基于相似性的外卖—人群深层神经网络分类模型
2019-03-19辽宁省沈阳市二中邢城祎
辽宁省沈阳市二中 邢城祎
在订外卖的人群中,不同的人群所订外卖的数量有着很大差别。本文把外卖垃圾数量—人群特点的关系和某地区月平均降水量—该地气候类型的分类方式相类比,通过实地采集,得到外卖垃圾数量的第一手资料,并且查询所需位置的降水量数据,经过数据清洗后,得到较为充分准确的数据。同时,在分类方法上进行深入研究,采用深层神经网络模型训练对应的降水量—气候类型数据。通过不断的模型设计与超参数调节,使模型在降水量—气候类型和外卖数量—人群种类两个数据集上均达到较高的分类正确率。保存训练后的模型作为之后的预测,达到使用时无需训练,仅需输入该地外卖垃圾数量,就能够以较高的正确率推测该地人群特点的目的。此模型在实际应用上可以通过外卖数量推测人群特点,从而研究更有效、更有针对性的垃圾处理方案。
一、问题背景
2016年,全国生活垃圾年清运量已经高达20362万吨,而其中外卖垃圾所占的比例正逐年上升。根据外卖类平台“饿了吗”发布的数据,外卖服务业每天至少会产生2000万份废弃的一次性包装盒、塑料袋和一次性餐具。垃圾已严重影响环境和人民的生活。
二、分类标准
通过调查得出以下带有一定普适性的分类标准:
1.外卖固体废弃物

类别举例塑料 塑料餐具,塑料盒,塑料袋等纸纸袋,纸巾等纸皮 纸盒,宣传单,纸杯等木头 木制筷子等食品残余物 各种食物残渣
2.人群种类与所处区域

所处区域 人群种类医院 病人,医护人员等研究所 科研人员等写字间 小型创业者等住宅区 普通居民等中学补课班 学生,老师等
三、外卖固体废弃物数据采集
1.采集方式
为了获取准确的第一手资料,收集数据采用实地采集的方法。因为在垃圾收集处,外卖垃圾与其他各种垃圾混合在一起,很难准确测量出仅属于外卖的垃圾质量。所以,我们采用单位骑手的外卖垃圾质量乘以外卖骑手数量作为外卖质量的估计值。对于单位骑手外卖垃圾质量,我们将通过模拟预定外卖来测量每位骑手所带来的外卖垃圾质量。
2.各人群种类所在地区外卖固体废弃物采集方法
