基于Word2Vec 的缺陷定位方法研究
2019-03-05万莹张光兰谭武坤
万莹,张光兰,谭武坤
(四川大学计算机学院,成都610065)
0 引言
随着软件规模和复杂度的不断增加,软件中出现缺陷是不可避免的。对于软件中的缺陷,开发人员通过对代码进行调试然后定位到真正的缺陷语句。然而,软件调试是一项既困难又昂贵的活动。美国国家标准与技术研究所在2002 年指出,软件缺陷每年给美国经济大约造成595 亿美元的损失[1],其中为了找到缺陷对软件进行测试和调试的活动占了30-90%的花销[2]。近年来,越来越多国内外的学者开始研究缺陷定位技术,并取得了许多不错的结果。现今对缺陷定位的方法主要分为两种:动态定位和静态定位。动态定位是通过程序执行测试用例,收集程序执行跟踪信息等进行定位,其中基于频谱的缺陷定位方法研究最多。静态定位是通过使用缺陷报告和代码进行各种形式的分析进行缺陷定位[3],研究者主要是使用基于信息检索的方法进行缺陷定位,该方法中与缺陷报告相似度分数越高的源代码文件越有可能含有缺陷。虽然动态定位方法准确率较高,但动态方法通常既耗时又昂贵,而静态方法比较易用,且它的即时推荐性使其具有吸引力。Ngyuen等人提出了BugScout[4],它使用LDA(Latent Dirichlet Allocation)方法进行缺陷定位,几个大型数据集的结果显示了其良好的性能。Zhou 等人[5]提出了BugLocator,它使用了TF-IDF 公式,并加入以前修复过的相似缺陷的报告。在对大约3400 个bug 的大规模评估中,BugLocator 显示出比BugScout 更强的性能。Ripon[6]等人提出的BLUiR 将缺陷报告以及源代码进行结构化处理后进行定位,得到的定位效果更好。但是传统的静态缺陷定位没有考虑到缺陷报告是用自然语言进行描述的,因此缺陷报告与源代码文件中的代码会有词汇不匹配的问题,如果考虑最极端的情况,源代码文件和缺陷报告没有共同的词,那么它们在标准TF-IDF 矢量空间模型中的余弦相似度为0。这也是导致静态缺陷定位效率低的原因之一。为了提高缺陷定位的准确率,本文提出使用项目相关文档,如用户手册、项目API 说明文档等进行训练获得Word2Vec 模型,根据Word2Vec 模型得到缺陷报告与源代码文件之间的相似度,解决缺陷报告与源代码文件之间的词汇鸿沟,在基于信息检索的缺陷定位方法上进一步提高了缺陷的准确度。
1 基于Word2Vec模型的缺陷定位
1.1 问题分析
目前静态缺陷定位方法的研究,如基于信息检索的缺陷定位主要是通过TF-IDF 对缺陷报告和源代码文件进行词向量化后计算两者之间的距离,以判断出含有缺陷的源代码文件。由于缺陷报告大多数是用自然语言进行编写的,而源代码文件是由编程语言组成,因此直接将缺陷报告和源代码文件进行词向量距离的计算,将会导致定位的准确率降低。如图1、图2 分别是与Eclipse 项目的缺陷报告和对应的缺陷源代码文件。
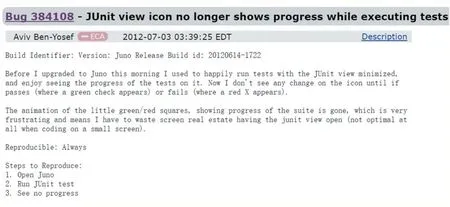
图1 Bugzilla系统上获取Eclipse项目的缺陷报告

