基于Spark平台的参数优化研究现状
2019-03-14尉耀稳余彬李豪帅沈鸿达
尉耀稳 余彬 李豪帅 沈鸿达

摘要:近年来,为迎合大数据时代的需求,诞生了一批大数据处理平台,包括Hadoop,Spark,Storm等,Spark以其独特的优势在此中最受欢迎。尽管Spark的应用得到了大力推广,其性能还存在严重问题,很多学者正致力于寻找提升性能的有效途径。针对这一问题,他们从优化相关配置参数的角度出发,分析并总结了参数优化对Spark平台性能的重要影响以及目前国内外的Spark参数优化技术。最后,归纳了Spark参数优化现存的主要问题,并提出了下一步的研究方向。
关键词:大数据; Spark; 性能; 配置参数; 参数优化
中图分类号:TP302 文献标识码:A 文章编号:1009-3044(2019)01-0011-03
The Research Status of Parameter Optimization Based on Spark Platform
WEI Yao-wen,YU Bin,Li Hao-shuai,SHEN Hong-da
(State Grid Zhejiang Hangzhou Xiaoshan District Power Supply Company, Hangzhou 311200, China)
Abstract: In recent years, in order to meet the needs of the era of big data, a number of big data processing platforms have been born, including Hadoop, Spark, Storm, etc.Spark is the most popular among them because of its unique advantages. Despite the widespread use of Spark, there are serious problems with its performance. In response to this problem, they analyze and summarize the current Spark parameter optimization techniques at home and abroad from the perspective of optimizing relevant configuration parameters. Finally, the main problems existing in Spark parameter optimization are summarized, and the next research direction is proposed.
Key words:big data; Spark; performance; configuration parameter; parameter optimization
1 引言
由于大數据时代的到来,大数据技术愈加受到各界学者的重视。然而大数据时代的传统计算模型无法满足性能和效率的需求,Hadoop [1],Spark [2],Storm [3]等分布式框架如雨后春笋般出现。 Hadoop作为开源的云计算平台,继承了MapReduce [4]的可靠性、扩展性、高效性和容错性,已经成功被应用到多个领域当中。例如Yahoo、Ebay、百度和FaceBook等大型互联网企业都已经在项目中应用Hadoop框架。Spark已经成为大规模并行数据分析中使用最广泛的框架之一,相比Hadoop MapReduce它在编程模型和性能方面更加灵活,特别是对于迭代应用程序。Spark还可以适应批处理和流媒体应用,同时提供与其他大型数据技术的接口。除此之外,它包含了类似SQL的处理,图形处理,机器学习和数据挖掘的组件。 Spark的关键特性是它能够隐藏最终用户和应用开发人员所面临的并行性,容错性和集群设置相关的复杂性,这使得Spark可以在应用在实际的数据科学和大数据处理应用中。
