子字粒度切分在蒙汉神经机器翻译中的应用
2019-02-25侯宏旭吉亚图武子玉白天罡
任 众,侯宏旭,吉亚图,武子玉,白天罡,雷 颖
(内蒙古大学 计算机学院,内蒙古 呼和浩特 010021)
0 引言
蒙古语是中国少数民族蒙古族的语言,也是蒙古国的官方语言,所以蒙汉机器翻译对于民族团结以及中蒙交流都有着重要意义和价值。近年来,统计机器翻译[1]的发展进入瓶颈期,深度学习[2]成为研究热潮,神经网络机器翻译成为机器翻译研究的重要方向。
蒙古语属于黏着语,其构词规则如图1所示,一个蒙古语词由一个词根与多个词缀组成。蒙汉机器翻译存在双语对齐语料不足、资源稀少等问题。这使得数据稀疏问题更加凸显。因此本文想要通过对蒙汉双语使用子字粒度的切分,来缓解数据稀疏问题,以提升翻译质量。与此同时,子字粒度切分缩小了双语词典的大小,降低了神经网络模型的计算复杂度,可以大大减少训练周期。

图1 蒙古文词汇构成
本文使用CWMT2009[3]和CWMT2017蒙汉双语语料,并在基于循环神经网络(recurrent neural network,RNN)和卷积神经网络(convolution neural network,CNN)的蒙汉神经机器翻译系统上进行了子字粒度切分的多方面对比实验。
1 蒙汉神经翻译模型
1.1 RNN模型概述

1.2 CNN模型概述
在本文中,CNN系统采用Gehring等提出的架构[8-9]的开源CNN模型。该模型依然是由编码器、解码器和注意力机制三个部分组成,如图2所示,其中编码器和解码器由多层卷积层组成,且每个卷积层之间加入线性门控单元(GLU)[10]和一个残差连接[11]。该模型利用CNN卷积核获取局部信息,并通过增加CNN卷积层数来获取长距离依赖信息,因此编码器和解码器均为多层的深层CNN,每层解码器配备一个注意力机制。
2 子字粒度切分
在机器翻译任务中,对语料的切分是语料预处理过程中非常重要的一步。句子所包含的特征,由多个局部特征共同组成。而在语料预处理阶段,句子切分粒度越大,切分结果越能够保存更完整的局部特征,但是加重了数据稀疏问题;切分粒度越小,其包含局部特征越少,但是数据稀疏问题会得到缓解。尤其在双语资源相对匮乏的蒙汉机器翻译任务中,切分粒度的把控尤为重要。
子字粒度切分是将句子切分成介于词和字之间的粒度大小,这样的做法可以在一定程度上保留局部特征,同时尽可能减小粒度,从而缓解数据稀疏问题,提高翻译效果,同时缩小词典规模,减少训练周期。
2.1 子字切分算法(BPE)
Sennrich等人[12]在2016年提出了一种使用Byte Pair Encoding(BPE)编码[13]来处理文本切分粒度的方法。
BPE算法的基本思路:首先将语料以最小单元(蒙古文是指蒙古文字母,汉文是指汉字)切分;然后统计语料中所有相邻最小单元组合出现的频数;再找出频数最大的组合;将最大组合合并后替换语料库中原来组合;循环上面操作。
传统的中文分词法是利用一个第三方词典切分句子,而BPE算法切分子字,是通过统计自身语料中词频,获得自身的词典,再根据词典切分句子。相较于传统分词处理,首先切分使用的词典来源于自身训练集,因此在对测试集的切分粒度也会与训练集保持一致,从而间接减少集外词的数量;更重要的是,BPE允许出现多粒度切分,即词频高的词会被切分成词,词频低的词则会被切分成字,这样可以在保留一部分局部信息的前提下,缩小词典大小,间接缓解了数据稀疏问题。
BPE算法有两种应用方法:一是独立BPE,即构建两个独立词典:一个源语言词典,一个目标语言词典;二是联合BPE,两个语言放一块,共同生成一个词典。理论上后者效果好一点,可以保证源语言和目标语言分割的一致性。尤其表现在拥有共享字母表的两种语言及同源词和外来词上。
2.2 蒙汉子字切分
蒙汉机器翻译模型非常适合使用子字切分来提升翻译效果。在子字切分时,我们往往需要在目标端语言中加入标记符号,用来还原词,但是汉文中字、词、短语的界限非常模糊,且最小单位字也能作为独立的切分模块,因此省去了标记符号,降低了噪声;蒙古文是一种纯粹的拼音文字[14],它是由蒙古文字母组成蒙古文词,再组成蒙古文句子,因此子字粒度可以大大缓解数据稀疏,从而提升整体的翻译效果。
如表1所示,因为其蒙古文字母种类相对较少,因此在两种切分粒度下(操作数指相邻最小单元组合合并次数,可以间接影响切分粒度,操作数越大,粒度相对越大)与原文比较变化不明显;汉文可以明显看到传统分词与BPE切分子字结果不同。子字粒度切分使得高频词得以保留,低频词切分为更小粒度的蒙文字母或高频字母组合,缓解了数据稀疏问题。

