一种改进的实体识别方法实现
2019-03-14蒋存锋赵川
蒋存锋,赵川
(1.上海计算机软件技术开发中心,上海 200000;2.Teradata Corporation,圣地亚哥,美国)
0 引言
排序是计算机程序设计中一项基本的操作,在实际应用中,有很多情况下需要对数据按照某种方式进行排序后才能达到某种要求,因此,学习和研究各种排序方法是计算机工作者的重要课题之一。
实体识别也称为重复记录去除、身份识别、对象识别、引用识别、记录连接、混合-清除、数据关联等。
实体是由属性来描述的,属性的值构成了某个特定实体的信息。例如,一个人有诸如姓名、生日、指纹等属性。因为实体是真实世界的实体,所以属性值的集合是独一无二和真实存在的。我们可能知道一个实体的真实属性值,也可能不知道。我们只有实体的引用,也就是实体属性值的一个集合。对于某一个特定实体,我们可能有多个引用,每一个引用都有不同的属性值集合。因为这些集合看上去不同,所以我们需要确定他们是否对应的是同一个真实世界实体。从一个比较窄的意义上来说,这也就是实体识别要做的事情。在更广泛的意义上,实体识别还牵涉到更多的工作。有的数据也许是没有结构的,也没有明显的实体引用(属性值集合)。或者有实体引用,但是缺乏统一的格式。Talburt[1]列出了实体识别在一个广泛意义上所涉及的五个主要的工作:
●实体引用抽取:从无结构信息中定位和收集实体引用;
●实体引用准备:在识别之前,对结构化的实体引用施加标准化、数据清洗等技术;
●实体引用识别:确定引用是否对应同一个实体;
●实体身份管理:建立和维护一个长久的实体身份信息记录;
●实体关系分析:开拓不同的但是相关的实体之间的关联网络。
我们的研究工作主要涉及的是实体引用的准备和识别。实验所使用的数据源是文本格式,并含有明显的实体属性和值,所以不需要进行实体引用抽取的工作。不过我们做了一些实体引用的准备工作来提高数据质量,以便更好地比较它们。
1 方法概述
1.1 常用方法
一般地,进行实体识别的技术需要在记录对之间建立良好的匹配标准,这样实体识别也可以看作是分类问题:对于两个记录的每一对对应的属性值之间的相似值构成的一个向量,把它归类为“匹配(副本)”或者“不匹配(非副本)”。匹配标准可能涉及到一个度量标准和一个用户定义的临界值,用来确定区分匹配记录和不匹配记录的点。根据一些通常的定义[2],匹配标准返回三个不同的值:匹配、不匹配、需要进一步检查。Brizan和Tansel[3]对不同的匹配技术做了一个简洁的描述。Elmagarmid等人[4]总结了检测不相同但是等价的数据库记录的技术。
实体识别系统一般使用四种基本的技术来确定是否两个引用是等价,或者称为对应同一个真实实体。它们是直接匹配、传递等价、关联分析、断言等价[2]。在我们改进的实体识别框架中我们使用了所有的四种技术。
传统的实体识别方法经常使用数据属性值之间的文本相似性。一些比较新的方法则考虑由数据上下文导出的关系相似性作为附加的信息,还有一些方法是基于概率模型的。匹配含有多个属性的记录方法大致可以分为两类。一类是依靠学习数据来“学习”如何匹配数据,这一类方法通常使用概率的方法以及监督的机器学习技术。另一类方法依靠领域知识或者属性距离度量标准来匹配记录。
1.2 改进的方法
通过研究,我们结合两种匹配方法中有用的部分,并进行改进,得到一种更为有效的匹配方法[5]。该方法提出了一个既使用直接相似度又使用间接相似度的结构化的相似度度量标准,并对非监督学习使用一个简单的相似度模型,对监督学习则提供了一个概率的分类模型以及估算概率的方法。此外该方法提供了简单的更新算法来消除分类匹配结果中的不一致性。
