基于主成分分析的林型数量分类研究
——以吉林省长白山科学院实验基地为例
2019-03-20陈颖异孙艺宁许嘉巍
陈颖异,孙艺宁,许嘉巍,王 丹
(东北师范大学地理科学学院,吉林 长春130024)
数量分类学是由美国生物统计学家索卡尔和英国微生物学家斯尼思等在20世纪50年代末所创建;60年代后,逐渐被越来越多的生物学家所接受,并将其广泛应用于生物分类当中[1]。植被的数量分类是数量分类学在植物学中的重要应用,主要是以植物物种的组成以及各种数量指标为基础,利用相应的数学方法来对物种进行定量的分类研究[2]。森林是植被的主要类型之一,其基本的分类单位是林型。林型是按照群落的内部特性、外部特征及其动态规律所划分的同质森林地段。划分森林类型的目的是为森林调查、造林、经营和规划设计提供科学依据,对不同的类型采取不同的营林措施[3]。
关于长白山地区的植被分类研究,起始于20世纪90年代,钱宏[4]采用等级分化分类法和DCA排序法,对长白山高海拔地区的冻原植物进行了分类比较研究;翟永华和刘海棠[5]运用PC-VTAB程序中植被排表分析法,得出植物鉴别概要表,并为各个等级的植被类群筛选出诊断种,提高了分类质量;徐文铎等[6]根据对长白山植被调查和长期定位观测资料,总结了长白山植被类型特征和演替规律;王颖[7]利用2000—2007年的遥感数据,建立NDVI-LST的特征空间模型,对长白山地区进行了植被分类和植被变化特征分析研究。
目前,关于林型分类的研究较为缺乏,将数量分析方法运用到林型分类中,既避免了传统人为分类的主观臆断性,同时弥补了遥感技术分类粗略的缺点。本文通过选取、测量具有一定生态学意义的林型指标,并对其数据进行主成分分析,计算得出长白山科学院实验基地4种林型综合分类指标的数值范围,使得分类工作者在野外进行一定的试验和数据处理后,通过对照分析林型综合分类指标的数值范围,进而快速有效地对林型进行分类。以此实现对长白山区森林群落系统的准确识别,从而更好地保护长白山珍贵物种的种质资源,使得林区更加持续稳定发展。
1 研究方法
1.1 研究区概况
长白山科学院实验基地,位于吉林省长白山自然保护区内(图1),地理位置为北纬42°21′28.618″~42°25′7.854″,东经 127°59′17.291″~128°4′37.969″,海拔 650~900 m,总面积 2 088 hm2。地处山地针阔混交林气候带,气候特点是冬季寒冷干燥,夏季温暖湿润。年均气温在2.51℃左右,其中最冷的月份(1月)平均气温为-17.5℃,最热月份(7月)平均温度为19℃,年均降水量为680 mm,年均风速较小。实验基地坡面较缓、地形差异不大,土壤以白浆土为主。基地内分布有3条主要河流,所有河流最后在二道江汇集,是松花江的水源之一。
图1 长白山科学院实验基地位置
实验基地内植被主要是以杂木林和红松阔叶林为主,树种资源丰富,红松(Pinus korainensis)、长白落叶松 (Larix Olgensis) 及紫椴(Tilia amurensis)为主要成林树种,并与其他针阔叶树种,如白桦(Betula playtyphylla)、杨树(Populus tomentosa)等形成针阔混交林。研究区内原始林较稳定,生境条件好,基地中的绝大部分都是天然林,只有很少一部分是人工林。天然林主要林型为杂木林、白桦林、长白落叶松林、红松阔叶林以及混交林;而人工林则只有果树林。较大面积的次生林主要分布在林区公路沿线,主要树种包括白桦次生林及蒙古栎次生林。