通过网络及实地调查,选取有代表性的人群种类所在地区,确定所在地区能使外卖骑手进入的大门数量,记录7:30~19:30每一个小时内各门外卖骑手的进入数量,准确测得数据后进行统一的数据汇总。
四、假设
1.假设外卖固体废弃物仅分为如上类别,忽略其余垃圾种类。
2.假设人群种类仅分为如上类别,忽略其他人群种类。
3.假设所采集数据的地方具有强代表性,可以代表其他类似场所。
4.假设所调查的地方每日所产生的外卖固体废弃物质量相同。
5.假设模拟预定的外卖固体废弃物质量经过平均计算,可以代表每位骑手所带来的外 卖固体废弃物质量。
五、估算每位骑手所带来的外卖固体废弃物质量
为估计每位骑手所带来的外卖垃圾质量,我们订了不同种类的外卖,分别称量种类不同的固体废弃物的质量,经多次称量,得出如下数据(单位:g):
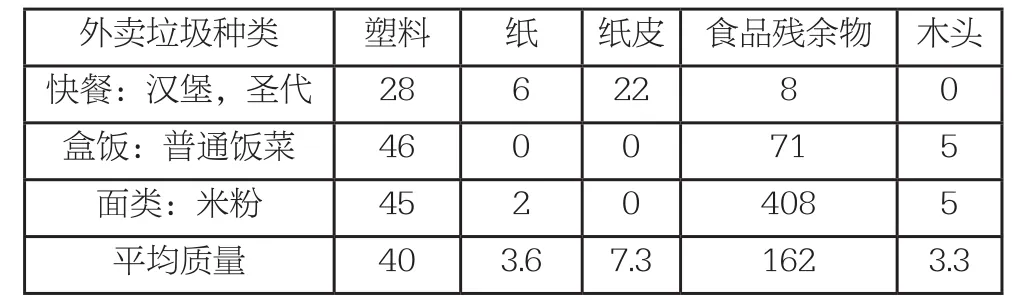
外卖垃圾种类 塑料 纸 纸皮 食品残余物 木头快餐:汉堡,圣代 28 6 22 8 0盒饭:普通饭菜 46 0 0 71 5面类:米粉 45 2 0 408 5平均质量 40 3.6 7.3 162 3.3
六、基于相似性的外卖—人群深层神经网络分类模型建立
1.数据采集
通过既定的方法,选取中国人民解放军沈阳军区总医院、中国科学院金属研究所、沈阳市华润大厦、丰泽花园与某补课班实地采集数据如下(单位:辆):
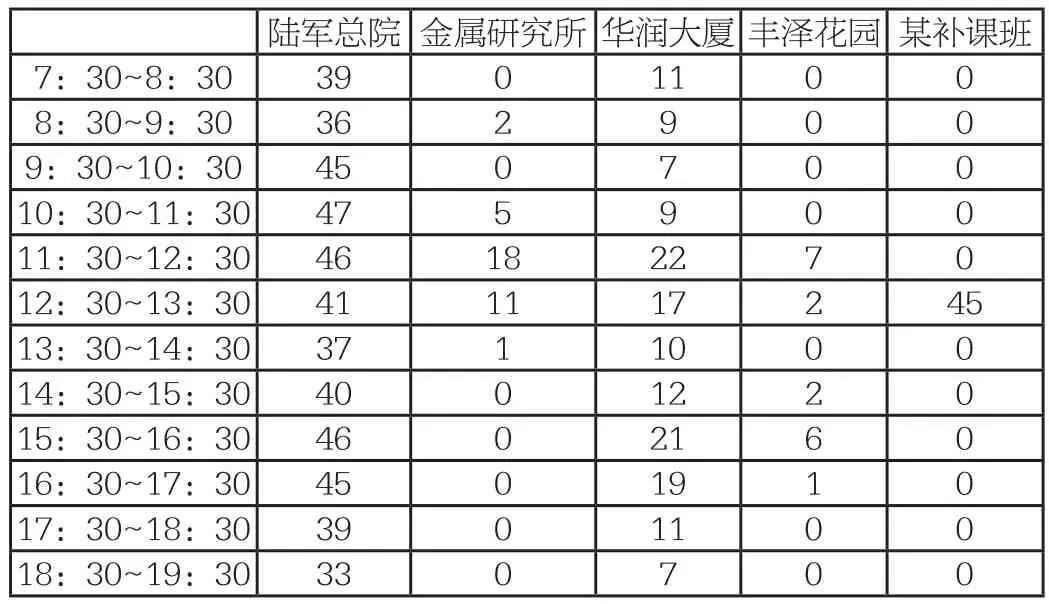
陆军总院 金属研究所 华润大厦丰泽花园 某补课班7:30~8:30 39 0 11 0 0 8:30~9:30 36 2 9 0 0 9:30~10:30 45 0 7 0 0 10:30~11:30 47 5 9 0 0 11:30~12:30 46 18 22 7 0 12:30~13:30 41 11 17 2 45 13:30~14:30 37 1 10 0 0 14:30~15:30 40 0 12 2 0 15:30~16:30 46 0 21 6 0 16:30~17:30 45 0 19 1 0 17:30~18:30 39 0 11 0 0 18:30~19:30 33 0 7 0 0
