基于线性回归算法的电影票房预测研究
2019-03-14罗干蒋煜楷陈文婷吴镇州施运梅宋莹
罗干 蒋煜楷 陈文婷 吴镇州 施运梅 宋莹

摘要:该次研究利用从豆瓣电影和猫眼电影所爬取的电影基本信息数据和票房数据作为数据集。在进行线性回归训练之前,先将电影基本信息中的非数值型数据转化为数值型数据,然后利用Spark的机器学习库构建了票房预测模型。经过实验分析得出,所构建的预测模型在电影票房的预测上有较高的准确率,可为电影票房分析提供有效的参考信息。
关键词:线性回归模型;电影票房预测;评价;Spark
中图分类号:TP312 文献标识码:A 文章编号:1009-3044(2019)01-0202-02
1 背景
随着我国经济的发展,人民生活水平不断提高,文化消费有了爆发式的增长,中国的电影市场得以繁荣发展[1]。电影票房的预测也变得越来越有意义,在2013年的时候Google就发布了一篇名为《Quantifying,movie magic with Google Search》[2]的论文,里面提出了线性回归的电影票房预测模型。之后也有很多相关的研究,也取得了一系列的成果,且大多数研究的票房预测模型都没有对外公开信息。此外所采用的数据没有一个后续的更新,不能顺应电影发展脚步[3]。中国电影市场现在还有很多“现象级”[4]的电影,电影票房确实有很多不确定性。
该文将从豆瓣电影和猫眼电影上爬取的2011-2017年的院线电影信息,针对国内电影市场的特点,利用Spark的机器学习库(MLlib)的线性回归算法进行电影最终票房的预测。
2 相关技术介绍
该节将对电影票房预测中使用的主要技术进行简单介绍。
2.1 Spark计算引擎
Spark是在Hadoop MapReduce的基础上提出的新一代大数据分析框架,拥有Hadoop MapReduce所具备的全部优点,并且Spark是将计算结果直接存储在内存中,运算效率更高[5],让它非常适合机器学习与数据挖掘等需要迭代的算法。
Spark主要有三个特点:1)高级API剥离了对集群本身的关注,让开发者可以专注于计算本身。 2)Spark支持交互式计算和复杂算法。3)Spark是通用引擎,可用它来完成SQL查询、文本处理、机器学习等各种各样的运算。
2.2 机器学习库MLlib
MLlib(Machine Learnig Lib)是构建在 Spark 之上,一个专门用于大量数据处理的通用快速的引擎,是一个可以进行扩展的机器学习库,其目标是使实际的机器学习变得可扩展和容易。
MLlib 主要包含三个部分:1)底层基础:包括了Spark的运行库、矩阵库和向量库;2)算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法;3)实用程序:包括了测试数据的生成、外部数据的读入等功能[6]。
