么,如何将这两种粒度的模型有机地结合起来,并有效解决多粒度模型之间的一致性问题呢?这就是本文接下来要重点解决的问题:多粒度建模方法。
1.2 面向AIS数据的多粒度建模方法
目前国内外关于多粒度建模的方法,具有代表性的有聚合解聚法(Aggregation-Disaggregation)、视点选择法(Selective Viewing,也称为优化选择法)和一体化层次化法(IHVR,Integrated Hierarchical Variable Resolution Modeling)等,三者的区别如表2所示[9]。

表2 三种多粒度建模方法的比较
由于各类AIS数据的典型特点是单条信息并不复杂,但更新频率高,因此适合于复杂仿真系统的“聚合解聚法”并不适合本文所研究的AIS数据;此外,各类AIS数据的更新频率并不相同,从2~360 s不等,因此在可视化过程中对模型一致性的要求也比较高。综合以上分析结果,本文选择视点选择法来完成AIS数据的多粒度建模。但从表2可看出,虽然视点选择法具有一致性好等优势,但其最大的问题在于资源消耗高,因此本文的另一个重点就放在如何构建高效的空间索引方法,以提高海量AIS数据的显示效率。此外,为更好解决多粒度模型之间的一致性问题,本文又在粗、细粒度模型内部分别细分为两级,如图1所示。
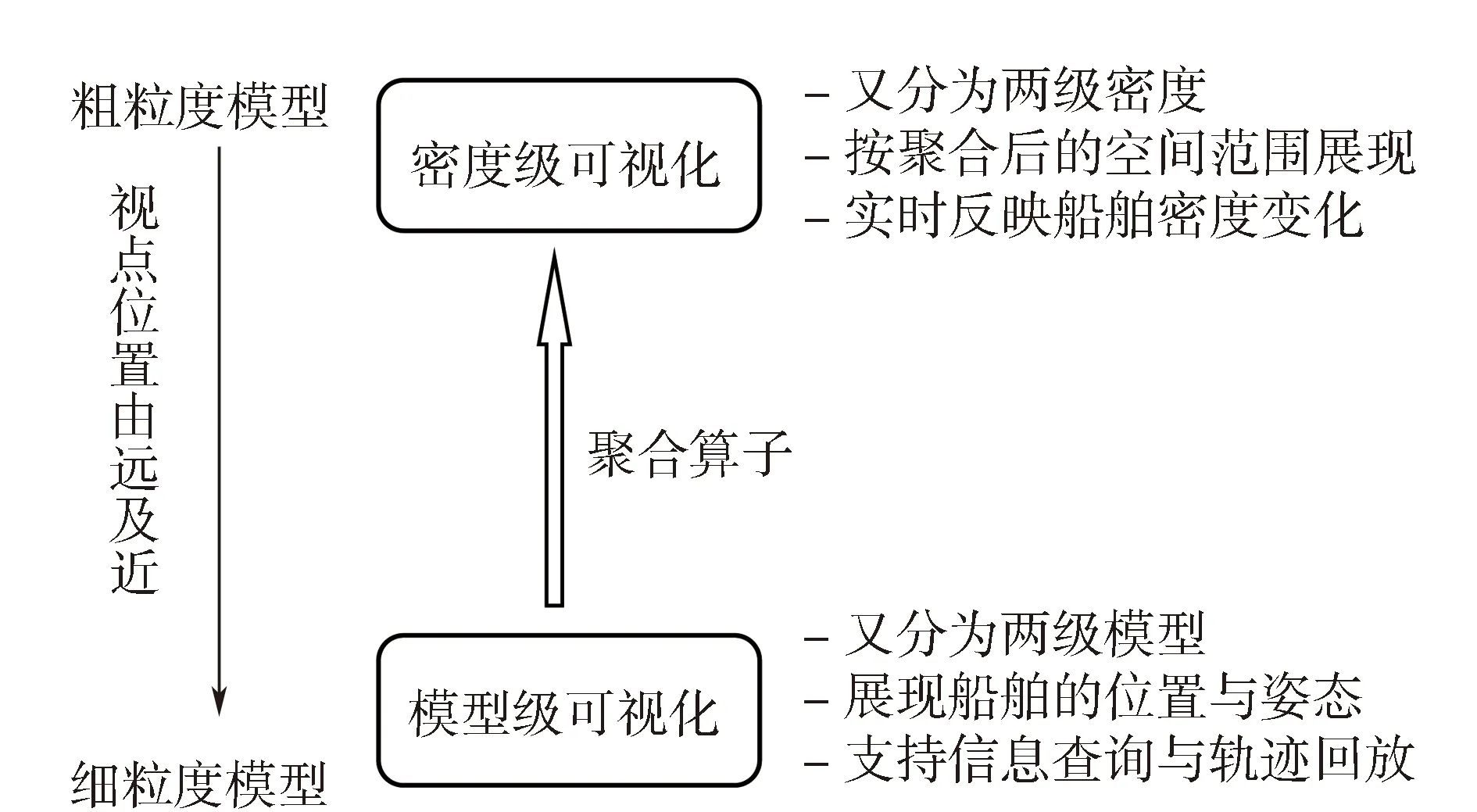
图1 基于视点选择法的AIS多粒度建模
2 面向AIS数据的空间索引
视点选择法只有聚合没有解聚,算法相对简单,且多个粒度之间的一致性较好,最关键的是要解决资源消耗大的问题。本文采用空间索引网格法为AIS数据构建各个粒度的模型。
2.1 面向粗粒度模型的空间索引
在粗粒度层面上,用户重点关注的是某个较大范围内(包括全球范围内)船舶的空间密度差异,因此本文以全球范围为根节点构建空间索引,将全球划分为若干等经差、等纬差的网格,作为子节点挂接在该根节点下。两级密度的网格分别使用不同的经差和纬差。网格索引编码的约束规则:从(-180°,-90°)处开始编号为0,行序优先。
若以dL和dB分别表示某级密度的网格的经差和纬差,以(L,B)表示船舶在某一时刻的地理坐标,则该船舶所在的网格索引的编码方式为
row=|(B+90)/dB|,
col=|(L+180)/dL|,
code=row×|360/dL|+col.
