小麦秸秆中K和Na元素LIBS同步定量分析研究
2019-03-06段宏伟韩鲁佳黄光群
段宏伟 韩鲁佳 黄光群
(中国农业大学工学院, 北京 100083)
0 引言
作为一种清洁可再生能源,秸秆已成为我国生物质资源燃烧发电利用的重要组成部分。与烟煤燃料相比,生物质秸秆中硫、氮和碳含量较低,钾(K)和钠(Na)含量较高。秸秆直燃发电虽然能够减少环境中二氧化硫、氮氧化物和二氧化碳的排放,但高浓度的碱金属容易引发结渣问题,从而对秸秆燃烧效率产生巨大影响。由于不同产地、不同种类秸秆中碱金属含量不同,能够表征秸秆燃料结渣程度的碱性氧化物指数也会有所差别[1]。因此,生物质秸秆中碱金属K和Na的元素定量分析具有重要意义。
与传统原子光谱分析技术相比,激光诱导击穿光谱(Laser induced breakdown spectroscopy, LIBS)技术具有不需要对样品进行繁琐预处理以及能够同时进行多元素快速分析的优点,已在土壤、植物和农产品等多个方向的农业领域中广泛应用[2-11]。然而,目前LIBS在生物质秸秆基础组成和特性方面的研究报道较少。原因可能是:对于农业物料样本,样品中各元素分析线光谱极易受到复杂的基体效应和自吸收/自蚀影响,从而较大程度地降低模型预测精度。合适的光谱预处理能够有效减弱因基体效应引发的光谱扰动[12-14],回归方法(线性/非线性)的合理选取也有利于建立更稳健的光谱定标模型。因此,LIBS光谱数据预处理和建模方法的选取对快速准确定量分析生物质秸秆中K和Na元素含量具有重要意义。
常用的原子光谱预处理方法主要包括基线校正(Baseline correction, BC)、归一化(Normalization, Norm)、中心化(Mean-centering, MC)、导数法和多元散射校正等方法。由于LIBS光谱仪采集通道数较多,不同通道之间基线差别较大,且光谱仪中暗电流噪声可能使所获取光谱发生基线偏移,同时考虑到光谱仪工作时微弱光程差异可能引起光谱变化,因此,本文主要选取基线校正、归一化和中心化相互组合算法作为小麦秸秆中K和Na的LIBS光谱预处理方法。在常用的多元建模方法中,线性建模方法偏最小二乘回归(Partial least squares regression, PLSR)能够同时对光谱和化学分析值进行主成分降维,所构建的定标模型稳健性较好;非线性建模方法增强型反向传播人工神经网络(Adaboost backpropagation artificial neural network, BP-ADaboost)通过将多个BP神经网络作为弱分类器构建成强学习器,从而克服BP神经网络容易陷入局部最优和过拟合的缺陷,因而具有较好的非线性拟合性能。因此,可将PLSR和BP-ADaboost作为小麦秸秆中K和Na含量的线性和非线性建模方法。
