超级基站心跳机制的设计与应用实现*
2019-03-05王园园
王 朋, 王园园
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.移动计算与新型终端北京市重点实验室,北京 100190)
0 引 言
集中式接入网架构是未来蜂窝移动通信网络架构发展的重要方向之一。超级基站是中科院计算所提出的一种基于资源池化的集中式架构新型基站平台,通过对集中部署的处理资源的池化和按需分配,可以有效应对大量传统基站的占地问题、能耗问题、运维开销大的问题以及潮汐效应问题。超级基站在物理上表现为一组通过高速交换机互联互通的网络节点,在逻辑上表现为很多多制式虚拟机站组成的网络[1-3]。
心跳机制是对网络通路健康状况监测的一种重要手段。所谓的心跳机制是指网络节点定时轮询地发送心跳包给服务端,告诉自己还“活着”。当服务端在超时时限内收到了网络节点发来的心跳包,则会回应一个确认心跳包;若没有收到,则视为该节点网络断开或故障[4]。目前,心跳机制在即时通信、集群网络监测、双机热备和工业网络安全监测中都得到了广泛应用[5-8]。在传统的心跳机制应用设计中,在给定的超时时限下,心跳间隔往往设置成超时时限的1/3~1/2[9]。这样设置虽然可以排除网络延迟或丢包造成的误判问题,但是心跳间隔较小,心跳包的发送过于频繁,再加上超级基站的节点较多,无疑增加了监测服务端的网络负担。另外,超级基站有软固件更新自动重启功能。对于任务量较少的节点,通过资源整合,任务迁移到一个节点上,下电其他节点来达到节能和提高资源使用率的效果。然而,超级基站的重启和下电会丢失节点的心跳。传统的心跳机制对于误判问题仅考虑了网络延迟,而没有考虑节点的重启和下电也会带来误判。一旦产生误判将会带来不必要的任务切换,增加其他节点的任务负载,导致被误判节点的资源得不到有效利用。
1 改进心跳机制的设计
针对以上提出的问题,本文设计提出了一种改进的心跳机制。该心跳机制分为两个阶段,分别是最优心跳间隔决策阶段和心跳监测判决阶段。从交互流程上分为节点端和监测服务端。
系统初始启动时,便开始进入最优心跳间隔查找阶段。此阶段发送标志位为“Test”的心跳包。在初始给定的超时时限、最优心跳间隔的查找范围和心跳间隔阈值下,通过使用二分法[10-11]不断分割并缩小最优心跳间隔所在的区间长度,保证监测服务器端能够在超时时限内收到被监测端的心跳包的同时,使心跳间隔尽可能大。当被分割的心跳区间的长度小于或等于心跳间隔阈值时,则不再查找,决策出最优心跳间隔,进入稳定工作模式。
当最优心跳间隔已确定进入稳定工作模式后,节点端将保持最优心跳间隔发送标志位为“Keep”的心跳包,进入心跳监测判决阶段。在此阶段,监测服务端每隔Timeout时间都会对接收到的各节点心跳包进行判决。为了避免节点重启或下电造成的心跳丢失带来的误判,在节点需要重启或下电前,节点端将会发送一条标志位为“Restarting”或“PowerOff”的心跳包告知监测服务端该节点将要重启或下电。监测服务端将节点的通路状态分为“Normal”“Fault”“Restarting”和“PowerOff”4个状态。根据收到的心跳包的标志位,将网络通路状态改为“Normal”或“Restarting”或“PowerOff”。当判定网络故障时,将该节点的网络通路状态改为“Fault”。网络通路状态的改变规则如表1所示。当某节点心跳丢失时,监测服务端通过判断该节点的网络通路状态,决定网络通路是否真的出现故障。