2.3 多元线性回归模型
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
2.3.1 模型描述
多元线性回归模型一般用公式(1)表示:
其中:Y为因变量;β1,β2,…,βn为回归系数;X1, X2,…,Xn为自变量;ε为随机扰动项;n 为变量个数。
Y是受n个自变量影响,每个自变量的影响程度由回归系数β决定,同时Y也受常量随机扰动项的影响。
2.3.2 评价方法
线性回归常用的检验方法有均方根误差(RMSE, Root Mean Squared Error),拟合评价参数R?,回归方程显著性检验F检验[7]。
RMSE的计算方法如公式(2),该参数能很好地反映真实值与预测值之间的偏离程度。
其中,x为自變量,y表示因变量,n为自变量个数。
RMSE的取值范围在[0,∞],值越小则预测效果越好。
拟合是指回归直线对观测值的拟合程度,拟合评价参数 R?的取值范围为[0,1],取值越接近1,说明回归直线对观测值的拟合程度越好;反之,R?的值越小,说明回归直线对观测值的拟合程度越差。
3 基于多元线性回归的票房预测
该文从猫眼电影和豆瓣电影两个网站上一共抓取了1642部电影的相关数据,包括:电影票房、影片类型、导演、演员、上映日期、上映年份和电影评分。
在所采集的电影数据中,包括数值型和非数值型两大类数据。其中影片类型、导演、演员和上映日期均为非数值型数据;电影票房、电影评分、上映年份为数值型数据。由于非数值型数据无法用于线性回归算法,所以需要对非数值型数据进行转化。
3.1 非数值型数据的转换
其公式(5)中TWi表示类型i的票房影响力,n代表该电影所属的类型有n种。
其余非数值型数据可以由此类推,得到数值化后的结果。
3.2 应用线性回归算法进行票房预测
经过初步预测,该文将电影票房定义为因变量Y。筛选以下变量为自变量:电影评分定义为X1,导演影响力为X2,主演影响力为X3,电影类型影响力为X4,上映日期影响力定义为X5,上映年份为X6。可以得到该多元线性回归的模型为:
Spark中的ML库提供了对各种机器学习算法的支持,spark.ml.regression.LinearRegression包支持的是线性回归算法。进过多次实验的比对,对算法中的各参数的设置如下:
最大迭代次数 MaxIter = 50
正则化参数 Regparam = 0.3
混合参数 ElasticNetParam = 0.8
最后得到多元线性回归预测模型中的回归系数取值如表1:
4 预测结果验证
该文采用了两种方式对预测效果进行了验证:一种是计算拟合评价参数R2,另一种是将预测结果与实际的票房进行比对。
通过计算,得到拟合评价参数R2的结果为0.843,说明预测效果良好。
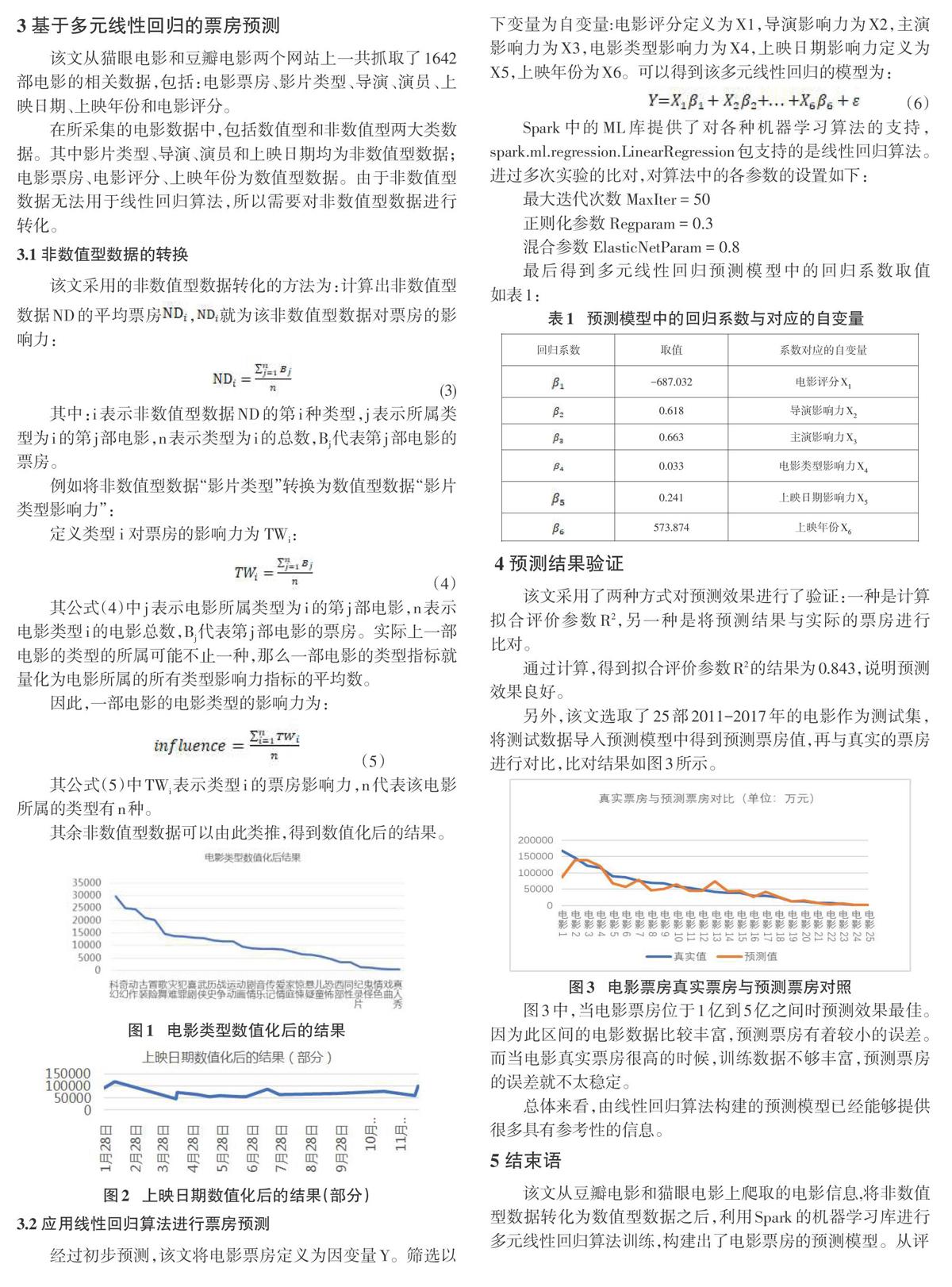