表1 使用子字粒度切分蒙汉双语对比
同样,如表2所示,我们在CWMT2009提供的6万句对的蒙汉双语语料和CWMT2017蒙汉评测提供的26万句对的双语语料上分别统计了不同切分粒度的词典大小。蒙古文切词处理,汉文分别切字(*_char)和切词(*_word)处理对比使用BPE算法进行蒙汉子字切分(*_BPE)处理,可以明显看出蒙汉两端词典大小均有明显减小;同时,当我们使用较大训练语料时,词典规模也会变大,从而增加了计算量。而子字切分的方式可以大大缩小词典规模,来缓解这个问题。

表2 使用子字粒度切分蒙汉双语词典大小统计
2.3 两种BPE在蒙汉双语上的应用
本文在2.1节介绍了使用BPE算法实现子字粒度切分有两种方式:独立BPE和联合BPE。我们在CWMT2009的蒙汉双语对齐语料上分别进行了两种切分,分析在蒙汉神经机器翻译任务中哪种子字切分方式更适合。

图3 CWMT2009不同操组数联合词典占比图
如图3所示,我们分别进行了操作数为5 000、20 000和40 000的联合BPE切分实验。理论上,联合BPE可以尽可能地保持源语言和目标语言分割的一致性。但是我们看到操作数不同的情况下,联合词典中蒙汉的占比差距较大。蒙汉占比不相近,使得蒙汉在切分子字粒度时粒度不一致。我们分析认为这与联合BPE的优势并不矛盾,词典占比不均的原因主要是蒙汉语言差异大,蒙古文是典型的拼音文字,而汉文字、词、短语没有明确分割界限,且作为蒙古文最小切分单元的蒙古文字母的数量远远少于汉文字。经统计我们得知,蒙古文单词平均由5个蒙古文字母组成,而汉文中绝大多数是二字词。在BPE计算共现频数时,蒙古文字母组合频数大,会优先组合蒙古文。因此随着操作数的增加,蒙古文高频组合结合完成后,越来越多的汉文字组合才被加入到词典中,蒙汉占比也越来越趋近于相等。
我们将蒙汉占比较为平衡的40 000操作数的切分结果与原文进行了对比,如表3所示。我们发现蒙古文中存在大量与原文一致的句子,而汉文中粒度却参差不齐。因此,我们分析认为使用联合BPE进行子字粒度切分,在蒙汉双语语料上无法体现自身的优势,而使用独立BPE进行子字粒度切分可以人为控制蒙汉双语各自的切分粒度,达到最优的切分结果,这样子字粒度切分才会发挥出其应有的效果。

