微博情感分析的情感词典构造及分析方法研究
2019-02-25杨立月王移芝
杨立月,王移芝
(北京交通大学 计算机与信息技术学院,北京 100044)
0 引 言
近年来随着微博的广泛应用,微博用户越来越多,微博成为人们关注世界、社会、记录生活等的重要平台之一。随着网络的发展,微博情感分析也越来越重要。通过微博情感分析,商家可以及时得到消费者的反馈,并对下一步产销计划做出调整;政府机关根据微博用户对某一热点事件的评论得到大众对热点事件的观点,从而及时控制网络舆情的发展来保证公共秩序安全;对于消费者来说可以通过对微博中某一商品评论的情感分析统计,得出这一商品的优缺点,从而根据自身需求决定是否购买此商品。此研究正是基于这样的研究目的,在前人研究的基础上改进了微博情感词典并创建了语气词词典,利用中文语法规则判断微博文本的情感倾向性。
1 相关工作
近年来,微博的广泛使用使得微博情感分析成为热点方向,国外的微博研究较早并且相对较成熟,英文情感词典相对较丰富,如SentiWordNet和Inquirei。而国内对于微博的研究是近几年才开始的,情感词典还不太成熟,目前主要有知网HowNet词典和同义词词林、台湾大学和大连理工大学等高校提供的情感词汇库。该研究采用分类效果较好的HowNet词典作为基准情感词词典。
目前对于微博情感分析的研究主要分为两大类:基于情感词典的微博情感分析和机器学习。基于情感词典的微博情感分析就是利用现有的情感词典根据语义规则通过算法求出文本的情感值;机器学习是通过选取文本的一些特征标注训练集和测试集,使用朴素贝叶斯(Naive Bayes)、支持向量机(support vector machine,SVM)和最大熵(maximum entropy)等分类器进行文本分类。根据文献[1-2],常用的分类方法和特征选取方法有各自的适应情况,但都无法带来性能上实质性的变化。还有一些基于模型及研究模型提高分类效果的研究,如王伟等[3]提出一种基于LDA主题模型的评论文本情感分类方法,黄发良等[4]提出一种基于多特征融合的微博主题情感挖掘模型TSMMF,证明了该模型有更好的微博主题情感检测功能。
国内研究主要针对于新浪微博、腾讯微博等平台的微博信息进行研究。M Taboada等[5]提出了一种基于词典的文本情感提取方法。谢丽星等[6]提出基于SVM的层次结构多策略方法进行分类,且引入主题相关特征进行分类。周剑锋[7]提出在分析海量微博数据过程中,自动构建情感词典的方法。自动从语料中筛选情感词汇,获取情感新词。肖江等[8]构建的具有自动识别和扩展功能的领域情感词典具有可行性和准确率。王志涛等[9]提出基于词典和规则集的中文微博情感分词方法,根据规定的语义规则结合词典进行情感分析。王振宇等[10]提出一种HowNet和PMI(point mutual information)相融合的词语极性计算方法。实验结果中微平均和宏平均性能提高了5%。
分析以上理论,通过改进词典对微博进行分析和研究是微博分析的重点。
文中与传统方法不同的是改进了微博情感词典的构建方法,在传统新词根据点互信息计算进行筛选的基础上结合新词根据积极训练语料和消极训练语料的文档频数差筛选出新词并加入词典,同时研究提出构建语气词词典。
2 中文情感词典的构建
2.1 分 词
利用NLPIR分词系统进行分词,先构建好开源情感词典、表情情感词典和网络情感词典,在分词系统中将构建好的词典加入系统,从而提高分词效果。例如,未加入词典之前,网络新词“坑爹”得到的分词效果是“坑/v 爹/n”,加入词典后的分词效果是“坑爹/a”。
