基于古汉语语料的新词发现方法
2019-02-25刘昱彤
刘昱彤,吴 斌,谢 韬,王 柏
(北京邮电大学 智能通信软件与多媒体北京市重点实验室,北京 100876)
0 引言
挖掘语料中的新词对整个自然语言处理领域都具有十分重要的意义,同时它也是中文分词、命名实体识别和其他任务必不可少的部分。根据黄昌宁等[1]的研究,60%的中文分词错误来源于未登录词。
如今,中文新词发现的研究主要集中在现代汉语语料,在古汉语语料上的研究鲜有涉及。然而,古汉语与现代汉语在很多方面有很大区别,例如,词汇、短语、语法结构等。此外,很多现代汉语的词汇,在古汉语语料中可能不是一个词语。举例来说,“可以”在现代汉语语境中就表示“可以”,但是在古汉语语境中,这两个字是单独的词语,当“可”和“以”组合在一起时,表示“可以凭借”的意思。因此,将针对现代汉语的新词发现工具直接套用在古汉语语料中是不合理的,对古汉语语料的新词发现进行研究十分必要。
在古汉语语料中,Deng等[2]提出了一种无监督的方法来同时挖掘新词和切分中文文本。尽管这种方法能够有效地切分古汉语语料,但仍存在一些问题。第一,分词的切分粒度不均匀,分词结果存在很多歧义。第二,这种方法对于低频新词的挖掘效果不太理想。然而,在古汉语语料中,很少会出现分词歧义,而且很多新词属于低频新词。基于这些原因,本文提出了一种新的古汉语语料的新词发现算法。
本文提出的AP-LSTM-CRF古汉语新词发现算法融合了改进的类Apriori算法和Bi-LSTM-CRF切分概率模型。改进的类Apriori算法能够有效地挖掘低频新词。Bi-LSTM-CRF模型能够获得连续两个字之间的切分概率。基于切分概率的序列,改进的类Apriori算法产生的候选词可以被划分为新词和噪声词。
本文的主要贡献包括3个方面:
(1) 提出了古汉语的新词发现算法AP-LSTM-CRF,融合了改进的类Apriori算法和Bi-LSTM-CRF切分概率模型,利用数据挖掘的关联规则算法和深度学习的方法有效地挖掘古汉语语料中的新词。
(2) 基于Apache Spark分布式并行计算框架将改进的类Apriori算法并行化,提高了挖掘新词的效率,提出了新的较为严格的过滤规则,能够过滤掉更多的噪声词。
(3) 在宋词和宋史数据集上验证了AP-LSTM-CRF古汉语新词发现算法的有效性,与现有最好方法比较,F1值分别提高了约8个百分点和2个百分点。
1 相关工作
最新的中文新词发现研究主要分为3个方面。第一是针对特定领域的新词发现。Chen等[3]提出了一种联合统计模型,可以同时发现特定领域的新词和在特定领域有特殊含义的词。霍帅等[4]提出一种基于微博内容的新词发现方法,引入词关联性信息的迭代上下文熵算法,并通过上下文关系获取新词候选列表进行过滤。周霜霜等[5]提出了一种融合人工启发式规则、C/NC-value改进算法和条件随机场模型的微博新词抽取方法。雷一鸣等[6]提出一种基于词语互信息模型和外部统计量的针对微博语料的新词发现方法。杜丽萍等[7]提出的互信息(PMI)的改进算法,将PMIk算法与少量基本规则相结合,能够从大规模语料中自动识别不同长度的网络新词。第二是针对开放领域的新词发现。陈飞等[8]提出了一系列区分新词边界的统计特征,并采用CRF方法综合这些特征实现了开放领域新词发现的算法。第三是用新词发现来辅助情感分析任务。杨阳等[9]提出了基于词向量的情感新词发现方法。万琪等[10]将新词发现融入微博情感表达抽取任务中,建立了基于CRF的联合模型,利用新词的信息提高了情感表达识别的效果。
然而上述的所有这些方法,都主要集中在现代汉语语料。
关于在古汉语语料中发现新词,最早的工作是Deng等[2]提出的TopWords算法。这是一种无监督的面向特定领域的新词发现算法,在古汉语语料中发现新词只是其中的一个应用场景。这种算法并不是针对古汉语语料的特点来设计的,存在着分词歧义和无法有效挖掘低频新词的缺点。谢韬等[11]的工作是在此基础上进行改进的。只保留了原先产生候选词集的Apriori算法,他们所提出的AP-LSTM是一种专门针对古汉语语料的有监督新词发现算法。
本文的工作与谢韬等[11]的工作最为相似,都是先通过改进的类Apriori算法产生候选词集,然后使用过滤规则去掉候选词集里的噪声词。而主要区别体现在3个方面:第一,为改进的类Apriori算法添加了并行化实现,极大地提高了产生候选词集的效率。第二,将LSTM切分概率模型改为了Bi-LSTM-CRF模型,提高了切分概率模型的准确率、召回率和F1值。第三,对过滤规则进行改进,使其变得更加严格,在不影响新词的条件下过滤掉更多的噪声词,提高了发现新词的准确率。
2 模型描述
2.1 问题描述
本文的研究点主要集中在古汉语语料的新词发现上,所以需要明确在古汉语语料中,哪种词才算是新词。首先,它应该是一个含有明确语义的词语,其次,它很少出现在现代汉语中;最后,它应该具有鲜明的历史意义,如古汉语、诗歌词汇、专有名词等。所以,本文给出古汉语语料新词的定义如下:
定义1古汉语语料新词
古汉语中的新词是一个包含了明确语义解释和历史特征的字符序列,同时它不包含在标准词典中。
基于上述定义,本文阐明了古汉语中新词的含义。并且设计了一个标准词典来过滤掉噪声词,标准词典主要包括现代词汇和停用词。进一步地,本文将古汉语新词发现问题形式化地描述定义如下:
定义2古汉语新词发现
给定古汉语语料C和标准词典D,新词发现旨在找出所有不在D中的新词W。这包括候选新词A的生成以及过滤掉噪声词T。换句话说,新词集合(A-T)就是最终的结果。
2.2 总体流程介绍
图1展示了本文提出的古汉语新词发现算法AP-LSTM-CRF的流程图。