虽然Spark在很多方面存在一定的优势,但仍存在一些短板让其在性能上有所欠缺。其中最突出的是,Spark不能保证长时间运行不出错,且由于Spark是基于内存运算的,内存中会缓存大量数据,而垃圾回收速率跟不上数据产生的速度,从而导致不能稳定性能。是以,研究如何在保持Spark原有优点的情况下,进一步提升性能从而降低运营成本,具备理论与现实意义。
为了更加快捷地处理海量数据,Spark执行引擎已经发展成为具有多个可配置参数的高效的复杂系统。使用者可以依据具体的实际应用需求进行参数的调整。一方面,通过仔细的参数调整,大参数空间为性能提升提供了很多机会,但另一方面,大参数空间和参数之间的复杂交互使得适当的参数调整变得极其困难。有相关实验证明,选择合适的参数配置能极大提升应用程序的性能,而选择不当可能会降低性能,并使平均运行成本增加2~3倍,最差情况下增加12倍[5]。大多数参数是相互关联的,参数的影响可能因应用程序而异,也可能因集群而异。默认的参数配置已经不能满足开发者对性能的要求,已经有很多工作致力于为应用程序和集群寻找最优的参数配置。显然,检查所有可调参数的所有不同参数值组合是不可能的。因此,通过低成本自动搜索所有可能的参数配置来调整广泛的大数据分析平台应用是一项具有挑战性的任务。
2 相关背景
近几年,大数据领域飞速发展,由此产生了多个数据处理与分析平台,Spark就是其中一个。为适应大众需求,Spark的功能一直在完善中,目前主要功能已经包括离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等。Spark主要有以下几个突出特点:1)计算速度快,Spark在Hadoop MapReduce上进行了扩展,是基于内存计算,所以其速度可快至少100倍;2)易用性,Spark支持多种编程语言,包括常用的Java,Python,Scala等,其默认语言Scala语法简单使用方便;3)通用性,Spark包含SparkCore,GraphX等多个组件,可以同时处理不同类型的数据;4)兼容性,Spark是开源产品,允许二次开发并和其他产品一起使用。
Spark的运行效率涉及众多因素,如集群配置,任务类型,任务调度,参数配置等。当集群配置已经确定时,参数是影响性能的主要因素。合适的参数配置会让任务运行效率大幅度提升,不合适的参数配置则会导致应用程序难以达到计算的峰值速度。在其他环境因素相同的情况下,参数对性能有着不可忽视的作用,参数配置的好坏决定着作业运行效率和集群吞吐量的变化。虽然Spark有默认的参数配置,但受集群负载情况不停变化、作业类型繁多等原因影响,不同作业有不同需求,默认参数配置不能充分利用集群资源提高系统吞吐率。
当前主要有两种调整参数的方式。首先,这些参数通过反复试验手动调整,由于参数空间大且参数之间复杂的相互作用,这是低效且耗时的。其次,基于成本的性能建模适用Hadoop的参数调整,Spark在底层实现机制上与Hadoop有很大不同,因此不能将此方法移植到Spark上。所以,从新的角度研究Spark的参数优化是必须且迫切的。
3 Spark运行机制
要想通过参数调整来优化Spark性能,首先要了解参数优化对性能是如何影响的,所以我们需要理解Spark的工作原理,首先介绍Spark的整体架构,如图1所示。
图1中,Driver是用户提交的应用程序;SparkContext是Spark的主要入口,也是应用程序与集群交互的接口;Cluster Manger是集群管理器,负责资源的管理和分配,目前支持本地、单机、Yarn等多种模式;Worker Node是执行各种运算的工作节点;Executor是进程;Cache是缓存;Task是作业的多个拆分。
首先运行用户的程序,其主函数会初始化SparkContext,然后与Cluster Manger通讯。Cluster Manger按需将资源分配给任务,分配结束启动Executor进程。Worker Node与Executor是一一对应关系。Executor会启动管理Task运行的线程池,同时将数据保存至内存或磁盘。从任务开始执行到正确执行完毕,这段时间Executor会一直向Driver报告Task的运行状态。
