动态背景下航道船舶目标检测方法
2019-03-08陈从平
陈从平 吴 喆 吴 杞 吕 添
(1.三峡大学 机械与动力学院,湖北 宜昌 443002;2.常州大学 机械工程学院,江苏 常州 213164)
水上运输是我国主要运输方式之一,但当特定航道上架有跨越式高压电缆、桥梁正在施工时,需对航道内过往船只进行高度限制,或要求按其规定路线行驶,或进行回避.因而需要提前对船只进行判断、监测,以便进行决策和指挥,及早预防事故发生.现有对航道船只进行监控的主要方法是,通过在航道合适位置架设长焦网络摄像机,实时将航道上的视频传输到监控室,再由人工进行甄别并发出警报或指令.由于船只出现在航道具有不定时、不可预见的特点,依靠人工值守查看视频工作量大,易疲劳和误判,需要开发自动化船只识别方法,待识别出有船只靠近时,提醒人工处置.
与一般视频监控场景不同的是,为使航道上的船只能被尽早发现,监控时采用了视距更远的长焦摄像机,但同时会减小摄像机的视场范围.为使摄像的可视范围覆盖整个航道,需使摄像机周期性往复转动、扫描,即所拍摄背景为动态背景,则若要自动判别航道船只,需要在动态背景下进行检测.
传统的动态背景下目标检测方法主要有两种:(1)根据全局运动参量估计进行背景匹配[1],从而将动态背景转换成静态背景进行处理,再通过帧差法或者背景差分法提取运动目标,最后对提取的运动目标进行分类[2].全局运动参量估计需要利用特征匹配的方法计算模型参数,但对于航道中的船舶检测,当图像背景全为水域时,其颜色及纹理较为单一,特征匹配存在困难,加上远距离视频中船舶移动的速度相对于视频帧率而言过于缓慢,通过帧差法或者背景差分法都很难提取出船舶目标.(2)多尺度滑动窗口法[3],其核心是对视频序列的每一帧构建图像金字塔,利用固定尺寸的滑动窗口以等步距在整幅图像上滑动,并对每一个窗口利用之前训练好的分类器判断窗口内是否存在检测目标[3].该算法不受摄像机以及目标运动的影响,并且通过增加图像金字塔的层数能够增加定位精度.该算法的主要缺点是运算量过于庞大非常耗时,并且由于使用固定尺寸的滑动窗口,仅适用于目标长宽比变化不大的场景.但在航道船舶检测过程中,由于摄像机不停转动,导致同一条船的拍摄角度及成像区域的大小也在不断变化,故该算法也不适用.
近年来,人工智能快速发展并被广泛应用于各种目标识别和检测领域.本文针对以上问题,利用基于深度学习的方法对动态背景下的航道船只进行自动检测.目前,在目标识别与检测领域公认的性能较为优越的模型有Faster R-CNN[4](Faster Regions with CNN features)模型、SSD[5](Single Shot MultiBox Detector)模型和R-FCN[6](Region-based Fully Convolutional Network)模型等,这些模型不仅能够实现端对端的训练,还能够同时实现目标的定位以及目标的识别,避免了传统方法中需要先进行目标检测,再单独训练分类器的繁琐操作,相比传统方法在定位精度、识别准确率以及检测效率上都表现出了更为优良的性能.但Faster R-CNN 相 比SSD 和R-FCN 在 检测准确率上更具优势[7].本文主要采用Faster R-CNN 对航道船只进行识别,在此基础上,提出了一种针对深度学习网络输出的后处理算法,使得在尽量小的样本集的训练下也能达到足够高的检测精度,避免了深度学习网络需要海量样本、长时间训练、前期准备工作量过大的问题.