2.模型建立思路
实地采集各地外卖骑手数量,发现各区域的每小时外卖骑手数量分布特点与一些气候类型所对应的每月平均降水量分布特点极为相似,故以相似为基础,将各个人群特点所处区域一一映射至如下的气候类型:
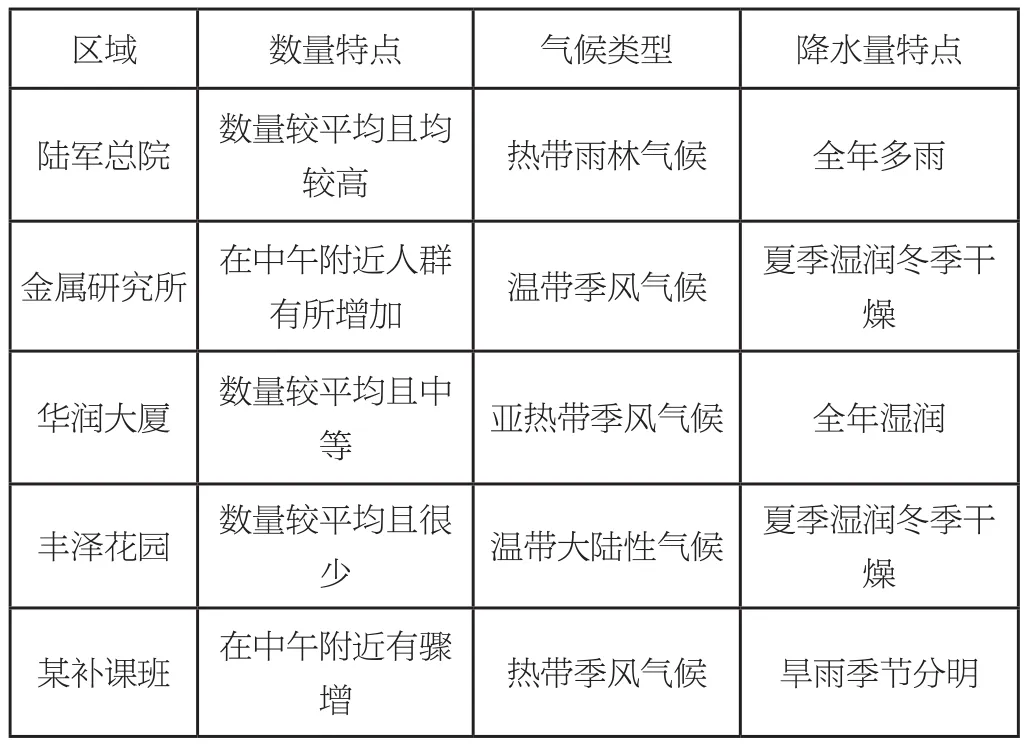
区域 数量特点 气候类型 降水量特点陆军总院 数量较平均且均较高 热带雨林气候 全年多雨金属研究所 在中午附近人群有所增加 温带季风气候 夏季湿润冬季干燥华润大厦 数量较平均且中等亚热带季风气候 全年湿润丰泽花园 数量较平均且很少温带大陆性气候 夏季湿润冬季干燥某补课班 在中午附近有骤增热带季风气候 旱雨季节分明
选取典型气候类型地区:新加坡、哈尔滨、南京、乌鲁木齐、新德里。收集历史平均月降水量数据如下(单位:mm):
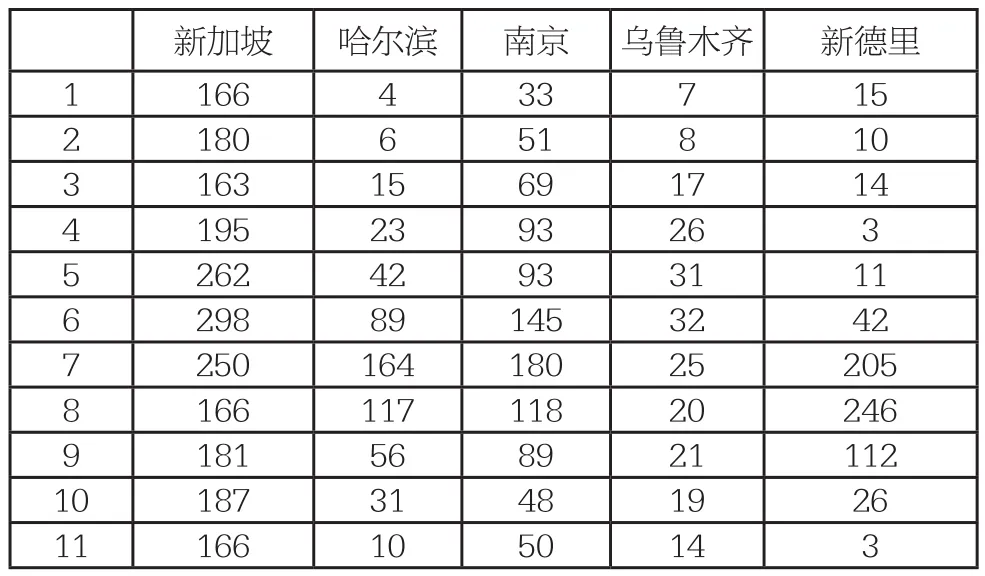
新加坡 哈尔滨 南京 乌鲁木齐 新德里1 166 4 33 7 15 2 180 6 51 8 10 3 163 15 69 17 14 4 195 23 93 26 3 5 262 42 93 31 11 6 298 89 145 32 42 7 250 164 180 25 205 8 166 117 118 20 246 9 181 56 89 21 112 10 187 31 48 19 26 11 166 10 50 14 3
由此可见,区域外卖骑手数量分布与与其相对应的地区降水量分布十分相似,故以此为基础建立模型。
3.模型目的
通过训练,模型能够接受一组从7:30~19:30每隔一小时的外卖骑手数量,输出五种人群特点的可信度。
4.数据收集及前期处理
(1)数据收集
从GHCN数据库、环境云和Global Weather Data for SWAT上收集上述地区历年的降水量数据作为训练数据,选取一小部分数据作为降水量—气候类型验证数据,将区域外卖骑手数量作为外卖骑手数量—人群特点验证数据。