本文选用我国华北地区小麦秸秆作为研究对象,通过查询NIST数据库确认K和Na分析线位置及对应波段,分别采用基线校正、归一化与中心化相互组合算法对LIBS光谱进行预处理,对比不同预处理算法对小麦秸秆中K和Na的LIBS光谱降噪效果的影响,同时分析比较线性建模方法PLSR和非线性建模方法BP-ADaboost对预处理后光谱数据的适用性。
1 材料与方法
1.1 样品采集与制备
29个代表性小麦秸秆样本采自我国山东省、山西省、天津市和河北省。小麦秸秆切碎后置于45℃ 干燥箱中干燥至质量恒定,经WKF-130型粉碎机粉碎后过20目筛,放入自封袋中备用。
1.2 K和Na含量测定
取每个制备样品约0.50 g,与7.00 mL浓硝酸消解液混合置于密闭的微波消解系统(意大利Milestone touch公司)进行消解处理,再于160℃加热板上赶酸后,将消解液转移到100.00 mL容量瓶中定容。配置对应浓度的K和Na的标准曲线,使用PE NexION 300型电感耦合等离子体发射光谱仪对消解液中K和Na含量进行测定。每个样品重复测定2次,最终以平均值作为K和Na含量标准值。
1.3 光谱采集
LIBS光谱采集使用ChemReveal 3764型台式LIBS激光光谱仪,其主要包括Nd:YAG钇铝石榴石晶体激光器(激发波长1 064 nm)、中阶梯光栅光谱仪(Echelle)、7通道电荷耦合(CCD)光谱探测器(波长190~950 nm,分辨率0.05 nm)、数字延迟发生器、精密旋转仪、计算机、反射镜、透镜和光纤等。
光谱采集前,首先将环境气体设置为氩气,激光器脉冲聚焦点调节在样品表面下2 mm,以防止氩气被击穿。针对激光脉冲能量波动对谱线强度的影响,将激光能量设为最大能量的15%,单点激光重复烧蚀次数设为20。为获取最佳的光谱强度和信背比,探测器相对于激光脉冲的延迟时间为1 μs。同时将单个样品的光谱采集点数设为80,单个点的光斑直径设为400 μm,以减少样品不均匀性带来的误差。
光谱采集时,扫描器按照设定路径逐点扫描,并依次获取每个点在187.781~982.287 nm波段内的光谱信息,扫描完成后将最终获取的80个点的平均光谱作为该样品光谱。制备样品从自封袋中取出后,均匀填满直径和深度为30 mm和7 mm的铝盖,以20 t压力将样品压制成紧实、平整的片状,以防止光谱采集过程中的样品飞溅。
1.4 模型及效果评价
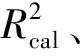
