基于Spark的模糊C均值算法改进
2019-03-08夏邢,薛涛,李婷
夏 邢,薛 涛,李 婷
(西安工程大学 计算机科学学院,陕西 西安 710048)
0 引 言
模糊C均值聚类[1]算法是基于目标函数的代表性模糊聚类算法,它与k-means[2]等算法属于常用聚类算法[3]之一。核心思想是算法进行柔性划分后,使同类簇下的对象之间相似度最大,不同类簇的对象之间相似度最小。由于FCM具有有效处理模糊信息的能力,从而在大规模数据分析、数据挖掘等众多领域被广泛使用。
但FCM算法存在聚类效果不佳、聚类时间长等问题,目前国内外研究者针对其不足提出了多种改进方法。YU等[4]使用MapReduce编程框架来解决FCM聚类算法花费时间较长的问题;DAI等[5]针对模糊均值聚类算法的聚类质量和聚类速度依赖于初始聚类中心,提出了一种基于MapReduce编程框架的混合Canopy-FCM算法;王桂兰等[6]针对FCM算法会衍生大量矩阵运算的问题,使用了基于Spark的机器学习库MLib分布式矩阵运算。
以上改进方法相比较传统的FCM都有一定的改进效果,但MapReduce[7]任务在进行中间结果磁盘读写和资源申请过程不仅耗时长而且浪费网络资源,本文给出一种基于Spark的Canopy-FCMBM并行算法,从目标函数度量方式和算法并行化处理两个方面提高算法执行效率和聚类准确率。Spark是一款基于内存的分布式计算框架,不同于MapReduce将Job中间输出结果保存在HDFS中,Spark将结果直接保存在内存中,从而不再需要读写HDFS,产生大量的磁盘I/O,可有效缩短执行时间。首先利用Canopy算法进行粗糙聚类[8-9],将其作为FCM算法的初始聚类中心,加快聚类收敛速度;并将传统FCM目标函数的距离度量方式由欧氏距离替换成马氏距离[10],提高聚类结果的准确性;最后利用Spark框架实现算法的并行化[11],减少聚类花费时间。
1 Canopy-FCMBM聚类算法设计
传统的FCM算法在对维度大且分布不均匀的数据聚类过程中,表现出无法考虑维度特征之间的差异,从而导致聚类精度低等问题,本文将其原始目标函数的度量方式更改为考虑维度权重的马氏距离,通过不断地迭代聚类中心矩阵,判断两次迭代的改变量是否小于设定的阈值来进行模糊聚类。并将Canopy粗糙聚类算法的结果作为FCM初始化的聚类中心矩阵,减小聚类随机中心导致的聚类结果不可控等问题,可有效提高聚类时间和精度。
1.1 FCM聚类算法
模糊C均值算法是一种重叠聚类算法,它的思想是通过优化目标函数得到每个样本点对所有聚类中心的隶属度,从而决定样本点的归属完成自动聚类。FCM算法是对于普通C均值算法的改进[12],普通C均值算法对数据属于硬性划分,而FCM是一种柔性的模糊划分。
FCM算法可以借助模糊参数[13]m来描述聚类过程和结果,一般情况下当m=1时,它就是普通的C均值聚类算法。m取值越高,算法的模糊程度也会越高[14],在实际应用中,m通常取值为2。FCM算法相比较其他聚类算法的优势在于精度高且柔性聚类,不类似硬性聚类非0即1的结果。但FCM也存在一定缺点,例如对初始化敏感、计算复杂等,因此本文提出了Canopy-FCMBM的改进方法。
1.2 Canopy算法
Canopy算法[15]是一种无监督的学习算法,属于快速聚类算法,但是其聚类效果却不理想。目前,比较普遍的聚类算法模式是将Canopy算法与其他聚类算法结合应用。它通常被用作聚类预处理方法以加快其他主要聚类算法的进程,有利于处理大规模数据集。Canopy算法的基本步骤[16]如下:
(1) 首先将数据集向量化得到一个listS放入内存,通过交叉检验的方式来选取2个阈值T1,T2,并保证T1>T2,一般情况下T1的取值是T2的2倍左右;
(2) 随机选取中一个对象P作为Canopy中心,并将P从S中删除;
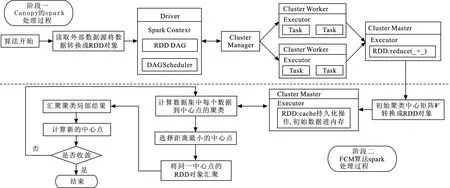
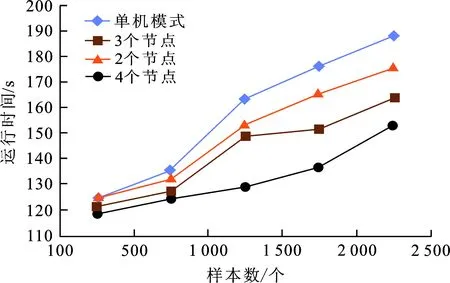
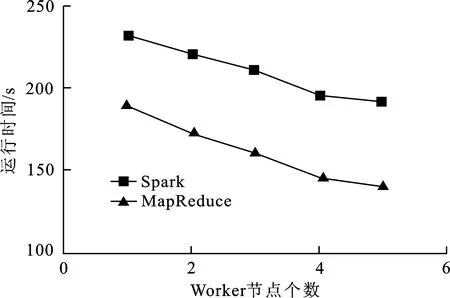
