基于ACO-PSO自适应的划分聚类算法
2019-02-25周文娟赵礼峰
周文娟,赵礼峰
(南京邮电大学 理学院,江苏 南京 210023)
0 引 言
在科技社会飞速发展的今天,人工智能应用已经遍及世界各处,受到了人们的重视。聚类作为常用的无监督学习方法,在识别数据对象的内在关系方面,起到了极其重要的作用。K-Means算法作为一种基于划分的经典聚类算法,根据差异度类内小类间尽可能大的原则进行聚类,基本思想通俗易懂,且聚类效果明显。但是该算法存在以下经典两大局限:(1)属于无监督的分类方法,聚类个数需要提前给出,不确定的K值对算法的性能影响很大;(2)易受初始聚类中心的影响,即不同的初始聚类中心聚类结果不同,容易陷入局部最优。学者们就以上问题提出了很多改进算法。
针对聚类中的K值问题,Pelleg等[1]在传统K-Means算法的基础上,对得到的K个聚类中心,利用贝叶斯信息标准(BIC)重新聚类以确定最佳K值;韩凌波[2]综合了类内与类间差异度,构建距离评价函数作为最佳K值检验函数。另外粒子群优化算法[3]也是一种全局优化算法,Merwe等[4]将PSO和K-Means进行融合,得到一种新算法,该算法充分利用K-Means较强的局部搜索能力和PSO的全局搜索能力,使得聚类结果更加精准;之后白树仁等[5]以粒子群算法收敛条件为改进的切入点,探索在给定不同K值情况下适应度函数的变化特征,提出能够自动调整K值的改进算法。
针对K-Means聚类的初始聚类中心易陷入局部优化问题,近年来,基于元启发式优化的改进算法得到广泛关注。元启发式算法的主要优点具有易实现、理论简单、随机搜索能力强等特点,可以应用于众多类别的组合优化中[6]。
国内外众多学者将启发式群优化算法与聚类分析结合应用到相关不同的领域。潘晓英等[7]提出基于适应步长的萤火虫划分聚类算法,在给定聚类数的情况下,该算法的随机性和全局搜索能力协助找到初始聚类中心;朱春等[8]在标准布谷鸟算法的基础上将发现概率P由固定值转变成随迭代次数逐步减小的变量,这样不仅可以提高搜索种群的质量,而且保证了算法的收敛;梁冰等[9]利用人工蜂群算法架构简单、全局收敛速度快的优势,提出一种改进的将人工蜂群算法与模糊聚类算法相结合的聚类算法,通过人工蜂群算法的启发性得到最优解,以此解决在模糊聚类算法求解过程中确定初始聚类中心的问题。
1 理论基础
1.1 蚁群算法
1.1.1 基本原理
蚁群算法(ant colony optimization,ACO)的基本思想是蚂蚁在觅食过程中会分泌一种特殊的物质—信息素,而蚁群之间的交流正是通过该物质进行信息传递以及分工协作。在一定范围内能够觉察到该信息素并指导它的行为,当某些蚁群在一些路径上留下足迹,也给其他蚂蚁提供了选择该路径的信号,使得蚂蚁越来越多,于是越发增加了信息素强度,形成一套正反馈学习系统慢慢接近最优路径。
1.1.2 模 型
蚁群算法通常在组合优化问题中应用广泛。所谓组合优化是某种离散对象按某个确定的约束条件进行安排,当已知合乎这种约束条件的特定安排存在时,寻求这种特定安排在某个优化准则下的最大或最小的解问题。
