基于云平台的多电网调峰调度自动控制系统设计
2019-03-05,,
,,
(广东电网有限责任公司 电力调度控制中心, 广州 510600)
0 引言
云平台由云服务器、云电脑及多种网络组件共同组成。其中,云服务器中包含了所有服务器端的运行软件,可在保持独立工作状态的情况下,向客户端服务器传输信息数据。云电脑中包含了所有客户端的运行软件,可以通过提升老旧配件综合处理性能的方式,使云平台的综合执行效力达到预期水平。基于云平台的电网调峰调度策略是保持均匀用电负荷的重要手段[1]。
在用电高峰时期,电网的实际负荷总量总是超过预期上限数值,在保持供电设备正常运转的情况下,需要投放一个或多个发电机组,来确保系统中的供电设备不会长时间保持超限度运行状态,这些被投放的发电机组即为调峰调度机组。简单来说,随着调峰调度机组的应用,电网同步调整运行执行水平得到有效保障。
为保证电网设备始终具备较高的执行效力,传统技术手段通过安装PC+可编程控制器的方法,确定系统中相关调峰数据总量,再引入PLC调节框架对这些调峰数据进行控制调配。这种方法虽然对调峰调度原理进行了深度的解析应用,但在调节过程中,不能保持调度运行模式具备较强的稳定性,且调峰控制数据的循环时间也总是随着电网数据总量的增加而延长。为避免上述情况的发生,引入云平台搭建理论,设计一种新型的多电网调峰调度自动控制系统,并通过设计对比实验的方式,突出新型系统的应用可行性。
1 多电网调峰调度自动控制系统硬件设计
新型自动控制系统的硬件运行环境包含多电网自动调度模块、调峰执行单元等组成环节,其具体搭建方法可按如下步骤进行。
1.1 云平台控制框架搭建
云平台控制框架是新型系统硬件运行环境的核心组成环节,主要包含自动控制机、多级调度模块、分层执行单元等多项组成部分,详细结构如图1所示。

图1 云平台控制框架结构图
分析图1可知,当多电网数据进入云网络平台后,会自动分为两部分。其中一部分进入系统自动控制机,在PC+可编程控制器的促进下,这些多电网数据改变原有排列顺序,并按照符合云平台抓取规则的方式进行定义重排。在数据节点保持稳定的情况下,完成重排后的多电网数据能够在短时间内进入系统数据库进行暂时存储,当客户端云服务器对多电网数据提出调用申请后,这些数据会根据既定拆分规则,进入下级处理模块,并在其中与调峰调度节点进行融合,使数据的完整度得到大幅提升。