面向Android应用隐私泄露检测的多源污点分析技术∗
2019-03-05何冬杰冯晓兵
王 蕾,周 卿,何冬杰,李 炼,冯晓兵
1(计算机体系结构国家重点实验室(中国科学院 计算技术研究所),北京 100190)
2(中国科学院大学,北京 100190)
随着移动应用的广泛普及,其安全问题正受到严重的挑战.移动支付、电子商务、社交网络等活动中存在着大量的用户隐私数据,大量第三方移动应用程序的使用导致隐私数据难以被有效地保护.例如,印度的一家公司设计了一组智能手机应用开发工具包SilverPush,它可以嵌入到一个正常的手机应用中并在后台运行,在用户不知情的情况下收集用户的隐私数据(包括IMEI ID、位置信息、视频与音频信息、Web浏览记录等),并将其发送给广告推荐商[1].污点分析技术(taint analysis)[2]是信息流分析技术(information-flow analysis)[3]的一种实践方法.该技术通过对系统中的敏感数据进行标记,继而跟踪标记数据在程序中的传播,检测系统安全问题.据调查分析[4],在Android应用的静态安全检测中,污点分析则是最为流行的分析方案.
污点分析可以有效地检测Android应用的隐私泄露问题.举例说明,图1所示为一段Android应用程序代码,运行该段程序会导致用户的密码数据通过发送短信的方式泄露.污点分析首先要识别引入敏感数据的接口(source,污点源)并进行污点标记.具体到程序中,即识别第 4行的 passwordText接口为污点源,并对pwd变量进行标记.如果被标记的变量又通过程序依赖关系传播了给其他变量,那么根据相关传播规则继续标记对应的变量.当被标记的变量到达信息泄露的位置(sink,污点汇聚点)时,则根据对应的安全策略进行检测.图1中,第 8行带污点标记的leakedMessage变量可以传播到发送信息的sendTextMessage接口,这就意味着密码数据会被该接口泄露.污点分析又分为静态和动态的污点分析.静态污点分析是指在不运行代码的前提下,通过分析程序变量间的数据依赖关系来进行污点分析.相对于动态运行的污点分析,静态污点分析可以在程序发布之前对应用程序安全问题进行检测,避免了发布之后造成的安全问题.另外,该技术具有分析覆盖率高(不依赖测试集合)、无需程序插桩(而导致的程序运行出现开销)等优势.
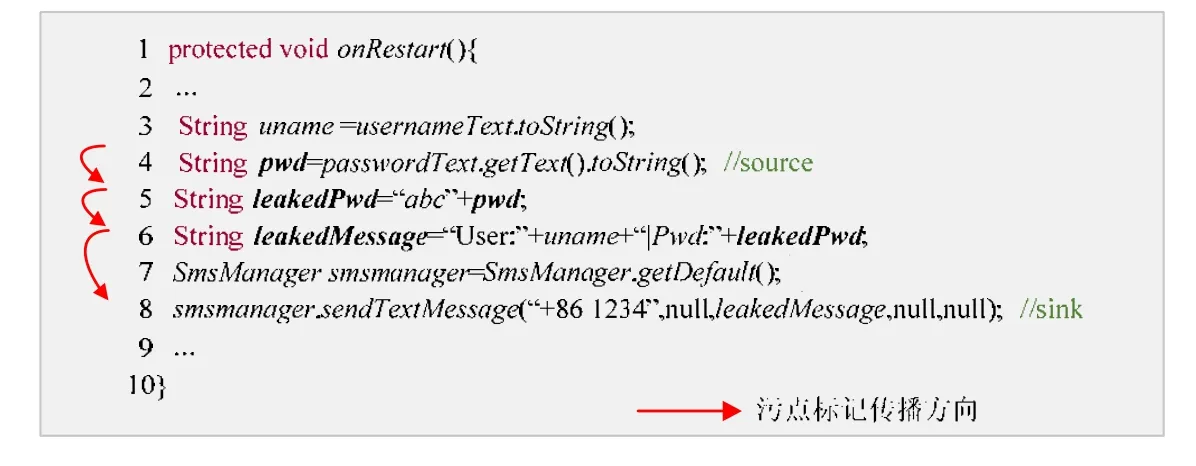
Fig.1 An example of taint analysis图1 污点分析示例
然而,在检测 Android应用隐私泄露问题时,静态污点分析存在结果误报率较高的问题.这是由于为了能够发现所有潜在的恶意行为,污点分析需要将可能的敏感信息泄露路径都报告出来,而程序中正常功能也需要选定一些敏感的数据传播到外界.据统计,MudFlow[5]利用静态污点分析工具FlowDroid测试的2 866个良性软件(benign App)一共产生了338 610条污点分析结果,检测人员需要在大量集合中选出具有恶意行为的结果,这将是效率极低的.利用污点分析解决的隐私泄露问题(提高检测精度)是当前Android安全的重要研究热点.一些研究工作[5-8]尝试使用统计的方法进行恶意行为区分,例如,MudFlow[5]尝试对比污点分析结果和良性软件结果的差异,利用 SVM 分类模型检测出一个软件是否是恶意软件.然而,检测人员常常需要验证具体的泄露路径,该工具只能给出一个软件整体是否具有恶意行为(而且该工具也会存在误报),无法给出其中一条污点分析路径[Source→Sink]是否是直接导致隐私泄露的结果,这驱使我们尝试更加有效的分析方案.不同于其他方法,本文选择了另外一种假设作为切入点:我们假设良性软件和恶意软件所使用的敏感数据流之间的相关性(绑定发生特性)是有差异的(我们将在第 5.1节来验证该差异确实存在).例如,在良性软件中,地图信息和设备标识信息的验证往往不在一个模块中执行,而恶意软件则将设备信息与定位信息一起(绑定)发送到网络.然而,当前研究工作没有提供有效的多源分析技术.基于上述的分析与假设,本文提出了一种分析污点结果中多源之间是否绑定发生的污点分析技术.该技术可以给出污点分析结果之间是否可以在一次执行中绑定发生.此外,本文还提出了一种高效的实现方法,使得多次的多源分析开销很低.随后,本文将该技术应用到Android应用隐私泄露检测中.
总之,本文的主要贡献如下.
(1)创新地提出了一种解决多源绑定发生问题的污点分析技术.该技术具有上下文敏感、流敏感、域敏感的特性,且可以精确地区分出分支条件路径互斥的情况.
(2)提出了一种多源绑定发生技术的高效实现方法.该方法将高复杂度(指数级别)的多源问题进行近似,并提出了一种按需的多源污点传播方法.实验结果表明,该方法与传统污点分析相比,开销仅为19.7%,且多次的多源分析开销很低(进一步分析的平均时间为0.3s).
(3)实现了原型系统MultiFlow,应用其到2 116个良性手机软件和2 089个恶意手机软件的隐私泄露检测中,发现了良性软件和恶意软件的绑定发生特性有较大的差别,且本文方法和传统方法对比有较大的精度提升(减少多源对 41.1%).最后,我们还提出了一种污点分析结果风险评级标准,应用评级结果可以直接提高检测的效率和精度.
本文第1节对本文的研究背景进行介绍,包括静态污点分析的通用解决方案及Android隐私泄露检测相关技术.第 2节使用实际例子演示本文的研究动机并分析该问题的难点.第 3节介绍多源绑定发生的污点分析技术,包括问题定义以及提高精度和效率两方面的关键技术.第4节给出具体实验以验证多源技术的开销.第5节将该技术应用到实际隐私泄露检测中.第6节为相关工作.第7节对本文进行总结,并深入讨论该技术潜在的应用场景.
1 背景知识
1.1 IFDS框架
一般而言,静态污点分析问题都是被转化为数据流分析问题[9]进行求解:首先,根据程序中的函数调用关系构建调用图(call graph,简称 CG);其次,为了提供更细粒度地区分程序不同执行路径的分析,还需要构建控制流图(control flow graph,简称CFG);最后,在过程内和过程间,根据不同的程序特性进行具体的数据流传播分析(与指针分析).在具体实现中,污点分析常常被设计为一种按需的分析算法:以污点源 source函数为驱动源,分析其返回值(污点)在程序中的传播,直到汇聚点sink函数为止.
IFDS框架[10]是一个精确高效的上下文敏感和流敏感的数据流分析框架,于1996年由Reps等人提出.IFDS的全称是过程间(interprocedural)、有限的(finite)、满足分配率的(distributive)、子集合(subset)问题.该问题作用在有限的数据流域中,且数据值(data flow fact)需要通过并(或交)的集合操作满足分配率.满足上述限定的问题都可以利用IFDS算法进行求解(文献[10]中的Tabulation算法),而污点分析问题正是满足IFDS问题要求的.污点分析的数据流值是污点变量,表示当前污点变量可以到达程序点Stmt.该算法的最坏的时间复杂度是O(ED3),其中,E是当前控制流图中的边个数,D是数据流域的大小.
IFDS问题求解算法的核心思想就是将程序分析问题转化为图可达问题[11].算法的分析过程在一个按照具体问题所构造的超图(exploded supergraph)上进行(如图2的例子所示),其中,数据流值可被表示成图中的节点.算法扩展了一个特殊数据流值:0值,用于表示空集合;程序分析中转移函数的计算,即对数据流值的传递计算,被转化为图中的边的求解.为了更好地进行描述,算法根据程序的特性将分析分解成4种转移函数(边).
(1)Call-Flow,即求解函数调用(参数映射)的转移函数.
(2)Return-Flow,即求解函数返回语句返回值到调用点的转移函数.
(3)CallToReturn-Flow,即函数调用到函数返回的转移函数.
(4)Normal-Flow,是指除了上述3种函数处理范围之外的语句的转移函数.