假如m只蚂蚁有可供选择的n个城市,每只蚂蚁进行每一步选择都是建立在前面蚂蚁选择该路径的基础上,然后提供给下一个还没有访问该路径的蚂蚁,t时刻位于城市i的蚂蚁k选择城市j为目标的概率是:
(1)
信息素更新方程为:
(2)
说明:
m—蚂蚁个数;
n—节点(顶点)个数;
ηij—边弧(i,j)的能见度,或称局部启发因子,一般取1/dij,dij表示路径(i,j)之间的长度;
(由城市i转移到城市j的可见度亦称启发信息)
τij(t)—边弧(i,j)的信息素轨迹强度;
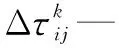
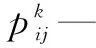
α—信息启发式因子,代表轨迹的相对重要程度(α≥0);
β—期望启发式因子,代表能见度的相对重要程度(β≥0);
ρ—信息素轨迹的持久性(0≤ρ≤1),1-ρ可理解为轨迹衰减度;
Q—体现蚂蚁所留轨迹数量的一个常数;
U—可行节点集合;
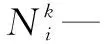
tabu(k)—一个列表,用于记录第k只蚂蚁到目前为止已经访问的城市。
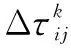
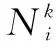
总体而言,三种模型各有所长,从局部考虑的是采用蚂蚁密度模型和蚂蚁数量模型,而全局考虑较好的一般利用蚂蚁圈模型。
1.2 粒子群算法
1.2.1 思想原理
粒子群算法(particle swarm optimization,PSO)利用群体间的信息共享和个体自身经验的总结不断修正个体的行为策略。在空间中,鸟被视作一个可以忽略大小的微粒,寻找最优解的过程就相当于鸟儿找到食物坐标的过程。每只鸟会分享当前时刻各自距离食物的最短路程,之后鸟群都会向着这个最短距离飞去,所以就会出现一聚一散,不断地变换方向,使整个群空间通过不断演化,从杂乱无章到一致协调,从而获得最优解。
1.2.2 模 型
假设在D维空间中,有m个粒子,粒子i位置:Xi=(Xi1,Xi2,…,XiD),粒子i的飞行速度为:Vi=(Vi1,Vi2,…,ViD),i∈[1,m],d∈[1,D],粒子i经历过的历史最好位置:Pi=(Pi1,Pi2,…,PiD),群体内(或领域内)所有粒子经历过的最好位置:pg=(pg1,pg2,…,pgD)(以上变量均为实数空间取值)。
基本PSO公式:
(3)
其中,c1,c2为学习因子或加速系数,一般为正常数,通常取2;r1,r2的取值范围是[0,1],是该区间内均匀分布的伪随机数;Vmax为粒子速度能达到的最大值。
粒子i第d维的速度更新公式为:
(4)
粒子i第d维的位置更新公式为:
(5)
说明:
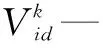
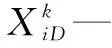
c1,c2—学习因子,调节学习的最大步长;
r1,r2—两个随机函数,取值范围是[0,1],以增加搜索随机性;
ω—惯性权重,调节对解空间的搜索能力。
2 自适应K值的个体轮廓系数算法
