基于数据挖掘技术的应答器报文分析方法研究
2019-03-04杨四辈
杨四辈
(北京全路通信信号研究设计院集团有限公司,北京 100070)
1 概述
我国高速铁路列车运行控制系统多采用CTCS-2级和CTCS-3级,应答器系统在信息传输媒介均发挥着至关重要的作用。
在实际的使用中,往往出现因为应答器报文错误而导致的高铁列车紧急制动等事故多次发生,严重影响列车运行效率,甚至危及旅客的生命财产安全。因此亟需对应答器报文有效性可用性等做出判断。然而,应答器数量庞大,其所包含数据信息数量庞大、种类繁多,面对如此海量的数据,从中筛选出不一致的信息,降低数据误差导致的不良影响,是一个急需解决的问题。
近些年来,计算机科学技术发展迅速,其处理分析数据的速度及能力高速提升,使得数据挖掘的作用得到更好发挥。
应答器报文数据信息又有复杂多样和隐蔽性的特点,把数据挖掘技术应用于应答器报文的数据分析,必将提高工作效率和计算结果的准确度,使应答器报文分析系统具有真正的实用价值。
2 应答器报文信息的国内外研究现状
对于应答器报文信息的研究从未中断,主要包括:朱晓航等充分研究基于FPGA的应答器报文编码和译码;邢毅等从应用层面,分析高铁列车运行控制系统应答器报文应用原则;刘长波等人提出一种采用仿真方法对应答器报文进行动态验证的方法:即通过使用计算机对联锁设备和列控中心设备进行仿真,验证应答器报文中的相关信息是否正确,这种方法在通号实验室普遍推广并为理论研究提供了良好的思路。但尚未有基于数据挖掘算法对应答器报文数据信息进行系统性的结构分析和报文内容一致性验证。
3 数据挖掘技术应用概述
数据挖掘(Data mining)是用人工智能、专家系统、统计方法和计算机数据存储的交叉方法在大的数据集中发现规律的计算方式。
数据挖掘过程的总体目标是从一个数据集中提取信息,并将其转换成可理解的结构,以进一步使用。而这一总体目标同对应答器报文信息的处理是一致的,所以可以使用数据挖掘技术进行应答器报文信息的处理。数据挖掘技术的算法有很多种,但是针对应答器报文信息的特点,要选择合适算法。
基于密度的聚类算法,是为了挖掘有任意形状特性的类别而专门设计的。此算法把一个类别看成数据集中大于某特定值的一个大区域。DBSCAN和OPTICS是两个典型的算法。
主要的聚类算法分类如表1所示。
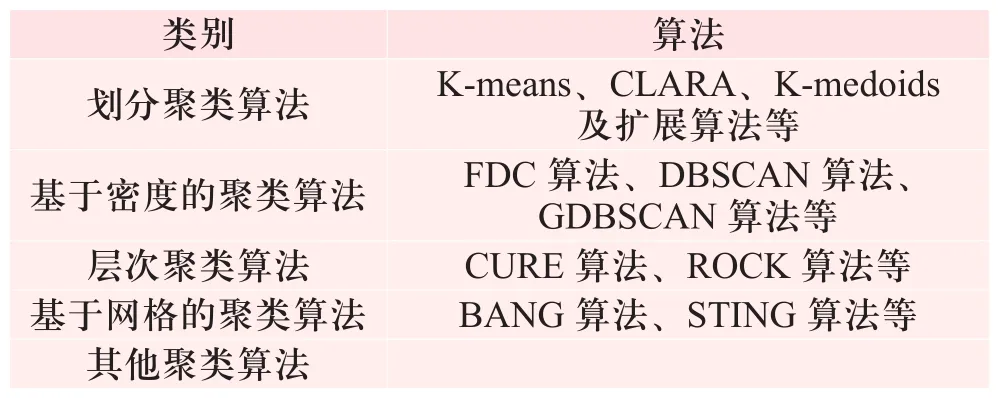