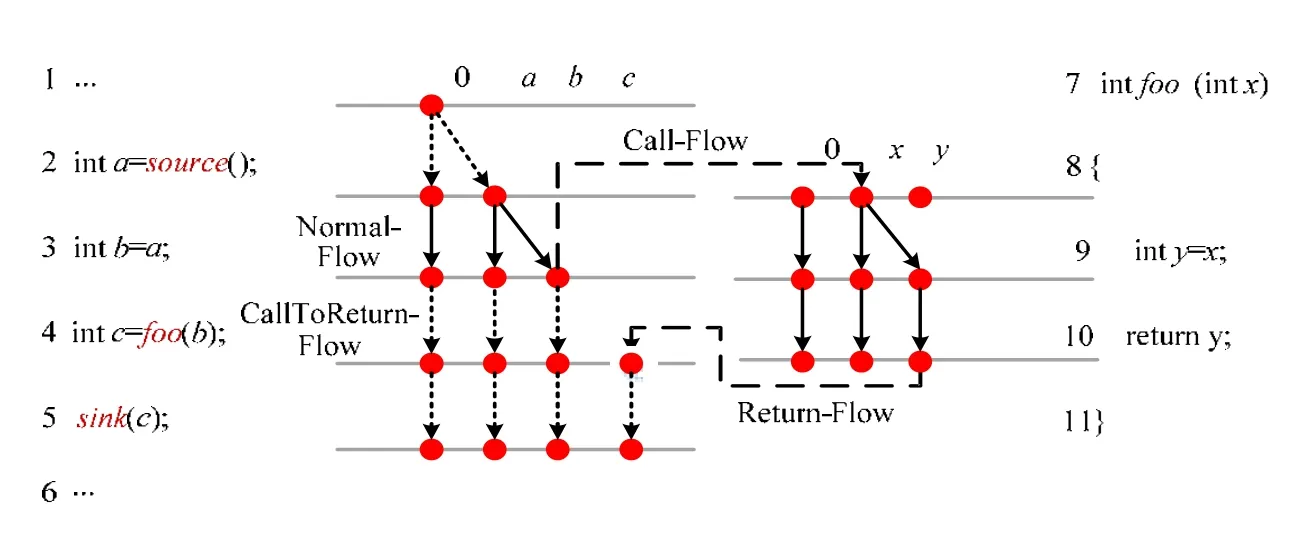
Fig.2 An example of taint analysis solved by IFDS algorithm图2 使用IFDS算法求解污点分析示例
IFDS求解算法Tabulation是一种动态规划的算法,即求解过的子问题的路径可被重复地利用.由于其数据流值满足分配率,因此可以在分支或函数调用将边进行合并.求解算法包括了两类路径的计算:路径边(path edge)和摘要边(summary edge).
· 路径边表示的是过程内从起点到当前计算点的可达路径.
· 摘要边表示的是函数调用到函数返回的边,其主要特点是,如果在不同调用点再次遇到同样的函数调用,可以直接利用其摘要边信息,从而避免了函数内重复的路径边的计算.
下面以图2中的例子来演示IFDS算法是如何求解污点分析问题的,其中的数据流值表示由污点源传播来的污点变量.为了简洁,我们简写污点源函数为source(),泄露点为sink(b),其中,b为泄露变量(下文同理).如第 2行所示,此时将产生一条由0到a的边.对于第3行的赋值语句[b=a;]和a变量,Normal-flow一般被定义为:如果赋值语句右值是污点变量,那么产生左值为污点变量且保留原值,即产生a→b和a→a的边.对于第4行的程序函数调用,由于b是函数foo的参数,分析将启动Call-Flow函数.Call-Flow一般定义为:如果实参为污点变量,就会对应产生形参的污点变量,即产生b→x的边.对于第10行的程序函数返回点,Return-Flow将产生返回语句的值到调用点返回值映射的边,即产生y→c的边.对于污点汇聚点 sink函数,如果有数据流值经过该语句,例如图中的变量c,则表示存在一条路径从0到达语句sink(c),c为最终触发sink的污点变量.对于foo中已经计算完成的入口到出口的边(图中x→y),分析将其保存为摘要边,之后,如果程序其他位置用 foo时,则直接利用该摘要边即可.
1.2 FlowDroid
FlowDroid[12]是当前最流行的开源Android静态污点分析工具,目前被广泛地应用于检测Android隐私泄露和其他Android安全问题.FlowDroid接受待分析的apk文件作为输入,利用反编译工具Dexpler和Java分析工具Soot[13]将apk文件转化成Soot中间表示Jimple,随后在Jimple上进行静态的污点分析.其分析的结果是多个污点源到污点汇聚点(Src→Sink)的集合.FlowDroid提供了完整的 Android函数调用图的构建,且提供了高精确度和高效率的污点传播分析.Android框架中存在大量回调函数,导致 Android程序的分析存在多入口的问题.FlowDroid尝试对 Android生命周期函数进行模拟,迭代地加入预先分析的入口函数(异步调用、回调函数等),使用dummyMain和虚拟节点连接成完整的调用图.在污点传播分析中,FlowDroid正是基于IFDS[10]数据流分析框架(提供了面向 Java的 Call-Flow、Return-Flow、CallToReturn-Flow、Normal-Flow的污点传播转移函数).FlowDroid同时提出一种按需的后向别名分析方法,使用Access Path来支持域敏感.因此,FlowDroid具有流敏感、上下文敏感、域敏感的高精确度.FlowDroid使用Susi[14]工具来生成在Android隐私泄露应用中使用的源和汇聚点;使用手工书写的摘要来对库函数的语义进行模拟(后续工作提供了 StubDroid[15]来自动生成库函数的摘要).FlowDroid的初衷是提供一个敏感度高且高效的污点分析工具,然而其没有深入探索污点分析检测Android应用隐私泄露的问题.
2 研究动机
正如引言中所述,当前污点分析面临的一个重要研究问题就是:污点分析结果无法回答一个应用程序是否具有隐私泄露(误报率高).本节用一个例子来说明本文的研究动机.我们选择两个应用程序的程序片段来演示当前污点分析检测隐私泄露问题的困难,其中,图3是从Google Play[16]应用市场中下载的一个新闻应用程序的代码片段,它是一个没有隐私泄露行为的应用软件;另一个程序(如图4所示)是一个从Genome库[17]中得到的恶意软件 DroidKungfu的变体.具体分析,新闻应用利用了地理位置的信息来提供用户当地的天气状况,图3左侧是其代码片段.同时,该应用的另一个常用功能就是提供设备号以便进行网络设备验证,图3右侧为其相关代码.然而,如图4所示的恶意软件片段在一个特殊的回调函数OnStartCommand下直接获取程序的地理位置信息和用户的设备号信息,然后传递给网络.它是以盗取用户敏感信息为目的的.

Fig.3 A code snippet of benign App图3 良性应用软件代码片段

Fig.4 A code snippet of malware图4 恶意软件代码片段
我们使用 FlowDroid对两个应用程序进行隐私泄露检测.由于 FlowDroid只是考虑单一的污点分析结果,分析上述两个应用程序的结果都是:{地理信息(getLatitude/getLongitude)发送到网络}和{设备信息(getDeviceId/getMacAddress)发送到网络}.即便我们尝试一些统计分析的方法,例如应用 MudFlow 中的统计结果(一种分类器)来区分,由于两者的结果是完全一样的,分类器也是无法区分两者的恶意行为的.因此,单独地依据FlowDroid的结果判断隐私泄露,会导致该问题检测的误报,这促使我们尝试更加精化的分析方法.
进一步分析我们发现,在新闻应用中,由于发送信息是在不同的模块下,因此在一次执行过程中,必然是只能发送地理位置信息到网络就不会发送用户的设备信息,反之亦然.然而对比恶意软件,由于地理信息和用户设备等信息是恶意软件同时需要的,因此它们往往是绑定在一起发送到网络的.目前的污点分析只能提供单一的污点源和汇聚点的组合结果,并没有考虑多个组合之间的相关性关系.出于上述考虑,本研究的目标就是利用多个污点源到污点汇聚点组合的相关性来降低隐私泄露检测的误报率.更进一步来讲,我们研究在程序的一次执行(一次事件触发下)路径上,多个污点分析组合是否能够绑定发生在这一路径上.我们将该问题命名为多源绑定发生问题,而提供解决此问题的污点分析称为多源绑定发生的污点分析技术.
更加特殊的情况如图3右侧程序的分支 7和分支 9下,在设备验证模块中,由于某些情况(缺少 SIM 卡),getDeviceId函数将返回空,这时需要使用设备的Wifi物理地址(getMacAddress)作为设备标识.FlowDroid得到的结果是getDeviceId→NETWORK和getMacAddress→NETWORK.然而在一次执行过程中,它们是不可能都被执行的,原因是IF分支的真分支和假分支是互斥的情况.由此可见,多源绑定发生的污点分析技术需要区分不同路径下的分析结果;其次,虽然在上述例子中没有出现,但分析还需要保证如FlowDroid一样的精度(上下文敏感、流敏感、域敏感等)以及可用范围内的开销.这些都给发掘污点分析结果之间的相关性带来了困难.因此,本研究的关键技术是提出一种精确高效的多源绑定发生的污点分析技术.
3 多源绑定发生的污点分析技术
3.1 多源绑定发生问题定义
首先,本文给出了多源绑定发生问题的形式化描述.
定义1(程序执行的轨迹流).在程序的一次执行中,从程序入口到程序出口的一系列被执行的语句序列P:
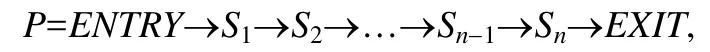
其中,Si表示程序执行过程中执行的指令语句.如果P1是P的子序列,那么P1⊆P,其含义表示P1出现在P的执行过程中.