另一部分多电网数据分别进入自动调度模块、调峰执行单元中。这些数据自身携带大量的云平台操作信息,当客户端云服务器发出数据调用申请后,云平台会对申请指令中的成分进行分析,并提取其中的有效信息,讲这些信息传输至自动调度模块、调峰执行单元。对于直接进入上述两个操作模块的多电网数据来说,与数据相关调峰调度节点的调节功能得到弱化,数据自身的重要性与系统执行周期产生直接联系,更能体现多电网数据对于调峰调度自动控制系统的重要性。
1.2 多电网自动调度模块设计
多电网自动调度模块是云平台控制框架的重要组成环节。当云网络平台中的多电网数据达到固有限定额度时,一部分调峰调度节点通过系统输入设备进入自动调度模块中,并与该模块中的PID控制设备结合,以环形调节的形式,对后续进入模块的多电网数据的排列状态进行基础调整[2]。多电网自动调度模块以电子控制器作为核心搭建设备,且在其周围均匀分布大量的PID控制结构,为保证多电网数据的传输流畅性,核心设备、辅助控制结构间应始终保持平行连接的存在状态。多电网数据在进入自动调度模块时大都保持电信号的存在状态,而当数据总量超过模块承载上限时,模块的调度功能会受到一定影响[3]。为避免上述情况的发生,新型系统在多电网自动调度模块中增设一个具备舒缓功能的压力传感器,且该设备作为模块运行的辅助设备,既能在承接由系统供电设备提供的直流电压的情况下,适当吸收多电网数据,也能在模块保持脱机工作的情况下,利用自身的储存电压对多电网数据进行疏导、传输,使自动调度模块始终处于稳定的调节运行状态。整合上述搭建原理,可将多电网自动调度模块结构表示为图2。
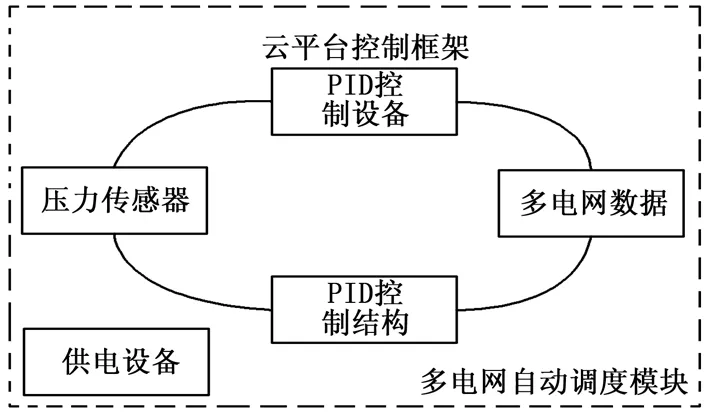
图2 多电网自动调度模块结构图
1.3 调峰执行单元设计
新型系统的调峰执行单元包含一个多电网数据收集装置和一个调制解调设备。其中,多电网数据收集装置以模拟信号作为核心处理对象。当系统数据库存储了一定数量的多电网数据后,调峰组件的执行效率会发生一定程度的下降。传统控制系统不具备专门的调峰执行单元,只能依靠PLC框架与调度指令结合的方式,逐渐提升多电网数据的门限存储值。这种方法虽然能在一定时间内使数据膨胀现象得到缓解[4-5],但随着系统运行时间的不断增加,这种传统方式的调节速度远远小于数据的累积周期。