1 Faster R-CNN 算法原理
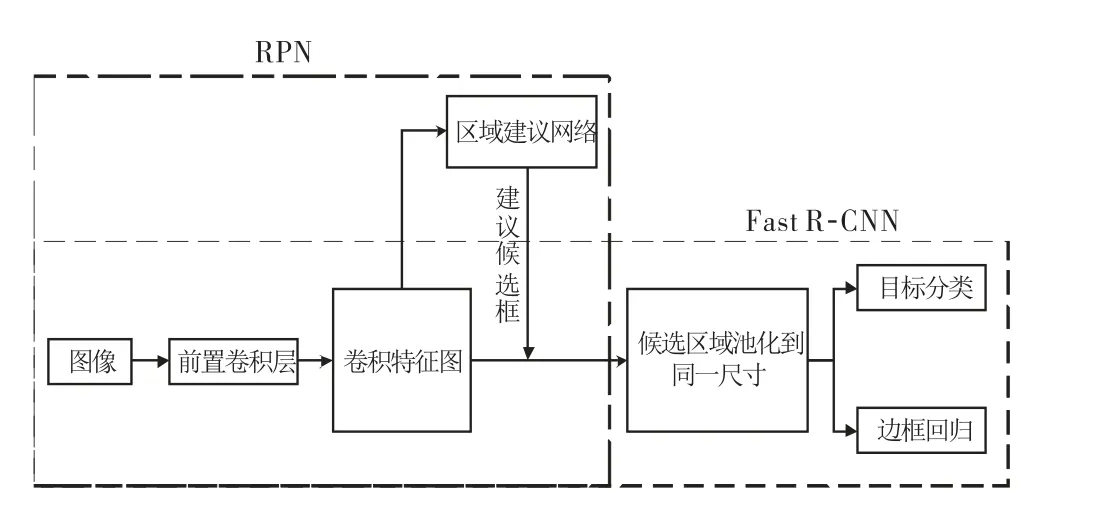
图1 Faster R-CNN 网络结构简图
如图1所示,Faster R-CNN 可以简单地看作是由RPN 网络和Fast R-CNN 网络的结合,首先由RPN 网络进行目标建议框的生成,再将生成的目标建议框提供给Fast R-CNN 网络进行目标的分类与边界框的回归.由于Fast R-CNN 网络的训练依赖于固定的目标建议框,所以训练网络时并不能简单地利用反向联合传播算法进行网络参数的更新.Ross Girshick设计了一种实用的Faster R-CNN 4步训练法,通过交替训练优化来学习共享的特征,具体训练策略如下:
1)利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN 网络参数.
2)固定RPN 网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN 网络生成的目标建议框去训练Fast R-CNN 网络参数.
3)固定利用Fast R-CNN 训练好的前置卷积网络层参数,去微调RPN 网络独有的卷积层以及全连接层参数.
4)同样保持固定前置卷积网络层参数,去微调Fast R-CNN 网络的全连接层参数.最后RPN 网络与Fast R-CNN 网络共享前置卷积网络层参数,构成一个统一网络.
2 样本集的制作与网络训练
2.1 样本制作
为了让收集到的样本更具一般性且能够让深度学习网络学习到更多有效特征,本文所采集的833张训练集样本图像以及86张验证集图像均来自不同的地点、天气、拍摄角度、拍摄尺度、不同的船舶目标以及船舶在视场中不同的截断程度等情景,并将采集到的样本统一缩放到1024×600pixel大小.为了能够更加准确地评估网络模型效果,本文的验证集与训练集并非同批次采集获得.采集的部分样本如图2 所示.

对采集的每张图像进行人工标注,即标注出每张图像中的每个船舶的最小外接矩形框信息(矩形框的宽、高以及中心点像素坐标),并生成标注文件.需要指出的是,本文主要针对的是大型船舶的检测识别,因为小型船舶(例如小型渔船以及航道上的定位浮船等)高度尺寸较小,实际中对航道上的设施或施工不会照成影响.