另外,该文选取了25部2011-2017年的电影作为测试集,将测试数据导入预测模型中得到预测票房值,再与真实的票房进行对比,比对结果如图3所示。
图3中,当电影票房位于1亿到5亿之间时预测效果最佳。因为此区间的电影数据比较丰富,预测票房有着较小的误差。而当电影真实票房很高的时候,训练数据不够丰富,预测票房的误差就不太稳定。
总体来看,由线性回归算法构建的预测模型已经能够提供很多具有参考性的信息。
5 结束语
该文从豆瓣电影和猫眼电影上爬取的电影信息,将非数值型数据转化为数值型数据之后,利用Spark的机器学习库进行多元线性回归算法训练,构建出了电影票房的预测模型。从评价结果看,构建好的预测模型有着比较好的预测结果。
但是该预测模型还存在着有待改进的地方,比如说该文采用的非数值型数据转化为数值型数据的方法,转化后的导演、演员的影响力数值差异变得很大,会削弱其他变量对票房的影响。此外,目前所爬取的数据还不够丰富、数据更新不够及时,这些影响了模型的准确性。
有文献[8]提到多元线性回归预测模型的优势在于能清楚地解释影响因素对票房的影响程度,但在预测精度上不如神经网络。
在下一步的工作中,将着手解决目前存在的问题,并尝试采用神经网络的方法构建模型,与现有的模型进行比对,进一步提高预测的准确度。
参考文献:
[1] 李龙生, 李晓怡. 由近期国产电影的高票房现象浅析中国电影产业的发展[J]. 艺术与设计: 理论, 2018, 2(9): 119-121.
[2] Reggie Panaligan, Andrea Chen. Quantifying Movie Magic with Google Search[EB/OL]. http://www.webmasterworld.com/google_adwords/4581847.htm.
[3] 何曉雪, 毕圆梦, 姜绳. 基于网络数据预测电影票房的多元线性回归方程构建[J]. 新媒体研究, 2018, 4(5): 41-48.
[4] 刁文鑫. 当代中国“现象电影”的传播特征及影响研究[D]. 合肥: 安徽大学, 2018.
[5] 马天男, 牛东晓, 黄雅莉, 等. 基于Spark平台和多变量L_2-Boosting回归模型的分布式能源系统短期负荷预测[J]. 电网技术, 2016, 40(6): 1642-1649.
[6] 殷乐, 姚远, 刘辰. 基于Spark的用户行为分析系统框架研究[J]. 网络安全技术与应用, 2018(2): 56-57.
[7] 彭辉, 赵亚军, 胡章浩. 应用多元线性回归模型的铁路客运量预测[J]. 重庆理工大学学报: 自然科学, 2018, 32(9): 190-193.
[8] 张雪. 基于深度学习卷积神经网络的电影票房预测[D]. 北京: 首都经济贸易大学, 2017.