为解决上述问题,新型系统增设调峰执行单元,并在连通继电器的控制下,调节该模块单元的连通或断开。连通继电器具备一定的调度判断能力,当系统数据库中的多电网数据接近承载上限时,连通继电器由闭合状态转换至连通状态,并以此方式释放空白的调峰执行单元结构,使系统数据库的存储压力得到缓解。当这些数据全部被核心处理器消耗后,连通继电器由连通状态转换至闭合状态,令已释放的调峰执行单元结构继续保持空白状态,并以此达到调节系统运行模式稳定性的目的。具体调峰执行单元的设计原理如图3所示。

图3 调峰执行单元设计原理图
2 多电网调峰调度自动控制系统软件设计
在系统硬件运行环境的基础上,通过电网组态端设计、PLC调峰调度指令完善、控制数据循环流程设计三个主要环节,实现新型系统的软件运行环境搭建。
2.1 云平台多电网组态端设计
云平台多电网组态端通建立控制安全列表的方式,实现过对调峰软件程序的调度。当客户端对系统核心处理器发出多电网数据的调峰调度申请时,云服务器中的管理员程序会根据申请指令中可行性信息所占比重,确定控制界面初始登录密码位数,且这些加密数据会通过定义新权限的形式,传输至客户端云计算机中。这种新型的组态端搭建形式,在沿用传统MCGS平台端口的基础上,针对FC51节点、OB主程序等待调用成分进行关联分析[6]。当云平台中的多电网数据顺次通过MCGS平台端口时,调峰读取传感器会根据这些数据中所包含的电网地址信息,重新配置控制系统客户端的量程地址,并根据标定模块对地质信息的解析程度,判断多电网数据的原始存在状态,再利用调度解析传感器标注适合这些数据的测量值,并将这些处理信息以设定变量的形式传输至系统的自动控制模块[7]。通过这种组态端建立手段,多电网数据的运行极值得到有效控制,更有利于缩短调峰控制循环周期时间。具体云平台多电网组态端的组成成分如表1所示。

表1 云平台多电网组态端成分组成表
2.2 PLC调峰调度指令完善
PLC调峰调度指令可对多电网数据传输模块进行独立编程处理。当云平台OB模块中生成自动控制主程序后,系统中多电网数据进入组织传输运行状态,且相邻数据始终保持着基本的相应调用关系。随着调峰调度输出结果的不断运行,在每个指令后都会生成一个特有的控制标志,客户端服务器通过截取控制标志的方式,控制PLC调峰调度指令的生成速度,进而达到影响调峰控制数据循环时间的目的[8-9]。新型PLC调峰调度指令在编写过程中,可以组织自动化控制程序的加速运行,再利用控制传感器的解算传感器信号值,使通过该模块多电网数据的安全性得到大幅提升,实现对调度运行模式的改善处理。具体PLC调峰调度指令的编码完善过程如下:
PROGRAM _CYCLIC;
MBMaster_xx.enable:=1;
(* Insert code here *);
MBMCmd_xx.data:=ADR(LocalPV1);
IF iSpeedActual < iMinPowerSpeed THEN;
IF iSpeedActual > iMaxStartBackupGenSpeed THEN;
nSystemWarnWord4.1 := TRUE;
END_IF;
END_ACTION;
2.3 电网数据控制循环流程设计
电网数据控制循环流程以云平台控制框架搭建作为起始环节。当多电网数据经过云网络环境进入系统核心处理器后,控制框架中的自动控制机会将这些数据完整传输至自动调度模块和调峰执行单元,并在完成硬件运行环境搭建的基础上,将这些数据按照符合自动化控制系统抓取规则的方式进行排列[10]。当多电网组态端感知到数据成分的变化时,PLC调峰调度指令会根据数据库中现存数据的排列状态,改变编程代码对变量的定义方式,再由控制判定模块对多电网数据的完整性进行分析,实现一次完整的数据循环控制。根据上述原理完成基于云平台多电网调峰调度自动控制系统的搭建,详细数据循环流程如图4所示。
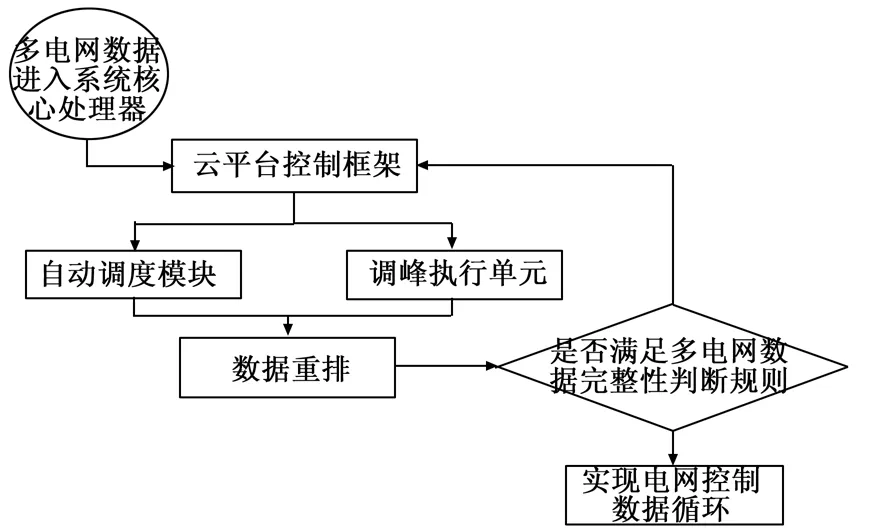
图4 电网数据控制循环流程图
3 实验结果与分析
为探究基于云平台多电网调峰调度自动控制系统的应用可行性,参照如下步骤进行对比实验。在保持云网络环境稳定的前提下,选取两台配置PC+可编程控制器的计算机作为实验对象,其中搭载新型控制系统的计算机作为实验组,搭载传统控制系统的计算机作为对照组。在保持其它实验因素不变的情况下,分别记录应用实验组、对照组系统后,调度运行模式稳定性、调峰控制数据循环时间的变化情况。
3.1 实验参数设置
为在实验过程中获得较为可信的运行数据,可按照表2对相关实验参数进行设置。
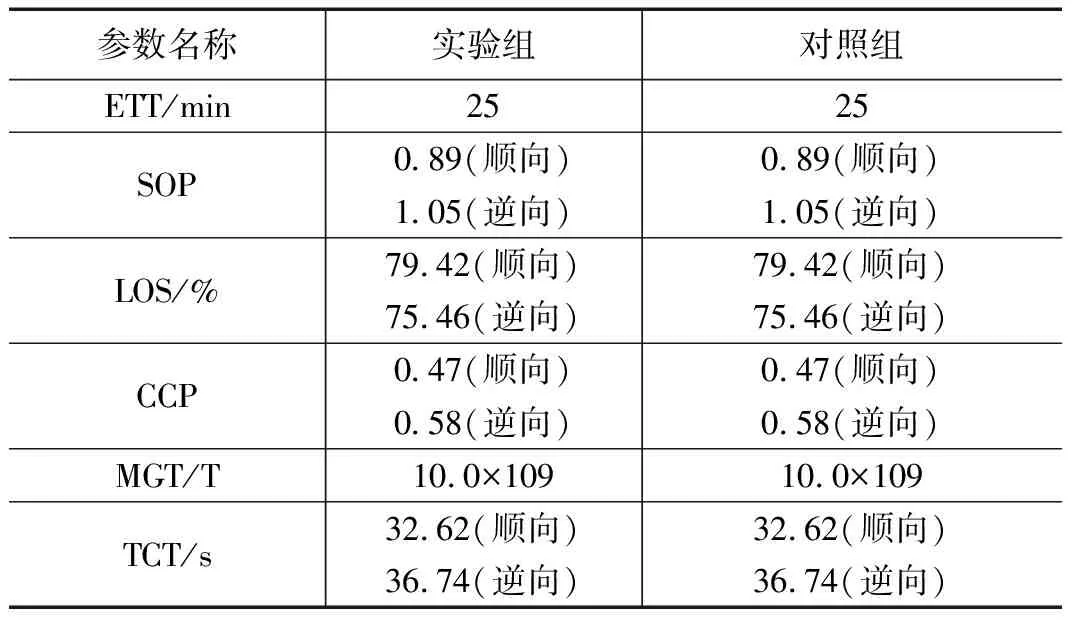
表2 实验参数设置表
