基于LSTM-CRF命名实体识别技术的研究与应用
2019-02-25张聪品刘昱良
张聪品,方 滔,刘昱良
(河南师范大学 计算机与信息工程学院,河南 新乡 453007)
0 引 言
电子病历是指医务人员在医疗活动过程中,使用医疗机构信息系统生成的文字、符号、图表、图形、数据、影像等数字化信息,并能实现存储、管理、传输和重现的医疗记录[1],是由医务人员撰写的面向患者个体描述医疗活动的记录。
随着自然语言处理技术的发展,可以从电子病历的文本[2]中自动提取大量专业医疗知识,构建医疗知识图谱。如电子病历中,“患者缘于1年前无明显诱因出现颈肩部及腰部疼痛、右上肢麻木,入院后进行颈椎CT检查:颈椎间盘突出。入院后给予患者颈椎牵引、颈部手法推拿、颈部中药塌渍、颈部微波照射治疗。于今日出院。”在病历中,“颈椎CT检查”证实了“无明显诱因出现颈肩部及腰部疼痛、右上肢麻木”的发生;而“患者颈椎牵引”、“颈部手法推拿”、“颈部中药塌渍”、“颈部微波照射治疗”这些治疗使患者的症状消失了,为了从电子病历里抽取出这些相关的医疗知识(即关系抽取),构建医疗知识图谱,首先需要识别出电子病历文本中与患者健康密切相关的各类命名实体,如“腰部”等身体部位、“疼痛”等症状、“颈椎CT检查”等检查手段、“颈椎间盘突出”等疾病名称、“颈部手法推拿”等实施的治疗。身体部位、症状、检查手段、疾病名称、治疗这些概念在电子病历信息抽取研究中被称为命名实体[3]。
传统的中文实体识别方法有条件随机场、字典法和混合方法[4]。随着深度神经网络技术的发展,深度神经网络技术已经广泛应用于自然语言处理中,包括中文命名实体识别[5]。基于深度神经网络的中文命名实体识别模型中,使用神经网络隐含层的上下文向量作为输出层标注的特征,但是神经网络模型却无法表示标注之间的约束关系[6]。
通过在长短时记忆神经网络(LSTM)模型中内嵌条件随机场(CRF)模型,利用CRF模型表示标注之间的约束关系。构建了LSTM-CRF模型,自动识别出电子病历中的五类中文命名实体:身体部位、疾病名称、检查手段、症状和治疗,为下一步抽取关系信息[7],构建医疗知识图谱奠定了基础。
1 LSTM-CRF模型
传统的神经网络输出只依赖于当前的输入,循环神经网络通过使用带自反馈的神经元,能够处理任意长度的序列,解决了传统神经网络解决不了的变长输入和相互依赖的处理任务[8]。长短时记忆神经网络模型解决了循环神经网络由于梯度爆炸或消失只能学习到短周期的依赖关系问题[9]。
LSTM模型通过引入一组记忆单元,使得神经网络具有学习遗忘历史信息,用新信息更新记忆单元的功能。在时刻t,记忆单元ct记录了到当前时刻为止的所有历史信息,并受三个“门”控制:输入门it,遗忘门ft和输出门ot。三个门的计算公式如下所示,三个门元素的值在[0,1]之间。