定义2(污点分析轨迹流).从污点源传播到污点汇聚点的一系列被执行的语句序列F:
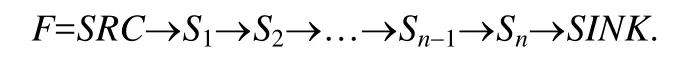
如果F⊆P,则说明一条污点分析轨迹流F出现在程序执行P中或程序的一次执行P可以触发污点分析结果F.
定义3(多源绑定发生).令表示一组污点分析轨迹流,那么在一次执行轨迹流P中,该组轨迹流能够绑定发生,当且仅当满足如下公式:
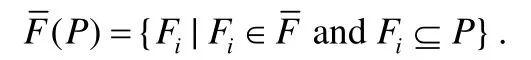
我们简称多源绑定发生问题为多源问题.令的大小(即中污点结果的个数)为k,我们称大小为k的F的绑定发生问题为k-多源绑定发生问题,简称k-多源问题.传统的产生独立污点结果的污点分析则是 1-多源问题.
目前,使用静态分析解决多源绑定发生问题具有很大的挑战.
· 首先,由于程序中分支和循环的存在,程序可能的执行路径数量会根据分支的数量呈指数级上升.为了完成有效的分析,静态(污点)分析常用的方法是在分支交汇处合并数据流值,以表示出当前可能发生的数据流值.例如,图3例子中,分支结束点第 13行得到的最终数据流值包含的源是{getDeviceId,getMacAddress},表示两个源都可能传播到网络.然而,同样的问题在多源绑定发生问题中并不适用,因为如果在程序分支处进行合并就无法有效地区分出不同路径下的污点传播.
· 其次,一次污点分析往往会产生多组污点分析结果,记其个数为k.对k-多源问题求解的复杂度会是k的指数级别(将在后文进行论证),即便我们仅对结果中的两对源进行分析(2-多源问题),k对结果之间两两组合的个数是,此时,我们可能的查询次数最多会有次数.如果多源问题的开销较大的话,多次的查询会导致系统难以使用.
本文创新地提出了解决上述难点的方法,我们将在第3.2节介绍多源绑定发生的污点分析技术(保证精度),在第3.3节介绍一种高效的实现方法(保证效率).
3.2 多源绑定发生的污点分析
正如第 1节所述,静态污点分析的数据流值表示的是当前的污点变量可能到达该语句 Stmt.为了能够保证多源绑定发生的分析,我们创新地提出了将数据流值扩展以污点变量组成的向量的形式,如公式(1)所示.
令v1,v2,…,vn-1,vn为污点变量,其绑定发生的数据流值为

数据流值是一个污点变量组成的向量,而整个数据流值表示向量中所有的变量在当前的语句 Stmt上是可以绑定到达的.以图5中的程序为例,如果数据流值〈b1,b2〉分别传播到sink(b1)和sink(b2),则表示污点变量b1和b2的源是可以绑定发生的.传统的污点分析方法(如FlowDroid中的方法)正是该方法的一个特例,即数据流值为一元向量的情况.
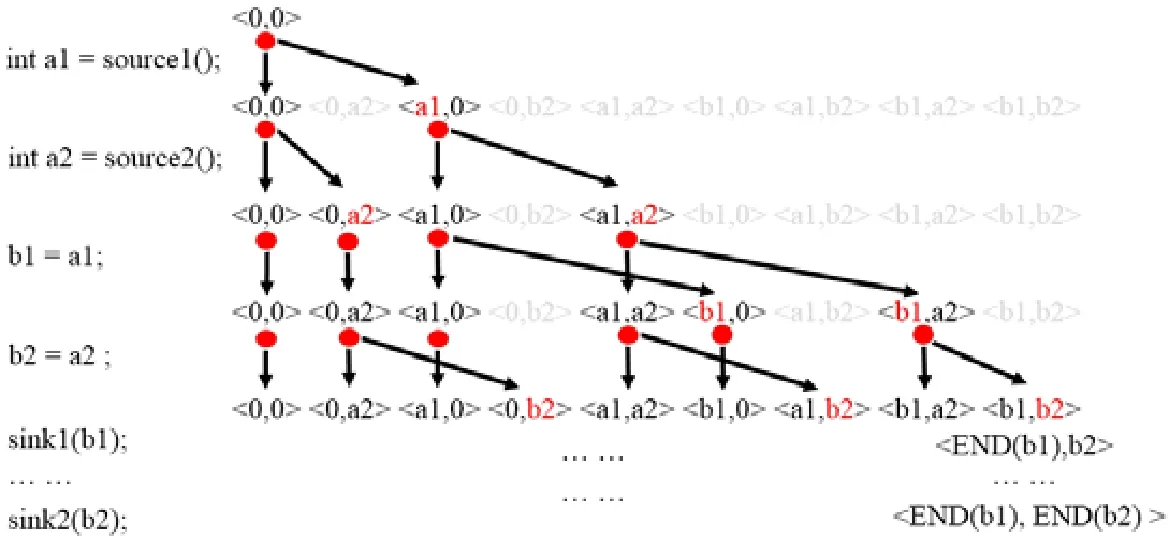
Fig.5 An example of multi-source binding data flow analysis(1)图5 多源绑定发生数据流传播示例(1)
上述数据流值形式保证其分析可以满足IFDS问题,从而对该问题的求解可以支持上下文敏感和流敏感的性质.具体来讲,我们提供了IFDS问题的扩展数据流方程相关的转移函数,即Normal-Flow函数、Call-Flow函数、Return-Flow函数、CallToReturn-Flow函数,表1给出了算法详细的伪代码.解释如下:令表示数据流值向量,用v表示中对应维度的元素,算法重用了传统的污点分析的转移函数(简称为 solo转移函数,算法中的soloNormal/soloCall/soloReturn/soloCallToReturn函数)用来表示对单一的v的污点变量独立的传播规则.由于solo转移函数已经在文献[18]中提供,这里省略.在 Normal-Flow函数中,对中的每一维度v进行遍历,如果v在当前语句n的计算,即Normal(v,n)的结果为soloRes集合,那么对于soloRes中每一个元素t,用t替换原中v生成新值,即.replace(v,t)来表示保证其他维度不变用新值t替换v生成新值.例如在图5右侧的传播:对于语句[b1=a1;],数据流值〈a1,a2〉中的a1 会根据 soloNormal函数产生a1 和b1,所以最终的函数会生成〈a1,a2〉和〈b1,a2〉.在 Call-Flow 函数中,需要对v中所有在函数调用中使用的变量都进行污点传播;对中每一维度元素,查找其是否在函数调用中使用,如果有使用,则用soloCall生成的新值进行替换.Return函数与Call函数类似,只是将参数映射转化为返回值的映射.CallToReturn与Normal类似,一种特殊的CallToReturn函数是对污点源和汇聚点的处理函数,例如,〈0,0〉表示IFDS框架的初始值(0值),污点源source1和source2为两个不同的源.对于污点源的计算,算法将从0产生对应位置的污点变量,如语句[inta1=source1();]将从〈0,0〉产生〈a1,0〉.算法的初始输入是待分析的多个源的集合,而其他不在这个集合的污点源并不会进行分析.图5右侧演示了左侧程序的传播过程.可见,算法能够有效地生成〈b1,b2〉向量,也就是之后可以绑定地触发sink(b1)和sink(b2)的污点变量.