表2中ETT参数代表实验时间、SOP参数代表调度运行参数、LOS参数代表调度运行稳定性上限、CCP参数代表控制循环参数、MGT参数代表多电网数据总量、TCT参数代表目的数据循环时间,为保证实验结果的公平性,实验组、对照组实验参数始终保持一致。
3.2 调度运行模式稳定性对比
为避免突发性事件对实验结果真实性的影响,本次实验分为两部分进行。在系统处于顺向运行状态、调度运行参数为0.89的条件下,以25 min作为实验时间,分别验证在该段时间内,应用实验组、对照组系统后,调度运行模式稳定性的变化情况;在系统处于逆向运行状态、调度运行参数为1.05的条件下,以25 min作为实验时间,分别验证在该段时间内,应用实验组、对照组系统后,调度运行模式稳定性的变化情况。具体实验对比情况如图5、图6所示。
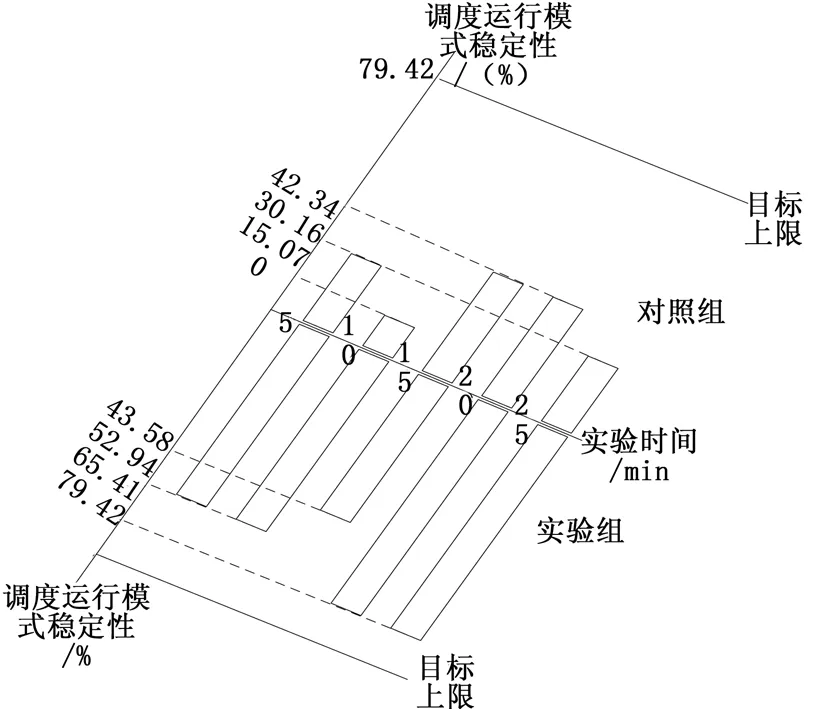
图5 调度运行模式稳定性对比图(顺向)
分析图5可知,在系统处于顺向运行状态、调度运行参数为0.89的条件下,随着实验时间的增加,应用实验组系统后,调度运行模式稳定性呈现稳定、下降、上升、稳定的变化趋势,实验时间处于20~25 min之间时,调度运行模式稳定性达到最大值65.41%,低于目标上限79.42%;应用对照组系统后,调度运行模式稳定性呈现下降、上升、稳定、下降的变化趋势,实验时间处于15~20 min之间时,调度运行模式稳定性达到最大值42.34%,远低于实验组。综上可知,在顺向运行情况下,应用基于云平台的多电网调峰调度自动控制系统后,调度运行模式稳定性能够提升23.07%。
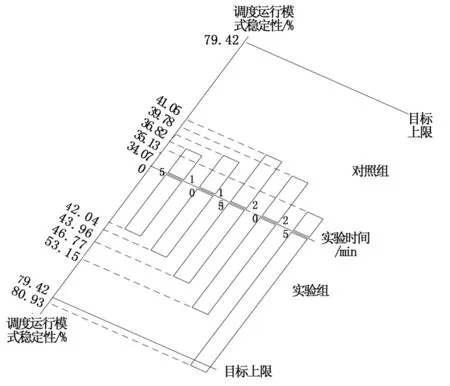
图6 调度运行模式稳定性对比图(逆向)
分析图6可知,在系统处于逆向运行状态、调度运行参数为1.05的条件下,随着实验时间的增加,应用实验组系统后,调度运行模式稳定性呈现逐渐上升的变化趋势,实验时间为25 min时,调度运行模式稳定性达到最大值80.93%,超过目标上限79.42%;应用对照组系统后,调度运行模式稳定性呈现先上升、再下降的变化趋势,实验时间为15 min时,调度运行模式稳定性达到最大值41.05%,远低于实验组。综上可知,在逆向运行情况下,应用基于云平台的多电网调峰调度自动控制系统后,调度运行模式稳定性能够提升39.88%。
3.3 调峰控制数据循环时间对比