表1 网络通路状态改变规则
1.1 最优心跳间隔决策阶段二分法详细设计
该阶段,网络节点端发送标志位为“Test”类型的心跳包。监测服务端若连续3次收到该类型的心跳包,则给予ACK回复;否则,给予NACK回复。网络节点端根据监测服务端回复的是ACK包还是NACK包,决策分割最优心跳间隔所在的区间。在节点端和监测服务端的交互流程图,如图1所示。
变量说明:Topt为最优心跳间隔;ρ为心跳间隔阈值;Timeout为超时时限;Tcurr为当前心跳间隔;hb_count为记录接收到的心跳包的次数;[A,B]为初始给定最优心跳间隔查找的范围,0<A<B≤Timeout;t1、t2为临时变量。
二分法算法步骤如下:
(1)给区间[A,B],心跳间隔阈值ρ和超时时限Timeout赋初值,然后令t1=A,t2=B。
(2)判断t2-t1<ρ成否成立,若否,则执行(3);若成立,最优心跳间隔确定为Topt=t1,进入稳定工作模式。
(3)将当前心跳间隔设为Tcurr=(t1+t2)/2。
(4)以心跳间隔Tcurr向监测服务器端发送标志位为“Test”的心跳包。
(5)当收到监测服务器端ACK回复时,说明心跳间隔较小,在右半区间查找,令t1=Tcurr,执行(2)。
(6)当收到监测服务器端NACK回复时,说明心跳间隔过大,在左半区间找,令t2=Tcurr,执行(2)。
使用该二分法通过节点端和监测服务端不断交互测试获取的心跳间隔,比传统方法获取的心跳间隔大而优,在保证心跳机制可靠性的前提下,减少了心跳包发送的频繁度,从而减少了监测服务端的网络负担。
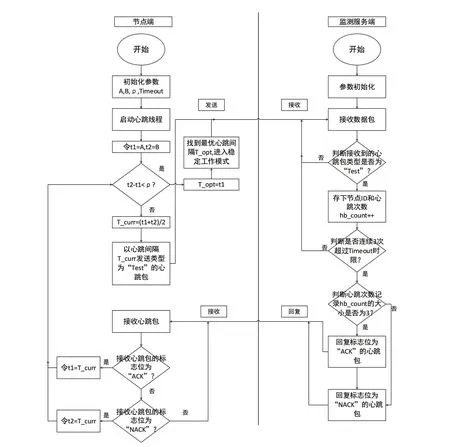
图1 二分法节点端和服务端交互的流程
1.2 心跳监测判决阶段的详细设计
该阶段节点端和监测服务端的交互流程,如 图2所示。监测服务端每收到的一个心跳包,都会保存发包的节点ID、心跳次数记录hb_count加1以及判断心跳包的标志位决定是否对节点的通路状态进行更改。每当定时器时间超过Timeout时,则会对每个节点的心跳次数进行判决。判决完后,将各节点的心跳记录清零,继续接收心跳包。
判决方法为:
(1)当节点的心跳次数hb_count都大于0时,则网络通路正常。
(2)当节点的心跳次数hb_count为0时,说明该节点的心跳丢失,然后对该节点的网络通路状态进行判断。
(3)若节点的通路状态为“Fault”,则说明节点的网络通路已经故障,需进行网络通路故障上报;否则执行(4)。
(4)若通路状态为“Normal”,说明不是节点的重启或下电造成,考虑可能是网络延迟导致,则再连续接收2次,若收到了节点的心跳包,则说明存在网络延迟,否则上报节点网络通路故障,并将该节点的网络通路状态改为“Fault”,否则执行(5)。
(5)若通路状态为“Restarting”,说明节点重启导致,判断5 min内是否收到节点的心跳包(经多次试验节点的重启时间一般在2 min左右),若否,上报重启后节点网络通路故障,并将该节点的通路状态置为“Fault”;否则执行(6)。
(6)若通路状态为“PowerOff”,说明节点下电导致,不进行网络故障上报,否则执行(7)。
(7)节点的状态为初始状态,则上报节点初始启动时网络通路故障,并将该节点的网络通路状态改为“Fault”。
在此阶段,综合考虑了网络时延、节点重启和节点下电因素可能使心跳机制产生的误判,并给出了相应的判决方法,提高了心跳机制的可靠性,保证了超级基站稳定可靠的运行。