表1 常见的聚类算法Tab. 1 Common Clustering Algorithm
基于各种聚类算法的优劣,结合高速铁路应答器报文数据的信息特征,选取K-means聚类算法,进行应答器数据挖掘技术中的数据分析算法。
4 基于K-means的应答器数据分析方法简介
基于K-means聚类分析的应答器数据分析流程如图1所示,主要包含以下几个步骤。
1) 应答器原始数据的提取。
2) 应答器报文数据解析。
3) 解析后数据的分类存储与预处理。
4) 采用K-means进行聚类分析,得到分类结果。
5) 对分类结果进行数据一致性分析,判定应答器报文数据的一致性。
5 应答器报文数据分析系统的设计及实现
5.1 应答器报文数据分析系统的功能分析
应答器报文数据主要功能需求及C/S结构的基本特征,应答器报文数据分析系统界面布局如图2所示,包括系统工具栏区、报文数据显示区、解析数据显示区和日志及报警信息显示4部分。
5.2 应答器报文数据分析系统软件的功能实现
虽然应答器数据量大,但是其解析数据拥有结构清晰的特点,对于使用大数据分析的方法,难免大材小用,且不易于工程化的设计和实现,因此可以考虑采用小型化、轻便的数据分析工具来实现基于K-means的应答器数据分析。
应答器报文读取功能模块是整个应答器报文数据分析系统的基础,其主要完成应答器报文数据的正确、高效读取,并注入整个系统平台,为平台的正常正确运行提供基础数据支撑。应答器报文读取模块的程序框架,如表2所示。
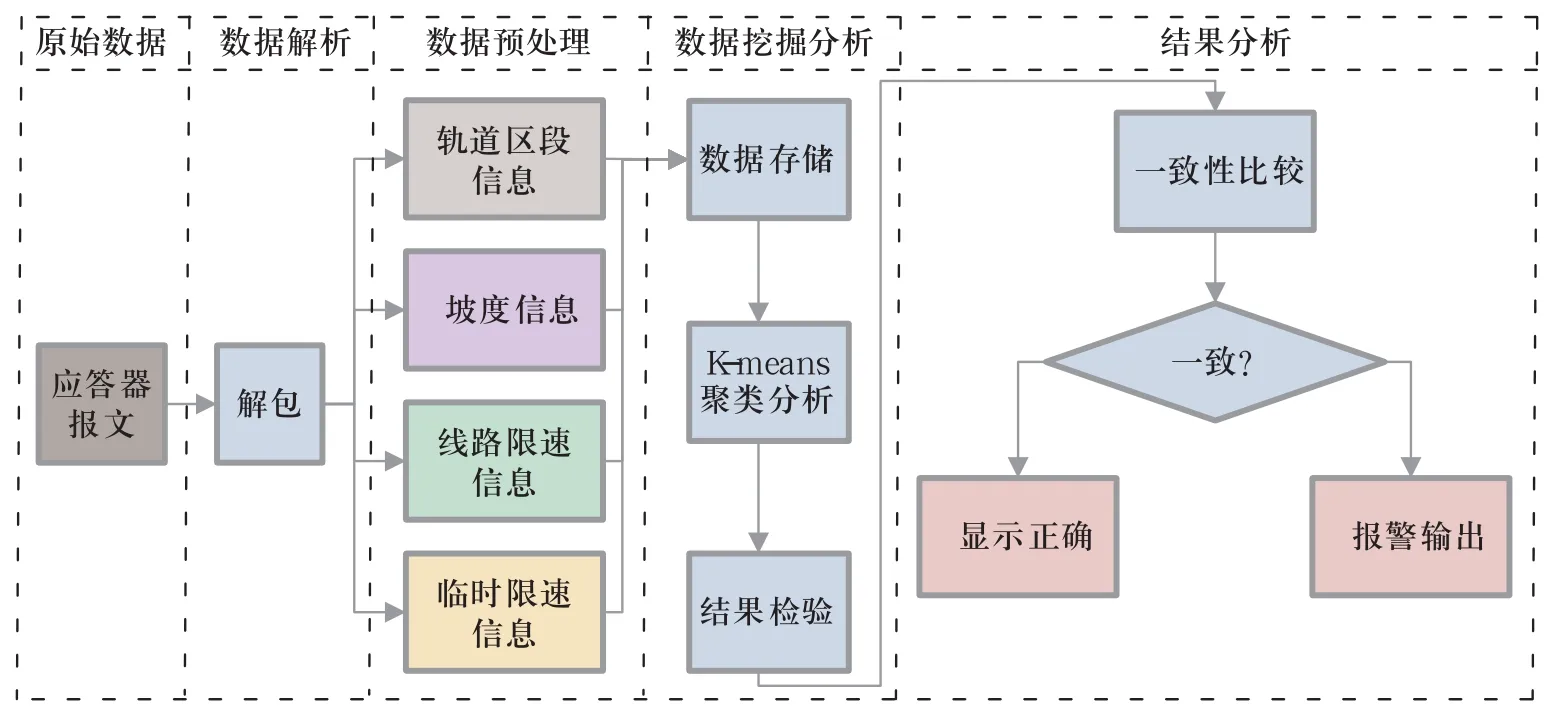
图1 基于K-means聚类分析的应答器数据分析流程Fig.1 The Balise data analysis process based on K-means
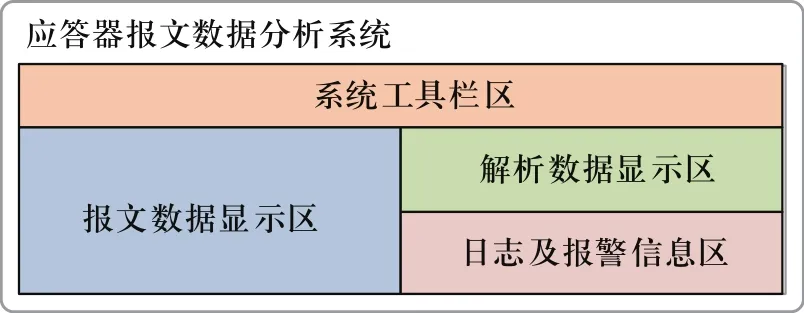
图2 应答器报文数据分析系统界面布局Fig.2 The operation interface of balise message data analysis system

表2 应答器报文读取模块的程序框架Tab. 2 Program frame of the balise message reading module
应答器报文解析功能模块是整个应答器报文数据分析系统的一个核心模块,其主要完成应答器报文数据解码功能,主要包含应答器原始数据进制转换、数据位数检查、应答器报文帧头解析、用户信息宝解析等功能,其程序框架,如表3所示。