图1 AP-LSTM-CRF算法流程图
(1) 用改进的类Apriori算法产生候选词集。
(2) 在测试集文档中找到候选词每次出现的位置和对应的上下文。
(3) 用训练集文档训练Bi-LSTM-CRF模型。
(4) 在测试集上用训练好的Bi-LSTM-CRF模型对句子进行切割。
(5) 用设计好的结合切分概率的过滤规则把候选词集里的噪声词过滤掉。
(6) 用jieba[注]https://pypi.org/project/jieba/分词器的词典对上一步得到的结果进行过滤,得到真正的新词。
2.3 改进的类Apriori算法
改进的类Apriori算法来源于谢韬等[11]的工作,现复述如下。
算法1改进的类Apriori算法
输入:原始语料D={s1,s2,…,sn}
输出:候选新词的集合
//产生1频繁项集
1候选项集C1={c1,c2,…,cm}
统计原始语料中单个字的频率,得到(字,频率)的二元组集合S1={(c1,f1),(c2,f2),…,(cm,fm)}
FOR(ci,fi) INS1DO
IFfi>支持度THEN
把ci加入1频繁项集L1
得到1频繁项集L1
//产生2频繁项集
FORsiINL1DO
FORsjINL1DO
把si+sj加入2候选项集C2
统计原始语料中C2的每个字符串si出现的频率,得到(字符串,频率)的二元组集合S2={(s1,f1),(s2,f2),…,(sm,fm)}
FOR (si,fi) INS2DO
IFfi>支持度 THEN
把si加入2频繁项集L2
IFfi<低频阈值THEN
把si加入低频项集M
得到2频繁项集L2
FORk=3 TOKDO
//产生k频繁项集
FORP(p1p2…pk-1)INLk-1DO
FORQ(q1q2…qk-1)INLk-1DO
IFp2p3…pk-1=q1q2…qk-2THEN
把p1p2…pk-1qk-1加入Ck
统计原始语料中Ck的每个字符串si出现的频率,得到(字符串,频率)的二元组集合Sk={(s1,f1),(s2,f2),…,(sm,fm)}
FOR (si,fi) INSkDO
IFfi>支持度 THEN
把si加入k频繁项集Lk
Iffi<低频阈值 THEN
把si加入低频项集M
得到k频繁项集Lk
ReturnL2∪L3∪…∪LK∪M
算法1描述了改进的类Apriori算法,图2展示了该算法的流程图。假设原始语料D由n个句子组成,s表示字符串,c表示字符,f表示频率。