2.2 开源情感词典
目前中文情感词典中没有成熟完整的情感词典可供研究。文中采用情感区分较明显的HowNet中文情感词典和台湾大学NTUSD简体中文情感极性词典。知网的情感词典分为正面情感词、正面评价词、负面情感词、负面评价词,程度副词分为6个等级,分别为极其、很、较、稍、欠、超。知网情感词典中正面情感词、正面情感评价词均赋权值为1,而负面情感词和负面情感评价词均赋权值为-1。台湾大学NTUSD简体中文情感极性词典中分为两类词,积极词汇和消极词汇,将积极词汇赋权值为1,而消极词汇赋权值为-1,表1是开源词典情感词情况。

表1 情感词示例
2.3 否定副词词典
否定副词是整理的33个常用于否定后面词语的否定副词,将否定副词的权值全部设置为-1,否定词如“不”、“没”、“没有”、“无”、“非”等。
2.4 表情符号词典
文中在分析文本情感词的基础上融入分析表情符号,随着表情符号的流行人们越来越趋向于用表情符号表达自己的观点,所以首先加入了新浪微博中常用的默认的表情符号并赋予相应的权值。提取的微博语料中的表情词以“[]”形式出现,表情词列表见表2。

表2 表情词典示例
2.5 程度副词情感词典
采用知网提供的程度副词,示例见表3。
2.6 网络情感词典
网络新词:即多在网络上流行的非正式语言。多为谐音、错别字改成,也有象形字词。
基于微博文本非正式、口语化的表达特点,网络新词在微博评论中的应用越来越广泛。
由于网络新词的流行使得微博语言更多样化,如“我”不叫我,叫“偶”,“这样子”不叫这样子,叫“酱紫”,“喜欢”不叫喜欢叫“稀饭”,“新手”不叫新手叫“菜鸟”等。
文中选用百度引擎和搜狐引擎里的网络新词,集合了现在广为流行的网络用语,有较好的网络用词覆盖率,网络词示例见表4。

表4 网络情感词示例
2.7 微博情感词典构建
由于HowNet情感词典并不完整,在进行微博情感分析的过程中仍然有许多情感词汇无法判别情感倾向,刘培玉等[11]在传统词典的基础上构建领域微博情感词典,该方法在微博倾向性分析中得到了很好的效果。
根据微博数据分词结果对各个词语按词频统计并排序,对排好序的词语从上到下进行筛选,筛选出含有明显情感倾向且词频高的词语作为基准词,所以分词的好坏直接影响到排序结果。文中用的是NLPIR分词算法并且加入了知网情感词典,台湾情感词典,网络新词词典,表情词典中的词语,从而使得分词效果更好,得到更准确的基准词词语。朱嫣岚等[12]证明种子词越多,词的倾向性判断准确性越高,故文中在词频阈值范围内选取了27对种子词,同时考虑到表情符号元素,选取了2对高频表情符号做基准词。
2.7.2 点互信息
点互信息主要用于计算语义间的语义相似度,基本思想是统计两个词语在文本中同时出现的概率,概率越大相关性越紧密,关联度越高。两个词语word1和word2的PMI计算公式如下:
(1)
其中,PMI(word1,word2)表示两个词语同时出现的概率,即word1和word2共同出现的文档数;PMI(word1),PMI(word2)分别表示word1,word2单独出现的概率。
褒义和贬义基准词分别用Pw和Nw来表示,基准词的选取是具有明显情感倾向性的且极具领域代表性的词语。则候选集中候选词word1的情感倾向计算公式如下:
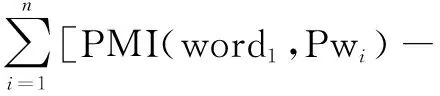
PMI(word1,Nwi)]
