基于数据挖掘技术的图书馆个性化快速推荐算法研究
2019-03-12王庆桦
王庆桦
关键词: 数据挖掘; 关联规则运算; Apriori算法; 算法改进; 个性化推荐; 关联分析
中图分类号: TN911.1?34; TP391 文献标识码: A 文章编号: 1004?373X(2019)05?0149?03
Research on library personalized fast?recommendation algorithm
based on data mining technology
WANG Qinghua
(Tianjin Sino?German University of Applied Sciences, Tianjin 300350, China)
Abstract: With the continuous development of the construction of university book management system, the book borrowing activities of teachers and students have generated a large amount of browsing data. In order to mine the above borrowing information to provide a higher level of service for readers, a library personalized fast?recommendation algorithm based on data mining technology is proposed. The main methods and organizational structure of data mining are introduced. The Apriori algorithm as a classical association rule mining algorithm is modified to improve the computing efficiency of association rules. The improved Apriori algorithm is used to perform the association analysis for the historical data of the book borrowing, so as to make the personalized recommendations for readers. The experimental results show that the proposed library personalized fast?recommendation algorithm has high accuracy and operational efficiency.
Keywords: data mining; association rule operation; Apriori algorithm; algorithm improvement; personalized recommendation; association analysis
0 引 言
数据挖掘作为近期全球范围内快速兴起的一门交叉学科,汇集了来自机器学习、模式识别、数据库、统计学、人工智能等各领域的研究成果[1?3]。计算机的大规模普及产生了海量的数据,数据挖掘通过综合以上学科领域的技术成果,对海量数据进行处理和分析。目前,数据挖掘在信息管理系统中的应用案例越来越多,相关领域的研究也层出不穷。文献[4]提出面向机场场区管理的商务智能理念,设计一种应用数据挖掘技术的机场场区数据挖掘系统,并完成了具体应用实例。文献[5]利用数据挖掘技术对智能化车辆管理系统进行设计,实现了系统的优化升级,从而起到较好的控制分流和防止拥堵的作用。
目前,我国各大城市和高校的图书馆大都已经使用了图书自动化管理系统。这些管理系统一般将数据存放在专门的网络服务器上。但是,随着借阅历史记录的不断增长,生成了数量越来越大的数据信息。现有的图书自动化管理系统仅能进行查询、统计汇总等表面分析工作。如果要对这些海量的数据进行进一步挖掘,就需要投入大量的人力和时间成本,而且往往得不到有价值的分析结果。因此,本文对经典关联规则挖掘算法中的Apriori算法进行改进,提高了关联规则的运算效率。并将改进算法应用于图书馆个性化推荐,以便对图书借阅历史数据进行关联分析,仿真结果表明,提出的改进推荐算法具有较高的准确度和运行效率,能够有效根据不同的读者属性提供有针对性的图书推荐。
1 数据挖掘的概念
1.1 数据挖掘的主要方法