为避免突发性事件对实验结果真实性的影响,本次实验分为两部分进行。在系统处于顺向运行状态、控制循环参数为0.47的情况下,以10.0×109T作为多电网数据总量,分别记录在达到该数据上限前,循环时间的变化情况;在系统处于逆向运行状态、控制循环参数为0.58的情况下,以10.0×109T作为多电网数据总量,分别记录在达到该数据上限前,循环时间的变化情况。具体实验对比情况如表3、表4所示。
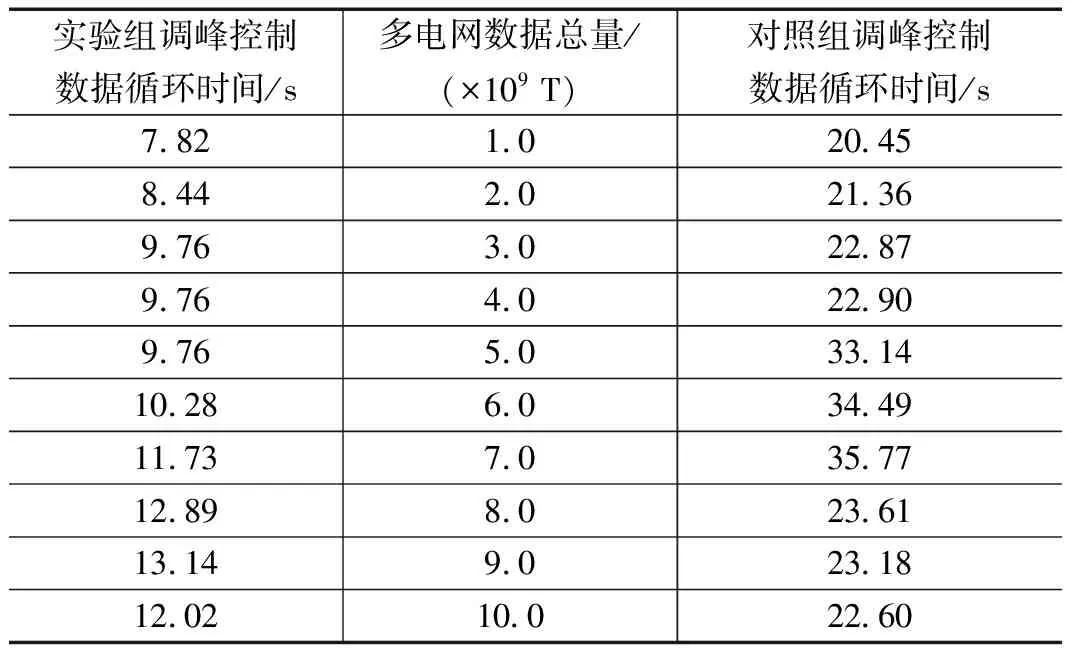
表3 调峰控制数据循环时间对比表(顺向)
对比表2、表3可知,在系统处于顺向运行状态、控制循环参数为0.47的情况下,随时电网数据总量的增加,应用实验组系统后,调峰控制数据循环时间呈现上升、稳定、上升、下降的变化趋势,电网数据总量为8.0×109T时,调峰控制数据循环时间达到最大值12.89 s,远低于目标上限32.62 s;应用对照组系统后,调峰控制数据循环时间呈现先上升、再下降的变化趋势,电网数据总量为7.0×109T时,调峰控制数据循环时间达到最大值35.77 s,高于实验组。综上可知,在顺向运行情况下,应用基于云平台的多电网调峰调度自动控制系统后,可以节约22.88 s的调峰控制数据循环时间。

表4 调峰控制数据循环时间对比表(逆向)
对比表2、表4可知,在系统处于逆向运行状态、控制循环参数为0.58的情况下,随时电网数据总量的增加,应用实验组系统后,调峰控制数据循环时间呈现上升、下降交替出现的变化趋势,电网数据总量为9.0×109T时,调峰控制数据循环时间达到最大值15.98 s,远低于目标上限36.74 s;应用对照组系统后,调峰控制数据循环时间呈现阶梯状上升的变化趋势,电网数据总量处于8.0×109~10.0×109T之间时,调峰控制数据循环时间达到最大值37.34 s,高于实验组。综上可知,在逆向运行情况下,应用基于云平台的多电网调峰调度自动控制系统后,可以节约21.36 s的调峰控制数据循环时间。
4 结束语
从设计理论角度来看,基于云平台的多电网调峰调度自动控制系统针对数据循环流程、平台组态端等环节进行改进设计,并通过更新硬件运行环境的手段,使多电网数据能够缩短在系统数据库中的存储时间,增强数据的循环使用效率。对于相关研究单位来说,将以这种新型的自动化控制系统作为起点,加强对电网调峰调度策略的更新力度。
