基于深度学习的人脸多属性识别系统
2019-03-12杨俊钦张雨楠林实锋徐伟臻
杨俊钦,张雨楠,林实锋,徐伟臻
(广州大学计算机科学与教育软件学院,广州 510006)
0 引言
人脸作为人体显著的生物特征之一,与指纹、虹膜一样包含着丰富的个人信息,如:性别、年龄、种族、表情、发型、是否戴口罩帽子,等等。这些人脸属性信息在海量图像检索、智能视频监控、辅助驾驶、人机交互、精准广告投放、娱乐休闲等系统中有着广泛的应用,涉及安防、金融、广告、娱乐等多个领域,与人们的生活息息相关。此外,相比于指纹、虹膜等生物特征所含有的信息,人脸属性具有信息易于获取、识别符合人类习惯等优势。
在传统的人脸属性识别方法中,程序通常先检测人脸区域,再提取以关键点为中心的图像块的高维特征,如方向梯度直方图特征(Histogram of Oriented Gra⁃dient,HOG)[1]或局部二值模式特征(Local Binary Pat⁃tern,LBP)[2],然后将其拉伸成长向量训练分类器对属性进行识别。这类方法对于限定条件下的正脸图像表现尚可,但在非限定条件下易受复杂环境影响,其准确率不高,难以满足人们的需求。
近年来,深度神经网络发展迅速,许多图像识别研究基于深度学习开展。在人脸属性识别问题上也出现了多种深度神经网络的方法和应用,如L-MFCNN方法[3],面向嵌入式应用的DeepID网络模型[4],等等。但是大多神经网络方法主要针对单一或者少量的人脸属性,很少做到多个属性识别,难以满足市场的需求。根据上述问题,本文设计并实现了一种基于深度卷积神经网络(Deep Convolution Neural Networks,DCNNs)的人脸多属性识别系统。该系统利用公开的人脸属性数据集CelebA[5],基于PyTorch深度学习框架设计训练了级联的深度卷积神经网络模型,模型在CelebA上的平均识别准确率达到了90.09%。
1 模型基础架构介绍
为了提高自然场景下的人脸属性识别的准确率和效率,本系统基于深度学习算法,设计了人脸属性识别模型,模型级联了人脸关键点(landmark)定位和人脸属性识别两个网络。对于自然场景下的图片输入,模型首先使用人脸关键点定位网络对人脸进行关键点定位,进而根据定位结果校准并截取人脸图像,最后将对齐后的人脸图像输出到人脸属性识别网络中,完成属性识别。其整体工作流程如图1所示。

图1 人脸属性识别流程图
1.1 人脸关键点定位与人脸对齐
人脸关键点定位,即在原始图像的基础上定位人脸的关键点,例如眼睛、鼻子、嘴巴等的坐标。其目的是为了利用定位的关键点进行人脸图像的校准与截取,排除角度、姿态因素对于人脸图像分类的影响。
本文采用一个主干-分支的全卷积神经网络模型(Backbone-Branches Fully-Convolutional Neural Net⁃work,BB-FCN)来进行人脸关键点定位。该模型能够直接从原始图像产生人脸关键点热度图而不需要任何预处理工作。模型采用了从粗到精的定位过程,先采用全局的主干网络粗略地估计人脸关键点的位置,然后对全局关键点位置取图像块训练分支网络,进一步优化该关键点的定位。为了提高算法的运行效率,模型只标注人脸的双眼、鼻子和嘴巴的两个嘴角共计5个关键点。
模型进行关键点定位的具体操作过程是:首先把整幅图像输入到BB-FCN的主干网,主干网由多个卷积层和最大值池化层交替堆叠而成,处理所有关键点、输出低分辨率的响应图像;然后根据响应图像反向定位关键点,以关键点为中心提取原图像中的相应的图像块;接下来以包含关键点的图像块为输入训练分支网络,分支网络仅包含卷积层以保证最后输出准确定位高分辨率的响应图像。
关键点定位完成以后,本文以双眼的坐标连线的中点为原点建立二维直角坐标系,将图片旋转变换,使双眼的坐标点位于水平轴方向上,以此完成人脸的对齐。之后,借助已定位的关键点坐标的横、纵向位置,分别估计出人脸的高度和宽度,以此截取出对齐的人脸图像。
1.2 人脸属性识别
经过人脸关键点网络的定位后,系统得到对齐的人脸图像,根据对齐的人脸图像,系统需要进行进一步的人脸多属性分类。
在人脸属性识别模型中,文献[5]最先提出使用ANet+LNet的深度学习方法进行人脸多属性进行识别,超越了传统方法。MOON[6]在DCNNs的基础上,通过改进网络模型和人脸属性数据集的不平衡时难以对深度卷积神经网络进行多任务联合优化的问题,进一步提高了准确率。随着近年来深度学习的快速发展,深度卷积神经网络的模型性能不断完善,人脸多属性识别的准确率还可进一步提升。
本文采用残差网络来进行人脸属性识别。残差网络是利用残差来重构神经网络的映射,把输入x再次引人到结果,其相比其他网络模型更易于优化,并且可以大幅增加网络深度,从而提高识别准确率。残差网络的结构是由多个残差块堆叠而成,单个残差块采用跨层连接的模式设计,内部由两个卷积结构组成,其结构如图2所示。