格雷在《兰纳克》中以熟悉的格拉斯哥为背景,凭空设想出盎散克这个具有普世意义的空间,通过对格拉斯哥和苏格兰社会现实的书写、对苏格兰历史和民族身份的思考和对西方社会政治意识形态的批判,表达出对平等博爱社会的憧憬,使这本小说既呈现现实社会,又超越现实社会。作为一名艺术家,他同时表示,不论小说家如何被政治吸引,都不该成为说教者,因为“如果他们把自己的创作变成了布道文,那么他们就只会写布道文了。必须鼓励读者自己得出不可预知的结论”(Gray 1986a:137)。这可能也是《兰纳克》游走于文学想象与现实关照之间,使其充满多重解读可能的原因之一。
2.2 网络的搭建
在Ubuntu16.04系统下,利用Python编程语言以及Tensorflow 深度学习框架搭建Faster R-CNN模型,并采用GoogLe-Net[10]网络结构作为其前置卷积神经网络层,而不是常用的ZF-Net[11]网络和VGG-Net[12]网络.根据ImageNet上的分类结果表明GoogLe-Net相比ZF-Net拥有更高的分类准确率,相比VGG-Net在准确率没有明显差异的情况下,拥有更快的推理速度.图3 展示了GoogLe-Net模型简图,图中并没有详细标出每个卷积核的大小以及个数.如图所示,在GoogLe-Net中并不是简单地通过将卷积层和池化层进行堆叠来提升网络性能,而是提出了Inception结构(如图3中虚线框内结构),Inception结构通过采用不同尺寸以及不同数目的卷积核对输入进行卷积,使得拼接后的特征图不仅具备不同大小的感受野,还融合了多种尺度信息,使GoogLe-Net网络相比VGG-Net网络拥有更高的计算效率和更少的模型参数,又比ZF-Net网络拥有更高的准确率.
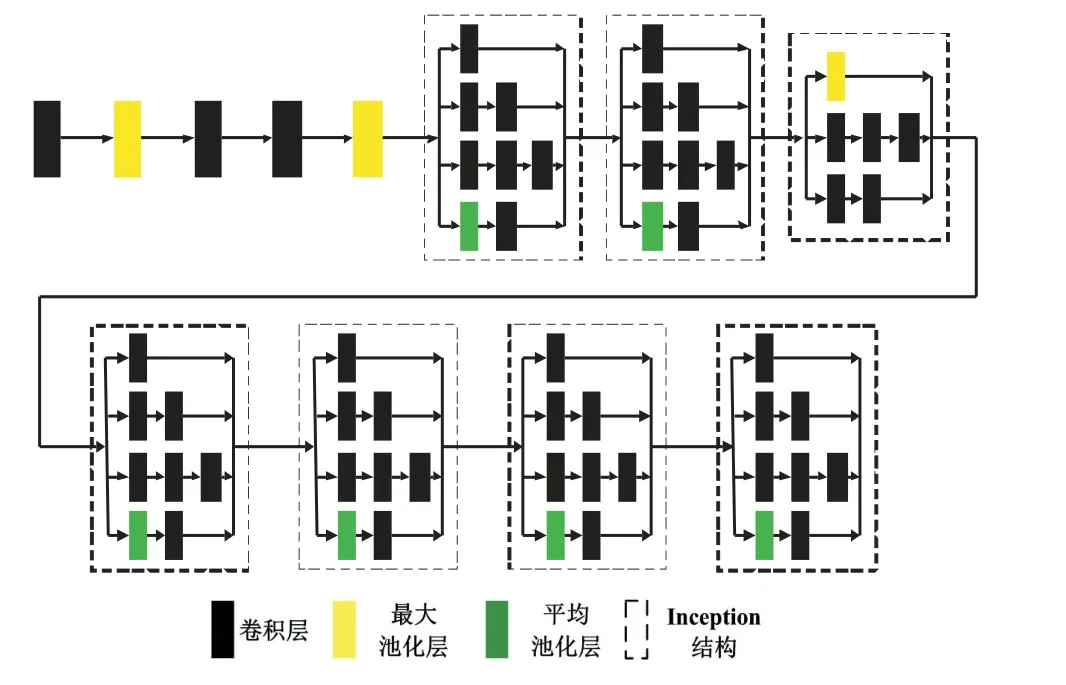
图3 GoogLe-Net网络模型简图
2.3 网络的训练
对于深度学习网络,若训练样本量过少,可能导致网络出现过拟合甚至无法收敛的情况.为降低人工制作船只图像样本的工作量,本文基于迁移学习的思路对网络进行预训练,即:首先利用MS COCO(Microsoft Common Objects in Context)标准图像库(包含船只及其他物种共80种类别,共30万张图像)对Faster R-CNN 网络进行训练,让网络预学习角点、边缘等表征轮廓的基础特征,为航道船舶识别模型做准备,后续再结合采集、标注的图像集进行再训练.在实际训练中,由于实验室GPU 的运算能力有限,本文利用Google预训练好并提供公开下载的模型参数进行网络的初始化.