图2 心跳监测判决阶段节点端和监测服务端的交互流程
2 心跳包组包方式的选择方案
为了保证超级基站的负载均衡,为是否进行虚拟基站的迁移提供决策依据,监测服务端还需对超级基站各节点的系统资源使用率进行实时监测[12]。因此,超级基站各节点不仅需要定时发送心跳包,还需要定时发送系统资源使用率监测包。在心跳包发送心跳间隔最优且一定的情况下,为了最大限度地减少心跳包给监测服务端带来的网络负担,针对心跳包的组包方式对产生的网络流量影响进行分析。节点端发送心跳包的组包方式可分为两种: (1)心跳包和系统资源监测包独立发送;(2)将心跳包和资源监测包合并为一个心跳包发送。下面针对两种不同心跳包的组包方式产生的网络流量进行建模分析。
假设消息头的大小为a字节,心跳包的主机标识信息大小为b字节,系统资源监测包的数据域的大小为c字节。集群节点的数量为n个,每个节点发送资源监测包的时间间隔为T1秒,发送心跳包的时间间隔为T2秒,一个小时内n个节点定时发送心跳包和资源监测包产生的网络流量为F。
方式1:心跳包和资源监测包独立发送
心跳包和资源监测包的数据格式如图3(a)和图3(b)所示,节点在一个小时内发送的心跳包和资源监测包产生的网络流量F1为:

化简,得到:

方式2:将心跳包和资源监测包合并为一个心跳包发送
将资源监测包的数据域添加到心跳包尾部的数据格式,如图3(c)所示。节点以这种方式发送心跳包一个小时产生的网络流量F2为:
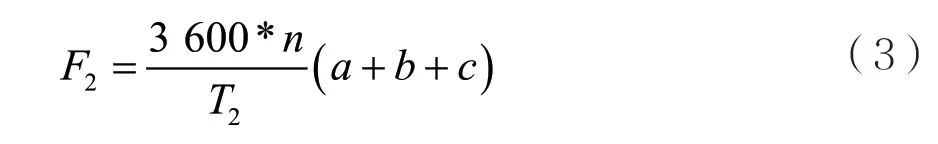
式(2)减去式(3),得到:


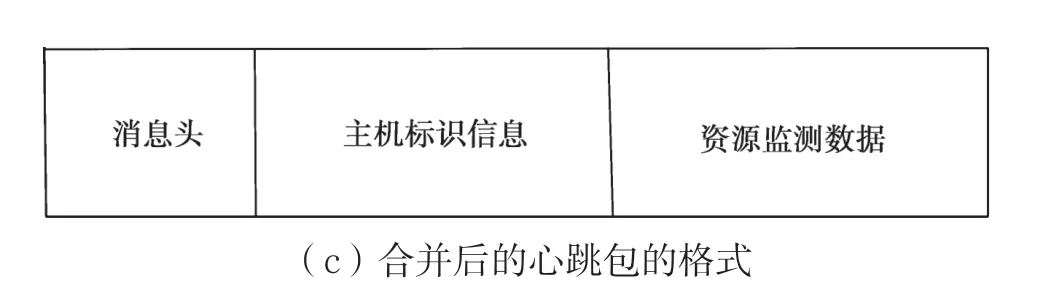
图3 数据包格式
综上所述,当资源监测数据包发送的时间间隔T1与心跳包发送的时间间隔T2的关系为时,F1>F2,采用将资源监测包和心跳包组合成一个心跳包的方式发送产生的网络流量更少;当资源监测数据包发送的时间间隔T1与心跳包发送的时间间隔T2的关系为时,F1≤F2,采用将资源监测包和心跳包相互独立的方式发送产生的网络流量更少。
3 测试分析
3.1 可靠性测试
该改进的心跳机制实现采用C语言编程,代码按照图1、图2节点端和监测服务器端的交互流程图编写,通信协议采用TCP协议,监测服务器端采用IO多路复用接口函数epoll来监听接收数据。在超级基站的3个节点上,对该改进的心跳机制进行了可靠性测试。设置监测服务器端的超时时限Timeout=10 s,最优心跳间隔的查找范围为 [1 s,10 s],心跳误差ρ=10 ms,3个节点的Ip分别为10.21.101.172、10.21.3.97、10.21.2.125,分别编号为0号节点、1号节点和2号节点。测试分为对网络延迟和网络断开测试、对节点重启和关机测试。
3.1.1 网络延迟和断开场景测试
对网络延迟测试和网络断开测试的方法为,在心跳机制正常工作的情况下,在监测服务端模拟网络延迟测试,然后依次拔掉3个节点的网线,测试结果如图4所示。初始3个节点与监测服务器端建立连接完成,然后进入最优心跳间隔测试阶段。当最优心跳间隔查找完成后,监测服务器端开始正常接收“Keep”标志位的心跳包。在正常接收的1个周期后,2号节点的心跳包丢失。考虑到可能是网络延迟导致,则继续接收,在下一个超时时限内又收到了2号节点的心跳包,判定网络存在延迟,而并没有上报网络通路故障。然后,依次断开0号节点、1号节点和2号节点,监测服务器端都能够正确判决出0号节点、1号节点和2节点的网络出现了故障,验证了该改进心跳机制对网络延迟和网络断开的可靠性。