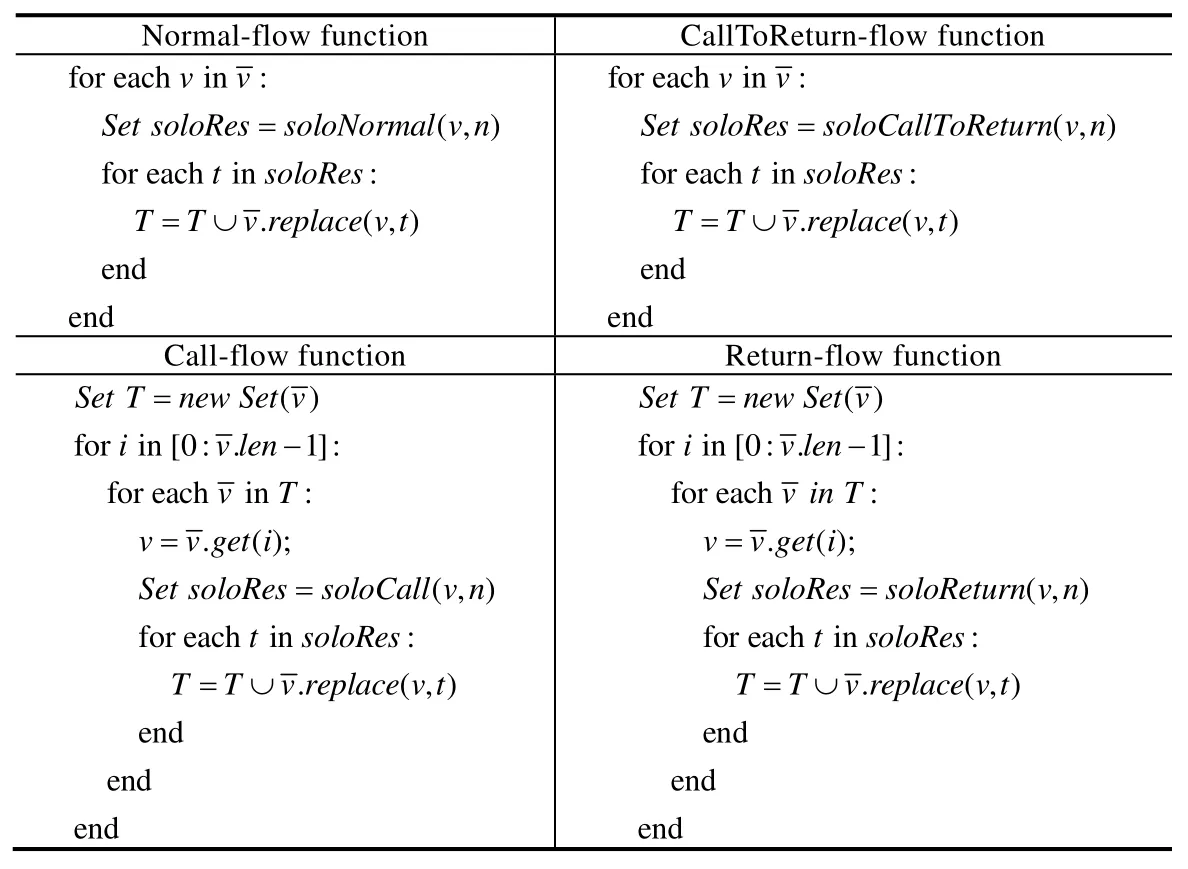
Table 1 Data flow transfer functions of multi-source binding analysis表1 多源绑定发生的数据流转移函数
该方法的主要特点就是能够区分出分支(IF)互斥的路径中污点变量的传播,如图6所示程序为例,source1()源的污点变量c1的传播路径是source1→a1→b1→c1.其中,如果变量无法传递到中间变量b1,自然无法传递到c1.如果考虑到分支的情况,分支Brb1和Brc1控制了污点源source1()进行传递的变量b1和c1,而分支Brb2和Brc2则控制对source2()传播的b2和c2.不难发现,Brb1和Brb2是互斥的.这会导致a1污点传播到b1而a2就不会传播到b2,反之亦然.所以对于可以触发sink(b1)的b1和触发sink(b2)的b2对应的源是不能绑定发生的.我们的方法可以有效地区分出此类情况.如图6右侧的具体数据流传递所示,传播算法可以正确地区分出具有互斥关系的分支.由最后的结果可见:结果向量集合中不会存在具有互斥(不会再一次执行中绑定发生)的污点变量,〈b1,b2〉,〈c1,c2〉,〈b1,c2〉,〈c1,b2〉是不会出现在结果中的.

Fig.6 An example of multi-source binding data flow analysis(2)图6 多源绑定发生数据流传播示例(2)
此外,我们还扩展了一个特殊的污点变量:END值(如图5所示),END(S)表示从S的源出发的污点变量已经流到sink().这是出于考虑:有些情况虽然一个源已经被sink触发了,但是为了整体的分析,还需要继续告知其他源该源已经发生的信息.例如图7的情况,源src1和源src2是可以同时发生的,但是在src1的污点变量还未能到达sink1()时,src2的污点变量就已经传播到sink2,且在func1内部完成了该传播.通过使用END数据流,可以有效地解决该问题,即在sink2之后,在src2源对应维度增加END变量继续传递.END值不同于触发sink但又可以继续传播的污点变量,因为END是可以跨越过程的.
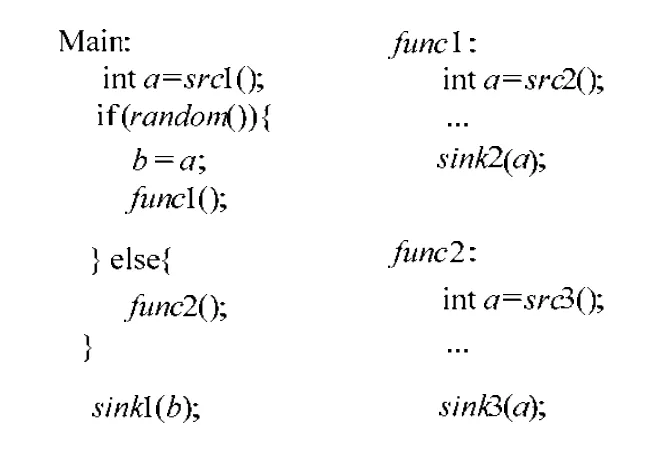
Fig.7 An example of multi-source binding data flow analysis(3)图7 多源绑定发生数据流传播示例(3)
3.3 多源问题的高效实现方法
由于IFDS求解算法的最坏时间复杂度是O(ED3),算法的效率与数据流域D的大小(即数据流值的个数)有直接关系.我们令传统方法(1-多源问题)的污点变量个数是Dsolo,多源问题中源的个数(向量维度)是k,那么最坏情况,代入得知,整个问题的复杂度是.由此可见,多源绑定发生问题算法的复杂度是k指数级别的.
为了能够高效地实现多源问题的分析,我们将该问题近似为:将k-多源问题转化为次的 2-多源问题求解.具体来讲,令k-多源问题中的所有源进行两两组合形成的集合为S,如果S中所有的2-多源问题都能满足(绑定发生),我们就近似认为k-多源问题能够满足.例如,对于结果为{getDeviceId,getMacAddr,getLineNum}的 3-多源问题,需要保证{getDeviceId,getMacAddr}、{getDeviceId,getLineNum}和{getLineNum,getMacAddr}这 3个 2-多源问题都满足.我们提出上述近似方法的原因是:首先,如果k-多源问题满足,那么S中的2-多源问题是一定都满足的(充分条件),所以该近似不会产生漏报.虽然反之不成立(不满足必要条件),即会产生误报,但是我们认为在隐私泄露检测问题中,k-多源问题绑定发生和其所有两两组合的 2-多源绑定都发生的危害是相近的.同时,我们在实验中发现,一般能够满足上述近似的k-多源问题,实际上有很大概率是完全满足k-多源绑定发生的,误报率很低.我们将在实验部分进一步阐述相关验证.
上述的近似方法导致数据流域个数D的值降低为,算法的时间复杂度是.一般情况下,污点源的个数k的值并不会太大,且为了保证完整的分析结果,控制流的边的个数往往不变,因此,k2×E的数量往往无法被降低,此时,减少Dsolo的个数将是本技术提高效率的关键.本节将提供一种减少Dsolo的个数的高效实现方法.
由于污点分析的本质是一个按需的分析问题,即污点传播只在污点源到汇聚点之间的路径传播,直观上,污点分析应该只针对该路径进行分析即可.传统的污点分析在未遇到污点汇聚点时并不知道最终的传播路径,因此需要保守地传播所有污点传播的变量.当扩展到多源绑定发生问题时,这种方法将产生大量的无用传播.如图8中的例子所示.来自source1的返回值a1会在第3行传递给f1、在第4行传递给t1,t1会在第11行传递给t2,t2在第12行触发 sink.这条完整的路径为a1→t1→t2→sink,在图8右侧路径中的红色节点即为该传播路径.然而对于f1来讲,他可以传递给f2、b、f3变量,但这些变量并不会触发sink,如图8右图中白色节点之间的路径.然而在多源绑定问题分析时,即与source2的返回值a2形成向量,会根据上节的算法生成〈f2,a2〉,〈b,a2〉,〈f3,a2〉的值.同理,这些值也不会到达sink进行触发.可见,这些值的传播实际上是没有意义的.当a2进一步在程序中传播时,则会带来更多的无用数据流值.基于上述观察,本节方法的核心思想就是消减这些无用的数据流值,只在可以触发sink的路径上进行多源分析,即在图中只传播红色节点变量(对于source1)和蓝色节点变量(对于source2).
为了维护污点源和汇聚点的路径信息,我们需要利用一种重要的数据结构[19]——数据流值的前驱节点(predecessor)和邻居节点(neighbor).所谓一个数据流值的前驱节点,是指直接生成该节点的数据流值.例如,图8中,数据流值t1的前驱节点是a1.数据流值的邻居节点是指,如果两个数据流值可在分支(循环)出口进行合并(merge),但它们分别来自不同分支,那么它们之间互为邻居关系.例如图8中第6行处的分支,第7行和第9行都会产生数据流值b.为了区分不同分支的值,令第7行处为b′,第9行处为b,那么在分支结束处会将b的邻居节点设置成b′.为了维护正确的污点分析路径,邻居信息是不可以被省略的,b′的前驱是f1,b的前驱是f2,它们分别代表不同的路径.有了上述的数据结构,就可以利用触发sink的变量进行回溯,求得完整的污点分析路径,进而在多源分析中重用.另外,为了在多源分析中使用这些路径信息,我们还需为数据流值扩展一个结构用于存储由〈useStmt,nextDatafact〉组成的集合.useStmt表示当前数据流值将要被使用的位置;nextDatafact表示在useStmt处产生的新数据流值.例如,t1在第11行生成t2,那么useStmt为line11,nextDatafact是t2.
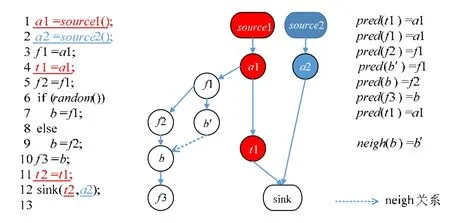
Fig.8 Efficient implementation method and data flow’s predecessor and neighbor图8 高效实现方法以及数据流值前驱和邻居示例
基于上述结构,多源绑定发生的高效实现方法具体流程如下.
(1)运行传统(1-多源问题)的污点分析,并通过FlowTwist[19]中的算法将数据流值的前驱和邻居进行记录;并得到触发sink的污点数据流值集合sinkSet.我们记该过程为SoloFlow.