在初始化网络参数后,将标注好的833张训练集样本图片输入到网络进行再训练,并在训练过程中使用图像随机水平翻转来增大训练样本量.在生成目标建议框阶段设置最大建议框数量为300,在预测类别以及精修边界框阶段设置每类最大建议框数量为100,优化器采用Momentum Optimizer,设置learning rate为0.0002,momentum 为0.9.在训练迭代约35000步后网络达到收敛.
网络收敛后,利用已标注好的86张验证集样本对模型进行验证.图4反映了不同场景、不同角度、目标(船)被不同程度截断及不同光照等典型情况下的部分识别结果,图中每个矩形框是网络检测出的目标,框上方数据为该目标的置信度,可以发现,图4(a)~图4(d)识别结果准确,但图4(e)中检测出了不希望被识别的岸边渔船,图4(f)中将岸上建筑误识别为船只.究其原因可归为两个方面:一是由于样本训练集的数据量不够大;二是因为网络只能对单张图片进行预测,当对连续视频序列进行预测时无法参考图像序列的前一帧以及前几帧的预测信息.

3 后处理算法
为了提高网络检测精度又不至于继续增加学习样本,本文通过对网络输出结果进行后处理,显著改善了检测效果(所使用的视频序列是由一个分辨率为1280×720,采集频率为10fps,采用自动变焦的相机拍摄.相机在一个120°的扇形区域内来回转动,周期为20s).后处理算法流程如图5所示,主要分为3个步骤:
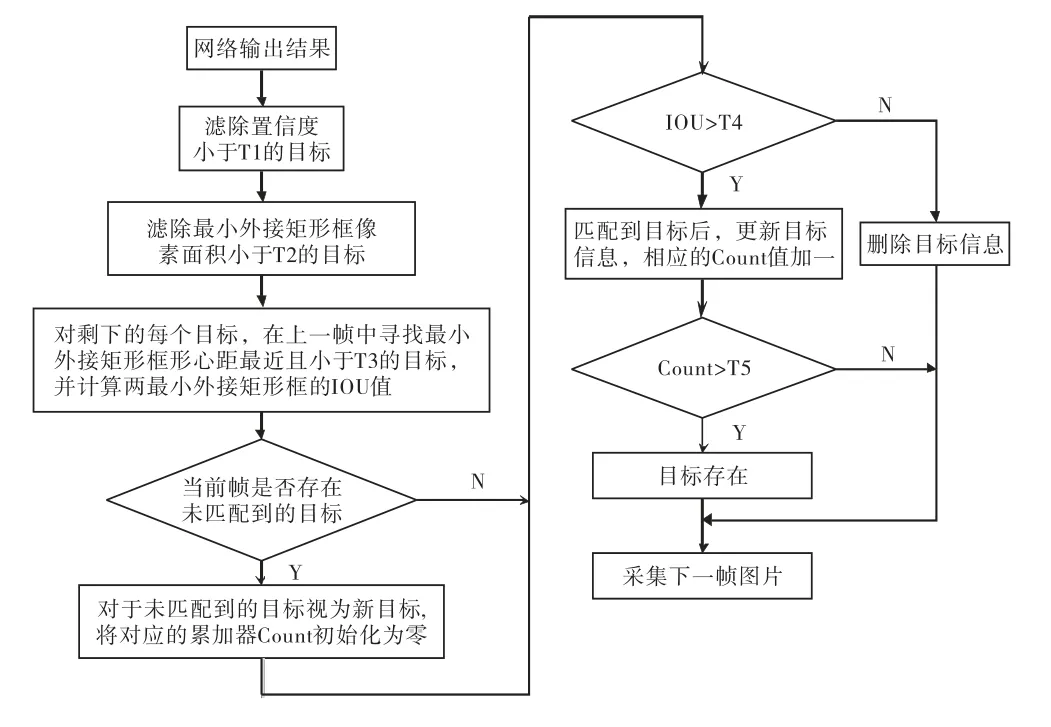
1)设置阈值T1,并滤除网络输出中置信度低于T1的目标;
2)在(1)的基础上,计算每个(剩余)目标的最小外接矩形框像素面积S,并设置阈值T2,并滤除S<T2的目标(即小目标);