我们沿用了相似度度量和概率模型,并在此基础上做了较大的改进。不但进行实体的识别,还兼顾到对象的合并。增加了数据预处理(pre-processing)的步骤,在其中设计了一种数据过滤策略。同时,还大大增强了后期处理过程(post-processing),设计了几种不一致性消除的方法以及两个有效的记录更新算法。这些步骤都大大改进了计算效率和分类结果。另外,记录更新算法还有两个功能:一个是找到“正确”的记录(拥有“真实”属性值的记录),另一个是为非监督学习找到一个好的匹配临界值。
我们仍然使用F1(F度量中最常用的一种形式(Rijsbergen[6]))和AUC(Area Under precision-recall Curve)。实验结果表明我们的方法对非监督学习和监督学习都能够获得高质量的实体识别结果。我们改进后的方法包含了狭义上实体识别的整个过程,并且其中的某些步骤是比较通用的,能够应用到其他基于记录对匹配的实体识别方法中。
对于较大的数据集或者是计算起来比较耗费时间的相似度度量,整个实体识别过程的运行时间可能会是一个问题。为了解决这个问题,一般会使用分块(blocking)或者遮蔽(canopy)(Elmagarmid等[4],Sarka等[7])的方法来有效地选择记录对的一个子集来进行相似度计算,而简单地忽略其他“不相似”的记录对。在我们的研究中,我们设计了一个数据过滤方法,它和遮蔽有着类似的效果。
我们的方法和经典的FSM(Fellegi-Sunter Model)主要有两点不同:首先,我们使用不同的概率匹配模型。FSM使用属性值的模式,而我们的方法使用相似值的模式。其次,FSM只使用直接匹配,而我们的方法使用直接匹配、传递等价,以及断言等价。此外,我们所改进的方法使用的间接相似度度量是基于上下文的,这就提供了进行关联分析的好处,当然我们并不做直接的集体匹配决策。
1.3 主要贡献
我们实体识别的研究工作的主要贡献有:
●我们将原方法[5]扩展成了一个通用的框架;
●我们设计了两个记录更新算法来:改进分类结果,找到“正确”的记录,以及为非监督学习找到好的匹配临界值;
●我们设计了不一致性消除方法来消除匹配结果中的不一致性,同时提高匹配的精确度。
我们把实验结果同几个较新的实体识别方法(Sin⁃gla和Domingos[8]、Wick等[9],以及Rendle和Thieme[10])的结果进行了比较(使用F1和AUC)。对于相同的数据集,我们的方法总体上要优于其他方法。
2 方法框架

图1 方法框架
我们的方法框架如图1所示。在预处理步骤中,我们使用过滤来有效降低需要比较的记录对的个数。接下来是匹配过程,我们对过滤后的每一对记录对计算它们的相似度(对于非监督学习)或者相似度和等价概率(对于监督学习),以此来确定该记录对是否是等价的。匹配过程经常会产生一些不一致的结果,所以我们设计了消除不一致性的方法,经过这一步,我们可以输出关系集合(R),它是所有记录对的关系(等价或者非等价)集合。在这一步后,我们还设计了记录更新的算法。在记录更新步骤中我们更新某些记录的属性值来提高识别的准确性,同时会输出“真实”记录集合(T)。此外,对于非监督学习,记录更新步骤还能找到好的匹配临界值。不一致性消除,记录更新以及等价消除构成了我们框架中的后期处理过程。后期处理过程结束后,我们可以完成任务输出结果,也可以回到预处理步骤重复整个过程。一般情况下一遍过程就可以获得很好的结果。
3 实验结果
3.1 实验环境
所有实验在一台PC上进行,配置如下:
●CPU:AMD Phenom II 2.9G Hz;
●内存:3.25GB。
我们使用两个公共的数据集Cora和CDDB。
Cora是一个科学出版物参考文献信息的数据集。我们从Weis等[11]处下载此数据集。它包含了1878个引用,而这些引用实际上只对应139个研究论文。它是McCallum[12]提供的数据集的扩展的版本。Cora数据集中的记录有五个属性:标题、作者、出处、卷号,以及日期。我们在数据预处理步骤中对该数据集进行了一些清洗工作,去除了一些标点符号。如果某记录的作者超过一个,我们把该记录的每一个作者单独作为一个作者属性值。