(3) 计算数据集S中每个对象到所Canopy中心的距离d,若d (4) 若d (5) 判断S是否为空,若为空则算法终止,输出Canopy中心数目和每个Canopy中心,否则转到步骤2,直至数据集合S为空。 Canopy-FCMBM算法的主要思想是首先使用Canopy算法完成粗糙聚类,产生初始聚类中心[17],并将其作为FCM聚类算法的初始聚类中心矩阵,并将FCM的目标函数距离度量方式替换为马哈拉诺比斯距离[18],然后对目标函数进行迭代计算得到最终的隶属度矩阵U,最后通过Spark计算引擎实现算法的并行化。 由于在进行数据挖掘时,大部分数据都存在多维度且分布不均匀的特点,传统FCM算法的距离度量采用的是欧式距离,它不考虑样本属性之间的权重比例,从而导致聚类结果不精确。为了消除不同特征量纲的影响,提高聚类准确度,本文将FCM算法原始目标函数的距离度量方式由欧式距离替换为马氏距离,它不受量纲的影响,即计算两点之间的马氏距离不必考虑原始数据的测量单位,这样可以避免变量之间相关性的干扰,对改进的算法简称为FCMBM(Fuzzy C-Means based on Mahalanobis)算法。但需注意的是,在计算Mahalanobis距离时,必须保证样本数量大于样本的维数,否则得到目标函数协方差矩阵的逆矩阵会出现不存在的情况,从而无法计算出样本间距离,导致聚类失败。 根据列出的拉格朗日函数,对各个矩阵参数求极值,即可得到目标函数的拉格朗日最优解。 Spark是一种基于内存计算的大数据并行计算框架[19],与MapReduce编程框架不同,Spark能够将Job的中间结果保存在内存中,减少对HDFS的读写,从而减少磁盘I/O以及节约网络传输时间,这使得交互式计算和复杂算法的效率得到大幅度提升。Spark的核心概念是弹性数据集(RDD),指的是一个只读、可分区的分布式数据集,能够以基本一致的操作方式去应对不同的大数据应用场景。RDD本质上是一个基于内存的不可变的数据结构,将用户上传数据进行封装,Spark通过不同的转换操作输出结果,由于大数据迭代算法中经常会多次使用同一数据集,所以Spark提供对RDD的持久化,避免多次调用行动操作对同一RDD计算而带来的开销。 使用单机方式运行FCM算法执行效率较低,而利用MapReduce实现FCM算法的并行化耗费网络资源及磁盘I/O较大,因此本文采用Spark对算法进行并行化处理。Canopy-FCMBM算法的并行化主要包含2个阶段,其流程如图1所示。 阶段一为Canopy算法在Spark计算框架的处理过程: (1) 算法开始,从HDFS或者HBase上读取原始数集S,将其转换成RDD对象对数据进行持久化操作,并通过调用word2vec接口将数据集格式化为向量形式; (2) Master节点将任务分配给各worker节点,在各节点上分别执行flatmap、reduce等操作,计算本数据点与Canopy中心点之间的距离; (3) 计算数据集S中每个对象到所有Canopy中心的距离d,根据预定规则,给这个数据贴上弱标记,将这个对象加入到当前的Canopy中,得到局部Canopy中心点; (4) 将各个Worker节点通过RDD计算出的局部Canopy中心点,执行reduce操作,汇总得出全局的Canopy中心点。 图 1 Canopy-FCMBM算法流程图Fig.1 The process of Canopy-FCMBM algorithm 阶段二为FCMBM算法在Spark计算框架的处理过程: (1) 将阶段一产生的聚类中心设置为FCMBM算法的输入即初始聚类中心矩阵; (2) 各Worker节点执行map操作,分别计算数据集中每个数据到中心点的距离,即数据对象xn与第i个聚类簇的聚类中心vi的隶属度值; (3) 各节点在经过cache持久化操作,以预备这个矩阵之后的RDD操作时可减少计算,再对RDD进行reduce操作执行FCMBM局部聚类; (4) 判断本次聚类中心点与上次的聚类中心点的改变是否小于某个阈值,如果小于则算法停止,否则把本次的中心当做初始聚类中心,继续进行矩阵迭代运算; (5) 主控节点执行reduce 操作将各个计算节点产生的局部聚类结果归并为全局聚类结果 Canopy 中的聚类中心经过cache持久化操作后,其数据对象放置于内存中,所以下一阶段FCMBM算法在聚类时可多次重复使用,并且FCMBM算法在迭代计算时,如果结果不收敛,可将本次的聚类中心执行cache操作,至此不需每次都对矩阵进行一系列RDDs的算子操作,并且不需要每次都在 HDFS 分布式文件系统上读取,从而可以有效提高算法执行的效率。 FCM算法在聚类过程中,会出现大量的包括隶属度矩阵、距离矩阵、更新聚类中心矩阵等矩阵迭代计算。若使用MapReduce计算框架,每迭代一次矩阵运算都要启动一次完整的MapReduce执行操作,并且在运算过程中会将中间结果写入硬盘,而频繁的读写硬盘会大大增加运算时间,这样不仅编写map阶段和reduce阶段代码不灵活而且执行效率不高。Spark使用内存运算技术,提供了丰富的RDDs算子转换操作,代码编写灵活高可用,使用的map、flatMap、reduce等操作可以轻松解决FCM算法中矩阵的转置、求笛卡尔积等数学计算,此外cache将中间数据对象写入内存,可有效避免矩阵重复计算,所以基于Spark的算法运算速度相比于Hadoop MapReduce计算框架有所提升。 