(2)将sinkSet中的值加入工作集中;对于工作集中的数据流值D,得到D的前驱pred(通过getPredecessor方法),将D和产生D值的位置语句(通过getCurrentStmt得到)记录到pred中的〈useStmt,nextDatafact〉集合域中(使用方法SetUseStmt()).将D的neigh和pred加入工作集,迭代地对工作集中的数据流值遍历直到结束.具体算法如算法1所示.我们记该过程为PreProcess.
(3)执行多源绑定的污点分析:由于每一个数据流值已经在 PreProcess过程中记录了其后继的产生位置useStmt和后继的值nextDatafact,我们修改原Solo转移函数为只有在useStmt的位置产生新的数据流值nextDatafact即可.记该过程为MultiFlow.
算法1.PreProcess过程算法.
输入:sinkSet.
输出:sourceSet.


举例说明,对于a1 变量,经过 PreProcess 过程之后,a1 中〈useStmt,nextDatafact〉域的值是〈line4,t1〉.因此,该变量只在第4行处生成t1而不会在第3行处生成f1.同理,t1也只会在第11行处产生t2.如图8右侧红色部分是source1的传播路径,而白色部分则不会计算.可见,该方法可将大量的无用变量的传播进行消除,而对于过程间的数据流值,效率提高的效果将更加明显.此外,我们还利用了SoloFlow阶段产生的摘要边信息应用到上述方法进行优化,即当只有一个维度的污点变量被函数调用使用,并且当前该调用已经具有该值得摘要边时,我们直接使用其摘要信息产生其函数返回值.摘要边也是在SoloFlow中自然产生的,因此不会引入额外的开销.
上述方法的主要特点是:我们只需要执行 1次污点传播以及回溯地完成路径信息的记录(soloFlow和PreProcess过程),但是可以执行多次的多源绑定发生(MultiFlow过程)的分析.所以,对于一次污点分析的结果进行n次的绑定发生分析,其时间为T=time(SoloFlow)+time(PreProcess)+n×time(MultiFlow).对于一个k-多源问题,其近似计算方法的时间是.
4 实 验
4.1 实 现
为了验证本文技术的有效性,我们实现了一个原型系统 MultiFlow.MultiFlow的实现是基于 Soot和FlowDroid的:重用了FlowDroid面向Android特性构建的函数调用图,使用访问路径(access path)来保证域敏感的分析,在Soot的中间表示Jimple上完成多源污点分析.MultiFlow重用了FlowDroid的后向传播求解的别名分析,将一个污点变量别名的数据流值的前驱设置成该变量的前驱.由于Android系统是事件驱动的,MultiFlow设置一次多源绑定分析的结束为一次回调函数的结束.
在下文的所有实验以及第5节的应用中,我们统一使用表2所示的污点源和汇聚点.
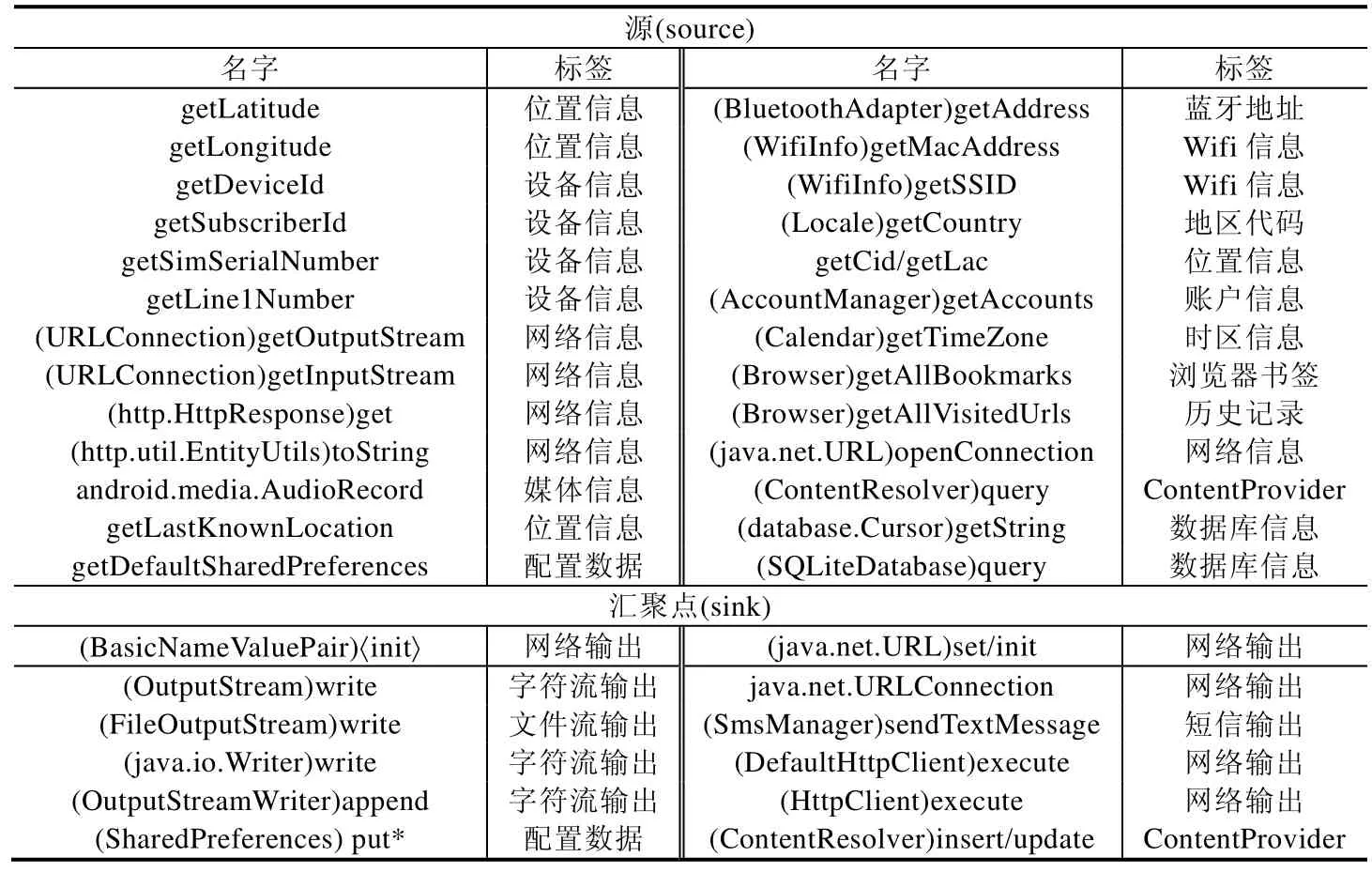
Table 2 Sources and sinks in MultiFlow provided by Susi表2 MultiFlow使用的Susi提供的源和汇聚点
表2所示的污点源和汇聚点由SuSi工具提供,由于排版受限,我们将源和汇聚点缩写成其函数名和方法名的形式,省略了参数和返回值类型,完整的名字请参考https://blogs.uni-paderborn.de/sse/tools/susi/.
4.2 效 率
本节将验证多源绑定技术的效率.本文的技术为传统污点分析技术精度的提升提供了可能,但是该技术也会引入开销的增加.因此,该实验的目的就是验证多源绑定发生技术与传统技术相比有多少开销.实验对比对象是传统的污点分析,此处我们使用FlowDroid的污点分析阶段.实验机器的配置是:64核Intel(R)Xeon(R)CPU E7-4809(2.0GHz)和128G RAM,为每一个Java虚拟机分配32G的内存.我们随机地从Google Play应用市场下载验证程序,并尽量选择其中可运行规模较大的程序.这里,我们选择 IFDS边的个数作为计算规模的衡量标准,最终的验证程序包含16个Android应用程序.由于我们将k-多源问题转化为2-多源问题,我们将验证多次的2-多源问题.此时,我们在1-多源问题(SoloFlow阶段)的结果中两两组合形成的集合中随机选择10对组合进行2-多源问题计算(如果少于10次,则将所有源进行两两组合计算).我们对验证集合的程序运行3次,随后记录其执行时间的平均值,表3是相关的实验结果.