交互验证决定系数越大,交互验证均方根误差越小,则建模效果越好;预测决定系数越大,预测均方根误差越小,则模型预测效果越好。若相对分析误差大于3,表明模型的预测效果较好,可以用于实际检测;若相对分析误差在2.25~3范围内,说明利用模型能够进行定量分析,基本满足实际检测需求;若相对分析误差在1.75~2.25范围内,说明模型预测效果一般,基本可以定量分析;若相对分析误差小于1.75,则模型难以进行定量分析[16]。
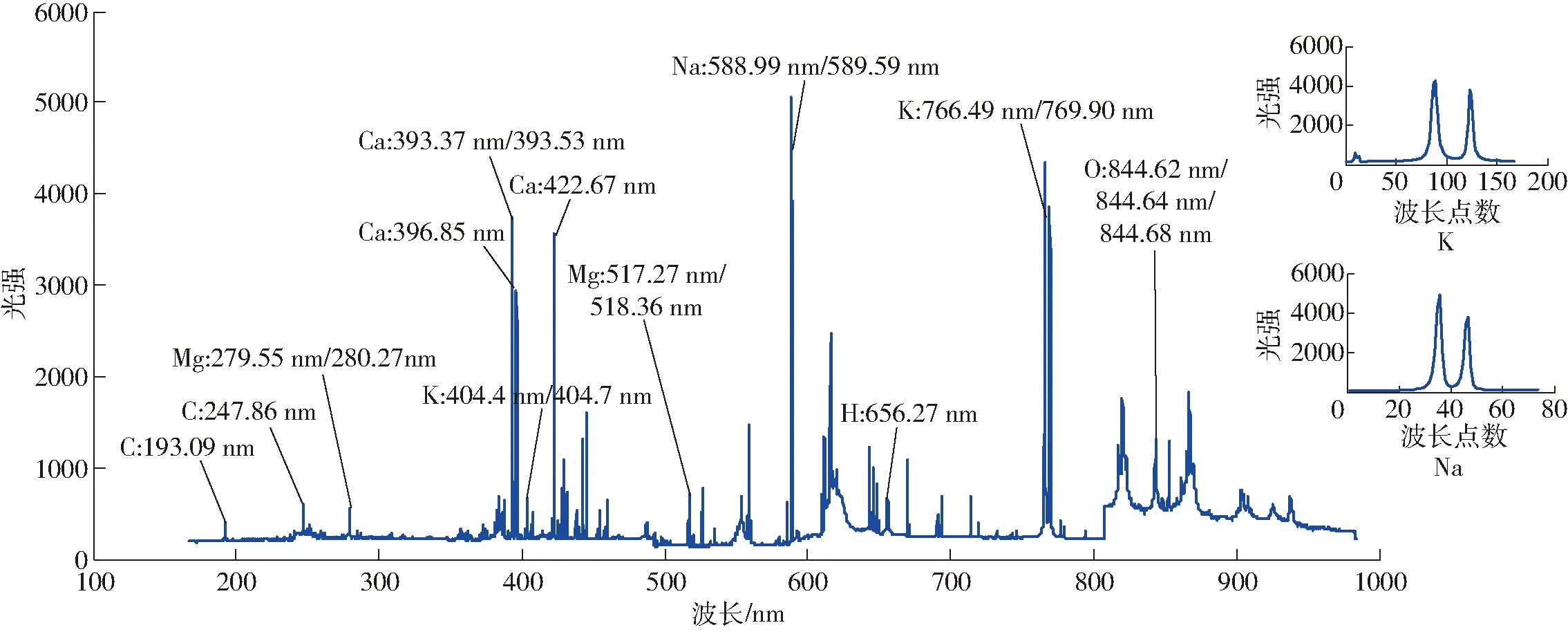
图1 小麦秸秆样品平均光谱Fig.1 Averaged spectrum of wheat stalk samples
1.5 数据处理和分析
原子发射光谱的数据统计、降噪和建模分析分别基于ChemLytics和Matlab 2014a软件平台完成。利用软件Office 2013、Origin 9.1和Matlab 2014a分别制作图表。
2 结果与分析
2.1 K和Na含量统计分析
将采集到的29个代表性小麦秸秆样本按照元素含量递增方式排序后,以3∶1的比例选取22个样本作为建模校正集,剩余7个样本作为预测集,小麦秸秆中K和Na的含量(质量比)统计结果如表1所示。
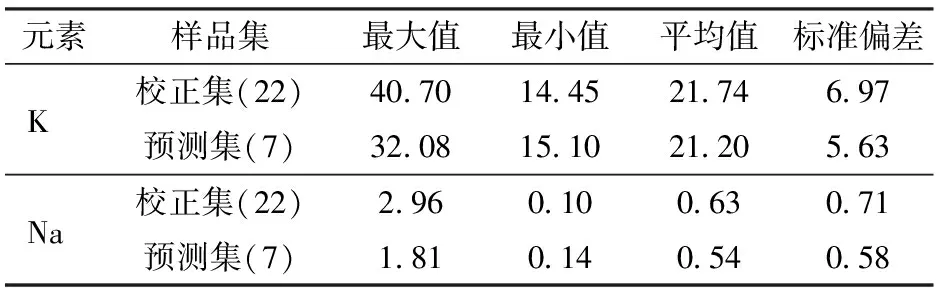
表1 小麦秸秆钾和钠含量统计结果Tab.1 Content statistical result of K and Na in wheat straw g/kg
2.2 小麦秸秆LIBS光谱解析
小麦秸秆主要由纤维素、半纤维素、木质素以及少量无机物组成,其主要包含C、H、O、K、Na、Ca和Mg等元素。LIBS仪器获取的29个小麦秸秆样品中各元素的平均光谱如图1所示。由图1结合NIST数据库得出C、H、O、K、Na、Ca和Mg 7种元素的19条分析谱线参数如表2所示,主要包括信号强度、能级结构、统计权重、跃迁概率、上下能级能量。观察发现,对于同种元素:当上下能级能量相同时,原子跃迁概率一般近似相同;当上能级相同时,下能级越高,跃迁概率一般越低;而当下能级相同时,上能级越低,跃迁概率一般越高。并且,对于同种元素同一类型的原子(如CⅠ、KⅠ、CaⅡ等):上下能级差越大,上下能级统计权重比值越小,原子越难被激发,信号强度越低。
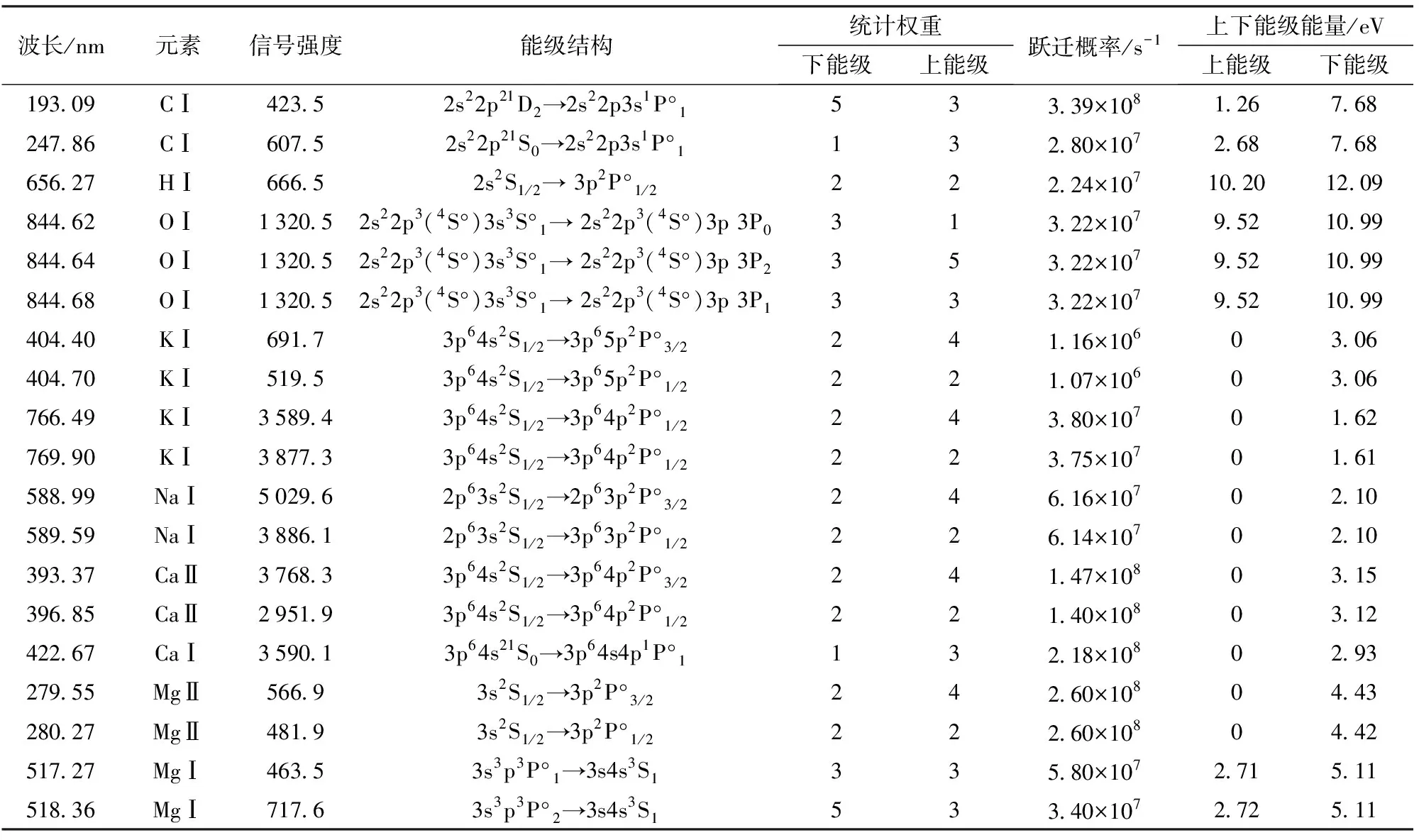
表2 小麦秸秆中主要元素分析线光谱参数Tab.2 Spectroscopic parameters of analytical lines of main elements in wheat stalk