数据挖掘(Data Mining)是按照既定的业务目标从海量数据中提取出潜在、有效并能被人理解的模式的高级处理过程[6]。它利用现有数据库管理系统的查询、检索及报表功能,与多维分析、统计分析方法相结合,进行联机分析处理,从而得出可供决策参考的统计分析数据。数据挖掘的主要分析方法包括归纳学习法、聚类方法、统计分析方法、关联规则分析、仿生物技术和分类预测等,如图1所示。由于关联规则分析能够揭示出某个事务与其他事务之间隐含的关联性。本文选择关联规则分析作为图书借阅信息数据挖掘的方法。
1.2 数据挖掘的组织结构
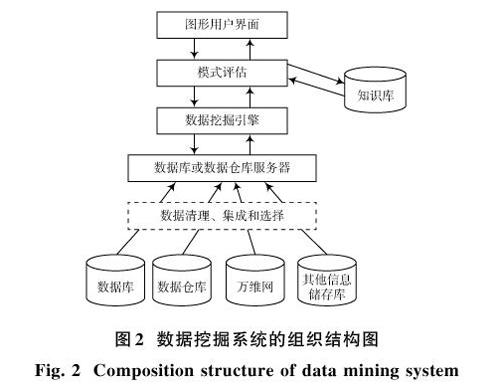
一个典型的数据挖掘系统通常包含:数据源、数据库或数据仓库服务器、知识库、数据挖掘引擎、模式评估和图形用户界面,如图2所示。
2 改进的Apriori算法
目前, 不少研究人員已经提出将数据挖掘技术应用于图书管理工作。文献[7]通过挖掘高校图书馆大量的借阅历史数据,从中提取出切实有用的信息及有效的借阅规则,可为读者提供个性化的推荐服务,进而提高图书馆馆藏图书的流通率。文献[8]提出将关联规则挖掘算法中的Apriori算法应用于高校图书管理系统,对图书的摆放方式提出相关建议,从而达到方便图书管理、便捷学生借阅的目的。但是传统Apriori算法在运行效率上存在缺陷,需要对数据库进行多次搜索,这在一定程度上降低了数据挖掘的执行效率。因此,本文对经典关联规则挖掘算法中的Apriori算法进行改进。
关联规则Apriori算法能够通过某个规则发现两种事物之间存在的一些隐藏关系。关联规则可以用[X→Y]表示,其中,[X]表示关联规则的条件,[Y]表示关联规则的延续[9]。此外,关联规则算法中具有支持度和置信度的定义,计算公式如下所示:
[P(AB)=P(AB)P(B)] (1)
式中[A]和[B]表示不同的事件。
可以通过式(2)计算支持度与置信度之间的对应关系:
[conf(YX)=P(YX) =P(XY)P(X)≈XY出现次数X出现次数] (2)
在设定好最小支持度(Min_Sup)和最小置信度(Min_Conf)之后,Apriori算法首先会读取数据库中的所有事务集,产生候选1项目集合的支持度,然后再次搜索事务数据库,产生候选2项目集合的支持度。在获得所需的候选项目集合后,仍需搜索数据库以便进行支持度对比,得出频繁项目集合从而最终生成新的候选项目集合。通过以上算法实现过程可以看出,传统Apriori算法的步骤中,读取和搜索数据库的次数较多,这在一定程度上降低了数据挖掘的执行效率。所以,本文对生成候选项目集[Ck]的过程进行了优化,以便减少数据库读取的次数,并且避免产生更多的无用候选项目集。改进Apriori算法的伪代码如下:
1 for each [lxLk-1];
2 {
for each [lyLk-1]
3 {
if ([lx][1]=[ly][1]∧[lx[2]]=[ly][2]∧[lx[k-2]]=[ly[k-2]]∧[lx[k-1]<][ly[k-1]])
4 {
5 [c=lx∪ly] //完成2个项集的连接
6 [Ck=c∪Ck]
}
7 else break
}
}
8 end for
9 return [Ck] //返回连接生成的项集
3 仿真测试
3.1 实验环境和参数
为了对本文提出的改进Apriori算法进行分析和验证,进行仿真测试。实验硬件环境为: Intel Core i5 2.8 GHz处理器,2 GB内存,300 GB硬盘。实验软件环境为:Windows XP操作系统,Matlab 7.0仿真软件。实验采用某高校中图书管理系统的数据集。该数据集包含图书馆5年内的图书借阅历史记录,并对其进行数据泛化。由于本文研究不同图书类别之间的关联规则,所以把该数据集中的所有书籍分为6大类,分别为I(信息技术类)、E(英语类)、L(机械类)、A(艺术类)、B(电气类)、H(文学类),对这6类图书进行数据泛化见表1。

为了验证提出算法的先进性,在相同的仿真条件下,分别对本文改进算法和传统Apriori算法进行对比实验。
3.2 评估指标
本文采用平均绝对误差(Mean Absolute Error,MAE)[10]完成推荐算法的性能评估。MAE的具体计算方法如下:
[MAE=i=1NPi-ViN] (3)
式中:[Pi]为推荐算法的预测评分;[Vi]为测试数据中用户的实际评分;[N]表示测试的总数。MAE的取值范围是[0,1],其值越接近0,则推荐算法的准确度越高。
3.3 推荐性能分析
随着图书借阅记录数据的不断增加,2种不同推荐算法的MAE结果如图3所示。2种不同算法的运行效率比较如图4所示。

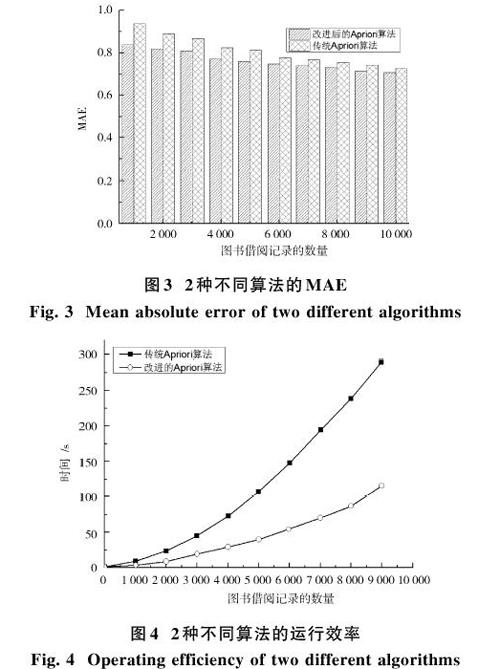
从图3中可以看出,随着图书借阅记录的不断增加,2种方法的准确度都不断提高,且两者几乎一致。但是,从图4可以看出,相比传统Apriori算法,本文提出改进算法的所用时间增长较慢。也就是说,本文提出算法能有效完成个性化图书推荐,并且在不降低准确度的前提下,有效提升了数据挖掘的效率。