5.3 数据验证与结果分析
结合应答器报文读取报文、报文解析、数据分析、数据显示等主要功能需求,实现界面包含系统工具栏区、报文数据显示区、解析数据显示区和日志及报警信息显示4部分,集应答器报文解析、报文组包、基于数据挖掘的应答器报文分析、分析结果显示于一体的应答器报文分析系统,系统应答器报文解析界面如图3所示。
应答器报文数据分析系统界面需清晰友好、操作简单,能够完全实现报文读取报文、报文解析、数据分析、数据显示等功能,在一定程度上具备系统的准确性、互操作性、依从性、安全性以及功能要求等。

表3 应答器报文解析模块的程序框架Tab. 3 Program frame of the balise message parsing module
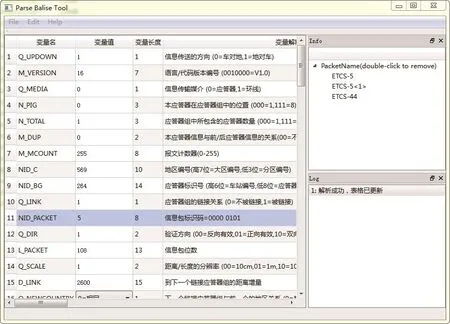
图3 应答器报文数据分析系统运行界面Fig.3 The operation interface of balise message data analysis system
应答器报文数据分析系统进行应答器数据分析,相比于以往的人工数据校验工作,效率大大提升,并且准确率也得到保障,降低了因人为疏忽导致的数据校验误差。
如图4所示,通过对国内某高铁线路的应答器信息进行数据解析、存储,并经过基于K-means数据挖掘算法的分析得到全线的分相区信息、坡度信息、固定限速信息、应答器链接信息、特殊轨道区段信息、大号码道岔信息等分类簇,并且分类簇的数据具备相同的属性,从而为进行不同应答器描述的同一信息的一致性分析奠定数据基础。
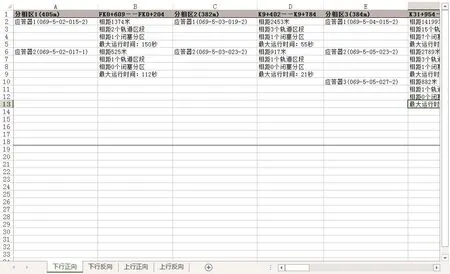
图4 分相区信息聚类分析结果Fig.4 The results of clustering analysis of the phase separation zone information
经过应答器报文数据分析系统对图4所示的全线分相区的分类汇总信息,进行数据的一致性分析,可以很直观的得到,全线对于同一分相区的信息虽然在不同的应答器中进行描述,但是对于同一分相区信息的描述与高速铁路应答器应用原则的要求一致,并且同一分相区的位置(反映到数据中就是公里标)一致,如图5所示,描述分相区信息的曲线完全重合。