其中,row和col分别表示网格在全球根节点中的行号和列号,code表示网格在全球根节点中的唯一编码。这是一种基于整数的编码方案,之所以不采用类似“row-col”这样比较直观的基于字符串的编码方案,主要是基于对二者编码与解码效率的考虑。如表3和表4所示,为整数与字符串编码与解码速度进行比较的实验结果。实验环境为华硕ROG S5VT6700笔记本,Intel Core i7-6700HQ 2.6 GHz四核CPU,16G内存,Nvidia GeForce GTX 970M 显卡,Windows7 64位操作系统。

表3 用32位整数和字符串对网格编码的速度对比实验结果

表4 用32位整数和字符串对网格解码的速度对比实验结果
从表3—表4中实验结果可看出,整数编码方案无论在编码速度还是解码速度上,都比字符串具有明显的优势。而AIS数据的典型特点就是每艘船舶的信息更新频繁且船舶数目众多,需要有高效率的编码方案,这就是本文采用整数方式对网格进行编码的主要原因。
此外,从上述编码式可看出,网格的经差dL和纬差dB是两个非常重要的参数,直接决定着网格的总数,那么该如何设置这两个参数呢?基本原则如下:首先,网格总数不能太多,否则会影响网格在哈希表中的查找效率;其次,网格总数也不能太少,否则无法体现出船舶在空间密度上的差异,影响可视化效果。综合考虑上述因素,本文经过反复实验,将一级网格的经差和纬差均设置为1°,将二级网格的经差和纬差均设置为0.5°,这样就可以在可视化的效率和效果之间找到一个较好的平衡。如图2所示,为本文构建的两级密度的网格,网格中的数字表示该网格中目前的船舶数量。实验环境与上文相同,实验数据为某时间段内的AIS压缩信息,数据量大小170 M字节,船舶总数为67 833艘,记录总数为3 413 867条,平均帧速为40帧/s,更新与绘制时间的平均占比为1∶3。

图2 面向AIS数据的粗粒度模型可视化效果
2.2 面向细粒度模型的空间索引
在细粒度层面上,用户重点关注的是单艘船舶的信息,包括静态信息、动态信息、历史轨迹等。为保持模型之间的一致性,本文对细粒度模型构建空间索引时,沿用了粗粒度模型的空间索引方案,即用一定经差和纬差的空间网格来对其范围内的船舶进行管理,方案的设计遵循如下规则:
1)以全球范围为根节点构建空间索引,将全球划分为经差和纬差均为15′的网格,作为子节点挂接在该根节点下,网格中记录位于所有位于其中的船舶在整个集合中的序号;
2)船舶在可视化时,又细分为两级模型:视点较远时采用一级模型,用不带方向的点状符号表示,只展现船舶的位置,不支持交互查询;视点较近时采用二级模型,用带方向的四边形符号表示,同时展现船舶的位置和姿态,且支持交互查询。
基于上述规则,本文设计了基于多线程的面向细粒度模型的空间索引算法,如图3所示。
2.2.1 子线程:更新线程
子线程主要面向用户开启,由用户根据船舶AIS数据的更新频率,向系统发送船舶的实时位置和姿态,并记录到待绘制队列中。