当程序开始执行后,启动一个Driver,初始化SparkContext并创建DAGScheduler、TaskScheduler、SchedulerBackend,HeartbeatReceiver。当执行Action操作时会触发一个Job。DAGScheduler会按照RDD之间的宽窄依赖关系将该Job划分为多个Stage。然后Taskset会被传给TaskScheduler,进行任务调度。Driver会根据需求请求资源,ResourceManager根据请求分配资源,并在对应的Worker Node上创建Executor。之后TaskScheduler进行Task分配,Executor执行结束会通过ExecutorBackend传递回去,该任务执行结束TaskManager开始执行下一个任务。所有任务全部执行结束后TaskSet Manager负责将结果反馈给DAGScheduler。
4 Spark参数优化的研究进展
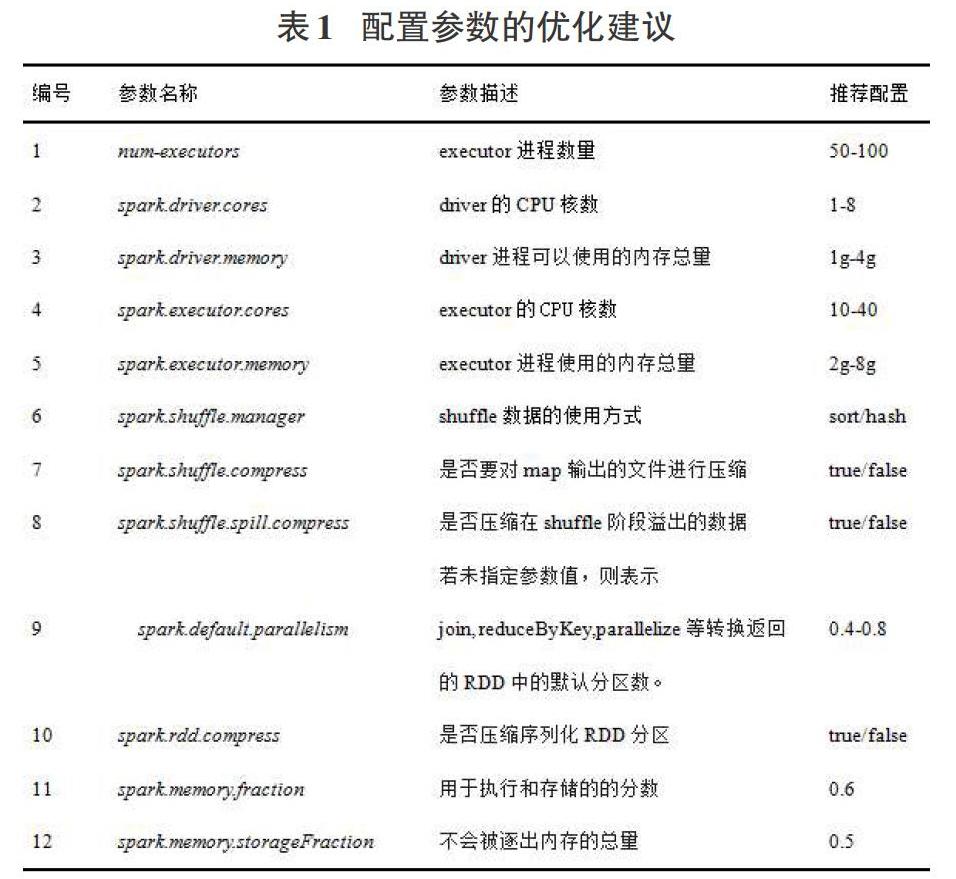
Spark已經发展成拥有180多个配置参数的大数据分析平台,其中可配置的参数多达150个,不同的应用程序对参数的配置有不同的要求,合理的参数优化将大幅提升平台的性能。配置参数的优化,顾名思义就是找出参数配置中最优或接近最优的取值,让作业性能在该组参数配置下得以优化。表1罗列了一些常见的Spark可调参数以及专业人员给出的推荐配置。
在参数优化方面,Apache Spark官方网站的Tuning Spark文档[6]给出了相关的参数调优指导意见。Omid Alipourfard等[5]介绍了一个基于贝叶斯优化的系统,可以发现最佳或接近最优的云配置,最大限度地降低云使用成本,保证应用程序性能并限制重复大数据分析作业的搜索开销。Anastasios Gounaris等[7]根据实验运行的证据,将经验映射到试错法迭代改进方法,用于调整任意应用中的参数,提出了一种用于参数调整的替代系统方法,该方法可以很容易地应用到任何计算基础设施上。
陈侨安[8]等提出了一种基于近邻搜索算法的参数推荐方法,通过与历史数据库中的任务对比,为用户推荐同种任务类型的相关参数配置。但是这种方法没有明确定义如何判断两个任务是同类型的,而且过度依赖历史作业的参数信息导致结果并不完美。王国路[9]等把参数优化问题看作是机器学习中的分类问题,然后设计出一种二分类加多分类的多模型融合方法来实现参数调优,该方法的优点是实现了参数的自动调优,但缺点是对于确定不同应用程序的关键参数没有合适的解决方案。
在文献[10]中,作者调查了输入数据量对Spark应用程序的影响,确定关键参数与内存和压缩有关,但没有分析它们的确切影响。在文献[11]中的工作关注Spark在高性能计算(HPC)系统上的部署,确定了四个关键参数以及与应用程序相关的并行级别。在文献[12]中作者对Spark的瓶颈进行了彻底的调查,它声称许多应用程序都是CPU绑定的,内存扮演着关键角色。在文献[13]中,作者提出了一种称为主动协调的方法。给定一系列参数,主动协调可以调整和提高性能。为了识别那些没有或可能没有任何显著影响的参数,文献[14]通过测试每个参数的值来验证应用程序的敏感度。文献[15]使用遗传算法来检查可能的参数空间,这样的解决方案可能涉及太多的实验运行,我们提倡独立于应用程序大小的有限数量的配置运行。
5 进一步的研究方向
从配置参数优化的角度来看,面向领域的系统运行维护已经成为大数据技术的成本瓶颈。目前国内对于Spark参数配置优化的研究远不及国外,但关于Hadoop MapReduce参数配置优化的研究较多,Spark又是在Hadoop基础上的扩展,二者之间存在一定的相似性和联系。所以可以尝试将Hadoop参数调优的方法转换到Spark平台。另外越来越多的专家和学者开始运用机器学习的方法进行大数据分析平台的参数优化研究,所以以后也可尝试借助机器学习确定关键的参数,以便更准确快速地找到最优的参数配置组合。
6 结束语
随着大数据处理计算框架的不断出现,Spark在性能和对多种计算模型的支持上都具有突出优势,已经逐渐得到了广泛应用,但其性能优化问题尚未得到解决。本文主要介绍了Spark的工作原理,阐述了国内外该课题的研究现状,分析了参数优化的重要性和技术难点,并从配置参数调优的角度提出了优化Spark性能问题的解决方案和未来的研究方向。