图2 Eclipse项目源代码文件
图3 、图4 分别是Eclipse 项目的用户手册和API文档。从图中可以看出,图1 的缺陷报告中关于缺陷描述的关键词与缺陷的描述与真正含有缺陷的源代码文件PartServiceImpl.java 中的代码单词不相关,因此如果直接使用信息检索技术计算将会判断两者不相关。但根据图3、图4 中对PartServiceImpl.java 中该功能的介绍,可以判断BugID=384108 的缺陷报告与PartServiceImpl.java 中的某些方法在语义上是相关的。
为了提高传统静态缺陷定位的准确率,本文提出可以根据项目的API 说明文档,用户手册等相关文档判断缺陷报告和源代码文件之间的语义相关进行缺陷定位,通过上下文语义可以很好的解决自然语言与编程语言之间的词汇鸿沟问题。本文的整体框架如图5。

图4 Eclipse项目API文档
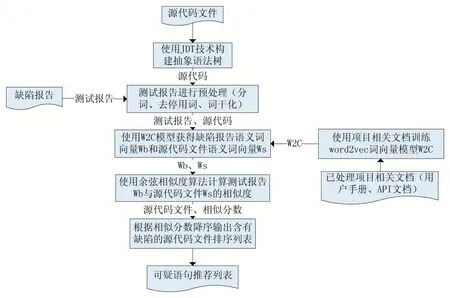
图5 基于Word2Vec缺陷定位方法的整体框架
1.2 Word2Vec模型简介
Harris[7]等人提出了分布假设,即在同一语境下的词往往具有相似的含义。这一假设引发了许多学者进行研究。Pantel 和Lin[8]将Mij 计算为wi 和cj 之间的点互信息(PMI),以衡量它们之间的相关性。Landauer和Dumais[9]提出通过“矢量语义空间”来提取文档与词中的概念意义,进一步分析文档与词之间存在的关系,即潜在语义分析(LSA)。近年来,人们提出可以使用神经网络模型直接学习向量以此来最优地预测上下文,这类方法称为“neural embedding”或“word embedding”[10]。这些模型被成功地应用于各种NLP 任务中[11-13]。在这些模型中,Mikolov 在2013 年提出的Word2Vec 模型[14]因其在训练过程中的简单和高效而广受欢迎。
Word2Vec 模型主要有两种训练模型:CBOW、Skip-gram。在文献[11,13]中,可以得到基于信息检索的一组自然语言处理任务中,Skip-gram 模型也明显优于其他传统方法,因此本文使用的训练模型选择Skipgram 模型。Skip-gram 模型是根据当前词来优化预测出它的上下文的概率,因此其目标函数[15]为式(1)。
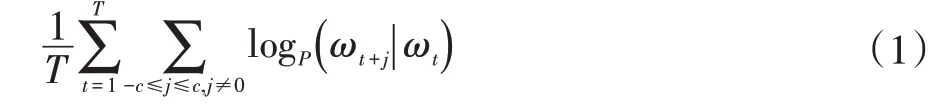
其中,T 是语料库单词的总个数,p(wt+j|wt)是已知当前词wt,预测周围词的总概率对数值。其条件概率函数p(c|w)的计算公式[15]如式(2)。
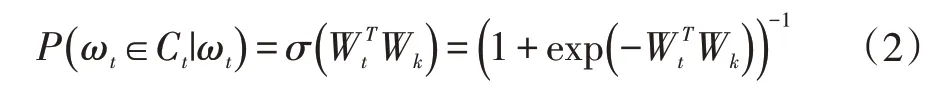
其中wt 是当前词语的词向量,wk 是任意词语的词向量。
本文使用用户手册、API 文档作为语料训练三个单层神经网络结构来建立Word2Vec 模型,通过Word2Vec 模型获得缺陷报告与源代码文件的词向量表示,由于词向量附加语义级别的信息,因此即使是两句话中有不相似或相同的词汇,只要二者在语义上大意相同,我们仍其识别为相同。Word2Vec 模型的优势在于其反映了文本的语义信息,即可以将语义相似的句子识别出来,而不像TF-IDF 算法一样需要有相同词汇才能判断出文本之间的相似性。通过Word2Vec 模型,我们得到了两文本的向量表示。
1.3 词向量的相似度计算
本文使用余弦相似度来度量文本之间的相似程度,即将每两个文本向量映射到空间中的两个线段,且线段均从原点出发,两条线段相交的夹角大小就可以反映出两个文本之间的相似程度。
给定经过Word2Vec 模型计算后的缺陷报告B={B1,B2,...,Bn}与源代码文件S={S1,S2,..,Sn},使用余弦相似度公式计算B 与S 之间的相似距离。余弦相似度计算公式如式(3)。