4 结 语
本文对经典关联规则挖掘算法中的Apriori算法进行了改进,提高了关联规则运算效率。并将改进算法应用于图书馆个性化推荐,以便对图书借阅历史数据进行关联分析,仿真结果表明,相比传统Apriori算法提出的改进推荐算法具有较好的准确度和运行效率,能够有效根据不同的读者属性提供有针对性的图书推荐。
参考文献
[1] ESLING P, AGON C. Time?series data mining [J]. ACM computing surveys, 2012, 45(1): 1?34.
[2] MUKHOPADHYAY A, MAULIK U, BANDYOPADHYAY S, et al. Survey of multiobjective evolutionary algorithms for data mining: Part II [J]. IEEE transactions on evolutionary computation, 2014, 18(1): 20?35.
[3] HARPAZ R, DUMOUCHEL W, SHAH N H, et al. Novel data?mining methodologies for adverse drug event discovery and analysis [J]. Clinical pharmacology & therapeutics, 2012, 91(6): 1010?1021.
[4] 朱小栋,樊重俊,杨坚争.面向机场场区管理的数据挖掘系统[J].计算机工程,2012,38(3):224?227.
ZHU Xiaodong, FAN Chongjun, YANG Jianzheng. Data mi?ning system for airport regional management [J]. Computer engineering, 2012, 38(3): 224?227.
[5] 周鹏.数据挖掘技术下的智能化车辆管理系统实现[J].现代电子技术,2016,39(16):52?54.
ZHOU Peng. Implementation of intelligent vehicle management system based on data mining technology [J]. Modern electronics technique, 2016, 39(16): 52?54.
[6] CAROLAN B V, NATRIELLO G. Data?mining journals and books: using the science of networks to uncover the structure of the educational research community [J]. Educational researcher, 2005, 34(3): 25?33.
[7] 杨国林,王飞,贺慧.基于数据挖掘的图书馆数据预处理方法研究[J].电子设计工程,2015(3):23?25.
YANG Guolin, WANG Fei, HE Hui. Research on the preprocessing methods of library data based on data mining [J]. Electronic design engineering, 2015(3): 23?25.
[8] 王娜,岳俊英.基于关联规则的高校图书信息数据挖掘[J].信息系统工程,2014(2):153?154.
WANG Na, YUE Junying. Colleges book information dada mi?ning based on association rules [J]. China CIO news, 2014(2): 153?154.
[9] POULIS G, SKIADOPOULOS S, LOUKIDES G, et al. Apriori?based algorithms for [km]?anonymizing trajectory data [J]. Tran?sactions on data privacy, 2014, 7(2): 165?194.
[10] BHANDARI A, GUPTA A, DAS D. Improvised Apriori algorithm using frequent pattern tree for real time applications in data mining [J]. Procedia computer science, 2015, 46: 644?651.