初中班主任要以科学合理的方式展开与学生之间的交流,帮助学生健康成长。能在谈话中了解学生的心理倾向,深化学生的情感变化,进而能更好的把握学生的心理情感变化,并在交流中包含学生的自尊心、自信心。
(2)
若SO_PMI(word1)>0,word1具有正面情感倾向,为正向情感词;SO_PMI(word1)<0,word1具有负面情感倾向,为负向情感词;SO_PMI(word1)=0,word1没有情感倾向,为中性情感词。
中文情感词情感倾向值计算方法首先选取基准词,通过计算基准词与候选词间的共现概率来初步确定该情感词的情感倾向值。计算情感词点互信息的计算过程如下:首先根据词频和情感词强度筛选得到基准词,其次根据程度副词提取新词并按词频阈值筛选,最后将新词和基准词进行PMI计算。
2.7.3 文档频数
wt=Fpos(wd)-Fneg(wd)
(3)
其中,wt表示词wd在语料中的频数差,其中Fpos(wd)表示词wd在正向语料中出现的次数,Fneg(wd)表示表示词wd在负向语料中出现的次数。当wt为0时,表示wd在正向语料和负向语料中出现的次数相等,直接删除该词。
2.7.4 微博新词抽取方法
陈建美等[13]分析了不同语法规律对情感词汇自动获取的作用大小,并且证明了情感词汇自动获取方法是有效的,其中否定词与词性搭配规律和程度副词修饰规律最为通用。汉语中程度副词经常修饰形容词及部分心理动词,而这些词多为情感词,如:非常开心,很郁闷等。所以在进行情感词汇抽取时选择程度副词和否定词后2/3/4个词范围内的词抽取出来。然后按照这些新词出现的频率进行排序,设定阈值,删除掉频率小于这个阈值的词汇,将筛选出来的新词和基准词做点互信息计算,若计算得出的点互信息结果为0,则不可以将该词加入情感词典,故删除该词。否则对新词进行文档频数统计,结合点互信息值进行筛选,若新词计算的点互信息值和计算得出的文档频数同为正数或同为负数,则将该新词加入词典,将新词的PMI值经处理后(若PMI值在0到10范围内,赋权值为1,在-10到0范围内,赋权值为-1,以此类推)作为对应的权值加入词典,具体步骤如图1所示。
2.8 语气词词典
姜杰等[14]将语气词数量作为语义特征提取,证明了语气词在情感表达中有重要作用。语气词在中文表达中经常会流露出感情倾向,例如“哎”,“啊”,“哇”,“耶”等。
文中从百度百科中查找的语气词大全,如“罢了”,“哈”,“呵”,“呸”等得到76个语气词,并扩展了没有提到的语气词,如“哎”,“哎呀”,共22个。语气词在词典中的权值设置和新词加入新词词典的权值计算方法一样,同样根据点互信息法和文档频数法筛选,最后将语气词及其权值加入语气词词典中。
3 语句情感分析
3.1 词语情感值的计算
语义是语句进行情感分类的重要特征[15],文档分类判断应按照词汇、句子、微博短文的步骤进行[16]。情感倾向情感词前经常有程度副词修饰。当情感词前有程度副词修饰时,则会使情感词的情感倾向加强或减弱。如开心是正向情感词,其权值为1,则很开心使得情感词情感倾向加强。而情感词前有否定词修饰时会使情感词的情感倾向反转,如“伤心”表示负向情感词,而“不伤心”表示正向情感倾向。但是存在一个问题,形如:“否定词+程度副词+情感词”的形式对情感词的强度有减弱作用。“程度副词+否定词+情感词”对情感词的情感强度具有加强作用。如很不开心和不是很开心的情感强度截然不同。故需要区分两种形式。情感词语的情感值计算公式如下:
否定词+程度副词+情感词:
w=d×a×t×0.5
(4)
程度副词+否定词+情感词:
w=d×a×t×2
(5)