图2 改进的类Apriori算法流程图
产生1频繁项集的过程可分为统计频率、过滤两个步骤。1候选项集是语料中出现的每个字。统计原始语料中每个字出现的频率,把频率大于支持度的字加入1频繁项集。产生2频繁项集的过程可分为组合、统计频率、过滤三个步骤。把1频繁项集中的字两两组合后的字符串加入2候选项集,在原始语料中统计2候选项集的每个字符串出现的频率,把频率大于支持度的字符串加入2频繁项集,把频率小于低频阈值的字符串加入低频项集。产生3频繁项集到k频繁项集的过程可分为组合、统计频率、过滤三个步骤。把k-1频繁项集的两两字符串经过特殊的方式组合后产生的字符串加入k候选项集,在原始语料中统计k候选项集的每个字符串出现的频率,把频率大于支持度的字符串加入k频繁项集,把频率小于低频阈值的字符串加入低频项集。最后把频繁项集L2…LK和低频项集M取并集成为候选新词的集合。
改进的类Aprior算法相比传统的Apriori算法的区别有两点。第一,加入了低频阈值,使之能够挖掘古汉语中的低频新词。因为中国古代文学中的大部分词汇只在整个语料库中出现过一次或两次,但是频繁项集的生成是基于支持度(频率)的,因此传统的Apriori算法无法挖掘出古汉语中的低频新词。第二,对产生3频繁项集到k频繁项集过程的组合步骤提出改进。传统Apriori算法的组合步骤虽然也能挖掘出频繁候选字符串,但会产生大量的噪声词,而且没有考虑词语里字符的顺序关系。
本文基于Spark平台为改进的类Apriori算法实现了并行化,详见算法2。
算法2改进的类Apriori的并行化算法
输入:原始语料D={s1,s2,…,sn}
输出:候选新词的集合
① 将原始语料文件以RDD变量的形式读入内存,假设该RDD变量为input_rdd。
//产生1频繁项集
② 对input_rdd的每一行,把出现的每一个字符存到数组中,并将每个字符映射到频率(也就是1)。最后用reduce操作把相同字符的频率相加,得到每个元素是(字符,频率)的RDD变量f1。
③ 对RDD变量f1做filter操作,将频率大于支持度的元素保留,得到新的RDD变量L1,即1频繁项集。
④ FORk=2 TOKDO
//产生k频繁项集
⑤ IFk==2 THEN
⑥ 对L1和L1做笛卡尔积(cartesian操作),产生2候选项集C2(C2也是RDD变量)。
⑦ ELSE
⑧ 用map操作把Lk-1的每个元素P=p1p2…pk-1映射到(p1p2…pk-2,P),得到RDD变量pre。用map操作把Lk-1的每个元素Q=q1q2…qk-1映射到(q2q3…qk-1,Q),得到RDD变量post。然后把pre和post做join操作,也就是把前缀和后缀相同的两个字符串关联在一起,然后把这两个字符串拼接在一起,得到候选词集Ck。
⑨ 对input_rdd的每一行,用长度为k的窗口滑动,将产生的所有长度为k的字符串存入数组,并将每个字符串映射到频率(也就是1)。最后用reduced操作把相同字符串的频率相加,得到每个元素为(字符串,频率)的RDD变量scan_trans。把Ck和scan_trans做join操作,得到每个元素为(字符串,频率)的RDD变量fk,每个元素为在原始语料中出现过的候选词和对应的出现频率。
⑩ 对RDD变量fk做filter操作,将频率大于支持度的元素保留,得到新的RDD变量Lk,即k频繁项集。再重新对RDD变量fk做filter操作,这次将频率小于低频阈值的元素保留,将得到的RDD变量与低频项集M合并。
2.4 Bi-LSTM-CRF切分概率模型
图3展示了Bi-LSTM-CRF切分概率模型的结构图,接下来的内容将分别解释该神经网络结构的每一层。

