改进主题模型的短文本评论情感分析①
2019-03-11花树雯张云华
花树雯,张云华
(浙江理工大学 信息学院,杭州 245000)
引言
2016年,Li等人根据评论语料中的时间、发布人等信息,为短文本分配不同的权重,将分配权重后的短文本合并为伪长文本,将LDA模型中的单词w替换成权重微博链组成的三元组形式
综合目前的研究,现有的短文本主题分类有以下两点不足:
(1)传统通过利用外部语料扩充词义或者合并短文本的方法提高语料的语义信息,但是主题模型对训练语料中的词义信息提取不充分.
(2)主题模型中词嵌入空间的词向量的能力有限,词嵌入模型运行在吉布斯采样的内层时,模型的运行效率十分缓慢.
上述存在的问题,则是本文开展研究的出发点.
1 相关工作
1.1 LDA主题模型
LDA主题模型是Blei等人在03年提出的,模型为文档集中的每个文档以概率分布的形式分配多个主题,每个单词都由一个主题生成[4],LDA的模型如图1所示.
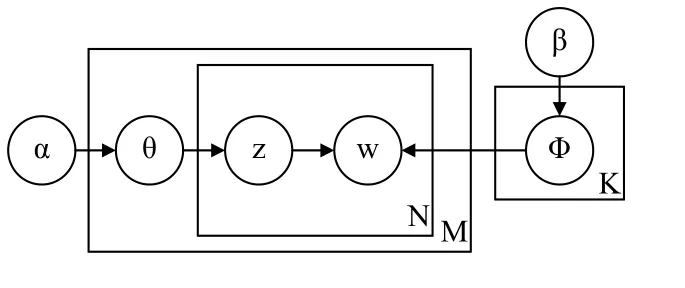
图1 LDA 模型结构图
图1中,α和β表示先验参数,θ表示从先验参数α中提取的主题分布,z表示从θ主题分布中提取的主题,Φ表示从先验参数β中提取的主题z对应的词语分布,w为最后生成的词[5].
LDA模型中,词w采样是根据主题z和模型的先验参数β,主题z是从先验参数α中提取,所以他们的联合概率分布如式(1)所示.
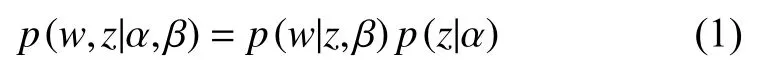
在模型中先验参数β服从关于参数Φ独立的多项分布,使用参数Φ将式(1)更新如下:
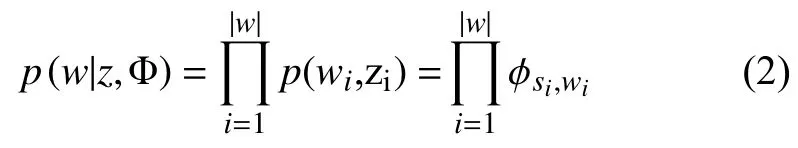
因为词服从于主题即参数为w的多项分布,所以将上式展开化解如下:

1.2 词嵌入模型和LDA模型的对比
词嵌入模型认为可以将语料中的每个单词分配给高维向量空间的实际向量,通常这个向量空间可以包含50到600个维度.提出了Word2Vec模型,在训练过程中,滑动窗口将覆盖文本和神经网络中的每一个单词的权重以学习预测周围的单词,通过PCA降维,投射出词嵌入模型和LDA模型的两个维度的单词嵌入空间,通过可视化方法使得词的距离更容易理解.两点之间的距离越短,表示词义越相近,PCA的降维结果如图2所示.

图2 词向量 PCA 图
选取LDA模型中前10个单词,在图2中用实心点表示,空心点表示词向量模型训练出的词向量,由图可以得出,实心点在距离上更近,而空心点之间的距离比实心点较远,说明词向量训练出的词在词义上更近.Batmanghelich等人在NSTM模型中提出词义的相似性可以通过词向量(x1,x2,x3,…,xn)的余弦距离cos来衡量,余弦的计算如式(4)所示.