(2)数据前期处理
由于降水量数据与外卖骑手数量量级并不相同。对于人眼,在观测折线统计图时,主要观测的是数据之间的相对大小关系以及数据(y)随时间或者月份(x)的变化趋势。因此,为统一数据量级,防止深层神经网络模型出现学习方向的错误,将每个数据除以12个单位时间或者月份(x),五种气候类型或者人群特点的总共60个数据的和,使降水量数据与骑手数据量级相似使大部分数据在0~1之间。
5.模型建立
此模型总共有六层,分别是:批规范层(Batch Normalization),全连接层,丢弃层(Dropout),全连接层,全连接层,批规范层。
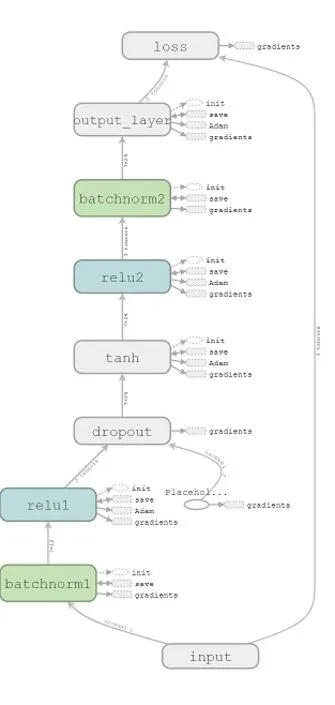
6.模型训练
(1)训练参数
经过多次实验比对,此模型采用全部数据以每10个为一批(Batch)输入至网络,训练时将全部数据完整地训练100次(epoch=100)的方法。将模型误差、降水量验证结果与外卖骑手数量验证结果输出。
(2)训练结果
训练后,保存训练日志。使用可视化工具TensorBoard查看模型误差,并且使用TensorBoard画出降水量验证结果与外卖骑手数量验证结果折线图。
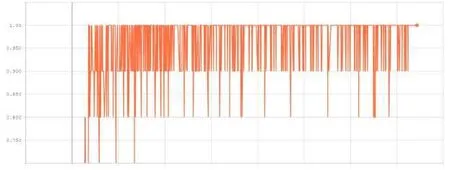
降水量分类正确率如下(Smoothing=0):
外卖骑手数量分类正确率如下(Smoothing=0.9):
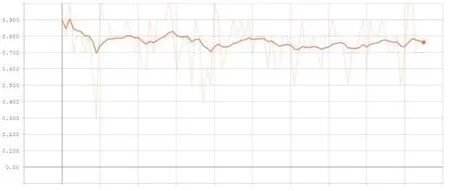
从图像中得出,经过100轮(epoch)的训练,降水量模型的训练误差在0和0.2之间,降水量的分类正确率几乎达到了100%,外卖骑手数量的分类正确率在75%到80%之间。
(7)模型结论
基于所处地人群特点与气候类型,所处地12个小时外卖数量与特定气候类型月平均降水量的相似性,建立深层神经网络模型,通过不断调整超参数,得出较为完善的模型,并进行训练,使得此模型满足模型目的,即,输入12个小时的外卖骑手数量,可以得出一个正确率在75%到80%的人群特点。