图3 Bi-LSTM-CRF切分概率模型结构图
2.4.1 Embedding层
在大规模古汉语语料上使用Word2Vec[注]https://code.google.com/archive/p/word2vec/训练字向量。假设古汉语语料中的不同字构成的字典为C,则字典大小为|C|,字向量的维度为d。那么可以得到字向量矩阵M∈Rd×|c|。在Embedding层,把输入句子的每个字映射到它们对应的字向量。
2.4.2 Bi-LSTM层
循环神经网络(recurrent neural network,RNN)是庞大的神经网络家族中的一员,主要用于编码序列数据。它以一个向量序列(x1,x2,…,xn)作为输入,返回另一个序列(h1,h2,…,hn)来表示输入中每个步骤中有关序列的一些信息。尽管在理论上,RNN能够学习到长距离的依赖信息,但是在实际应用中,却因为梯度爆炸或梯度消失的问题难以学习到长距离信息。

图4 LSTM单元结构
因此,长短时记忆网络(long short-term memory network,LSTM)通过添加了一个存储单元来克服这个问题,以此能够捕捉到长距离的依赖信息。LSTM单元结构如图4所示。LSTM单元拥有三个特殊的“门”结构,分别是输入门、遗忘门和输出门。具体通过以下式(1)~式(6)来说明:
i(t)=σ(Wx ix(t)+Wh ih(t -1)+bi)
(1)
f(t)=σ(Wxfx(t)+Whfh(t -1)+bf)
(2)
o(t)=σ(Wx ox(t)+Wh oh(t -1)+bo)
(3)
g(t)=tanh(Wx gx(t)+Wh gh(t -1)+bg)
(4)
c(t)=f(t)⊗c(t -1)+i(t)⊗g(t)
(5)
y(t)=h(t)=o(t)⊗tanh(c(t))
(6)
其中,i,f,o,c分别代表输入门、遗忘门、输出门和记忆细胞的启动向量。从权值矩阵的下标可以看出每一个权值矩阵的具体含义,例如Whi代表的就是隐藏输入门的权值矩阵。bi,bf,bo分别代表对应门的偏置向量。
但是,从前往后的LSTM层(前向LSTM层)只能编码每个字的上文信息。若要表达出每个字的上下文信息,还需要一个从后往前的LSTM层(反向LSTM层)编码每个字的下文信息,然后把这两层结合起来,如式(7)~式(9)所示。
这样,通过双向LSTM神经网络,就可以表示出一句话中每个字所有的上下文信息,为后续的标注任务奠定了基础。
2.4.3 全连接层
从Bi-LSTM层输出的是每个时刻t(每个字)的隐状态向量ht,接下来使每个时刻的输出映射到4个神经网络单元,分别代表该字标注为B、M、E、S的分数,映射采用全连接的方式,如图5所示。字的标签B、M、E、S的含义见表1。

图5 全连接层时刻t的网络结构

标签含义标签含义B词的开头字E词的结尾字M词的中间字S独立成词
2.4.4 CRF层
在全连接层之后可直接加一个softmax层,对标注为B、M、E、S的分数做归一化,使之转化为概率,即每个时刻这四个神经网络单元的输出相加为1。但是这种方法对每个字的标签独立地进行预测,无法捕捉到输出标签之间的依赖关系(例如,标签“M”后面不能接标签“S”),而条件随机场(conditional random field,CRF)可以有效解决这个问题。
对于一个输入句子(假设x1,x2,…,xn都是中文字符),如式(10)所示。
X=(x1,x2,…,xn)
(10)
假设预测的输出标签序列如式(11)所示。
Y=(y1,y2,…,yn)
(11)
定义它的得分如式(12)所示。
(12)
其中,A是转移分数矩阵,Ai,j表示从标签i转移到标签j的分数。y0,yn+1分别代表句子的开始标签(start)和结束标签(end)。P是双向LSTM层输出的得分矩阵,所以P的大小是n×k,k是不同的标签数,Pi,j表示句子的第i个字标注为标签j的分数。
在CRF层后,通过一个softmax层,得到给定输入句子X的条件下所有可能的标签序列的概率,YX表示所有可能的标签序列的集合。
(13)
然后在模型训练的过程中,极大化正确标签序列的log似然,如式(14)所示。
(14)
在测试(解码)的过程中,将得分最高的标签序列作为预测输出序列,如式(15)所示。

(15)
2.5 过滤规则
对于由改进的类Apriori算法产生的每个候选新词,它在测试集文档中可能出现一次或多次,并且在每个出现位置都存在一个输入上下文。测试集文档经过训练好的Bi-LSTM-CRF模型后,会得到每一个位置的切分结果。下面给出过滤规则的定义:
定义3过滤规则
对于一个候选新词,如果存在某个输入上下文窗口,它的左边界切分概率和右边界切分概率同时大于0.5,并且它的内部切分概率全都小于0.5,则将其划分为新词。
3 实验
3.1 数据集介绍
本文中,主要用到两个很有代表性的古汉语数据集:宋词和宋史。这两个数据集来源于谢韬等[11]的实验语料,其中,分别随机抽取3万行进行分词标注,并标注出有具体语义的新词。数据集的具体描述见表2。