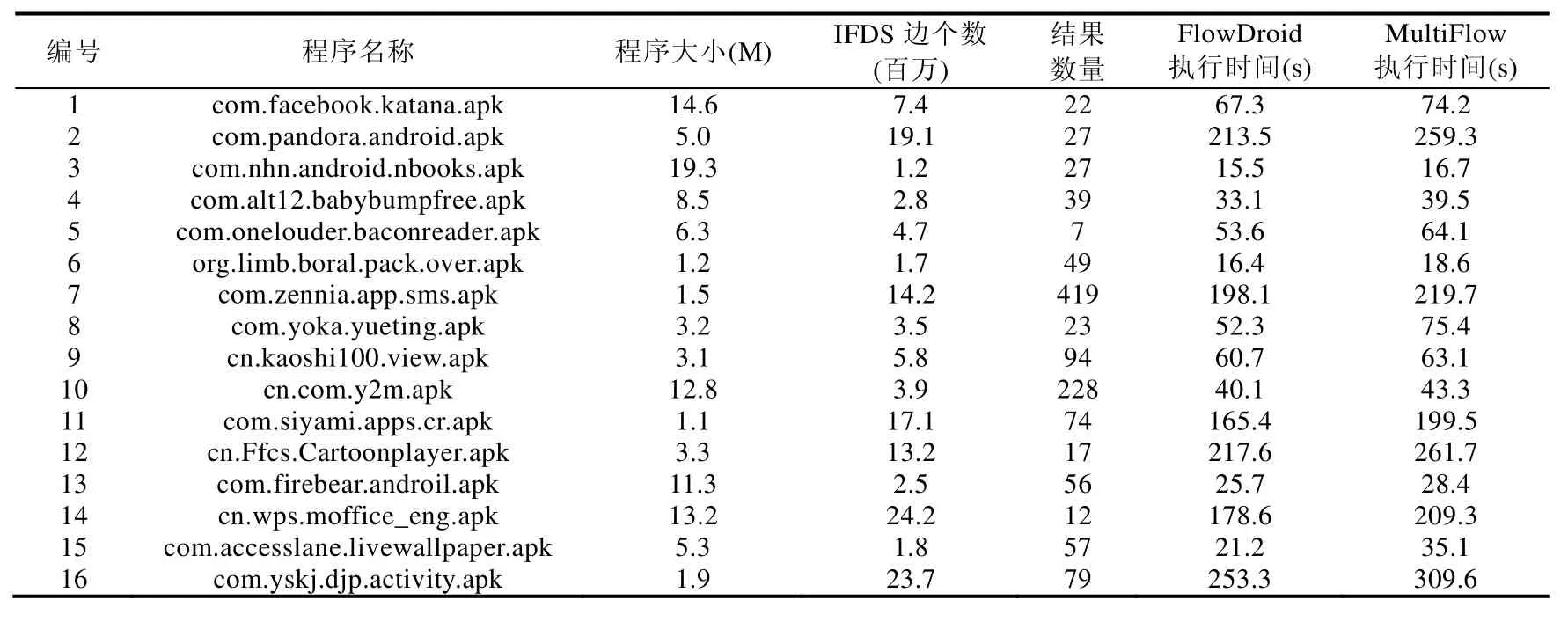
Table 3 Time overhead of multi-source binding taint analysis technique表3 多源绑定发生污点分析技术的时间开销
由实验结果得出,我们的方法与传统方法相比不会有较大开销.此外,由于通常多源分析会进行多次MultiFlow阶段的查询,我们验证了多源问题高效实现方法的各个阶段时间所占比例.如图9所示,由于SoloFlow阶段的时间即为1-多源问题的时间,所以我们的主要开销是time(PreProcess)+n×time(2-MultiFlow).
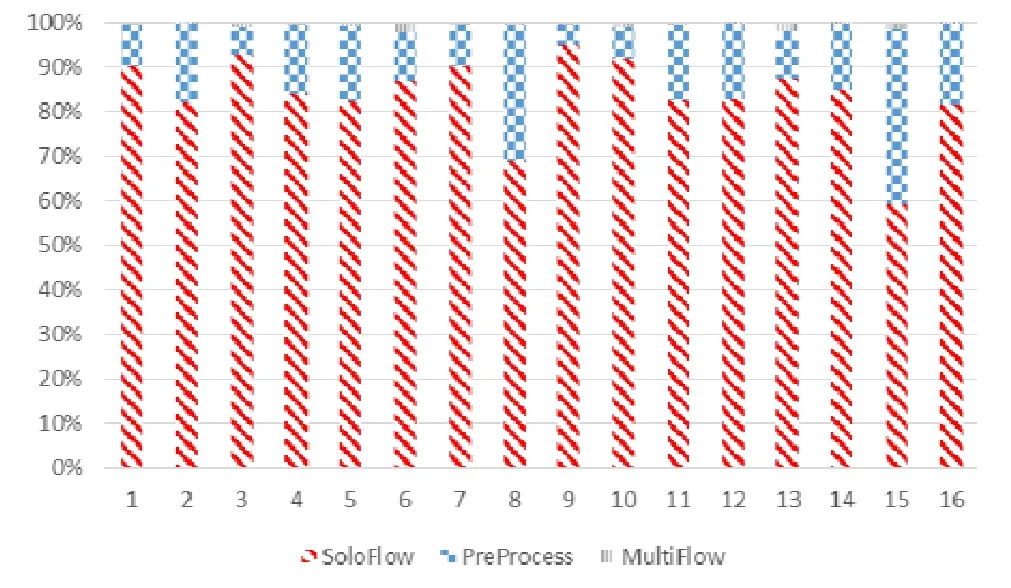
Fig.9 Percentage of each phase of the efficient implementation method图9 高效实现方法的各个阶段所占比例
从图9中可以发现,2-MultiFlow所用时间所占比例仅为1%(平均0.3s).这正说明了多源高效实现方法的有效性.因此,我们的开销主要消耗在 PreProcess阶段.也就是说,进一步对 2-MultiFlow进行多次查询对系统的查询开销影响并不大.综合统计,本文技术的平均时间开销(PreProcess阶段开销)为19.7%,这在静态分析中往往是可以接受的.
4.3k-多源问题近似方法验证
本节将验证将k-多源问题转化为次的2-多源问题的可行性.由于此方法并不会产生漏报,而可能产生误报,我们这里主要验证其误报率的大小,也就是说,验证次 2-多源问题满足的条件下,k-多源问题的满足情况.这里,我们选择在恶意软件库中挑选程序进行验证.我们在Genome库[17]中随机挑选50个具有隐私泄露问题的程序,利用 MultiFlow对其所有的污点分析结果两两配对进行 2-多源问题分析.我们使用反编译工具将其转化为可读的中间表示代码,对其结果进行人工验证.我们发现,这 50个程序中,所有通过近似方法满足的k-多源问题就是k-多源绑定发生的.进一步分析,如果近似方法不满足,则说明具有多个2-多源问题分别出现在了不同的分支下,如图10 所示的分支,多源对〈src1,src2〉,〈src1,src3〉,〈src2,src3〉分别出现在不同的分支下,而我们选择的这50个例子是没有这种复杂情况的.这也充分地验证了k-多源问题近似方法的可行性.
Fig.10 An example of thek-multi approximation method violation图10k-多源问题近似方法违反示例
5 Android应用隐私泄露检测应用
本节我们将探索多源技术在 Android应用隐私泄露检测中的应用.首先,本节验证了当前良性软件和恶意软件在多源绑定发生特性上的差异,从而提供区分恶意行为的依据;其次,本节验证多源技术相比简单方法的精确度提升;最后,本节提出了一种污点分析结果风险评级方法,检测人员即可从结果中恶意行为级别由高到低地进行检测,从而缩小了检测范围,提高了分析的效率.
5.1 良性软件和恶意软件多源绑定发生特性差异
本节将验证文章开始部分提出的假设:良性软件和恶意软件的多源绑定特性具有较大差异,从而可以利用其提高检测精度.实验使用统计方法进行验证,选择具有较大数量的良性软件库和恶意软件库作为验证集合.我们在应用市场中随机选择了2 116个程序作为良性软件库测试集合,其中,1 148个来源于Google play应用市场[16],968个来源于安智网应用市场[20].另外选择了 2 089个程序作为恶意软件库集合,其中,1 089个来自Genome库[17],1 000个来自 VirusShare库[21].最后,使用 MultiFlow 对这些软件进行多源绑定的分析,将所有SoloFlow阶段产生的结果之间的所有组合进行了分析,如果两个源可以绑定发生,我们就停止对这两个源(其他调用点)进行分析.
在良性软件库运行结果中,337个(占15.9%)应用程序(由于超时、反编译错误等问题)无法正常分析,443个(占20.9%)程序产生小于2条污点分析结果(绑定发生至少需要2个源).我们将这两类程序去除,最终可以进行绑定发生分析的集合包括1 336个应用程序,其中有382个(占能多源分析的28.6%)应用程序没有绑定发生的污点分析结果(虽然有大于1条的传统污点分析结果,但都不是绑定发生的).对剩下的具有绑定发生结果的954个应用程序进行统计分析,实验使用 Apriori算法[22]抽取频繁项集,其中,选择最小支持度(support)为 10%,即多源组合中出现次数大于整个集合的 10%(95个)的多源组合.最后统计结果按照支持度进行排序,见表4.在恶意软件库运行结果中,除去103个(占4.9%)应用程序无法正常分析和711个(占34%)程序产生小于2条的污点分析结果(恶意软库中还包含很多非隐私泄露问题的恶意问题[17],这种情况并不会产生污点分析结果),最终可以进行绑定分析的集合有1 275个.另外发现有237个(占能多源分析的18.7%)应用程序没有绑定发生的污点分析结果.最后对剩下的产生结果的1 038个应用程序进行统计分析,同样使用Apriori算法抽取频繁项集(最小支持度 10%),统计结果见表5.同时,我们还对比良性软件库中使用频繁的组合在恶意软件库中所占的比例(反之亦然),结果为表4和表5的最后一列.
从表中的结果可以发现,恶意软件和良性软件在多源绑定发生特性上具有明显的差异.具体来讲:
· 首先,在使用频繁度上,良性软件和恶意软件的统计结果差别很大.良性软件统计结果包含 16个组合,且其中有8个组合出现在恶意软件统计结果中;但恶意软件统计结果产生了38个组合,而只有6个组合也出现在良性软件的统计结果中.针对排名次序差异的比较结果更为明显,良性软件结果中出现频率最多的是{getLongitude,getLatitude}(47%),其次是{getDeviceId,getLongitude/getLongitude}(39%)和{getDeviceId,(java.net.URL)openConnection}(34%),这也说明了良性软件使用的都是用户常用的功能,即地理信息(经度/纬度)、地理信息和设备号、设备号和网络输入信息.我们发现,这些信息在恶意软件统计结果中也会出现,这充分说明了当前恶意软件经常需要伪装成一个正常的软件,所以同样会使用这些常用的功能组合.然而对比恶意软件结果,{getDeviceId,getSubscriberId}出现的次数是最多的(43%),而该对组合在良性结果中仅占 0.4%(4个),这反映出良性软件往往不需要 getDeviceId和getSubscriberId绑定发生,而恶意软件则出于盗取更多设备信息的目的将两者绑定发送.表5中的大部分组合都是此类的信息,它们是组合1、组合5、组合6、组合9、组合10、组合12~组合38,一共32组,它们出现在良性软件中的概率最大仅为2.5%.