需要说明的是,此处为什么要为每艘船舶额外生成一个序号并作为其在网格中的索引号,而不直接使用船舶的MMSI编号?这是因为船舶需要频繁更新位置和姿态,如果用MMSI编号,就必须用数据结构中的关联型容器(如map)存储船舶信息,众所周知,当关联型容器中元素个数较多时,查询的速度相当慢。而如果改用序号方法记录船舶,则可使用数据结构中的序列型容器(如vector),查询时通过下标直接寻址,速度相当快。当然,这需要在内存中维护一个映射表,建立船舶MMSI号与其序号之间的映射关系。实验结果表明,这种“以空间换时间”的做法,是完全可行的。
2.2.2 主线程:绘制线程
主线程由系统内部控制,主要负责两项工作:一是计算视相关参数,二是从待绘制队列中取出并绘制船舶。
1)计算视点相关参数。出于绘制效率和内存容量的考虑,系统中不可能同时绘制或存储用户提交的所有船舶,因此需要根据视点参数,动态加载视场范围以内的船舶,同时卸载视场范围以外的船舶。在本文设计的空间索引算法中,船舶是以索引号形式存储在其父节点中的,即细粒度索引网格中,这就要求算法要以网格为单位完成船舶的动态加载与卸载。
需要注意的是,在卸载视场范围以外的船舶时,需要以视场范围为中心,对其进行适度外扩(如图4所示),以便保留一定数量的视场范围以外的网格,否则会因为视点的微小变动而引起网格的频繁加载与卸载,影响绘制效率与可视化效果。
2)从待绘制队列中取出并绘制船舶。本文采用树状场景图结构存储并绘制各个节点,只有当节点的状态发生改变时(如添加、删除、修改),才需要重新处理。因此,本文此处的待绘制队列仅指那些因状态发生该变而需要重新绘制的船舶。
待绘制队列的数据来源,为用户在子线程中提交的船舶信息,但这并不意味着这些船舶统统需要系统立即进行处理,因为某些船舶有可能距离视场范围很远,根本不需要进行可视化。这就需要利用空间索引算法对待绘制队列进行筛选,也就是图3中“计算视点相关参数”的主要工作内容。图4为本文实验环境和实验数据实现的细粒度模型,平均帧速为30帧/s,更新与绘制时间的平均占比为3∶1(此处的更新时间包括了视相关参数的计算时间)。
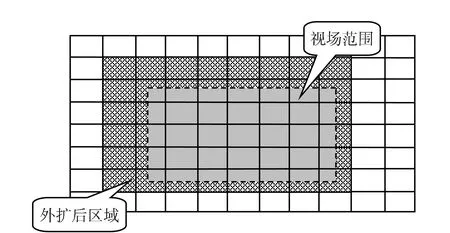
图4 卸载网格时需要对视场范围适度外扩
3 结 论
AIS数据的典型特点是数量众多、位置及状态更新频繁,如果没有一套合理高效的建模及可视化方案,很难满足多方面用户对于三维可视化高效、直观的要求。本文在详细分析AIS数据的模型粒度的基础上,设计并实现基于“视点选择法”的多粒度建模方法,通过构建面向移动对象的动态空间索引,实现海量AIS数据的三维可视化,并通过实验验证算法的可行性。