表2 数据集统计信息
另外,本文将开源中文分词工具jieba分词器的词典作为算法里的标准词典,jieba词典共包含584 429个已知词。
3.2 实验结果
3.2.1 有效性实验
(1) 分布式的类Apriori算法
改进的类Apriori算法采用和谢韬等[11]工作的相同实验设置,将支持度设置为5,低频阈值设置为2,对于宋词语料,设置频繁项集的最大长度为5,对于宋史语料,频繁项集的最大长度设为10。在测试集上运行改进的类Apriori算法,分别在宋词语料和宋史语料中得到了13 905和12 265个候选词。
本文采用的并行化实验集群由1个主控节点和9个计算节点组成,计算节点的配置信息参见表3。

表3 计算节点配置信息
实验结果如图6所示,并行化后的算法相比于串行的算法,效率提升显著。而且节点数越多,算法耗费的时间越少。

图6 改进的类Apriori算法随节点数目变化运行时间图
(2) Bi-LSTM-CRF切分概率模型
切分概率模型用来预测一个句子的每个位置是否应该被切分。假设一个句子表示为s=c1c2…cn(c1,c2,…,cn表示句子中对应位置的字)。经过切分概率模型后,则产生由0和1组成的长度为n-1的序列,1表示切分,0表示不切分。该序列是预测的切分序列。带有分词标注的句子经过处理可以得到实际的切分序列。
在实验中,用准确率、召回率和F1值来评价切分概率模型的好坏,如式(16)~式(18)所示。

(16)

(17)

(18)
本文将经过分词标注的数据集划分为训练集和测试集,划分比例为8∶2。
神经网络模型中超参数的设置对实验结果有较大影响,本文选择的超参数的值详见表4。表中所列超参数的值是凭经验选择的。其中,Embedding层和Bi-LSTM层的dropout比率都设置为0.5。设置dropout主要是为了防止模型的过拟合。

表4 超参数设置
关于隐藏层单元个数和字向量维度这两个超参数的选择过程如下:
测试基于不同字向量维度和LSTM隐藏层单元个数的模型效果。如表5所示,对于宋词语料,当字向量的维度是100,LSTM隐藏层单元个数是128的时候,Bi-LSTM-CRF有最高的性能。而对于宋史语料,当把字向量维度设置成50,LSTM隐藏层单元个数设置为150时,模型能够有最好的效果。

表5 Bi-LSTM-CRF切分概率模型实验结果
所以本文将这两组设置和表4的设置合起来作为后续实验的超参数设置。相比于谢韬等[11]的切分概率模型,F1值分别有7.20%和3.07%的提升。[注]关于谢韬等[11]的切分概率模型实验结果详见其论文,在本文不再赘述,此处是将表5与谢韬等[11]的切分概率模型实验结果的F1值作比较。谢韬等[11]的切分概率模型是用来判断一个四字输入的中间是否应该被切分。它的网络结构是字向量层+Bi-LSTM层+1输出的全连接层,再接sigmoid函数把输出值映射到[0,1]。最终的输出表示四字输入的中间的切分概率,大于0.5表示切分,小于0.5表示不切分。
(3) 过滤规则
假设改进的类Apriori算法产生的某个候选新词是字符序列CtCt+1,找到它在测试集文档中的每一个出现位置,然后获得它的左邻接字符和右邻接字符,所以可以得到一个上下文窗口Ct-2Ct-1CtCt+1Ct+2Ct+3,如果上下文中不存在邻接字符,则用一个默认字符“padding”替代。进而能够得到三个小窗口:Ct-2Ct-1CtCt+1,Ct-1CtCt+1Ct+2,CtCt+1Ct+2Ct+3。通过Bi-LSTM-CRF切分概率模型可以得到测试集文档中每个句子任意两个连续字之间的切分概率,从中找出这三个小窗口中间位置的切分概率,就得到了候选词的内部切分概率和边界切分概率。然后利用与内部切分概率和边界切分概率有关的过滤规则来判断候选新词是真正的新词还是噪声词。这样,利用过滤规则从候选词集中筛选出真正的新词,即AP-LSTM-CRF模型预测的新词。语料中标注的新词即是实际的新词。
在实验中,用准确率、召回率和F1值来对新词发现结果进行评价,如式(19)~式(21)所示。

