基于Python的重庆二手房爬取及分析
2019-03-07刘航
摘要:随着大数据时代的到来,信息出现了爆炸式的增长,计算机技术在大数据时代的重要性日益凸显[1]。本文以python爬虫框架scrapy为出发点,利用计算机技术,对贝壳找房网重庆在售二手房进行抓取,并进行数据分析,得出二手房分布区域最多的地方单价不一定是最高,房屋中介最喜欢的标题是户型方正等结论。
关键词:计算机技术;python爬虫;scrapy;数据分析
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2019)36-0006-02
1背景
随着互联网的高速发展、数据库存储技术的成熟,高性能的存储设备和存储介质日益普及,人们在生活、工作等产生的数据量以指数形式爆炸式增长,大数据发展势不可挡,但如何利用大数据分析为人们的生活提供便利就成了人类的共同话题。同时由于人们的住房压力越来越大,但新房价格一般来说更高,因此有些人会考虑购买二手房。据中国指数研究院公布的数据显示[2],重庆2015年8月的二手房销售价格指数为1416,而到2019年8月的二手房销售价格指数为1747,因此就有必要探讨二手房价格背后的影响因素。
大数据时代的到来,让人们可以在互联网上获得越来越多的信息,其中包括二手房信息。但网络数据来源广泛,且数据量庞大,为了把网贞上的数据下载到本地,且节约时间,网络爬虫技术便应运而生。本文选择贝壳网重庆二手房为数据来源,并利用python爬虫框架scrapy对数据进行爬取,爬取的字段包括发布的二手房标题、位置、楼层、修建年份、面积、朝向、户型、总价、单价等,一共九个字段。最后对获得的数据进行数据清洗、可视化,分析重庆二手房楼层、面积等对房价的影响情况。2重庆贝壳二手房爬虫框架
2.1 Scrapy爬虫框架的介绍
网络爬虫是在网络上爬行的蜘蛛,能够通过网页链接,对网页上的信息进行访问,获取网页的源代码。Scrapy是一种由Twisted编写的、快速的高级网络爬虫框架,可以访问页面,并提取其中的结构化数据,包括的用途有自动化测试、监控、数据挖掘。
Scrapy框架分别由以下七个部分组成:
1) scrapy引擎:负责各个部分之间的数据流动。
2)调度器:接受引擎的请求,并把请求加入队列,并返回给引擎。
3)下载器:下载网页源代码并返回给引擎。
4)爬虫文件:接受网页源代码并进行数据定位和提取。
5)项目管道:负责处理提取后的数据,包括清理、存储等。
6)下载中间件:位于引擎和下载器之间,能對网页请求或响应进行加工处理。