it=σ(Wixt+Uiht-1+Vict-1)
(1)
ft=σ(Wfxt+Ufht-1+Vfct-1)
(2)
ot=σ(Woxt+Uoht-1+Voct)
(3)
(4)
(5)
ht=ot⊙tanh(ct)
(6)
其中,xt是当前时刻的输入;σ是logistic 函数;Vi、Vf、Vo是对角矩阵。遗忘门ft控制每一个内存单元需要遗忘多少信息,输入门it控制每一个内存单元加入多少新的信息,输出门ot控制每一个内存单元输出多少信息。
LSTM模型工作时,首先由遗忘门层通过sigmoid来控制确定通过记忆单元的信息。根据上一时刻的输出ht-1和当前输入xt来产生一个0到1的ft值,以决定是否让上一时刻学到的信息Ct-1通过或部分通过。然后进一步产生需要更新的新信息[10]。需要更新的新信息包含两部分,第一部分是输入门层通过sigmoid函数决定哪些值用来更新,第二部分是tanh层用来生成新的候选值C~t,它作为当前层产生的候选值会添加到记忆单元中。模型结合这两部分产生的值进行更新[11]。
文中在识别中文电子病历中的命名实体时,将汉字分解成若干个偏旁部首,每个汉字表示成d维向量。对给定的包含n个汉字的句子(x1,x2,…,xn),句子中的每个汉字,LSTM模型通过式1~6计算字左边内容的ht和字右边内容的ht,得到词向量的LSTM表示,从而包含了所需要记忆的信息。
在LSTM神经网络模型中,直接用ht作为特征值去计算网络输出yt,在识别中文命名实体时,输出标签之间存在的一些约束条件LSTM模型无法表示出来。如文中所识别的五类中文命名实体,身体部位BOD、疾病名称DIS、检查手段EXA、症状SYM和治疗TRE,通常B表示开始的字,I表示中间的字,E表示最后的字,S表示该实体是单个字,I-BOD不能在B-DIS之后,LSTM模型无法表示这些约束条件,因此在LSTM模型中嵌入CRF模型,利用CRF模型计算输出yt的值。
在条件随机场中,每个特征函数有下面几个输入值:一个句子X、一个单词在句子中的位置i、当前单词的标签li、前一个单词的标签li1、输出为一个实数(通常是0或者1)[12]。在LSTM-CRF模型中,首先定义了句子X输出标签序列y的分值s(X,y)的计算公式。
(7)
其中,A是转移矩阵,表示将所有状态一步转移的概率;P是LSTM输出的矩阵,pi,j是假设从第i个字到第j个字作为一个实体的分值。根据s(X,y)的值选择y。
输出y*=argmaxs(x,y'),其中y'∈Yx,Yx表示y所有可能的标签序列。所设计实现的LSTM-CRF模型结构如图1所示。
2 实验分析
2.1 实验环境
实验的硬件环境如下:处理器为intel@Corei7CPU
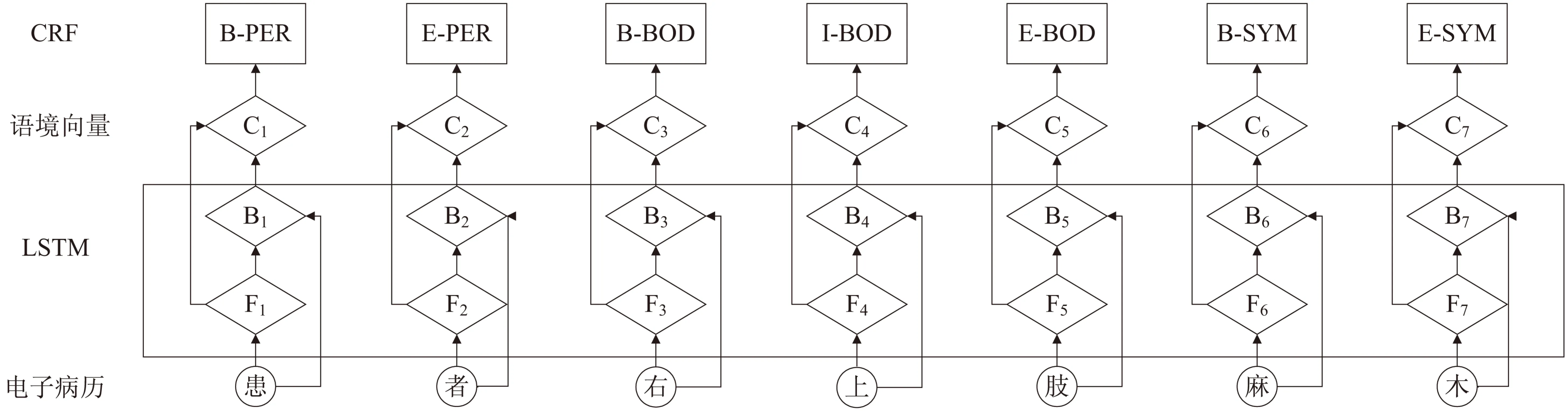
图1 LSTM-CRF模型