(19)

(20)
(21)
使用谢韬等[11]的过滤规则,新词发现的效果如表6所示(AP-LSTM模型是谢韬等[18]提出的古汉语新词发现算法,它的过滤规则是,对于一个候选新词,如果存在某个输入上下文窗口,它的左边界切分概率和右边界切分概率同时大于0.5,则将其划分为新词)。
使用本文提出的新的过滤规则的实验结果如表7所示。
分别观察表6和表7,可以看出,无论是使用谢韬等[11]提出的过滤规则,还是使用新的过滤规则,AP-LSTM-CRF算法的性能都比AP-LSTM好,证明了本文提出的Bi-LSTM-CRF切分概率模型的有效性。
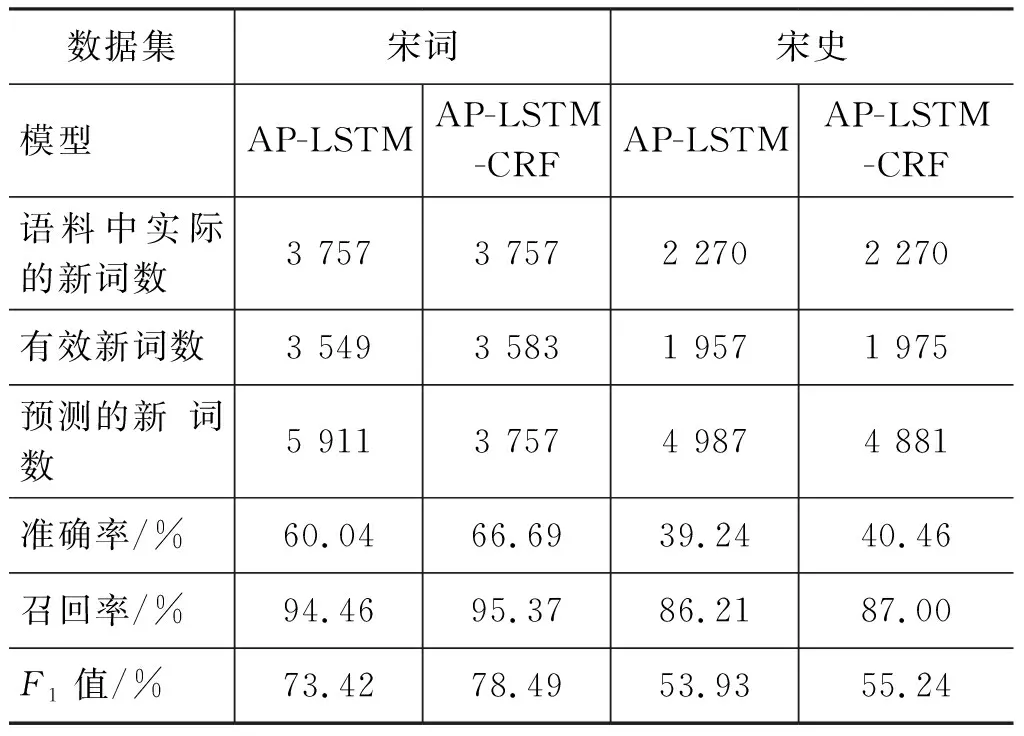
表6 使用旧的过滤规则的新词发现实验结果

表7 使用新的过滤规则的新词发现实验结果
通过对比表6和表7的实验结果,可以发现无论是AP-LSTM算法,还是AP-LSTM-CRF算法,使用新的过滤规则的实验结果都比使用谢韬等[11]提出的过滤规则的实验结果要好,由此证明了本文提出的新的过滤规则的有效性。
3.2.2 AP-LSTM-CRF算法和其他算法的对比实验
本文对比了古汉语新词发现算法AP-LSTM-CRF和当今主流的几种开源中文分词工具(Ansj[注]https://github.com/NLPchina/ansj_seg,中科院ICTCLAS[注] http://ictclas.nlpir.org/,斯坦福中文分词工具[注]https://nlp.stanford.edu/software/segmenter.shtml)以及Deng等[2]提出的TopWords模型的效果。
关于AP-LSTM-CRF模型,改进的类Apriori算法部分采用谢韬等[11]的实验设置,Bi-LSTM-CRF切分概率模型采用3.2.1节最佳的超参数设置,最后利用新的过滤规则。
关于几种中文分词工具,首先用分词器切分语料,然后把得到的词用jieba词典过滤,得到预测的新词。
关于TopWords模型,采用Deng等[2]的实验设置。
经过实验,关于发现的有效新词个数的对比如图7所示,关于新词发现的F1值的对比如图8所示。