对于Na,原子发射光谱分析线位于588.99 nm和589.59 nm处,对应的2个吸收峰主要分布在587.026~591.022 nm附近。并且,588.99 nm处的信号强度高于589.59 nm,原因可能是二者上下能级能量相同的条件下,588.99 nm处的上下能级统计权重比值更大。对于K,其原子发射光谱分析线位于404.4、404.7、766.49、769.90 nm处,对应的4个吸收峰主要分布在403.711~405.283 nm和760.052~774.026 nm附近。对比发现,前后两个波段区间的基线水平相差较大,原因主要是LIBS全波段(190~950 nm)光谱仪包含7个光学通道,而不同通道之间存在拼接误差。同时,观察发现K的原始光谱在766.49 nm和769.90 nm处吸收峰存在严重的自吸收现象,原因可能是随着激光能量的增加,激光与样品作用形成的烧蚀坑直径和深度均增大,样品烧蚀量增大,激发的K原子、离子量增加,光源中心温度较高,原子所发射的光谱容易被周围大量分散的基态同类原子所吸收,又由于吸收线宽度小于发射线的宽度,因此可以发现谱线中心处的吸收比边缘更强烈,即发生了自吸收[17-18]。
2.3 定标模型构建
与分子光谱分析技术相比,LIBS技术依据罗马金-赛伯[19-20]公式原理进行样品元素检测,主要利用已知元素的分析线和吸收峰光谱信息。因此,当采用多元线性或非线性方法进行小麦秸秆中K和Na含量的定标模型构建时,选取K(403.711~405.283 nm、760.052~774.026 nm)和Na(587.026~591.022 nm)的光谱数据作为建模原始数据[12]。为了消除因样品的基体效应引发的光谱噪声,分别选用中心化(MC)、归一化(Norm)、基线校正(BC)对所获取小麦秸秆中K和Na的LIBS光谱数据分别进行预处理。分别采用PLSR和BP-ADaboost构建不同预处理后光谱数据的定标模型,并采用留一法对定标模型进行交互验证,结果如表3所示。为了提高BP-ADaboost算法计算效率和建模精度,采用主成分分析法(PCA)首先对原始数据进行特征信息提取,提取参数累积方差贡献率设为95%。交互验证均方根误差越小,则定标模型建模效果越好,表明所对应的光谱预处理效果越好。
对于K,在5种预处理方法中,PLSR模型中最小的交互验证均方根误差为3.203 g/kg,此时采用的潜变量因子数为2,对应的预处理方法为MC;而PCA-BP-ADaboost模型中最小的交互验证均方根误差为1.255 g/kg,对应的预处理方法为BC+MC。