本研究根据长白山科学院实验基地的林斑调查数据,选取基地内未受过人为砍伐、耕种等干扰,仍保持原始状态的4种天然林型:杂木林、白桦林、红松阔叶林和长白落叶松林进行样方调查。在每种林型内随机设置20个20 m×30 m的样地,共80块样地,编号1~60为建立林型数量分类方法研究的样地,编号61~80为验证林型数量分类方法可行性的样地。
1.2 分类指标的选取与测量
所选取的分类指标需要具有快速测量得到试验结果的易获得性,以及能充分体现植被群落和环境特点的综合性。结合以上2点选取原则,从植物群落的数量特征、气候数据、土壤数据3个方面共选取了9个分类指标,分别为:叶面积指数LAI、有效光合辐射、土壤呼吸通量、土壤pH值、速效氮、速效磷以及土壤温度、湿度、盐度。
测定时间选在天气状况较好的生长季,使用LAI-2000冠层仪测量实验当天的太阳辐射值和不同植物的叶面积指数,使用LI-8100土壤碳通量测量系统测量土壤呼吸通量。在不同样地上按照土壤发生层,采用对角线法进行取样。在对角线的位置,利用土壤三参数分析仪对土壤温度、湿度以及盐度、空气湿度进行测量,并在同一位置使用土壤酸度计测量土壤的pH值。将采集的土壤样本进行混合,使用土壤速测箱,对土壤的速效氮、速效磷进行测量。
1.3 主成分分析原理
主成分分析 (principal component analysis,PCA)是一种重要的多元统计分析方法,也被称为主分量分析或矩阵数据分析[8]。它主要是通过对变量进行正交变换处理,把原来的多个指标变量转换为若干个综合指标变量,从而对多维变量系统进行降维处理,使得问题得以简化。主成分分析提取出的较少的综合指标之间互不相关,却能提供原有指标的绝大部分信息;因此,在保证研究精确度的前提下提高了研究效率[9]。
1.4 数据处理与分析
选取Z分数的方法对原始数据进行标准化处理,以消除不同量纲之间所造成的差异性。在此基础上,对样地编号1~60的试验数据进行主成分分析,获取分类指标之间的相关关系,提取主成分因子,并计算得出不同林型综合分类指标的数值范围;最后将样地编号61~80的试验数据,代入到林型综合分类指标的计算公式,进行林型数量分类方法可行性的验证。上述数据处理与统计分析均使用SPSS22.0统计软件完成。
2 结果与分析
2.1 分类指标间相关性分析
运用SPSS22.0软件对数据进行运算处理,得到相关系数矩阵,即原始分类指标之间的相关性(表1)。由表1可以看出,多数分类指标间的相关系数达到显著水平,如叶面积指数与土壤温度呈现极显著的负相关关系(r=-0.801)、与土壤盐度呈现极显著的正相关关系(r=0.894);土壤呼吸通量与土壤pH值呈现极显著的负相关关系(r=-0.882);土壤湿度与速效氮和速效磷呈现极显著的正相关关系(r=0.938、r=0.959)等。所得出的相关系数矩阵中绝对值大于0.3的系数(P<0.01)占66.67%,表明各变量间大多为强相关,故认为适合进行主成分分析。
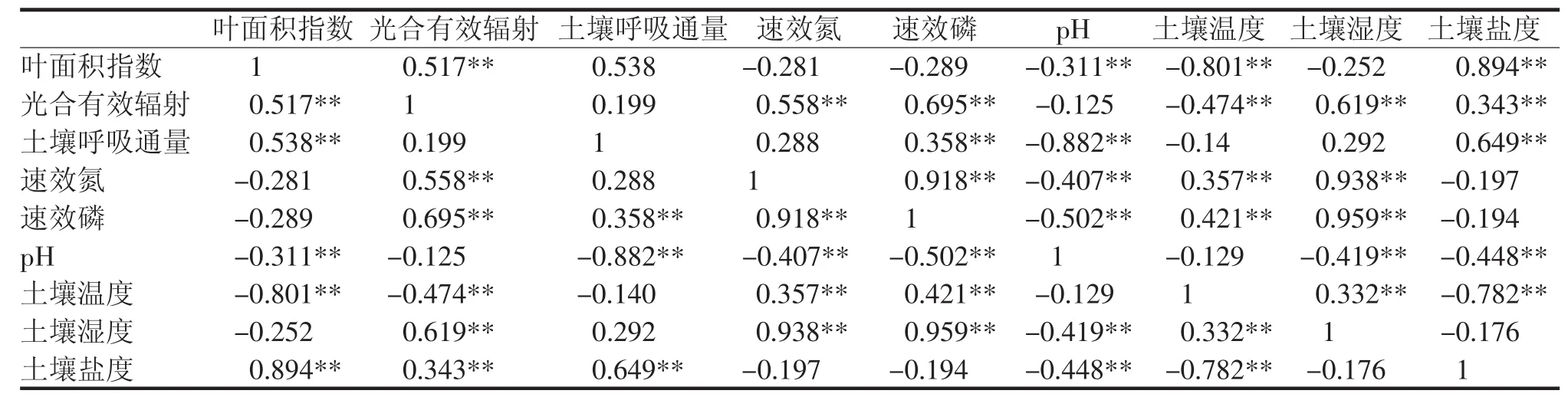
表1 分类指标的相关系数矩阵
2.2 主成分特征分析
利用软件对数据进行主成分分析,提取出3个主成分因子,各主成分因子的特征值与贡献率见表2。一般选取特征值大于1且累计方差贡献率大于85%的作为主成分因子,前3个主成分的初始方差贡献率分别为42.568%,37.667%和15.648%,累积方差贡献率达95.883%,说明这3个主成分已经涵盖了原指标绝大部分的信息,剩余其他因子的信息载荷可以忽略不计。因此,降低了原始数据的复杂性,达到了降维的目的。