图7 AP-LSTM-CRF算法和其他算法发现的有效新词数对比

图8 AP-LSTM-CRF算法和其他算法发现新词的F1值对比
可以看出,AP-LSTM-CRF算法的性能明显优于现有的主流分词器,这证明了现代汉语和古汉语在语法和构词规则上确实存在很大的差异,针对现代汉语的算法无法很好地运用于古汉语这一特殊领域。而AP-LSTM-CRF模型比TopWords模型的效果要好,证明了低频新词也是古汉语中新词的重要组成部分,通过找到更多的低频新词,可以减少切分歧义,使相同的词不再会有多种切分结果。
3.2.3 差错分析
有两种情况的识别错误。第一种情况是算法并未将实际的新词识别出来。如“江渚”,它在原文中出现过1次,“乘/兴/离/江渚”。经过Bi-LSTM-CRF切分概率模型,得到的切分序列为011,而实际的切分序列应该是101,根据过滤规则,把该词判定为噪声词,而实际上该词是新词。再如“山耸”,在原文中出现过两次,分别是“鳌/山耸”,“重叠/暮山/耸翠”。经过Bi-LSTM-CRF切分概率模型,得到的切分序列分别为011和010,而实际的切分序列应该为101和010,根据过滤规则,把该词判定为噪声词,而实际上该词是新词。在这两个例子中,若切分概率模型得到的切分序列是正确的,那么根据过滤规则可以得到正确的结果,所以问题出在切分概率模型上。
第二种情况是算法将噪声词误判成了新词。如“渐遏”,它在原文中出现过1次,“渐/遏/遥天”。经过Bi-LSTM-CRF切分概率模型,得到的切分序列为101,而实际的切分序列应该是111,根据过滤规则,把该词判定为新词,而实际上该词为噪声词。再如“知我”,在原文中出现过两次,“争/得/知/我”,“争知/我”。经过Bi-LSTM-CRF切分概率模型,得到的切分序列为101和011,而实际的切分序列应该为111和011,根据过滤规则,把该词判定为新词,而实际上该词为噪声词。在这两个例子中,问题同样在于切分概率模型,所以在后续的工作中切分概率模型有待进一步完善。
但是由这几个例子可以看出过滤规则是合理的,为了包容切分概率模型可能产生的差错,过滤规则要求只要有一个上下文完全满足两边切分中间不切分的条件就判断成新词。事实证明,如果切分概率模型预测正确,使用这样的过滤规则是不可能判断失误的。
3.2.4 古汉语新词发现结果展示
表8分别列举了AP-LSTM-CRF算法在宋词和宋史中发现的20个典型的新词。
基于在语料中已经发现的新词,本文把这些新发现的词添加到分词器的词典中,并比较其与原分词器的性能,结果如表9所示。

表8 古汉语中发现的典型新词展示
从表9可以看出,当向分词器里添加了新词之后,分词器的准确性得到了极大的提升。

表9 加入新词后分词器的性能提升效果
4 结束语
本文提出了一种基于古汉语语料的新词发现算法AP-LSTM-CRF。改进的类Apriori算法可以有效地挖掘低频新词,通过并行化该算法,极大地提升产生候选词集的效率。Bi-LSTM-CRF切分概率模型可以更加准确地判断两个字之间的切分概率。基于候选词上下文的切分概率序列,本文提出的过滤规则可以更加有效地过滤掉噪声词,从而有效地从古汉语语料中挖掘新词。
将来,我们将尝试采用无监督或半监督的算法对古汉语的新词进行挖掘。因为如果采用有监督的算法,就需要研究者人工标注大量训练数据,这种代价是十分大的。此外,在大量的古汉语数据背景下,句子语法十分繁多,这给数据的标注和模型的训练带来了很大的挑战。因此,无监督地在古汉语语料中发现新词具有十分重大的现实意义。