3)针对当前帧中剩下的每个目标Pi,在上一帧中逐一寻找与每个目标Pi的最小外接矩形框形心距最近且距离小于设定置T3 的目标若存在满足条件的,计算Pi与最小外接矩形框的IoU(交并比)值,判断IoU 值是否大于设定阈值T4,若大于设定阈值,则认为匹配到同一目标,更新目标信息,并将该目标对应的累加器Count值加1.若Count值大于设定阈值T5,即表明该目标在连续多帧中被持续检测出来,此时认为目标存在,且为期望检出的目标.
经过测试分析,当T1=0.8,T2=3000,T3=100,T4=0.8,T5=30时能够达到较好的效果.对网络输出进行后处理后再次进行测试,对比结果如图6所示,其中第1行为未经过后处理的结果,第2行为与第1行相对应的经过后处理的图像,对比第1列两幅图可以发现,经后处理后未再将岸上建筑及岸边渔船目标检出;第2列图像中,当未进行后处理时,同一艘船被误认成为两个目标,加上后处理后该现象消失;第3列图中,经后处理后,再未将岸边停靠的渔船检出.可见对网络输出进行后处理后,各类检测错误都被有效抑制.更为详细的对比与评价将在第4节中给出.

4 结果与分析
4.1 Faster R-CNN 性能评估
对训练好的FasterR-CNN 网络,本文利用微软针对COCO(Common Objects in Context)数据集提出的目标检测评估方法对网络的性能进行评估.(COCO 评估标准考虑了不同IoU、Area以及Max Detections对平均准确率(Average Precision)和平均召回率(Average Recall)的影响,使得评估标准更加严格,评估结果更为可靠),结果见表1,其中IoU 是实际目标边界框与网络预测输出的目标边界框的交并比,表中0.5∶0.05∶0.95是指取0.5到0.95且步距为0.05 共10 个IoU 值,并分别计算这10 个IoU 值对应的平均准确率的平均值.Area中的small为像素面积S<322的目标,medium 为322<S<962的目标,large为S>962的目标.Max Detections为允许网络生成最大目标建议框个数.