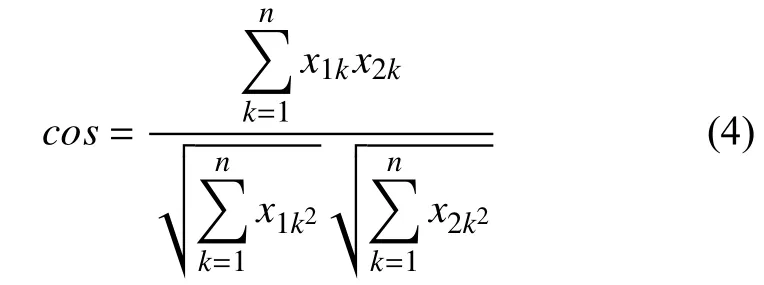
Batmanghelich等人的实验证明这种衡量方式,比通过嵌入模型中的欧几里得距离衡量要准确[6].
2 WELDA 模型的建立
2.1 替换词向量模型构建
词语的关系有相似性和相关性,语义的相似性关系例如词语‘医生’和‘大夫’,相关性例如词语‘医生’和‘护士’.基于词嵌入的模型关注于语义的相似性,而基于文档的主题模型则擅长捕捉语义的相关性.考虑到实验的数据量并不十分巨大,因此使用的Skip-Gram模型进行模型的构建.
(1)语料库通过Skip-Gram模型进行词向量训练,Skip-Gram模型能很好的表示相似的词汇,使用余弦距离的值计算表示词义的相似性.
表1表示实验中在Skip-Gram模型下输入语料库后抓取的‘复查’词义相近的词汇.
(2)模型中,替换单词w的具体做法是,从Skip-Gram模型空间中抽取一个与w`相近的词向量w*,w*是词嵌入空间中产生的余弦距离上最近的单词,最后,替换单词w`.例如,对上文中的‘复查’来说,替换词新词是‘复诊’.
(3)借鉴LFTM模型的方法,替换词向量模型时引入了伯努利参数s~ber(λ),词的采样可以以一定概率从从词嵌入空间v或者从主题分布的词语分布Φ中进行采样[7].

表1 ‘复查’的相近词向量余弦距离示例
2.2 WLDA模型构建
在WLDA模型中,首先将预处理文本输入到替换词向量模型层v,得到训练好的词嵌入空间.其次,在模型中加入替换词向量模型层,最后,将词w`输入替换词向量模型层,模型的结构图如图3所示.
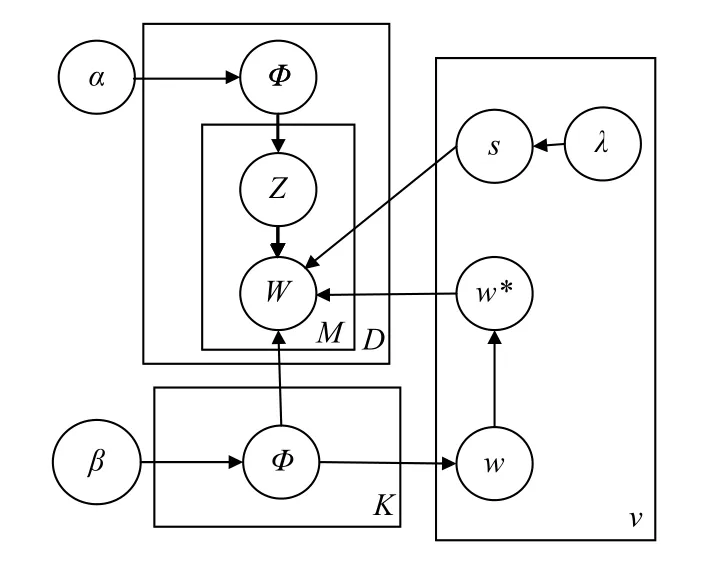
图3 WLDA 模型结构图
WLDA模型生成过程如下:
(1)选择文档集合中的主题k=1,…,k;
(2)选择单词分布Φk~Dir(β);
(3)对每篇文档d=1,…,M:
1)生成文档主题分布θd~Dir(α);
2)对文档中的每个词i=1,…,Nd;
① 生成词的主题zdi~Mult(θd);
其次,这支40mm F1.4 DG HSM |Art镜头是适马第一支为了达到电影镜头所追求的视角和性能标准而开发的Art系列镜头。这支镜头使用三枚FLD萤级低色散镜片和三枚SLD特殊低色散镜片,最大限度地校正了轴向色差和倍率色差。大光圈下即可在焦平面上呈现清晰的成像效果,与柔和的焦外虚化部分相比,可以更好地突出主体。畸变被控制在1%或以下,彗形像差也得到了良好的校正。
② 选择w~Mult(Φzdi),Ψd,i~Ber (λ),如果Ψd,i=1,替换新单词w*.