对于Na,当采用BC+MC进行光谱预处理时,其PLSR模型的交互验证均方根误差为0.167 g/kg,小于其他光谱预处理后模型结果;而当采用BC+Norm+MC进行光谱预处理时,PCA-BP-ADaboost模型的交互验证均方根误差为0.001 g/kg,小于其他光谱预处理后模型结果。
综上可知,当分别采用MC和BC+MC对小麦秸秆中K和Na的LIBS光谱进行预处理时,其PLSR模型建模效果分别达到最优;而当分别采用BC+MC和BC+Norm+MC对小麦秸秆中K和Na的LIBS光谱进行预处理时,其PCA-BP-ADaboost模型建模效果分别达到最优。进一步比较可知,最优预处理方法后的光谱模型效果均好于未预处理后光谱建模效果。原因可能是BC方法能够消除仪器中不同光谱通道之间的基线差异及暗电流噪声引起的轻微基线偏移,Norm能够消除光程差的影响,而MC能够增强不同样本之间的光谱数据差异性从而有利于提高模型精度。
2.4 模型预测效果比较
为验证所构建小麦秸秆中K和Na最优PLSR和PCA-BP-ADaboost定标模型性能,选用具有代表性的7个小麦秸秆样本进行预测分析,模型预测结果如表4所示。
对于K,当潜变量因子数为2时,其PLSR模型预测均方根误差和相对分析误差分别为2.569 g/kg和2.192,相对分析误差小于PCA-BP-ADaboost模型结果。表明PCA-BP-ADaboost模型预测性能较好。分析原因,可能是K在766.49 nm和769.90 nm处存在自吸收,致使分析线光谱强度与K浓度含量之间不再遵从朗伯比尔线性定律,从而更适用于非线性神经网络模型。并且, PCA-BP-ADaboost模型相对分析误差大于2.35,表明该模型能够用于定量分析小麦秸秆中K含量,基本能够满足实际检测需求。
对于Na,当潜变量因子数为5时,其PLSR模型的预测均方根误差和相对分析误差分别为0.222 g/kg和2.613,相对分析误差小于PCA-BP-ADaboost模型结果。表明PCA-BP-ADaboost模型预测性能较好。分析原因,由于小麦秸秆组成成分较为复杂,不同样本的基体效应相差较大,预处理后光谱中仍存在一定的基体效应噪声,容易对PLSR线性模型产生干扰。又由于PCA-BP-ADaboost模型相对分析误差大于4,表明该模型能够用于小麦秸秆中Na含量的实际在线检测。
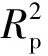

图2 小麦秸秆中K和Na的最优模型结果Fig.2 Results of K and Na in wheat straw by using the best models
3 结束语