7)爬虫中间件构成:位于引擎和爬虫文件之间,能够处理爬虫文件的输入和输出。
2.2 scrapy爬虫框架的编写
2.2.1创建项目文件
首先,创建整个爬虫项目文件,通过在cmd中输入scrapystartproject beike创建框架,并进入beike目录,cmd中输入scra-py genspider spider ke.com完善爬虫名和爬虫的域名设置。
2.2.2定义需要爬取的字段
由于serapy框架需要实现定义变量,因此需要在items.py[3]定义变量,以及确定变量的个数。
2.2.3爬虫文件的编写
这里是整个scrapy框架的核心,这里涉及对返回的网页源代码进行定位和提取,同时体现了scrapy框架的强大。Scrapy框架支持多种数据定位方式,包括正则表达式,beautifulsoup,xpath,css选择器等,本文使用beautifulsoup进行数据的定位和提取。
2.2.4数据的存储
进行定位和提取之后,由于需要保存到本地进行后续的分析,需要在pipelines.py里进行数据的保存,选择保存的数据格式为Excel文件。
当完成整个框架后,在cmd中输入scrapy crawl spider之后,程序开始运行。
3数据分析
当已经把网页上的数据下载到本地之后,需要对数据中隐藏的规律进行探索,找寻其中拥有实用价值,分析出重庆贝壳二手房数据的价值,为人们选择二手房或为信息发布者提供便利。
3.1数据预处理 在进行数据分析之前,由于可能存在残缺补全的数据,因此需要先进行数据预处理,才能进行接下来的数据分析[4]。首先进行数据清洗,即将多余重复的数据筛选并清除,将有缺失的数据进行处理,将错误的数据进行整理。接着进行数据加工,经过清洗的数据,并不一定能直接进行数据分析,因此需要进行加工。
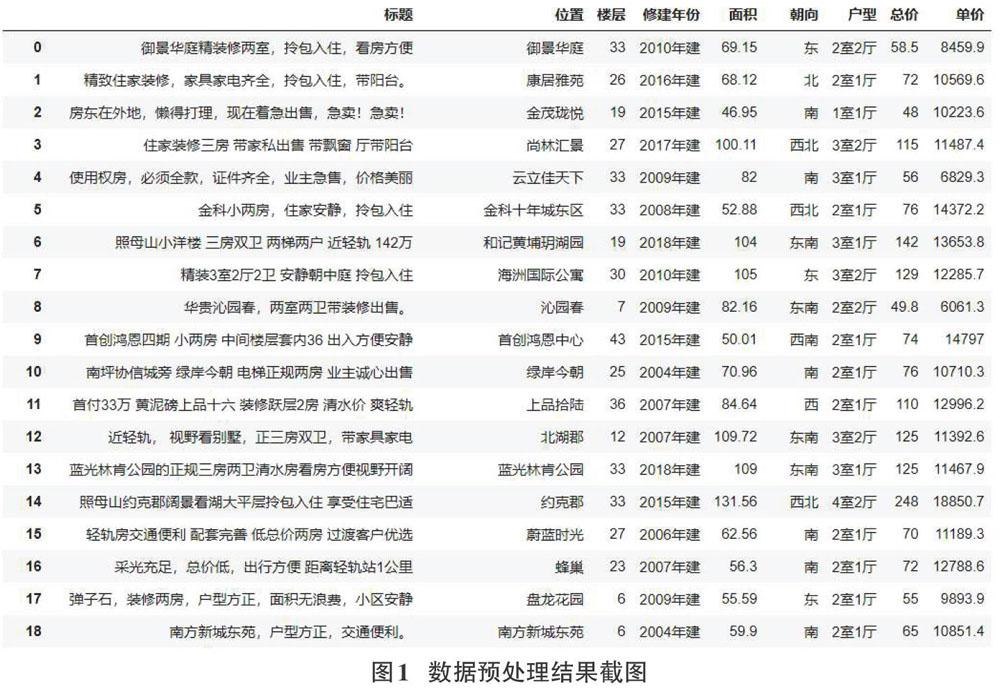
首先用pandas库读取数据[5],使用info方法可以看到数据存在缺失值,为了不影响后续的分析,选择dropna方法删除缺失值,使用pandas库的str属性的split方法对数据进行切割,得到完整的数据。未进行数据清洗之前的数据一共有3000行,经过数据预处理过程后,数据一共有2709行,预处理后的结果如图l所示。
3.2数据可视化
可视化技术作为解释数据最有效的手段之一,能够把分析结果以图形图像的方式呈现,便于人们发现数据中隐藏的规律,有着广泛的应用。
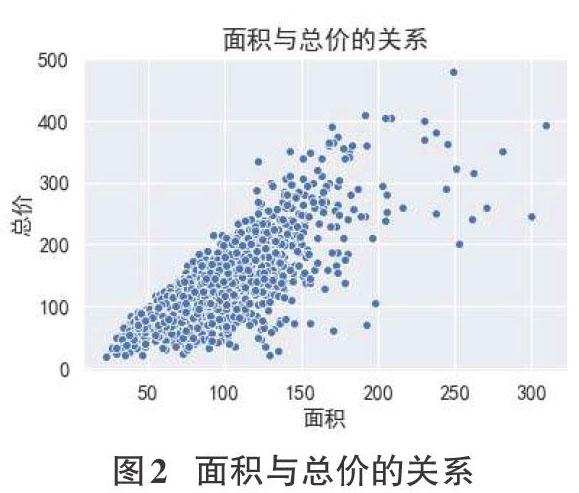