替换词w为在上述替换词向量模型中抓取相似的单词w*,用表示wi被分配给话题j的次数,根据步骤 a 中得到的公式,以及贝叶斯法则和 Diri 先验,将公式推导如下.
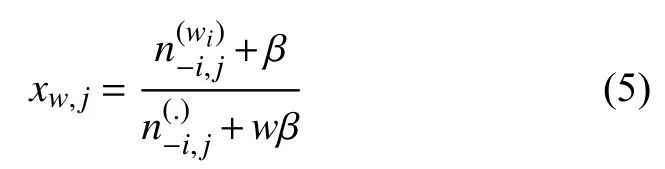
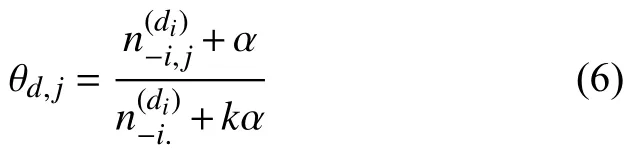
更新吉布斯采样器如式(7)所示.

其中,基于伯努利分布,从替换词向量模型层v中采样词w*,交换当前单词w`的新主题的分布,由于词向量训练并不运行在吉布斯采样的内层,而是在词向量模型训练好之后,主题模型在词采样阶段从词嵌入空间中以一定概率提取词义相近的词进行替换.
由此在理论上来说,词的替换使该模型的主题的困惑度下降,而在外部训练好词嵌入空间,使WLDA模型的运行效率更高.
3 实验与分析
3.1 实验环境及数据预处理
实验硬件环境为酷睿i7处理器,运行内存为16 GB,操作系统为 Win10,实验的软件是 Eclipse,采用的语言是Python.
实验数据处理分为以下两步:
(a)在挂号网上爬取出评论数据,去除标点符号.
(b)使用结巴分词,进行停用词处理和将语料库进行分词.
分词得到的txt局部文本如图4所示.
3.2 实验内容及结果分析
实验分为2个部分.
(a)配置λ参数,找出合适的重采样概率λ.
(b)基于WLDA的进行情感词抽取并和其他模型进行实验对比.
实验中我们采用Perplexity(困惑度)值作为评判标准,式(8)为Perplexity的计算公式[7].
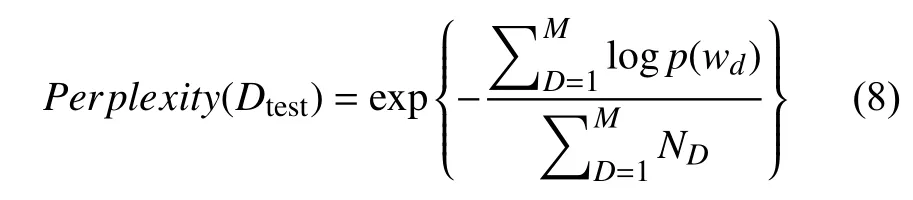
其中,M代表测试预料集的文本数量,Nd代表第d篇文本的大小(即单词的个数),p(wd)代表的是文本的概率[8].如果重采样的参数等于1,则实验中使用的为标准的LDA,当重采样次数等于0时,文档中所有的词全部是从词嵌入的空间中抽取.Perplexity对比的数据如图5所示.