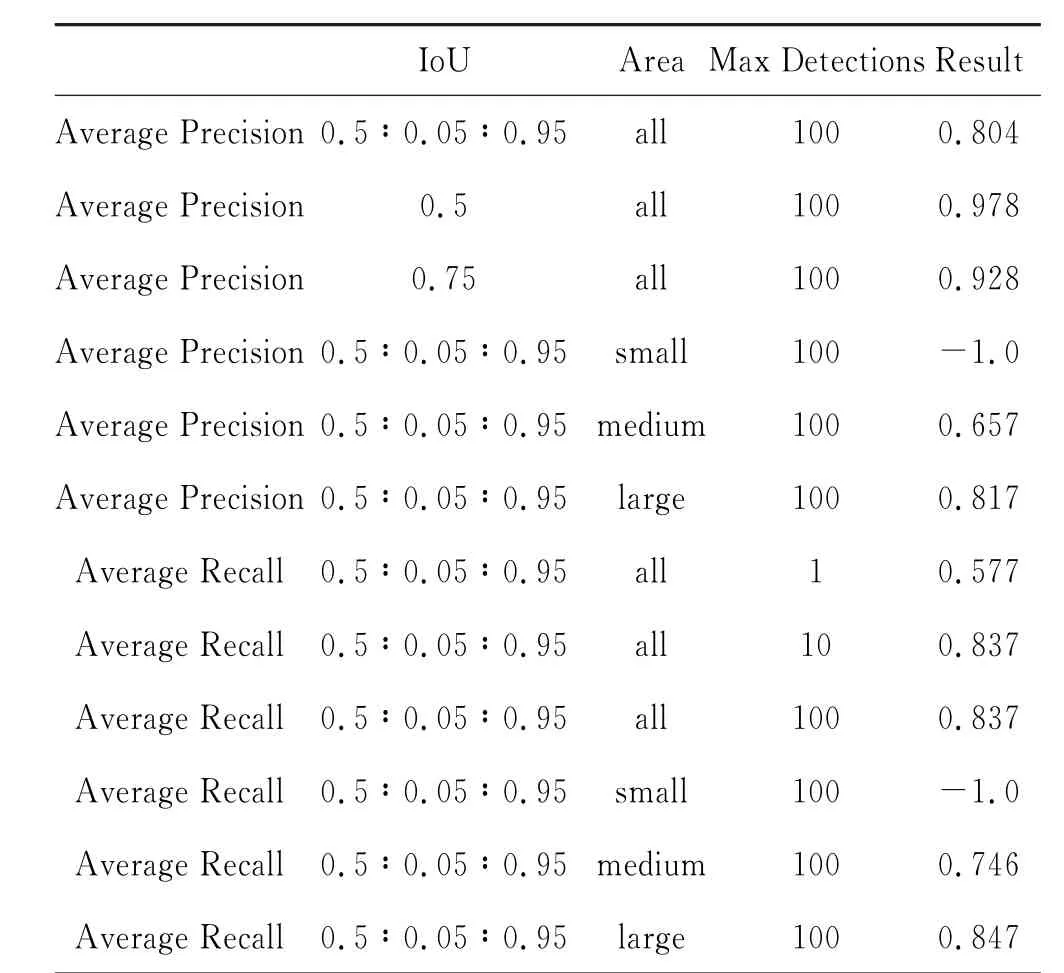
表1 网络性能评估结果
由表1可以看出,即使利用COCO 严格的评估标准,在IoU 分别取0.5:0.05:0.95共10个值时,模型依然拥有很好的性能,平均准确率达到0.804.当降低标准,例如IoU 只取0.5 时,模型准确率可达0.978.由于样本中船舶外界矩形框的像素面积都达到6000个像素,所以无法正确评测该模型对小面积目标的检测性能(例如表中Area为small时,平均准确率与平均召回率都为-1.0).此外,当Max Detections的值从100减到10时对平均召回率并没有太大影响,说明在该模型中即使使用较少的目标建议框数,其检测结果的准确率基本不受影响,并且能够提升检测速度.
4.2 后处理前后对比结果
由于在视频序列中的目标检测评估标准和在单张图像中的目标检测并不完全一样(例如在一段视频序列中,一艘船舶从驶入监控区域到驶出监控区域这段时间内,对于判定监控区域内是否出现船舶,并不需要每帧都检测出船舶,至少检测出一次即可),需要结合视频序列的上下文信息来重新制定新的检测评估标准.为表述方便,首先给出相关规定:
1)在连续视频序列中,若从某帧开始(含该帧)连续n帧检测到同一个真实的目标,当n≥1时视为正确检测到一个目标,当n=0时视为漏检一个目标.
2)若一个误检目标在连续多帧中被检出,视该误检目标仅被检出1次.
3)假设在整个视频序列中真实目标个数为num1,正确检测到的目标个数为num2,漏检测目标个数为num3,误检目标个数为num4.则检测准确率rate1=num2/num1,漏检率为rare2=num3/num1,误检率为rate3=num4/(num4+num2).