这是两个向量的内积,用欧几里德范数标准化。其WB 代表一个缺陷报告的词向量,WS 代表一个源代码文件的词向量。本文根据实验结果获得文本相似阈值,当最终的结果高于阈值时,则判断两个文本相似,若低于此阈值则认为这两个是不相似的,并将最终计算所得的余弦值按照降序输出源代码文件名,该源代码列表即为缺陷推荐列表,排名越靠前的源代码文件越有可能含有缺陷。
2 实验验证
本文设计的基于Word2Vec 模型的缺陷定位系统原型是以缺陷报告B 作为输入,从大量的源代码文件库中对所有的源文件S 进行排序,排名越靠前的源代码文件越有可能含有缺陷,本文使用PyCharm 作为实验过程中的开发工具。为了研究本文所提方案是否能提高缺陷定位发准确率,本文收集了Eclipse、AspectJ等多个开源项目数据来验证所提方法的有效性,各项目的详细信息如表1 所示。
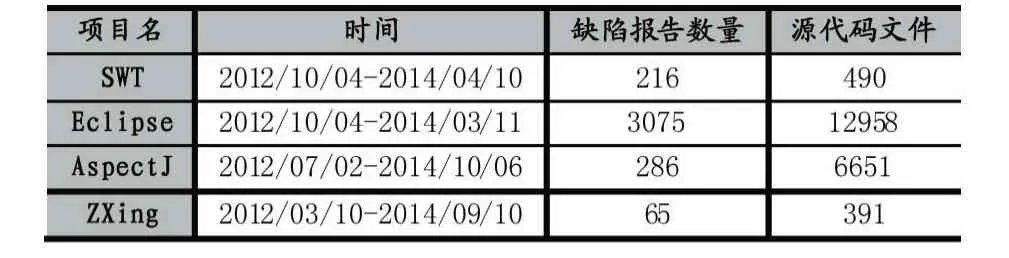
表1 实验项目的数据
在进行缺陷定位前,本文需要对缺陷报告文档、源代码文档以及其他与项目相关文档进行预处理。其中对源代码文件需要使用JDT 技术对其构建一棵抽象语法树(AST),该语法树的程序结构为:类名、方法名、变量名。本文在Bugzilla 缺陷跟踪系统中爬虫获取的缺陷报告xml 文档中含有许多字段,如BugID、summary、description 等,在本文中,我们主要使用缺陷报告的summary 和description 两个部分的文本内容。本文使用Python 的nltk 库对所有文档进行分词、去停用词、词干化等。处理好的项目用户手册、API 文档等的信息如表2。

表2 训练Word2Vec 的数据
本文使用与项目相关文档用户手册、API 文档等数据训练Word2Vec 模型。使用Word2Vec 模型获取缺陷报告与源代码文件的词向量,并使用余弦相似度计算公式计算两者相似度。
3 实验分析
本文使用目前静态缺陷定位研究中使用的评价标准平均准确率(MAP)和平均排序倒数(MRR)[6]来对本文所提方案进行评估。其中MRR 和MAP 值越高,说明缺陷定位技术的性能越好。
MRR 是第一个定位到正确的缺陷源代码文件位置的倒数的累加均值,它是通过正确的结果值在所有搜索结果中的排名来评估该方法的结果。因此MRR的值越高,就代表缺陷定位方法的性能越好。MRR 在本文中的计算方法为公式(4):