图4 分词得到的 txt文本局部图
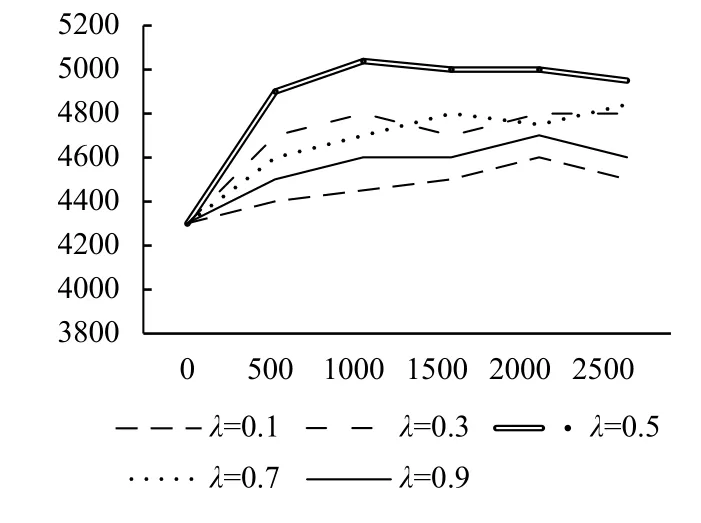
图5 Perplexity 值对比
图5中的λ为重采样次数,横坐标为模型的迭代次数,纵坐标为困惑度,实验得出当收敛次数需要小于1000次,重新采样次数为0.5时,模型的困惑度较小.
DMM模型通过假设每个短文本只包含一个主题[8],15年,das等人首次提出了高斯LDA模型,使用词向量代替离散的值[9],这两个模型都在一定程度上,解决了短文本的上下文依赖性差的问题.实验选择DMM模型,高斯LDA模型和重采样概率为0.5的WLDA模型进行对比.
针对测试的评论数据,使用PMI来量化这三个主题模型中的主题质量.PMI(主题一致性标准)常常被用来量化主题模型中的主题的质量,PMI的定义如式(9)所示[9].
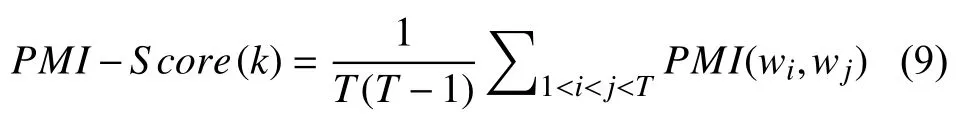
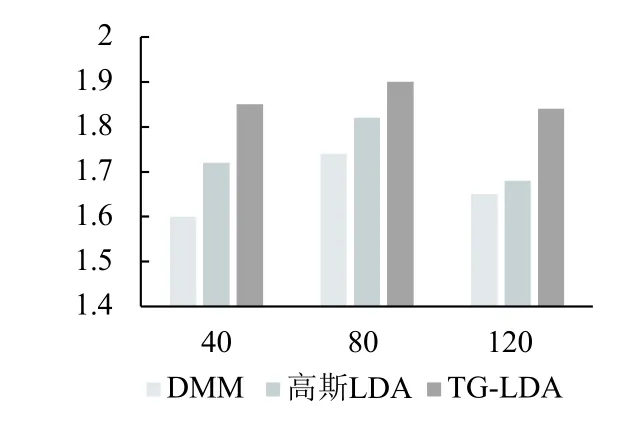
图6 模型的 PMI对比
实验结果表明,WLDA模型的表现要优于高斯LDA模型模型,困惑度最小,这一点得益于WLDA在吉布斯采样阶段,选择词嵌入空间的词向量w*,对单词w`选择性替换,而替换的词向量提高了模型训练中词向量的相似性,补充了上下文的语义,当模型中的主题数为120时,模型的PMI值变低,是由于替换的词向量的质量不高,对短文本的主题学习造成了影响.
运行时间如表2所示.

表2 运行时间表(单位:min)
DMM模型的运行时间最短,但是由于DMM模型假设每个短文本只包含一个主题,这个假设十分不严谨,因此,DMM的PMI值远远小于WLDA模型.
4 结束语
本文提出了一种基于主题模型的短文本评论情感分析模型,通过在某医院的评论数据上实验,证明了该模型对主题词的分类更加的突出,并且有较高的主题一致性.
在下一步工作中,将进一步研究降低模型的时间复杂度,提高模型的运行效率.