CDDB数据集包含9763个从freeDB随机抽取的音乐CD的信息。我们也是从Weis等[11]处下载此数据集。CDDB不像Cora数据集那样有很多等价记录,它的记录对应9388个不同的音乐CD,所以等价的记录只是一少部分。每个音乐CD记录有七个属性:艺术家、标题、分类、流派、年份、额外信息,以及音轨标题。类似的,我们把一条记录的每一个艺术家单独作为一个艺术家属性值。
3.2 监督学习实验结果
因篇幅所限,我们略去非监督学习的实验结果。
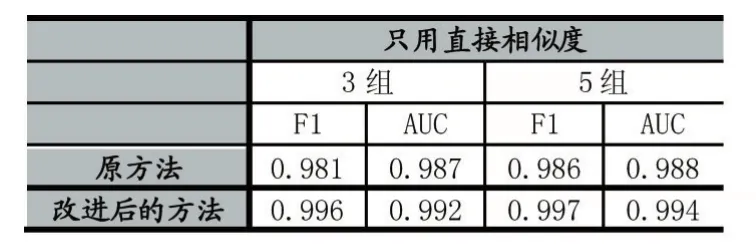
表1 Cora数据集实验结果
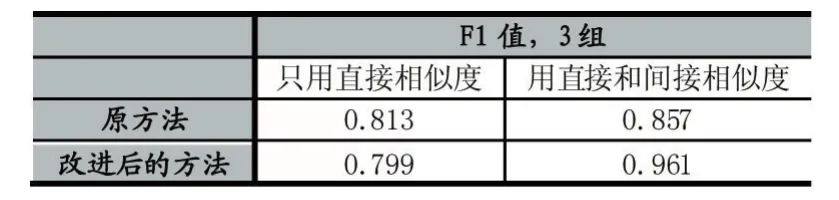
表2 CDDB数据集实验结果
表1和表2中,3组和5组是指3组交叉验证和5组交叉验证。从表1和表2来看,我们改进后的方法比原方法除了一项结果有略微下降以外其他的都有明显的提高。
4 有关研究工作
Chen等[13]提出了一种基于图的实体识别方法。该方法分析由数据集构建的实体关系图,并度量不同节点对之间的互联度。
Dong等[14]考虑复杂的信息空间来解决引用关系重建的问题。该算法在决定合并两个引用的时候,它会使用引用增强机制来利用上下文信息。他们的引用增强有一点类似与我们的记录更新。不过我们的记录更新是有一些限制的更新记录,而不是合并。
Singla和Domingos[8]提出了一个基于马尔科夫逻辑的集成的实体识别方法。马尔卡夫逻辑结合了一阶逻辑和概率图模型。我们把同一个数据集上的实验结果和他们的进行了比较。
Bhattacharya和Getoor[15]针对非监督学习实体识别扩展了隐含狄利克雷分布(Latent Dirichlet Allocation)模型,并且针对引用互相连接的关系领域的集体实体识别提出了一种概率模型。
Rendle和Thieme[10]提出了一个使用结构化信息的模型来进行集体的对象身份识别。我们把同一个数据集上的实验结果和他们的进行了比较。
Cong等[16]研究了有效的方法来改进数据一致性和精确度。他们采用了一类条件的功能依赖(Bohannon等[17])来指定数据的一致性。他们设计了两个算法来改进数据的一致性。
Chaudhuri等[18]观察到某些情况下数据中额外的约束可被用来评估重复数据去除的质量。
Bilgic等[19]介绍了一个叫D-Dupe的交互工具。该工具结合了实体识别数据挖掘算法和网络可视化来展现潜在的等价数据的协作上下文。
Arasu等[20]提出了一个在约束下的集体的重复实体引用去除的方法。该方法基于一个简单的具有精确语义的说明性语言。
Wick等[9]提出了一种差异性学习模型来联合进行引用识别和规范化(生成实体稳定表示的过程)。我们把同一个数据集上的实验结果和他们的进行了比较。
斯坦福SERF项目组(Benjelloun等[21])开发了一个叫Swoosh的一般的实体识别方法。他们确定了四个属性,如果这些属性被匹配和合并函数满足的话将会使得实体识别算法更加有效。他们为这些属性的不同情形开发了不同的算法。他们并没有研究这些匹配合并算法的内部细节,而是把它们视为被实体识别引擎调用的黑盒子。
更全面的实体识别方法概览可以参考Elmagarmid等[4]以及 Winkler[22]。
5 结语
虽然我们已经在很大程度上改进了原来的方法,但是依然有很多改进的空间。方法中使用的直接相似性和间接相似性有图形的解释,但是它们还可以集成地更好。CDDB数据集的实验结果比Cora要差一点,也是有改进的余地。尽管我们使用了数据过滤方法来大大降低候选记录对的数量,对于非常大的数据集来说,成对的记录匹配的效率依然可能会是一个问题。