其中,w表示计算得到的情感词语的情感强度值;t表示情感词的权值;a表示该情感词t前的程度副词的权值;d表示否定词的权值。
3.2 句间关系原则
赵天奇等[17]在语义规则描述部分,基本涵盖了汉语中最常用的几种句型规则和句间关系规则,从而使得对复杂句的情感分析更加准确。由于中文表达的传统习惯,一个句子可能包含多个关联词,而这些关联词对句子的情感表达有很大影响。如:虽然s1但是s2,其中,s2=w5w6w7,其中wi是一些情感词语。显然句子s1表达的情感强度没有s2的情感强度大。总结句间规则如下所述。
3.2.1 转折关系原则
当句子中出现转折时,如:虽然……但是……由于出现转折,则强调转折后的句子的情感倾向而减弱转折前的句子的情感倾向。邸鹏等[18]提出依据已有资源,并根据转折句式中否定词、转折词、情感词的组合规律进行情感分析的启发式规则,证明该方法能更好地对转折句式进行情感倾向性分析。转折语句情感分析规则如下,因为转折关系连接词并非都是成对出现,故分为以下三种情况。
将转折关系连接词分为转折前接词和转折后接词,其中转折前接词包括虽然、虽说、尽管等,转折后接词包括但是、可是、不过等。根据中文表达习惯,转折前接词会削弱用户要表达的意思,而转折后接词会加强用户要表达的意思。
(1)当分句只含有转折前接词时,设转折前接词出现在分句sk,则各句句间关系系数为:sk,sk+1,…=0.5。
(2)当分句只含有转折后接词时,设转折后接词出现在sk,则句间关系系数sk,sk+1,…=1.5。
(3)当分句既含有转折前接词又含有转折后接词时,句间系数为默认值1不变。
3.2.2 假设关系原则
当句子出现假设关系连接词时,句子强调的是条件,例如:如果s1,那么s2,则句子强调的是“如果”后面的内容即s1。设假设关系后接词如上例中的“那么”出现在分句si,则令s1,s2,…,si-1=1,si,si+1,…,sn=0.5。
3.2.3 因果关系原则
当句子中出现因果关系连接词时,表示强调的是因果关系前接词后的句子。例如:因为s1,所以s2,强调的是子句子s1的情感倾向。设因果关系前接词出现在分句si上,因果关系后接词出现在分句sj上,则si,si+1,…,sj-1=1.5,sj,sj+1,…,sn=1。
3.2.4 分句情感倾向计算公式
E(sj)=∑E(wi)*rj
(6)
其中,E(sj)表示第j个句子的情感倾向值;E(wi)表示第j个句子中的情感词的权值;rj表示第j个句子的句间关系系数。
3.3 句型关系
刘楠[19]将标点符号作为特征进行提取。当一个句子以“!”结尾时,该句的情感倾向明显加强。例如:“海燕儿,你可长点心吧!”表示的是加强句子的感叹作用,当句子以“!”结尾时,该句的情感倾向值变成原来的两倍。
当句子以“?”结尾并且该句子存在反向疑问词时,该句子表示的是质疑。例如:“难道你就不能开开心心独立自主吗?”,该句子中出现的情感词“开开心心、独立自主”均为正向情感词,该句子以“?”号结尾,并且出现反向疑问词“难道”,故该句的情感倾向将反向加倍。复句情感倾向值计算公式如下:
E(Ti)=∑E(sj)*Mi
(7)
其中,E(Ti)表示第i个复句的情感倾向值;E(sj)表示第i个复句中各个子句的情感倾向值;Mi表示句型关系系数,若该复句Ti以“!”结尾,则Mi=2,若Ti以“?”结尾,且Ti中含有反向疑问词,则Mi=-2。
3.4 首句和尾句