其中Q 是缺陷报告的数量,firsti表示第i 个缺陷报告为第一个含有缺陷的源代码文件的位置。
MAP 是指第一个定位到正确的缺陷源代码文件的准确率平均值,因此MAP 的值越高,就代表缺陷定位方法的准确率越高。MAP 在本文中的计算为公式(5):
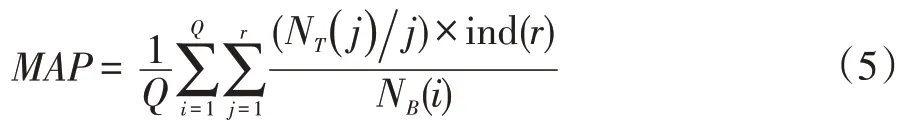
其中ind(R)表示位于第j 个源代码文件是否为真正的含有缺陷的源代码文件(ind(R)=1 代表为是,0代表否),NB(i)表示查找的第i 个缺陷报告的源代码文件数量。
本文用WBugLocator 代表本文所提的基于Word2Vec 模型的缺陷定位方法。缺陷报告与源代码文件的相似度分数在[0,1]之间,为了找到合适的相似阈值,本文将相似分数按每0.1 划分为一个区间,并统计每个区间找到的缺陷个数。结果如图6 所示。
在图6 中,可以发现相似分数大于等于0.75 时反馈给开发者的源代码文件排序列表中含有的缺陷最多,因此本文所提方法的相似阈值为0.75。
WBugLocator 经过大量的实验后,与BugLocator、BLUiR 两个工具进行比较的实验结果如表3。
与BugLocator、BLUiR 两个工具进行对比的MRR与MAP 的值如图7、图8。
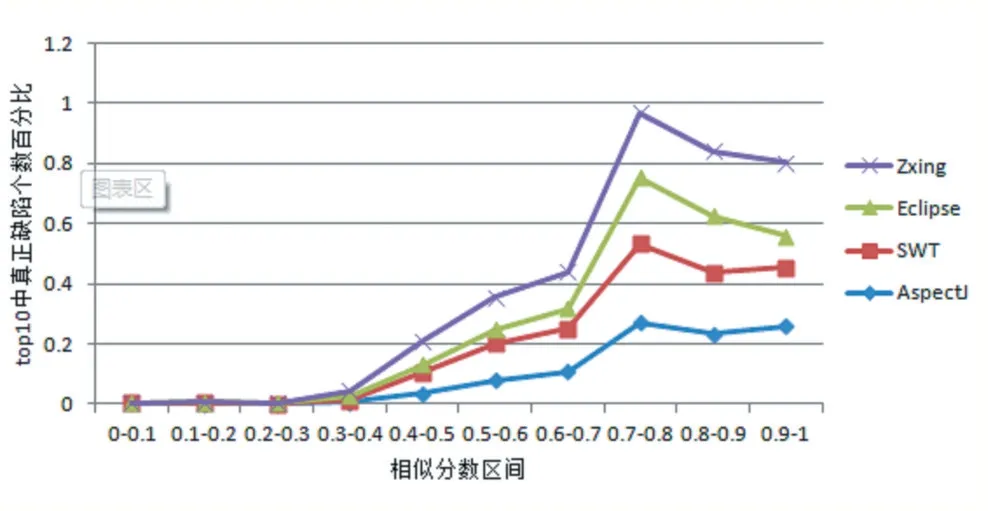
图6 缺陷报告与源代码方法的相似阈值

表3 WBugLocator 与BUGLOCATOR、BLUIR 工具对比

图7 WBugLocator的MRR值
实验结果表明使用BugLocator、BLUiR 方法和本文的WBugLocator 相比,如对于AspectJ 项目,使用WBugLocator 方法返回的与缺陷相关源代码文件位于Top1 的MAP 值为40%,而使用BugLocator、BLUiR 方法定位到的缺陷只有22%左右。并且对于返回的Top5 和Top10的文件,WBugLocator 方法计算得到的MAP 和MRR 数值也都高于BugLocator、BLUiR 方法的MAP 和MRR。因此整体来说,WBugLocator 方法在四个项目中的MAP、MRR 均高于BugLocator、BLUiR 两个工具,可见本文提出的基于Word2Vec 方法提高了缺陷定位准确性。
4 结语
本文提出了基于Word2Vec 模型的缺陷定位方法,该方法解决了缺陷报告与源代码文件之间词汇不匹配的问题,实验结果证明,本文提出的缺陷定位方法提高了定位准确率,对之后的研究具有一定的实际意义。下一步工作将研究该方法与动态缺陷定位方法相结合是否能进一步提高缺陷定位的准确度。