参考文献:
[1] Apache Hadoop, http://hadoop.apache.org/.
[2] Apache Spark, http://spark.apache.org/.
[3] Apache Storm, http://storm.apache.org/.
[4] 门威. 基于MapReduce的大数据处理算法综述[J]. 濮阳职业技术学院学报, 2017,30(5):85-88.
[5] Omid Alipourfard, Hongqiang Harry Liu, Jianshu Chen, Shivaram Venkataraman, Minlan Yu, Ming Zhang, CherryPick: Adaptively Unearthing the Best Cloud Configurations for Big Data Analytics, Proc. of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17),Boston, MA, USA, March 27–29, 2017:469-182.
[6] SparkConfiguration, http: //spark.apache.org/docs/1.6.1/configuration.html.
[7] Gounaris A, Torres J. A Methodology for Spark Parameter Tuning [J]. Big Data Research, 2017.
[8] 陈侨安,李峰,曹越,等.基于运行数据分析的Spark任务参数优化[J].计算机工程与科学,2016,38(1): 11-19
[9] XU J G, WANG G L, LIU S Y, et al. A Novel Performance Evaluation and Optimization Model for Big Data System [C] // Proceedings of the 15th International Symposium on Parallel and Distributed Computing (ISPDC 2016). Fuzhou,China,2016: 1765-1773.
[10] A.J. Awan, M. Brorsson, V. Vlassov, E. Ayguade, How data volume affects spark based data analytics on a scale-up server, arXiv:1507.08340, 2015.
[11] Y. Wang, R. Goldstone, W. Yu, T. Wang, Characterization and optimization of memory-resident mapreduce on hpc systems, in: 28th International Parallel and Distributed Processing Symposium (IPDPS), 2014, pp. 799-808.
[12] A. Davidson, A. Or, Optimizing Shuffle Performance in Spark, Tech. Rep., Berkeley-Department of Electrical Engineering and Computer Sciences, University of California, 2016.
[13] 楊志伟,郑烇,王嵩,等.异构Spark集群下自适应任务调度策略[J].计算机工程,2016,42(1): 31-35,40.
[14] 王利, 王晶, 张伟功,等. Linux内核参数对Spark负载性能影响的研究[J].计算机工程与科学, 2017, 39(7):1219-1226.
[15] 康海蒙. 基于细粒度监控的Spark优化研究[D]. 哈尔滨工业大学, 2016.