2.1 聚类数K值
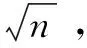
2.2 个体轮廓系数
轮廓系数是由Kaufman等提出的概念,其定义表达式如下:
(6)
不难看出,轮廓系数是所有个体轮廓系数的求和取平均,因此个体轮廓系数具体定义如下:
(7)
(8)
假设样本i被聚到C类,a(i)表示样本i和同属于C类的其他所有样本之间的平均距离,b(i)表示样本i和非C类的各个类中所有样本的平均距离的最小值。si表示类内样本与类间样本的差异性的最小值,从而体现样本聚类结果的优越性,其取值范围在[-1,1],取值越大,表示该样本的类内平均距离远与类间平均距离越明显,则说明对该样本的聚类达到了最优效果。
2.3 变化率函数
适应度函数是用来评价当前步骤聚类结果的好坏,针对个体轮廓系数,知道随着群集数量的增加,该值不断减少,通过绘制结果曲线,则可能会发现在达到某个K值时,平方距离的总和会突然下降很快,然后再慢慢减小。在这里,可以找到最佳聚类数。因此文中定义一种新的适应度函数—基于个体轮廓系数的变化率函数。
适应度函数值的大小表示聚类效果的好坏,越大越好,用式9表示算法的适应度。显然,不同的K值得到的适应度值不同,而在数据集合适的K值之前或之后,适应度值的大小有着明显的差异,一般是之前的幅度非常大,之后增大的程度很微小。因此,需要一个能反应单次变化程度在总变化过程中最突出的变量,从而引入变化率概念,表达式定义如下:
(9)
其中,用pk表示K时的变化率,ε表示一个很小的数。根据K值的特点可知,随着其值不断增加,pk逐渐减小,最后无限接近零,可以根据pk的变化来知道哪一步迭代为最佳迭代过程。
2.4 算 法
根据个体轮廓系数设计了K值优化算法,即在传统K-Means算法的基础上,通过个体轮廓系数优化K值,运算过程描述如下:
Input:n个数据对象的数据集;
Output:个体轮廓系数最小时的K值。
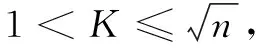
(2)利用K-Means算法计算出不同聚类数K下的聚类结果,在每个K值上重复运行数次K-Means(避免局部最优解);
(3)根据个体轮廓系数分别计算不同聚类数K下的S,计算当前K的平均轮廓系数;
(4)利用变化率函数搜索在变化率最大值下的相应K值;
(5)输出最佳聚类数K。
3 蚁群和粒子群融合算法
3.1 依 据
蚁群算法和粒子群算法作为人工智能领域的两大主要算法,两种算法的有效融合已经广泛应用于许多领域,如离散优化问题、旅行商问题、最大流最短回路问题等。粒子群算法也是起源于对简单社会的模拟,最初是模拟鸟群觅食的过程,但后来发现其是一种很好的优化工具。二者的优缺点对比如表1所示。

表1 算法对比
通过对比可以看出,蚁群算法多应用于离散变量问题处理,但是搜索时间很长,很容易陷入局部最优解,粒子群算法更加擅长解决连续问题,并且它具有收敛速度快、算法简单等优点。因此,针对优化初始聚类中心点,文中试图通过融合两大算法各自优势,找到一种更加科学合理的改进策略,并且融合两大算法策略已经被充分肯定。