表3 40 000操作数蒙汉子字切分结果
3 实验
3.1 实验数据配置
实验数据均基于CWMT2009的蒙汉双语语料(6万句)和CWMT2017蒙汉评测提供的双语语料(26万句)。汉文语料分词处理采用中科院计算所开发的ICTCLAS[15]中文分词系统进行切分,蒙古文和汉文均使用tokenizer[16]进行词语切分处理。BPE子字切分操作数均为最优结果的经验值。在本文中采用BLEU4[17]作为翻译效果的评测指标。
由于蒙汉机器翻译双语语料有限,词典本身就较小,因此我们的实验不限制词典大小。本文想要通过对比子字粒度切分处理后词典大小变化,并结合最终翻译模型的BLEU值的提升,来验证子字粒度可以通过缓解数据稀疏问题来提高模型翻译质量。
本文使用CWMT2009的蒙汉双语语料分别训练RNN和CNN两个模型,且分别进行了分词和子字粒度切分等对比实验,用来验证子字切分粒度的普适性,以及对模型的提升。其次,我们使用CWMT2017的语料训练RNN模型,与使用CWMT2009训练的RNN进行对比,以验证子字粒度切分对数据稀疏的缓解和缩短训练周期的作用。
实验使用的RNN和CNN模型是此前调优的结果,本文所有实验均使用以下参数:
① RNN模型,使用的Google 开源的seq2seq系统作为RNN系统。系统参数如下:编码器和解码器均为4层的双向LSTM循环单元[18],隐藏层节点数512,batchsize 128,dropout 0.3。
② CNN模型,使用的是Facebook AI Research 开源系统fairseq作为CNN翻译系统。系统参数如下:编码器不少于5层和解码器不少于9层,解码器的每一层均配备一个注意力机制,编码器和解码器的核宽度不小于3,词向量维度500,隐层单元数量不少于500,batchsize 32,训练算法Nesterov’s accelerated gradient (NAG)[19]。
3.2 蒙汉双语子字切分
3.2.1 蒙古文子字粒度切分
由于BPE操作数是个经验值,不同的语言种类、语料大小最优操作数也不同。
本实验设置操作数为5 000、10 000、15 000、17 500和20 000,将蒙古文切分成子字粒度、汉文分词,分别训练RNN模型,测试集BLEU值如图4所示(横坐标为操作数,纵坐标为BLEU值)。最终得出该语料蒙古文的最优操作数的经验值为17 500。
如表4所示,通过原文与最优切分结果的对比,本文发现,蒙古文子字切分粒度还是比较大的,与分词差别不大。蒙古文词构成通常是由词干和多个词缀构成[20]。结合蒙古文形态分析,我们认为子字粒度切分其实相当于蒙古文词缀的切分,而最优的切分结果能够使得切分的蒙古文子字片段既保留了较为完整的局部信息,又提高出现频率,从而缓解数据稀疏问题。
同理,经过大量实验,得到CWMT2017蒙古文独立BPE的最优操作数的经验值为35 000左右。
3.2.2 汉文子字粒度切分
汉文与蒙古文差异较大,尤其是蒙古文有明确的分词边界,而汉文字、词、短语界限模糊。因此我们想到两种子字粒度切分方式,如图5所示:一是汉文直接使用BPE算法切分子字;二是模拟蒙古文子字粒度切分方法,先进行中文分词处理,人为加入词边界,再使用BPE算法切分子字。

图5 汉文子字切分方法
两者相比,前者切分结果存在大于分词的粒度,可能包含更多的局部特征,也可能破坏原本词的局部特征。例如,“大学 生活”→“大学生活”或者“大学生”+“活”;后者切分结果的粒度一定小于分词,不会破坏分词前后信息。例如,“大学 生活”→“大学”+“生活”或者“大学”+“生”+“活”。
如图6所示,在保持蒙古文独立BPE操作数为最优操作数不变的基础上,汉文使用第一种子字切分方法,操作数设置为500、1 000、1 500、2 000、2 500和5 000,分别训练RNN模型。当操作数为1 000时,模型效果最佳,BLEU值达到32.83。同理,我们使用第二种方法,操作数分别设置为1 000、2 000、3 000、5 000、7 000和10 000,可以看到当操作数为5 000时模型效果最佳,BLEU值达到34.16。

图6 汉文两种子字切分方法对比
通过对比实验可以明显看出汉文先进行中文分词,再进行子字粒度切分的效果更好。同理,我们得到CWMT2017汉文独立BPE的最优操作数的经验值为15 000左右。
3.2.3 词缀切分与BPE子字切分对比
根据蒙古文形态分析发现,理论上对蒙古文切分后缀也可以减小粒度,缓解数据稀疏问题,因此通过规则和字典对蒙古文进行了词缀分析,用来作为子字切分的对比实验。根据蒙古文构词规则,得知改变构词后缀一般会改变该词的词义和语义,而改变构形后缀只会改变词性,因此我们通过蒙古文构词规则和后缀字典对构形后缀和结尾后缀进行切分。
如表5所示,从后缀切分与子字粒度切分实例对比可以发现:子字粒度切分结果与两种后缀切分结果相似。

表5 子字切分与词缀切分实例对比
如表6所示,我们统计了CWMT2009语料上两种后缀切分后词典大小。可以看到,与原始语料相比,词典大小明显缩小,但是比子字粒度切分的词典大。

表6 子字切分与词缀切分词典大小统计
如表7所示,因为子字粒度切分和后缀切分结果相近,因此在CWMT2009上的表现两者也互有输赢。我们分析认为:两者相比,后缀切分的优势在于切分准确,不会破坏蒙古文词本身。但是子字粒度切分优势在于它完全根据共现频率来切分,不需要外部的规则和字典,且粒度可控,应用更广泛(汉文也可以使用)。

表7 CWMT2009上的表现对比
3.3 实验结果与分析
表8可以看出,同为RNN模型,无论小语料库(6w)还是大语料库(26万),汉文分词均不如汉文分字的模型效果好,但是随着语料库的扩大,两种粒度的差距从3.68缩小到了0.39。我们结合表2认为,汉文分词效果较差的原因并不是较大粒度本身带来的,而是大粒度切分会放大小语料库数据稀疏问题,致使翻译结果不理想。语料库的扩大,直接缓解数据稀疏问题,因此汉文分词与分字效果差距并不明显。