· 其次,我们发现,恶意软件结果平均每个组合中源的个数更多,良性软件结果中只有组合5和组合10包含3个源(这里,getLongitude、getLatitude被视为1个源).而在恶意软件结果中,有18个组合包含3组以上的源,有5个组合包含4个以上的源,更特殊地,组合36包含了5个源,这也充分说明了恶意软件是需要更多的信息来完成恶意行为的.
· 最后,针对某些源,两个库之间的配对差异也很明显.例如,在恶意软件库中,对于(ContentResolver)query主要和getDeviceId绑定发生,(ContentResolver)query出现时,getDeviceId绑定发生概率为95%.而在良性软件库中,(ContentResolver)query经常和(database.Cursor)getString(数据库查询)源绑定出现,(database.Cursor)getString出现概率为 99%.这也说明恶意软件经常是发送用户账户信息结合设备信息来完成用户账户信息的盗取,而良性软件则是正常的数据库功能.

Table 4 High frequency results in benign App set表4 良性应用软件测试集合中出现频率高的结果
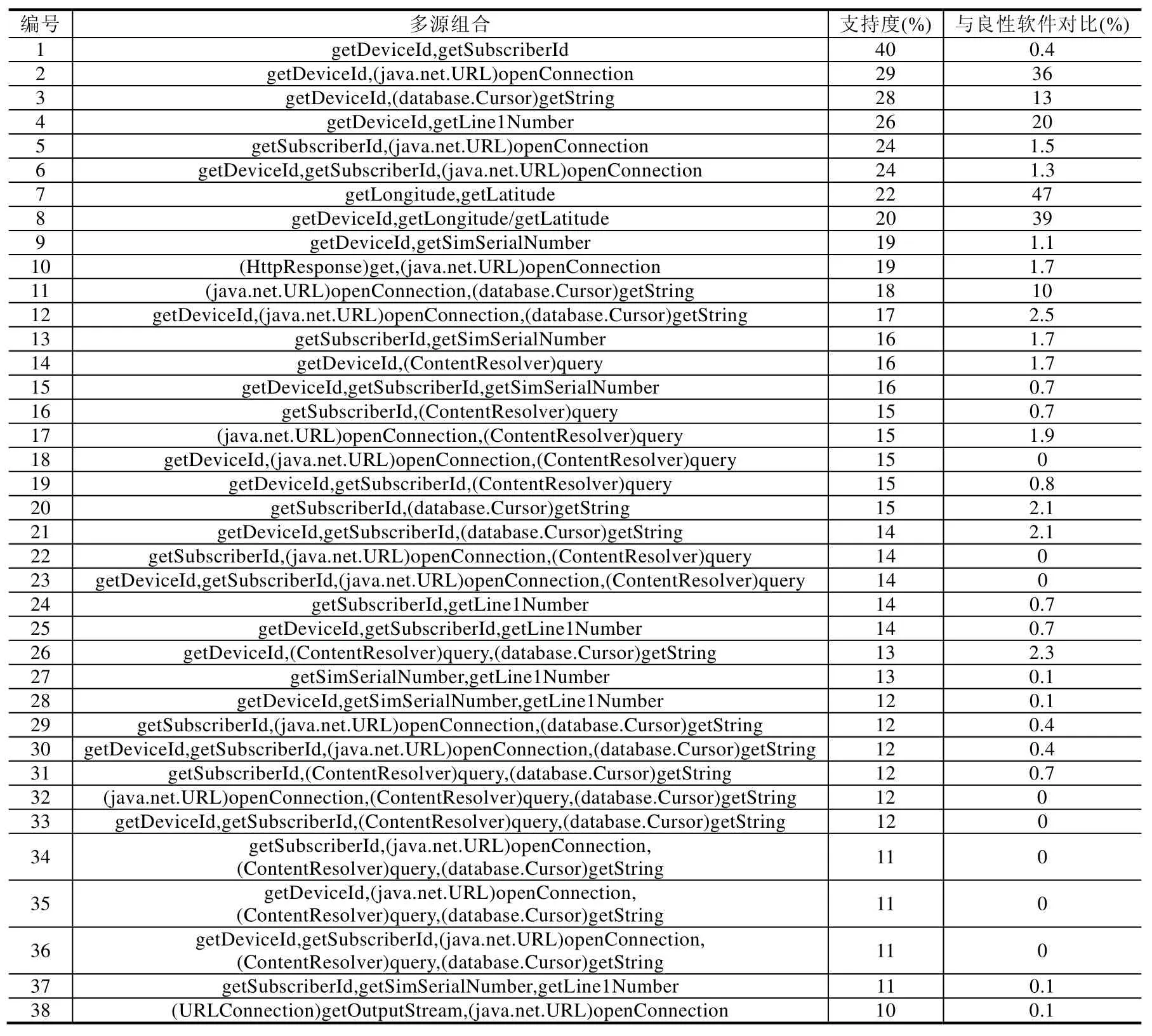
Table 5 High frequency results in malicious App set表5 恶意软件测试集合中出现频率高的结果
5.2 Android应用隐私泄露检测的精确度提升验证
本节所验证精确度的衡量标准是对良性软件的检查结果中 2-多源对的个数,2-多源对个数越少,该工具的精确度就越高.之所以使用良性软件的结果,是因为工具报告的良性软件中的污点路径并不是以隐私泄露窃取为目的的,在隐私泄露检测上,该工具产生了误报.当分析多源问题结果时,用户必须手工验证每个多源对结果是否是真实的泄露.多源对的数目越少,用户所检测的范围就越小,说明检测工具的误报就越少.而且当前没有准确标注恶意软件中污点分析路径的恶意行为的基准集合(benchmark),而良性软件中的路径是非恶意行为则是一个确定的事实.我们会在下一节介绍风险评级方法用以提高人工检测恶意软件中恶意行为路径效率的方法.
基于上述标准,我们统计了第5.1节中能够产生大于1条污点分析结果的良性软件,一共1 336个.分别使用MultiFlow和FlowDroid分析其产生的结果数目,对比图如图11所示.对于不考虑多源(图11中SOLO列)的情况,即将 FlowDroid中所有的源进行统计(这里,我们假设同一个源出现多个调用点等同于用出现一次源),此时FlowDroid得到3 935个源.此时,MultiFlow会产生3 472个2-多源对,其中,一共有2 827个非重复的源.对于多源的情况,由于当前 FlowDroid没有多源分析的功能,我们假设其产生的结果中所有源的两两组合等同于 2-多源分析的结果,此时,FlowDroid产生了5 890个2-多源的对,对比MultiFlow产生的3 472个对,可见MultiFlow与FlowDroid相比在多源计算减少了2 418个2-多源对,提升了41.1%的精度.
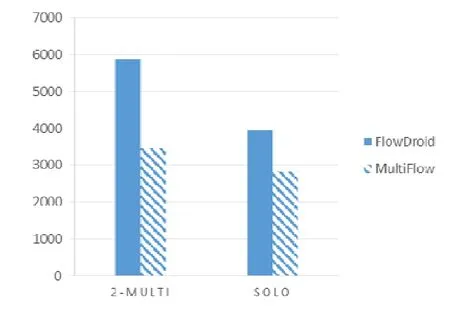
Fig.11 Result number comparision of MultiFlow and FlowDroid on multi-source analysis图11 MultiFlow和FlowDroid多源结果数量对比
5.3 污点分析结果风险评级
对污点分析的结果进行风险评级具有较大的意义.当前的工具[5-8]不能保证 100%检测精度的恶意软件分类,这难免使得检测人员需要手工地检查每一条污点分析结果.即便上述工具可以精确报告该软件具有恶意行为,检测人员也可能想知道具体是哪条路径泄露的信息,或产生什么类型的泄露行为等.如果对污点分析结果进行评级,程序员就可以从危害级别较高的组合到级别较低的组合分别进行检测,一旦确定高危险度的路径是恶意路径则不必继续分析,这使得待分析的范围缩小而提高了检测的效率.由于第 5.1节的实验证实了多源特性在恶意和良性软件间的差异,本节尝试利用该特性对污点分析结果进行风险评级.
本文的风险评级规则建立在3个启发式规则上.
启发式规则 1.如果一个污点源不与其他任何的源绑定发生,我们则认为该源的污点分析路径几乎没有恶意行为.我们相信,恶意软件在盗取了用户的敏感数据之后是需要进行恶意行为的,然而单独地盗取一种敏感数据往往是没有意义的,例如只盗取用户的密码信息而不知道用户名等.而对于良性软件来讲,它们往往针对一类固定的信息进行正常使用,例如手机设备号验证或者单一的物理地址使用等.
启发式规则 2.在大量的良性软件分析中,如果某些源的组合经常绑定发生,那么很可能这些组合是良性的.例如,地理信息中,经度信息往往和纬度信息绑定发生,如果只有经度和纬度的绑定发生,则认为其只是获取地理信息这一单一的行为.
启发式规则 3.在大量的数据分析中,如果某些多源组合经常出现在恶意软件中,却很少出现在良性软件中,那么这些多源组合的绑定发生是具有恶意性的.在表5中,一些组合正好满足这样的特性.例如组合 18和组合22,它们出现在恶意结果中的频率分别为15%和14%,然而在良性软件统计结果中出现次数为0.这也说明了在上一节的库中,只要包含组合18和组合22的都是恶意软件,而产生泄露的信息正是组合18和组合22.