如陈睿等[10]针对双边匹配问题,以求得利益最大化以及同时满足多方需求为主要目标,提出一种改进的粒子群蚁群优化算法。柴大宝等[11]考虑到蚁群算法的控制参数往往需要经验来取得,提出将粒子群算法应用于蚁群算法中,从而解决著名的旅行商问题。且融合算法验证得到新算法对于参数的调整工程量大大降低,避免了许多盲目查询的实验。潘鸿雁[12]将蚁群算法和粒子群算法融合到Ad Hoc网络组传播路由的研究中,用以解决单一算法存在的局限性,主要策略是用蚁群算法发现大量的路径并选出较优备选路径集后,通过粒子群算法的全局搜索能力[13]进一步搜索,然后依据其约束条件和调整算子交叉进行及时调整,解决算法在求解QoS组播路由问题中的最优路径。
3.2 融合策略
(1)PSO拥有粒子本身位置和速度参考信息,但是在进行精确求解过程中搜索能力差,不能充分利用反馈信息。将ACO引入到PSO系统的每次迭代过程中,以ACO每一代形成的解作为PSO的初始种群,然后经过PSO的多次迭代,通过其正反馈性进行不断调整,从而找到更好的解,提高求解速率,得到快速收敛。
(2)ACO是某种启发式算法和正反馈机制有机结合的产物,这种结合容易出现早熟现象,加上求解速度慢以及初始信息匮乏等缺点,将PSO引入到ACO中,使得蚂群算法具有粒子群算法独特的优势,从而可以根据全局和局部最优解及时进行有效调整。
3.3 算法过程
Input:n个数据对象的数据集D={X1,X2,…,Xn},聚类数目K,粒子群体大小N,初始化种群P(0);
Output:最优初始聚类中心。
(1)在给定聚类数下,随机选定初始聚类中心。首先按照K-Means算法随机或者人为给定初始聚类结果,然后通过计算粒子适应度值进行不断调整并给定粒子的速度。重复操作反复进行N次,共生成N个初始粒子群。
(2)对于粒子每一维适应度值,将其与它所经历的最好位置pid的适应值进行比较,如果更好,按照式4和式5更新pid,反之则进行下一步。
(3)对每个粒子适应度值,将其和群体所经历的最好位置pgd的适应值进行比较,如果更好,按照式3更新pgd,反之则进行下一步。
(4)对于新一代粒子,按照以下的蚁群算法优化,得到新个体的K-Means优化。
(a)对粒子的聚类中心编码,此步中信息素即为上述适应度值,按照式1和式2进行更新,以确定对所有粒子的聚类划分;
(b)按照聚类划分,计算新的聚类中心,更新粒子的适应度值,取代原来的编码值。
(5)如果满足结束条件(给定阈值或最大迭代次数),则结束,否则转步骤2。
4 实验仿真
该实验是基于MATLAB平台验证文中算法在处理大规模数据时的稳定性和鲁棒性,验证数据集来源于UCI机器学习网站,分别为Iris、Wine、Yeast三个分类数据集。各个数据集的属性特征如表2所示。
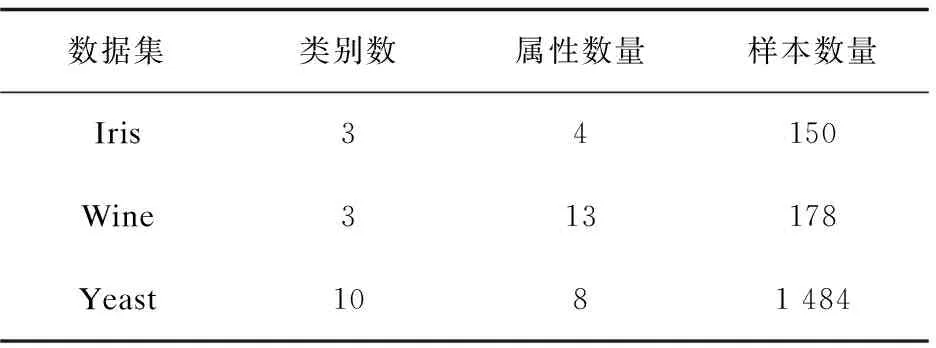
表2 数据集的属性特征
为了验证改进算法的稳定性和鲁棒性,从以下两部分进行讨论求解。
4.1 聚类数K的确定
根据文中提出的聚类数K确定算法,求出三种数据集的个体轮廓系数图,通过画出其个体轮廓系数图得到合理可视化的聚类数目,如图1所示。

图1 三个数据集关于K值的轮廓系数
由图1可知:
(1)针对数据集Iris,当K值等于2时,具有最大轮廓系数,而数据集实际分为了三个类,而K值取4之后,轮廓系数的变化趋势就不是特别明显。
(2)针对数据集Wine,K值等于3时,具有最大轮廓系数,而数据集实际也是三类,当K值取6之后,轮廓系数的变化趋势就不是特别明显。
(3)针对数据集Yeast,当K值等于3时,具有最大轮廓系数,实际也是十类,而K值取4之后,轮廓系数的变化趋势就不是特别明显。
综上,随着K值的不断增大,个体轮廓系数逐渐减小,并不能作为适应度函数的评价标准,所以需要选择一个合适的适应度函数—变化率函数。各数据集的个体轮廓系数变化率趋势图如图2所示。
利用变化率函数来判断最佳的聚类个数K,通过计算得出数据集Iris,Wine,Yeast的最佳聚类数为3,4,4。
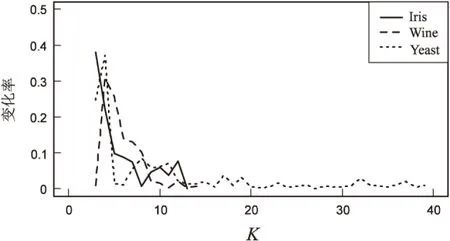
图2 三个数据集的相邻轮廓系数间的变化率
4.2 初始聚类中心的优化
由上一步可知,三个数据集的最佳聚类数均已确定,那么接下来分别针对这三个数据集进行初始聚类中心的优化。
确定选取粒子群大小均为N=30,当三个数据集Iris,Wine,Yeast的最佳聚类数分别为K=3,4,4,依次采用传统K-Means算法,基于个体轮廓系数自适应地选取优秀样本来确定初始聚类中心的改进算法(OICCABICC)以及文中算法(PSO-ACO),基于MATLAB对所提算法的有效性进行验证。
首先,通过粒子群算法选取的30个粒子种群进行加权求平均,得到问题的次优解,然后利用次优解的类内路径长度,类间形成的路径长度,作为蚁群算法信息素更新公式中的初始信息素,在蚁群算法中,蚂蚁的个数等于粒子个数,遍历城市个数等于聚类个数K,然后利用信息素更新公式得到最优解。新算法避免了优化过程中的搜索盲目性,并且加入了精确求解思想,从而显示新算法在求解能力和时间效率上的对比,如表3和表4所示。
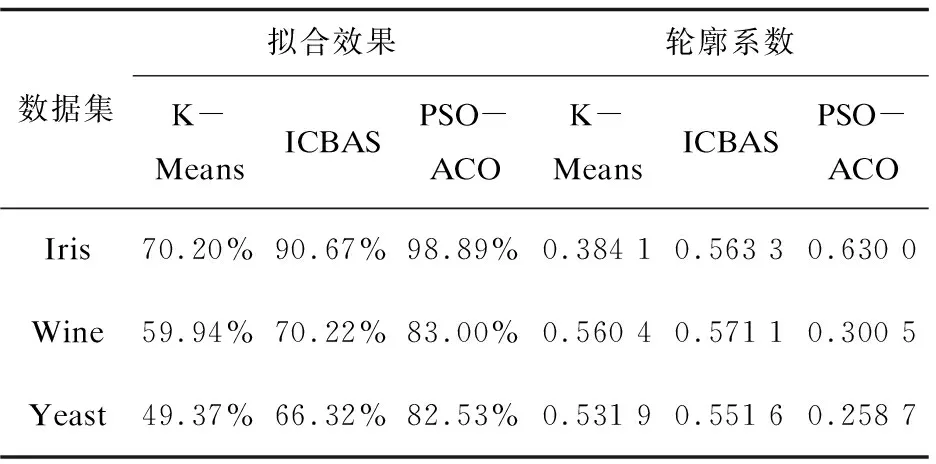
表3 新算法在求解能力上的优势比较
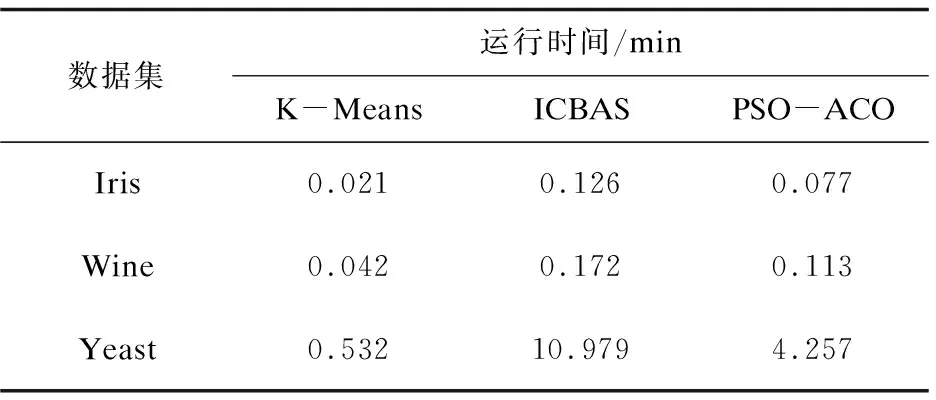
表4 新算法在求解效率上的优势比较
从以上结果可以看出,新算法较其他两种算法在求解效率和优化能力上有明显的优势。首先经过粒子群算法的优化,初始聚类中心得到了改善,不再是随机或者人为给定,避免了传统算法由于初期信息素缺乏而造成的盲目性,也有利于蚁群算法更精确的求解。
5 结束语
仿真实验表明,通过设定粒子群和以个体轮廓系数作为适应度函数评价准则,使得K-Means聚类的最佳聚类数目得以确定,个体轮廓系数结合粒子类内距离与类间距离,判断某个粒子被聚到某一类的合理性,数值越大,表明某粒子的类内平均距离与类间平均距离的差异性越大,即越合理;另外,通过设定粒子群,避免个体轮廓系数值陷入局部最优,文中将粒子群个数取30,30个粒子群的平均个体轮廓的系数值作为最终值。
初始聚类中心优化的好坏程度,主要体现在最终聚类的时间性能和优化性能上,文中算法的优势较其他算法均有体现,具有可行性。并且该算法能够应用于所有类型的数据集。此次实验数据是建立在小型数据平台实现的,对于大数据平台Hadoop应用是下一步研究的重点。