利用从航道采集的5段视频(帧率10 fps)对后处理前后的网络检测效果进行评估,结果见表2.其中Vij表示第i段视频有(j=2)/无(j=1)应用后处理算法的结果.由于num3=num1-num2,rate1+rate2=1,故在评估过程中只使用num1、num2、num4、rate1和rate3五个指标.
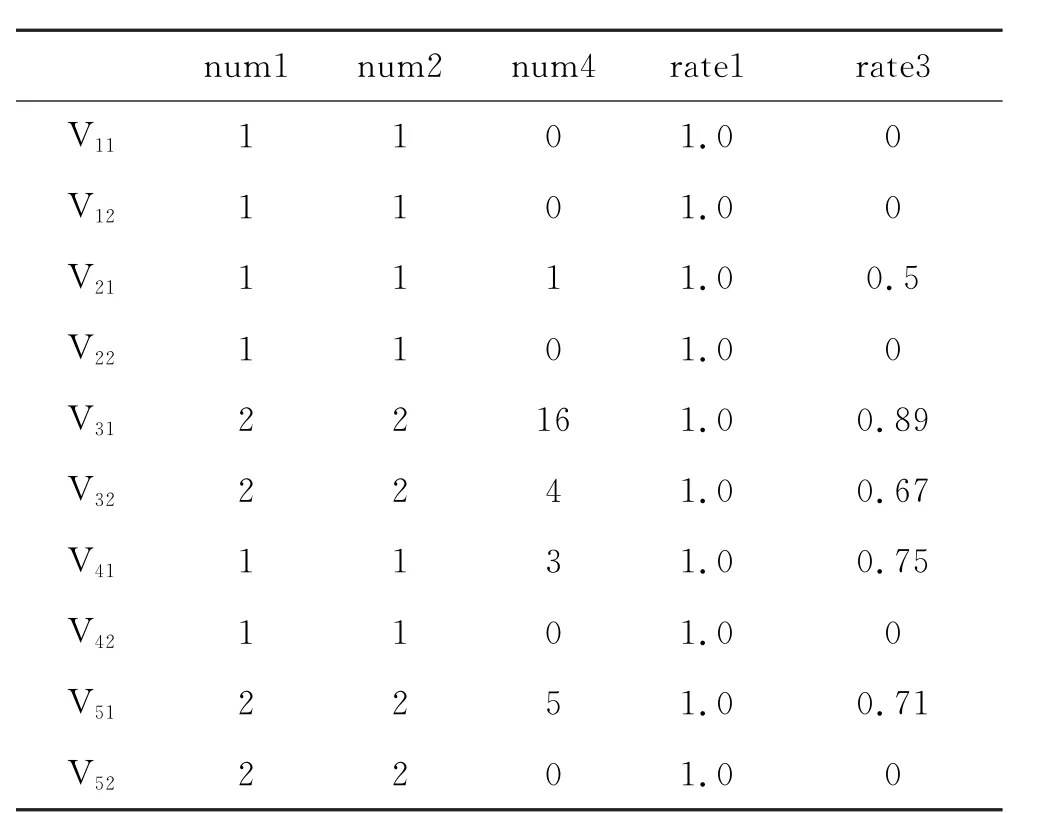
表2 后处理前后网络检测结果对比
由表2可知,在对5段视频序列使用后处理算法后,在检测准确率不变的情况下,误检率平均降低了43.6%.在视频序列2、4、5 中,直接将误检率降至0%.说明本文设计的后处理算法在降低误检率方面有明显的效果.
5 结 语
针对动态背景下的航道船舶检测问题,本文利用Faster R-CNN 深度学习网络进行处理,并利用严格的COCO 评估标准进行评估,平均准确率达到0.804.再根据实际检测情况中可能出现的各种干扰情况,通过分析并设计了一套针对网络预测结果的后处理算法.通过对采集的5段视频序列进行测试,分析得出本文提出的后处理算法能够在检测准确率不变的前提下,大幅降低了误检率.由于本文实验条件有限,网络训练过程中所采用的样本集较小,故在今后可通过扩大训练样本集的方式进一步提升识别准确率.