表8 RNN中不同语料大小与不同粒度结果对比
如表9所示,蒙汉双语均使用子字粒度切分的RNN模型效果最好,BLEU值达到了34.16,相比于蒙汉均分词和蒙古文分词,汉文分字的模型分别提升了4.81和1.13。

表9 CWMT2009在RNN模型上的表现
由于语料较小,训练周期本身不长,因此子字粒度切分虽然使得RNN模型训练周期缩短,但效果并不显著。其中蒙汉双语均使用子字粒度切分的模型训练周期最短。
如表10所示,相同语料下,CNN模型对比效果与RNN模型相近,依然是蒙汉双语均使用子字粒度切分的模型效果最好,BLEU值达到了35.28。因此子字粒度切分在不同模型中都能提高翻译效果,且缩短训练周期,其普适性较高。
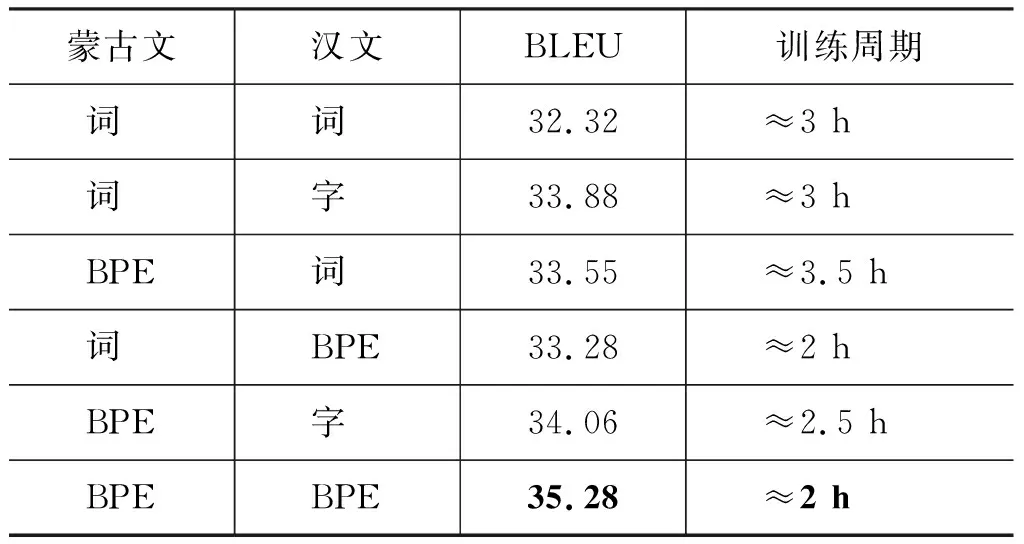
表10 CWMT2009在CNN模型上的表现
如表11所示,RNN模型在CWMT2017的26万语料下的表现。由于测试集使用的是日常用语领域的语料,而CWMT2017在日常用语的基础上加入了大量政府文献、法律等领域的语料,使得最终翻译效果没有CWMT2009上的理想。因此我们只能做同语料下不同处理方法之间的对比。

表11 CWMT2017在RNN模型上的表现
因此我们可以看到,蒙汉均使用子字粒度切分的模型翻译效果提升依然显著,且训练周期缩短更为明显,缩短了三分之二。由此可见子字粒度切分随着语料的扩大,缩短训练周期的效果越来越显著。
4 总结
实验从同语料不同模型和同模型不同语料两个角度进行验证,使用子字粒度切分,将低频词切分成相对高频的子字片段,缓解数据稀疏问题,可以使得多种模型翻译效果得到显著提升,且通过缩小词典大小,显著缩短训练周期。
子字粒度切分技术在语料相对匮乏的前提下,主要是通过切分低频词,来缓解语料匮乏带来的严重数据稀疏问题,从而提高蒙汉神经机器翻译的效果。词典规模和网络模型的训练周期随着语料规模的增大而增加。我们通过限制词典的大小来减少计算复杂度,但这会使得一部分原本在词典中的低频词成为集外词,影响翻译质量。子字粒度切分会将低频词切分成更小单元,这样集外词可以由粒度较小的子字单元拼接而成。因此子字粒度切分在大语料限制词典大小的前提条件下,可以充分体现其减少集外词的能力,来提高模型的翻译效果。
因此,在蒙汉神经机器翻译任务中,子字粒度切分技术无论在现在还是未来都是一个很有应用价值的技术。