图4 对网络延迟和网络断开测试结果
在最优心跳间隔测试阶段,使用二分法不断分割最优心跳间隔所在区间,如图5所示。当超时时限Timeout设置为10 s时,3个节点最终查找决策出的最优心跳间隔均为9 292 ms,约为9.3 s。和传统的将心跳间隔设置为超时时限的1/3~1/2倍即设置为3.3~5 s相比,使用二分法获取的心跳监测大而优,减少了心跳包发送的频繁度,减少了监测服务端的网络负担。

图5 二分法查找最优心跳间隔测试结果
3.1.2 节点重启和下电场景测试
在心跳机制正常工作的情况下,先重启所有节点,待节点都重启后下电0号节点,测试结果如图6所示。
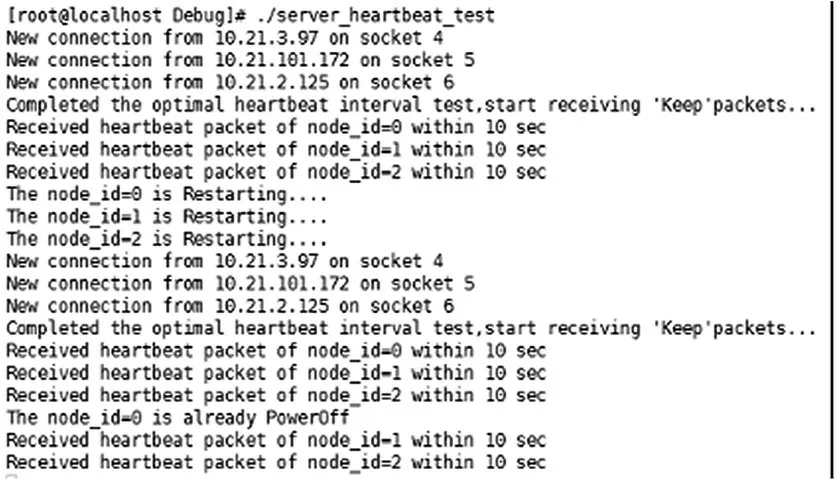
图6 对节点重启和下电测试结果
系统初始启动时,监测服务端与3个节点建立连接成功。在第一个超时时限内收到3个节点的心跳包,然后成功检测出节点重启。过一小段时间后,节点重启成功,并在第一超时时限内收到了所有节点的心跳包,在下一超时时限内成功检测出了0号节点下电和其他两个节点正常,验证了该改进心跳机制对节点重启和下电的可靠性。
3.2 不同心跳包的组包方式产生网络流量的对比
在Linux系统下,通过使用进程流量监控工具NetHogs,对监测服务端进程接收和发送的流量进行监控。在超级基站中,系统资源使用率数据包的采集频率为T1=10 s,消息头的大小a=8字节,心跳包的主机标识信息大小b=5字节,资源监测包的数据域的大小c=16字节。针对两种不同的组包方式进行测试,分别采集了5 min、10 min、20 min、 30 min的流量进行对比,结果如图7所示。

图7 两种组包方式产生的流量对比
从图7的柱状图可以明显看出,心跳包采用方式二的组包方式发包,产生的网络流量更少,对监测服务端造成的网络压力更小。随着时间的推移,两种发包方式产生的网络流量差距越来越大,说明随着时间的增大,与方式一相比,采用方式二节省的网络流量更多,性能更优。由式(4)可得,当,F1>F2,也可以得出采用方式二的发包方式更节省流量。可见,此计算结果和测试结果一致,验证了心跳包组包方案对于节省网络流量的有效性。
4 结 语
本文设计了一种改进的心跳机制,使用二分法查找决策出最优心跳间隔,考虑了多种可能使心跳机制造成误判的因素。另外,为了尽量减心跳包频繁发送产生的网络流量,减轻监测服务器端的网络负担,提出了一种心跳包组包方案。测试结果表明,该改进的心跳机制具有很高的可靠性,提出的心跳包组包方案能够节省网络流量,减轻监测服务器端的网络负担。