基于此,我们将污点分析的组合分成4类级别,由高到低依次是级别IV、级别III、级别II、级别I.其中,级别IV是最严重的危险级别,其组合是根据规则3产生的,在本应用中,我们使用表5中的组合1、组合5、组合6、组合9、组合10、组合12~组合38作为级别IV的组合,这些组合出现在恶意结果中的频率高于10%,但是出现在良性结果中的频率低于2.5%.级别II的组合是由规则2产生的,在本应用中我们认为,如果一个应用程序产生的多源组合集合中只出现在表4,那么这些组合的危险度一般不高.级别I的组合是由规则1产生的,如果一个污点源不与其他任何的源绑定发生,则是级别I.最后,如果组合不是上述3种级别,则认为它是级别III.
进一步地,我们将上述的评级规则对实际手机软件进行应用,验证该规则是否可以有效地区分出不同类别的软件及其污点分析结果.我们直接将软件中包含的评级规则最高的级别作为其标签,利用其标签将所有验证集合的软件进行分类.我们的验证集合是第5.1节中所有能够产生1条以上污点结果的软件,其中包含1 336个良性软件和1 275个恶意软件.如果使用表5中的组合1、组合5、组合6、组合9、组合10、组合12~组合38对集合中软件进行检测,可以直接检测出685个具有级别IV组合的软件.使用规则2可以检测出953个包含级别II及其以下级别组合的软件.使用规则1可以检测出621个只包含级别I污点分析结果的软件,剩下的352个软件是包含级别 III及其以下级别组合的软件.图12为该结果的分布图,可见,包含级别 IV组合的软件占有26%,这也说明了我们的方法可以直接给出占较大规模的恶意结果(占实际恶意软件的66%),检测人员可以直接识别出26%个恶意软件中的具体泄露路径而不必分析其他路径.而级别II和级别I的结果分别占37%和24%,由此可见,该方法可以直接筛选出超过大半的良性的软件,一般情况下,此类软件的检测优先级较低.而对于包含级别III及其以下危险的软件只包含13%,且检测人员可以优先检查具有级别II的污点路径.上述的应用数据也直接说明了使用该评级标准可以区分出不同级别的软件,间接地帮助检测人员提高检测效率和精度.
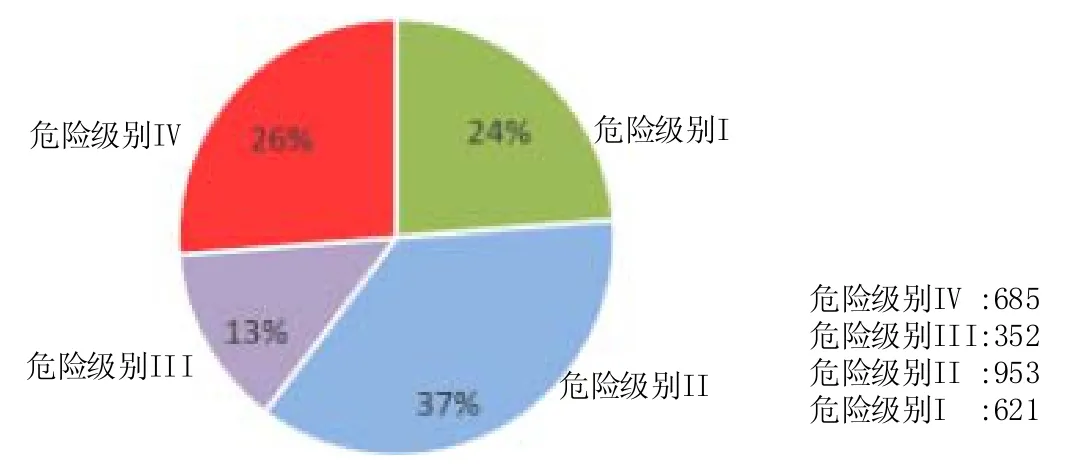
Fig.12 Distribution of App’s taint result risk ranking图12 污点结果评级分布
6 相关工作对比
污点分析技术是一类重要的程序分析技术,如今,大量的研究工作应用其解决计算机系统信息的保密性和完整性问题.Mino[23]在硬件级别上扩展了寄存器的标志位来实现污点分析,以进行一些基础漏洞挖掘,如缓冲区溢出.Privacy Scope[24]、Dytan[25]利用插桩工具 Pin[26]实现了针对 x86程序的动态污点分析.TAJ[27]工具利用混合切片的污点分析提供Java Web安全漏洞的检测.在面向Android安全的应用中,TaintDroid[28]是当前最流行的动态检测隐私泄露的工具,它使用多层次的插桩来完成污点传播.然而,TaintDroid必须在运行时对APK文件进行检测,这依赖于APK输入测试集合来触发敏感数据流,且TaintDroid会对Android系统本身带来一定的开销,每次Android版本更新之后,TaintDroid都需要重新进行定制.CHEX[29]尝试使用静态的污点分析方法检测智能手机组件劫持漏洞.FlowDroid[12]则提供了更精确的静态污点传播.DroidSafe[30]结合 Android Open Source Porject(AOSP)实现了与原 Android接口语义等价的分析模型,并使用精确分析存根(accurate analysis stub)将AOSP代码之外的函数加入到模型,在此基础上进行污点分析.IccTA[31]利用静态程序插桩和IC3工具[32]提供了敏感信息通过组件间进行泄露的检测方法.正如前文所述,上述工具虽然提供了基础污点分析方法,但是没有关注分析结果之间的相关性,也没有解决结果之间多源绑定发生的技术.
此外,利用污点分析对Android应用市场中恶意软件分类的相关工作也与本文类似.MudFlow[5]利用数据挖掘的方法直接使用FlowDroid的输出结果进行恶意软件分类,该工具针对2 866个良性软件的污点结果进行统计训练,其核心思想是,通过对良性软件产生的污点结果与当前待检测的 Apk文件的差异来判断其恶意性.Apposcopy[6]尝试利用污点分析结合组件的语义信息提供应用签名,之后,尝试利用签名匹配来检测恶意行为.Dark Hazard[7]使用特殊的分支条件下的污点分析触发路径作为机器学习的特征,从而检测恶意的隐藏敏感操作.虽然上述工具都是以提高检测精度为出发点,但是我们发现,这些方法都是直接使用污点分析的结果,并不会提高污点分析本身的功能.我们如果假设污点分析是一个黑盒,那么这些方法使用黑盒产生结果,然后在外部进行分析;而我们的方法是在黑盒内部提供更细粒度的分析.所以我们相信,多源污点分析是可以直接应用到上述方法中完成更进一步精度提升的.我们将在后续的工作中,将多源技术结合机器学习技术及更多语义信息来探索高精度的恶意软件分类方法.
7 总结与未来的工作
本文以当前污点分析检测Android应用隐私泄露的误报率高为出发点,针对恶意软件和良性软件之间的多源绑定发生特性差异来提高检测精度.我们提出了一种多源绑定发生的静态污点分析技术:在精度上,该技术具有上下文敏感、流敏感、域敏感等特性,并且可以有效地区分出分支互斥路径的情况;在效率上,提出一种按需的高效实现方法,降低了多次的多源问题计算的开销.我们的实验数据表明:即使在一次污点分析结果上进行多次多源问题分析,我们的执行时间也在可以接受的范围之内(初始阶段开销为 19.7%,进一步的多源分析时间平均为 0.3s).随后验证了多源绑定发生技术在隐私泄露检测问题中的应用,发现当前良性软件和恶性软件的多源绑定发生特性确实具有较大的差异.随后,我们验证了多源技术与简单方法相比的精度提升(减少多源对41.1%).最后提出了一种智能手机隐私泄露结果风险评级标准,应用此评级结果,可以进一步改善用户的检测的效率.
在未来的工作中,我们将把该技术与其他应用技术相结合,以提供更高的恶意软件检测精度.
· 首先,该技术可以结合更多语义信息,基于语义信息的恶意软件检测方法可以避免代码混淆技术带来的威胁,而多源绑定发生技术为更多语义信息支持提供可能性,一些有效的语义信息包括Android生命周期、特殊的回调函数、关键的API使用、GUI信息特征、特殊的分支触发条件等.例如,我们可以提取污点分析路径中的关键API作为语义信息基础,探索多个绑定发生源之间的API调用序列之间的关系.又如,我们可以探索在一个特殊的Button触发下,有哪些多源被绑定发生.如果这些源绑定发生行为与Button本身语义违反,则可以报告相关问题.
· 其次,我们将探索更有效的统计分析方法.目前,利用该方法在检测 Android安全问题上有很大的应用空间.例如,MudFlow尝试将待分析程序与良性软件间的差异作为特征,进一步利用 SVM 分类器进行检测.DroidADDMiner[8]利用了FlowDroid提取API数据之间的依赖关系作为特征向量进行恶意软件检测.多源方法在上述方法中的应用需要更有效的统计方法支持.另外一个值得研究方向是探索应用市场中不同的目录类别下的应用程序中多源问题的使用情况,因为相同类别下的 APK往往会有类似的使用结果,探索相关的多源特性违反情况可以提供保证软件质量和软件安全的特征.
此外,多源绑定的污点分析技术还可以用来对别名分析进行优化.非别名的污点传播是跟随程序的执行而传播的,然而对于别名的传播往往不能通过直接的计算可以得到.例如,FlowDroid尝试在遇到堆变量赋值计算别名时启动一个后向的别名分析求解器.此时,如果后向的别名传播和正向的变量在分支互斥的路径下,则会产生误报.例如,如图13所示,a和b别名的前提是IF语句执行了第5行的分支,而实际的污点传播则是通过第7行进行的.此时,我们可以利用多源绑定的技术对该问题进行精度提升(设置a为另一个污点源,判断a是否与source绑定发生).我们坚信多源技术是一类重要基础性的技术,未来将被更多程序分析领域应用.

Fig.13 An example of alias analysis optimization图13 别名分析优化示例