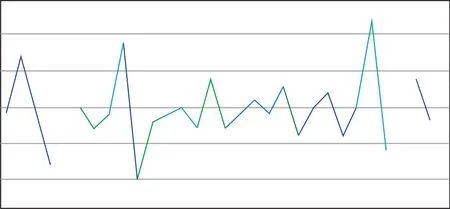
图5 分相区信息一致性分析结果Fig.5 The results of consistency analysis of the phase separation zone information
同样,以该高铁线路某区间的坡度信息为例,其聚类分析后的数据分类簇如图6所示,其中可以看到对于某段坡度信息的描述,少则在某一组应答器单独描述,多则可以达到12个应答器组之多,可见如果对于该线路所描述的所有坡度信息进行人工的数据一致性分析,是非常庞大的工作量,需要耗费相当大的人力和物力。但是应答器报文数据分析系统实现对于数据的查看、分析和辅助完善更加便捷、高效。
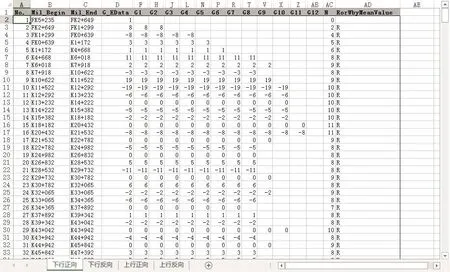
图6 坡度信息聚类分析结果Fig.6 The results of clustering analysis of the slope information
经过本文所研发的应答器报文数据分析系统对图6所示的全线坡度的分类汇总信息,进行数据的一致性分析可以很直观的得到,全线对于同一坡度的描述虽然在不同的应答器中,但是对于同一坡度信息的描述有5处描述的不一致,如图7所示。
1) 有2组应答器对于同一坡度位置的坡度信息描述不一致的4处。
2) 有3组应答器对于同一坡度位置的坡度信息描述不一致的1处。
6 总结
以地面应答器报文验证需求为出发点,结合应答器的本身特性,对应答器应用进行分析,提出基于数据挖掘的应答器报文数据分析方法,对高速铁路列控系统的应答器报文验证工作有一定的参考价值和实用意义。
但也存在不足:实现算法依个人观点总结所得,算法较简单,究其原因,是实现思路、验证方法过于简单,未能使检测结果满足所有的现实情况所致。其次对应答器报文的验证只局限于地面设备,未能加入车载接受信息过程对整个测试过程的影响。
7 未来工作展望
我国对于应答器系统的研制起步相对较晚,类似于应答器报文数据验证等很多操作还需人工手动完成,时间长且工作效率低。在大量的应答器报文信息编制工作及保证应答器报文数据正确性、安全性方面仍需进一步改进。因此开发全自动化的应答器报文数据验证工具,通过对应答器报文进行解码译码验证数据包格式正确性,并与工程数据表对应数据比对,以检验其内容的正确性。为后续应答器报文数据分析提供可靠真实的依据。