图2 残差块模型
2 模型训练和实验结果
2.1 数据集介绍
本文采用了香港中文大学发布的CelebA人脸属性数据集作为实验数据集。该数据集包含约20万张人脸图像,每张图片提供了40个人脸属性标注和5个人脸关键点的位置信息。本文依据CelebA官方的标准,取其中的约16万张人脸图像用于网络模型的训练,约2万张图像用于验证,2万张图像用于测试网络模型。本实验在CelebA提供的图片数据集上进行模型准确率的测试,并联合整个系统进行系统的性能测试,对系统的现实应用能力进行综合评估。
2.2 优化目标和评价方法
针对多标签分类问题,本系统算法使用交叉熵作为损失函数进行训练,该函数创建一个衡量目标和输出之间的交叉熵的标准,其公式如公式(1):

公式(1)中的m表示属性总数,ni表示第i个属性的样本总数,y(i)指第i个属性第j个样本的标注值,而jhx(i)指第i个属性第j个样本的预测值。θj
为了方便与其他网络模型的实验结果比较,本文采用了多属性平均识别准确率(mACC)作为评价标准,其计算公式如下公式(2):

2.3 实验结果
本文随机抽取12项人脸属性进行测试,其平均识别准确率达到了90.02%。实验结果见表1,在相同的测试条件下,所有属性的识别准确率均高于已有的方法 ANet+LNet和 MOON。

表1 在数据集CelebA上识别正确率比较
3 识别系统构建
3.1 系统环境
系统运行平台为Windows 10操作系统,开发语言为Python 3.5.2,基于PyTorch神经网络开源框架开发。
3.2 系统流程
本文的人脸属性识别系统功能主要分为两部分:图像获取和属性识别。
图像获取分为两种方式:第一种方式是系统调用摄像头设备,拍摄并采集图像,将图像存入内存进行识别。本系统对摄像头的调用通过OpenCV(Open Source Computer Vision Library)计算机视觉库实现。OpenCV调用摄像头获取图像的步骤为:①利用Video⁃Capture函数获取摄像头对象;②在内存中开辟三维矩阵空间用以保存彩色(多通道)图像;③将图像的像素以矩阵形式保存到内存中。
第二种方式是通过用户选取保存在硬盘内部的人脸图像文件,将其送入内存中。
属性识别部分的具体工作流程主要包括以下几个步骤:从内存中获取图像,对图像进行人脸关键点定位、人脸校准以及人脸截取处理,预处理后进行人脸属性识别,最后将识别结果输出。
具体工作流程如图3所示。
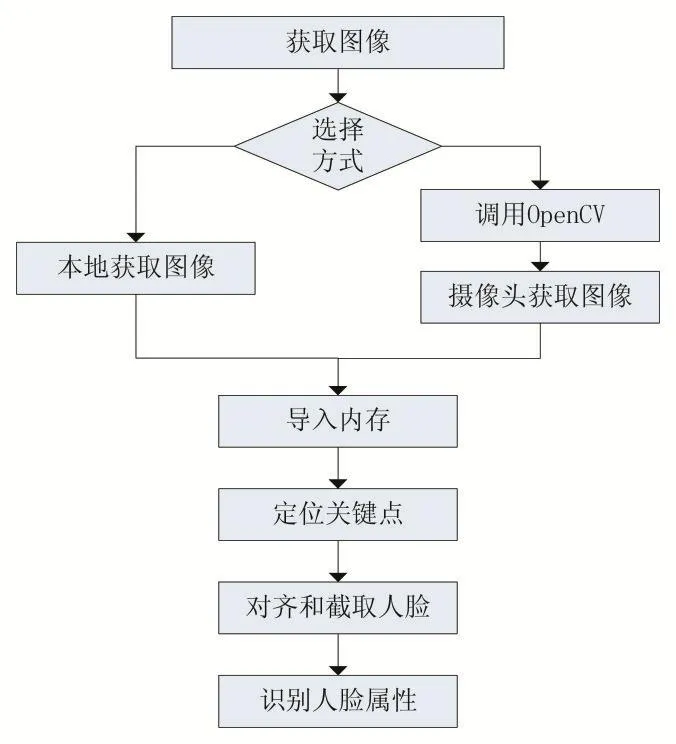
图3 系统运作主要流程
3.3 系统性能评价
系统效率的主要影响因素为神经网络模型的加载和对图像的处理速度。我们在CelebA数据集上进行测试,单张图片从加载到完成所有属性的识别需时236ms。该时长保证了用户在使用系统时能有较好的交互体验。
3.4 系统成果展示
系统运行时的效果如图4所示。系统提供了用摄像头获取图像、从本机选取图像、属性识别图像等多种功能。用户能够通过两种方式输入图像,对系统进行识别。一种是从本机中选取人脸图像,图像选择后将显示在界面中部;另一种是通过调用计算机配备的摄像头直接获取用户图像,将获取的图像显示在界面中部。识别之后界面右侧出现识别结果。

图4 系统运行结果
4 结语
本文设计并实现了一个人脸多属性识别系统。该系统设计了级联的神经网络分别对图像进行关键点定位和属性识别,其中关键点定位采用了主干-分支网络结构,能够直接从原始图像中提取关键点信息,进而帮助系统获取对齐后的人脸;属性识别方面则使用了较为先进的残差网络,提高了系统的识别准确率(平均识别准确率为90.02%),有良好的应用前景。