中文表达中有开门见山的表达习惯,故首句在短文本情感判断中具有很重要的作用。如:中文表达中尾句的情感倾向在微博情感表达中占得权重很大,故设置首句的加权关系系数为2,微博语句的尾句具有很重要的情感倾向判断价值,如“今年是交大120周年校庆,我很荣幸作为母校的学子。今天好开心呀,哈哈。但是没有和曾经的老同学们团聚真的太可惜了”。这段微博包含3句话,其中第1,2句表达了正向情感,而最后一句表达了负向情感。这段微博整体表达的是负向情感,以尾句的情感倾向为准,所以在微博表达中尾句的情感倾向具有非常重要的作用。故设尾句的加权关系系数为2,如计算首尾句的情感倾向值为E(Ti),则E(Ti)=E(Ti)*2。
4 实验与分析
实验选取NLPCC官方网站中Task A Annotated Training Data中的数据,主题包括IphoneSE、春节放鞭炮、俄罗斯在叙利亚的反恐行动、开放二胎、深圳禁摩限电,同时还加入了coae2014评测数据的task3& 4任务中对蒙牛的评论。正面数据2 019条,负面数据2 139条。判断标准如下:当微博情感值>1时,判断该微博为正面;当微博情感值<-1,判断该微博为负面;当微博情感值为0时,判断该微博为中性。实验结果如图2所示。
对比基准词词典+语义规则的结果和传统新词情感词典+基准词典+语义规则的结果可以发现,加入传统的新词词典判断的结果有个严重的弊端,负面微博的分类准确率骤降,而正面微博的准确率骤增,这是因为微博数据正面情感词比例远远大于负面情感词的比例。这对于分类判断来说是无效的。通过新的新词词典+基准词典+语义规则的结果可以观察到,加入新的新词词典后,正负面的微博分类的准确率都有不同程度的提高,这是因为当加入了文档频数筛选方法后,可以筛掉那些在负面微博中出现的大量正面情感词。
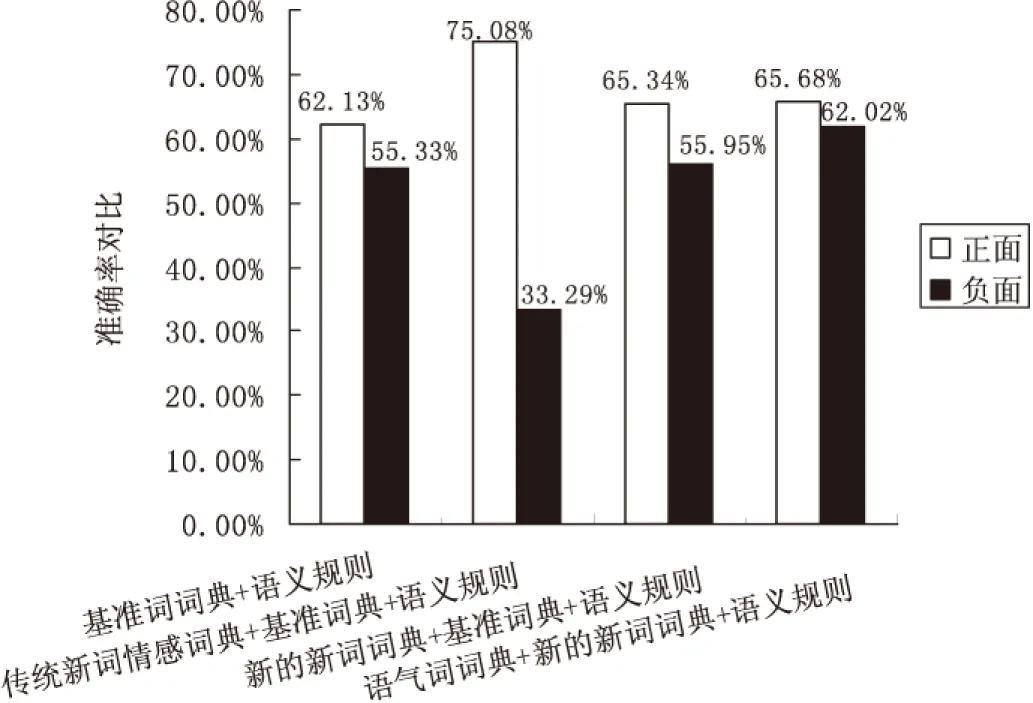
图2 准确率对比
对比新的新词词典+基准词典+语义规则的结果和语气词词典+新的新词词典+语义规则的结果可以发现,加入语气词词典后,正面微博的分类准确率没有明显变化,而负面微博的分类准确率有明显的提高。
5 结 论
在分析已有情感词典的基础上,建立了更全面完整的微博情感词典,在现有网络资源的基础上对微博语料进行统计建立网络情感词典和表情情感词典,通过词典的构建形成了更加完备的情感词典,用于情感分析。建好情感词典后根据中文的语义规则包括句间规则和句型规则,进行句子级的微博情感分析。文中的特点是加入了首句和尾句情感分析倾向的权重系数,从而提高了微博情感分析的正确率。本次研究的创新之处首先在传统的微博情感词典的构造上做出了改进,对新词通过点互信息和文档频数法进行筛选再加入词典。其次创建了语气词词典,有了语气词词典后负面微博分类的准确性有了明显的提高。
6 结束语
微博情感分析的关键是词典构建,词典的囊括范围及准确性对分类的准确率具有关键作用。文中构建了开源情感词典、表情情感词典、网络情感词典,并且改进了微博情感词典的构造方法,创建了语气词词典。利用改进后的词典,微博分类的准确率有了明显提高,通过实验证明了该方法的准确性。
但是微博分类还存在有待研究的方向。例如,微博文本中经常出现反讽现象,具有反讽现象的微博文本的情感倾向和用算法算出来的情感分析值相反;微博用户的情感表现不仅包括文本,还有微博的点赞信息,转载量等;由于微博用户发表的微博多接近于口语化,故微博文本经常出现拼写错误或符号省略等现象,如何识别这些错误并在情感分析中考虑这些因素带来的影响需要进一步研究;文中采用基于词典和语义规则的方法进行情感分类,将其作为特征,结合深度学习方式并与社会背景结合尚需进一步探索。