表2 各主成分的特征值和方差贡献率
由软件的输出结果得到各主成分因子的载荷值(表3),即表征指标变量与各主成分间的相关系数,其绝对值的大小决定归入的主成分因子,指标变量的绝对值越大即对该主成分的影响越大。由表3中可以看出,主成分一(F1)所包含的因子最多,其中光合有效辐射、速效氮、速效磷、土壤湿度为F1的主要影响因子;主成分二(F2)中以叶面积指数、土壤温度、土壤盐度为主要影响因子;主成分三(F3)中则以土壤呼吸通量与pH值为主要的影响因子。

表3 各主成分因子载荷值
2.3 综合分类指标范围的确立
将各主成分因子的载荷值(表3)除以相应主成分特征值的平方根,即得出不同主成分的特征向量,作为计算各样本点主成分值的权重,再结合标准化数据,由公式(1)计算出每个样本点的3个主成分值;其在由3个主成分向量组成的三维空间里显示,结果如图2所示,可以看出每种林型的样本点都发生了明显的汇聚现象,不同林型的类型区域划分显著,达到了有效分类的目的。

式中,Fij为第 i个样本点的第 j个主成分值;pij为 第i个样本点第j个评价因子的标准值;nj为第j个主成分的特征向量。
根据由软件得出的各主成分的方差贡献率(表2),将其作为计算不同林型综合主成分值的权重,再由公式(2)计算出不同林型样本点的综合主成分值,即可得出4种林型综合分类指标的数值范围,计算结果见表4和图3。

图2 林型分类主成分分析散点图

式中,Fi为第i个样本点的综合主成分值;Fij为第i个样本点第j个主成分值;wj为第j个主成分的方差贡献率。

表4 不同林型综合分类指标的数值范围

图3 不同林型综合分类指标数值范围的数轴图
2.4 不同林型的分类验证
为验证林型数量分类方法的可行性,从杂木林、白桦林、红松阔叶林和长白落叶松林4种林型中各选取5个样地,共计20个样地进行林型分类验证试验。对每个样地进行指标测量和数据标准化处理,然后将数据代入到综合主成分值的公式中,计算出不同林型样本点的综合主成分值,再与对应林型综合分类指标的数值范围进行对比验证。20个验证样地中,有18个样地利用林型综合分类指标而成功确定林型,准确度达90%。将验证样地的各主成分得分值绘制在包含已划分林型区域的三维空间里,按照林型类别用对应颜色的菱形标示,结果如图4所示,可以清楚地看到大部分数据点落在对应的林型区域内,由此说明使用这种方法可以很好地对林型进行分类判别。
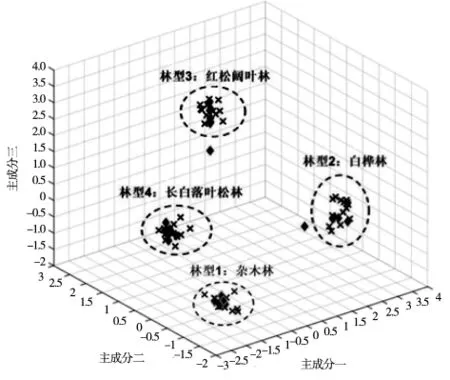
图4 林型分类主成分分析验证散点图
3 结论与讨论
(1)通过对长白山科学院实验基地4种林型的9种分类指标数据的分析表明,运用主成分分析法能够很好地消除林型分类时不同指标之间所反映的重复信息,对多维指标变量系统进行降维处理,计算得出能够反映长白山科学院实验基地林型综合分类指标的数值范围;同时林型综合分类指标数值范围的确定,是以不同主成分因子的特征向量和贡献率来作为指标权重,这种基于数量分析的分类方法,有效地避免了人为分类的主观臆断性,在一定程度上改善和提高了林型分类的质量;因此,在保证研究精确度的前提下,建立了一种较为快速准确的林型数量分类方法,降低了工作难度,提高了研究效率。
(2)研究结果表明,所选取的9种林型分类指标,多数指标之间的相关性显著,相关系数矩阵中绝对值大于0.3的系数占70%以上;通过主成分分析的降维处理,提取出3个主成分因子,进而得出长白山科学院实验基地林型综合分类指标的数值范围为:杂木林 [-1.456,-1.128]、白桦林[0.303,0.796]、红松阔叶林[1.286,1.745]、长白落叶松林[-0.256,0.156];对该林型分类方法进行可行性验证,准确度达90%;因此,基于主成分分析法的林型数量分类方法能够实现对林型的有效分类。
(3)本研究基于主成分分析建立的林型数量分类方法,在长白山科学院实验基地得到了较好的验证,具有一定的普适性,可以推广到其他温带地区进行林型分类实验的探索。今后对于林型数量分类的研究,可以从植被、土壤、气候等因素中筛选出更具代表性的林型特征指标,简化指标体系,提高分类效率,以及对多种数量分析方法进行探索研究。