@3.60 GHz*8;内存32 G;GPU为TITAN X (Pascal);操作系统为Ubuntu16.04。
文中设计实现的中文电子病历命名实体识别程序,使用Python程序设计语言开发,开发过程中调用的工具包如下:
jieba-0.38:结巴分词模块可支持精确模式、全模式、搜索引擎模式三种分词方式,支持基于概率的用户词典。实验过程中使用精确模式并结合加载外部用户词典,从原文本产生分词语料。词典格式设计为一个词占一行,涵盖常用医学上的专有名词即确定的实体边界。
gensim-2.3.0版本:gensim-2.3.0是Word2Vec基于python的实现。Word2Vec是Google公司发布的一个开源词向量工具包,并在语料中获取了高精度的词向量表示。实验中首先使用结巴分词库产生的分词语料来生成词向量,然后使用Gensim的Word2Vec,训练结果在构建LSTM深度学习模型时使用。
tensorflow-gpu==1.2.0版本:实现神经网络模型的开源工具。实验中使用tensorflow-gpu==1.2.0搭建了LSTM神经网络模型[13-14]。
2.2 实验数据处理
首先,在医学专家指导下人工标注了100×4条实体语料[15],并建立字典,字典中包括实体和实体类型;其次,利用模型生成部分实体标注语料,并设计程序自动校对,校对程序判断模型生成的语料是否与字典中的一致,包括实体和实体类型是否一致;最后,生成深度学习模型需要的BIO字标签形式语料。反复迭代下去,不断优化模型生成语料,直至建立好模型需要的语料。
2.3 实验结果
准确率是多分类中最重要的性能指标。该实验中的准确率达到96.29%,精确率、召回率、F值分别是91.61%、96.22%、93.85。所识别的5个实体的精确率、召回率和F值如表1所示。
表1中疾病名称和治疗的精确率相对较低,主要有两方面的原因。一是和训练测试数据不均衡相关,因为电子病历中包含的相关信息相对较少;二是和词典相关,随着医学技术的发展,许多新的治疗方法并未录入词典中。
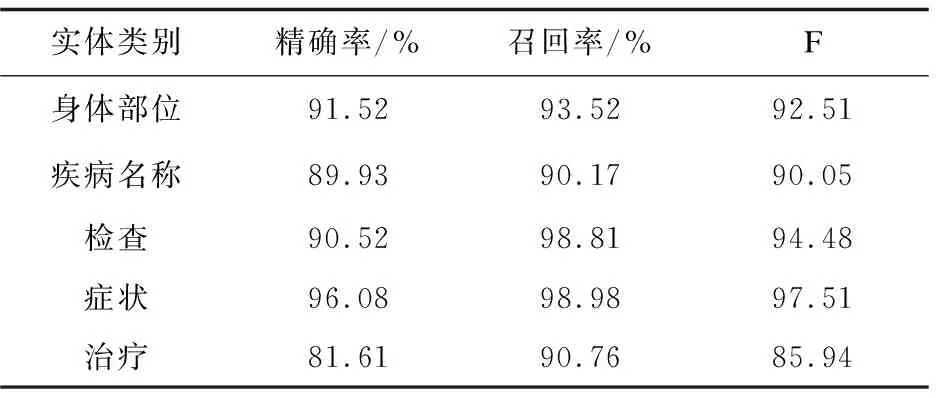
表1 LSTM-CRF多分类器性能评价指标
3 结束语
文中设计实现了基于LSTM-CRF的中文电子病历命名实体识别系统,该系统能识别五种实体类型,准确率达到了96.29%,超过了大多数多分类识别器的准确率。实验结果为基于中文电子病历的关系抽取和构建医疗知识图谱奠定了扎实的基础。另外,该系统也存在不足,需要进一步改进,如基于LSTM-CRF模型的训练时间。实验中,在没有GPU的环境下训练,在人工标注的400条语料上,花费了69个小时,在TITAN X (Pascal)GPU的环境下训练,仍然花费了3个小时,因此下一步工作将进一步完善模型,以缩短训练时间。