实验平台是在Hadoop2.6.5的基础上部署Spark框架,在VMware中创建4台虚拟机,其中1台为master节点,3台为slave节点。操作系统均为CentOS-6.3-x86-64版本,Java环境为jdk1.8-103,Spark版本为Spark2.1.1,Scala版本为2.12.6,Sqoop版本为sqoop-1.4.6.bin--hadoop-2.0.4-alpha,mahout版本为apache-mahout-distribution-0.10.1。 本次实验数据集选用来自UCI机器学习库的Iris,Balance Scale和Car Evalution 3个标准数据集作为测试数据,实验测试数据集描述如表1所示。 表 1 实验数据集 为方便实验结果比较,将数据集分为两大类,其中Iris和Balance Scale属于小数据集,其属性维度相对较少,Car Evaluation为大数据集。但所选数据集均满足样本数量大于属性数量的要求,假设所选数据集模糊指数m=2。 为了验证Canopy-FCMBM算法的有效性,本文基于Spark平台,采用Spark On Yarn运行模式,使用实验平台中的4个worker节点去对UCI 3个不同大小和维度的数据集进行FCM算法、Canopy-FCM算法与Canopy-FCMBM算法分析比较,上述3个聚类算法结果如图2所示。 图 2 算法聚类准确度对比Fig.2 Comparison of algorithm clustering accuracy 从图2知,针对数据量少且数据维度少Iris数据集,改进后的Canopy-FCMBM的性能低于传统的FCM,但是随着数据量和属性维度的增长,Canopy-FCMBM算法的性能明显高于后两者。聚类准确率平均提升了12.7%。实验结果表明,改进后的算法具有更好的聚类效果。 利用Canopy-FCMBM算法,针对上述数据集,分别在单机模式下和Spark计算框架下多个Worker节点进行试验,计算聚类算法运行时间,实验结果如图3所示。 图 3 单机模式与并行模式算法运行时间对比 从图3可知,当数据量不大时,聚类算法的运行时间较为接近。当处理大规模数据集时,分布式的多节点明显优越于单机处理。这是因为,随着节点增多,分布式处理进程也会增多,Spark的Master节点会让Worker快速启动Driver,SparkContext初始化之后Master节点会给各个Slave节点分配具体Task让其执行,同时,因task执行时读写数据都在内存中,也会加快算法执行速度。 为进一步验证Canopy-FCMBM算法的性能优势以及在Spark计算框架下的运行优势,实验针对同一数据样本Car Evaluation数据集,将集群节点扩展到5个,测试在Spark计算框架下与MapReduce计算框架下因Worker节点不同,聚类算法的运行时间对比,算法运行时间结果如图4所示。 图 4 Spark与MapReduce框架下聚类收敛时间比 由图4可以看出,Spark的执行效率要高于MapReduce。当执行节点数达到5个的时候,Spark的执行效率大约为MapReduce的1.35倍,这是由于Spark使用RDD进行迭代计算的特点,将每次计算后的中间结果都保存在内存中,减少对磁盘的I/O操作,可提高聚类速度。 随着大数据逐渐日常化,传统模糊C均值聚类算法在分析海量数据时存在聚类中心随机取值,导致聚类结果不准确等问题.本文将传统FCM与Canopy算法结合,并将FCM目标函数距离度量方式由欧式距离替换成马氏距离,形成Canopy-FCMBM算法,这样可以有效解决对于多维度且分布不均匀大数据聚类结果不准确的问题。将Spark基于内存处理的计算框架应用于Canopy-FCMBM算法,大大提高了传统FCM算法的计算性能以及大数据适应能力。实验结果表明,改进后的算法有较快的聚类速度和较高的聚类准确率。但在研究中发现,面对数据量较小的数据集时,基于Spark编程模型的Canopy-FCMBM算法优越性难以体现,其聚类的准确率也相对低于传统算法。此类问题,将作为下一步工作的研究内容。1.3 改进后的Canopy-FCMBM算法

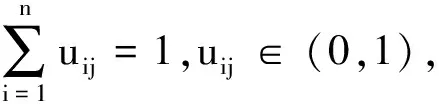
2 基于Spark的Canopy-FCMBM算法
2.1 Spark编程模型
2.2 Canopy-FCMBM算法并行化
3 结果与分析
3.1 实验环境和实验数据

3.2 结果分析

4 结 语