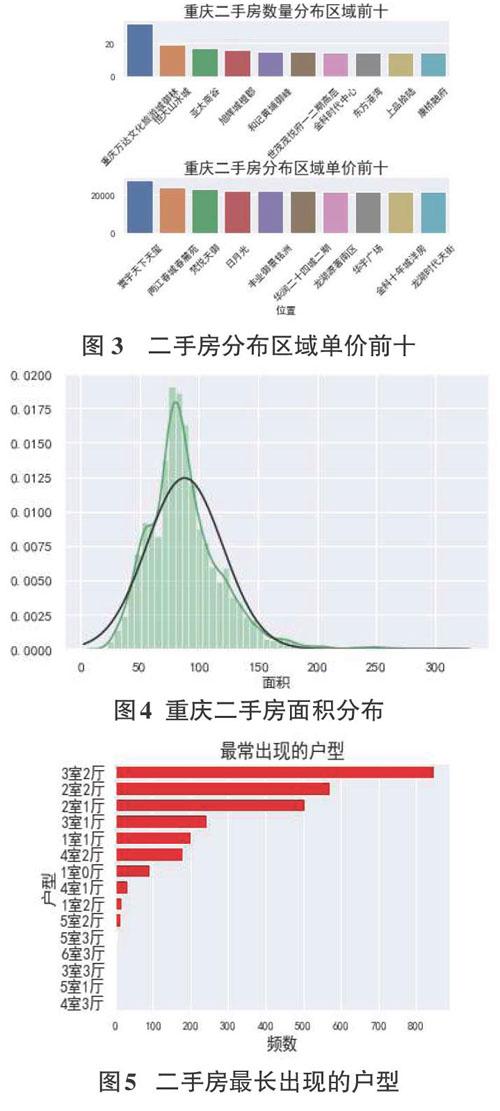
对重庆市二手房总价与面积的关系以散点图的方式进行可视化,以直方图展示二手房在重庆各个区域分布数量最多的十个区域及单价平均值最高的十个区域,可视化结果图2、图3所示。
由图2可以得出面积和房价是正相关关系,随着房屋面积的增加,房间价格也随之上升,符合人们的常识。由图3看出重庆万达文化旅游城御林是二手房出售最多的区域,出售数量远超其他区域,数量达到了32套,但寰宇天下天玺是二手房平均单价最高的地方,平均单价达到了27459元/平方米,所在区域位于重庆江北区重庆金融中心,是两江新区的龙头,因此二手房平均单价高于其他区域。
通过seabom的distplot方法,为二手房面积拟合正态分布,拟合结果如图4所示,可以看m面积的分布符合正态分布,并计算出拟合的偏度为1.448067,峰度为4.841826,并且面积为80平方米左右的房屋数量最多。此外还有一些大于170平方米的房屋,已经超出正常范围。
对重庆二手房最常出现的户型进行计数并可视化显示结果,由图5可知,二手房最常出现的户型为3室2厅。
为了探索二手房标题后的规律,使用jieba分词,对标题进行切分,再用可视化的方法,画出标题的词云图。由图6可知二手房为了更快的卖出房屋,标题通常包含户型方正、诚心出售、拎包人住等关键词。
4总结
大数据时代的到来,数据量以指数的方式增长,应该利用计算机计数挖掘大数据背后的信息,为人们的生活提供方便。本文利用了网络爬虫技术,从贝壳找房网爬取了重庆二手房的信息,经过数据分析,得出二手房最常出现的户型是3室2厅,标题大都包含户型方正等结论,为人们发布房源,购买二手房等提供了信息。
参考文献:
[1]刘智慧,张泉灵.大数据技术研究综述[J].浙江大学学报:工学版,2014,48(6):957-972.
[2]刘乙颖,余函.重庆市房地产市场价格变动趋势探卡厅[J].市场周刊(理论研究),2017:38-39.
[3]晋振杰,曹少中,项宏峰,等.基于python的电商书籍数据爬虫研究[J].北京印刷学院学报,2018,3(26):39-42.
[4]张文霖,刘夏璐,狄松.谁说菜鸟不会数据分析(入门篇)[D].北京:电子工业出版社,2016.
[5]熊畅.基于Python爬虫技术的网页数据抓取与分析研究[J].数字技术与应用,2017(8):35-36.
【通联编辑:光文玲】
收稿日期:2019-09-13
作者简介:刘航(1995-),男,重庆丰都人,硕士在读,主要研究方向为爬虫、图像处理。
