基于概念漂移检测的土石坝压实质量评价模型更新研究
2019-02-22王佳俊钟登华吴斌平刘明辉张宗亮
王佳俊,钟登华,吴斌平,刘明辉,张宗亮
基于概念漂移检测的土石坝压实质量评价模型更新研究
王佳俊,钟登华,吴斌平,刘明辉,张宗亮
(天津大学水利工程仿真与安全国家重点实验室,天津 300350)
土石坝压实质量评价模型的更新对保证其长期高精度评价压实质量具有重要的意义,然而目前对于压实质量模型的更新还缺乏相应的研究.借鉴流数据中概念漂移检测的思想,同时针对碾压施工流数据具有不平衡数据、含有噪声且流速缓慢的特点,本文提出了一种基于概念漂移检测的土石坝压实质量评价模型更新方法.首先提出基于K-means的下抽样技术处理不平衡数据;其次提出基于增强概率神经网络(enhanced probabilistic neural network,EPNN)和可变窗口技术(variable window technique,VWT)的碾压施工流数据概念漂移检测方法;最后若检测到有概念漂移则进行压实质量评价模型的更新.工程应用表明:基于K-means的下抽样技术能保证分类器具有较高的一致性;基于EPNN与VWT的方法能有效地检测出碾压施工流数据概念漂移;同时以出现概念漂移为条件而更新的压实质量评价模型能够长期高精度评价压实质量.
压实质量评价模型;概念漂移检测;碾压施工流数据;增强概率神经网络;可变窗口技术;模型更新
土石坝压实质量评价模型对压实质量控制有着重要的研究意义.目前常用的压实质量评价模型主要有多元线性模型[1]、神经网络模型[2]、支持向量回归模型[3]等,在压实质量评价中发挥着重要的作用.然而这些模型利用历史数据建立模型,且建立好的模型随后被用来长期评价压实质量.但是由于气候变化、料场变化或施工机械更换等外部环境的改变,这些模型的性能可能会显著降低(如预测精度显著下降),此时压实质量评价模型需要更新后才能适应现有的数据.然而,目前有关压实质量评价模型更新的研究还相对匮乏,何时进行模型的更新是困扰研究者的一大难题.为此,本文借鉴流数据中概念漂移检测的思想,提出了一种基于概念漂移检测的压实质量评价模型更新方法.
流数据(stream data)是一种实时连续的数据信息序列,具有持续到达、速度快、规模宏大等特征,常见于商业运作或者互联网操作中[4].流数据中包含的概念会随着时间的推移发生显著或缓慢的变化,即出现了概念漂移(concept drift),这给流数据挖掘带来了极大的困扰[5].因此,进行流数据分析时需要进行概念漂移检测,并对出现的概念漂移现象加以处理,模型才能够适应后续到来的流数据.目前在流数据中常用的漂移检测方法主要有3类:性能法、距离法和统计法.性能法是通过检测已建立的概念在新来的数据上是否出现性能下降而提出的方法,如OLIN 法[6]和基于模糊聚类的检测方法[7]等;距离法是将流数据映射到特征空间中抽离出特征向量,检测新来的流数据的特征向量是否偏离了已有的特征向量集而进行概念漂移检测,如“概念向量”法等[8].统计法是考虑数据的分布特征来检测新来的数据与之前的数据是否具有相似的分布而提出的方法,如统计学中的熵[9]、鞅等[10]常被用来检测概念漂移.
目前,完整的碾压施工数据包括碾压参数、料源特性参数、物理特性参数(由振动信号分解的基波和一次谐波的振幅表征)和压实质量参数[11].借助于本课题组的碾压监控系统[12],可实时获取碾压参数和物理特性参数;借助于本课题组PDA信息采集系 统[13],可获取料源特性参数;借助于试坑试验,可获取压实质量参数(本文以压实度作为压实质量参数).这些参数集成在数据服务中心,且随着时间的推移不断地增加,形成所谓的“碾压施工流数据”.与商业运作或互联网操作等流数据不同的是,土石坝碾压施工流数据具有自己的特点:数据不平衡、含有噪声且流速缓慢.试坑试验中压实质量参数绝大部分是处于合格状态(如压实度处于98%~100%之间),少有不达标(压实度小于98%)或超标(压实度大于100%)的不合格数据,两种数据的比例十分悬殊,因此碾压施工流数据是不平衡数据;受外界干扰影响,碾压施工数据尤其是用振动特性表针的物理特性参数含有一定的噪声,因此碾压施工流数据具有含噪的特征;受限于现有的质检技术(试坑试验),完整的碾压施工数据的获取比较缓慢,因此,碾压施工流数据具有流速缓慢的特征.
不平衡数据会造成分类器向多类倾斜,影响分类结果的一致性.目前的研究主要从数据层和算法层两个方面处理不平衡数据.数据层的方法主要包括上抽样和下抽样,前者试图增加少类的训练样本,如SMOTE技术[14],而后者试图减少多类的训练样本,如Tomek Link和一致子集等[15].相关的实验研究表明没有一种是绝对占优的抽样方式[16].算法层的方法主要包括代价敏感性学习、分类器后处理、极小极大概率机等[17],同样也是试图增加少类的信息或减少多类的信息以达到平衡数据的目的.然而,这些方法少有考虑到多类样本中可能包含多个子概念的问题.因此本文提出了一种基于K-means的下抽样方法来处理碾压施工样本空间中的不平衡数据,既保证抽样出的训练集能基本保持原数据蕴藏的建模信息,也解决了多类中可能含有多个子概念的问题.
与商业运作和互联网操作的流数据概念漂移一致,称包含于碾压施工流数据中的概念(如建立的回归模型、分类模型等)发生缓慢或显著的变化(表现为回归模型或分类模型的精度出现缓慢或显著下降)的现象为碾压施工流数据概念漂移.为了检测出流速缓慢、含噪的碾压施工流数据概念漂移,提出了一种基于增强概率神经网络(enhanced probabilistic neural network,EPNN)和可变窗口技术(variable window technique,VWT)的概念漂移检测方法.该方法首先在处理过不平衡数据的样本空间上建立EPNN分类器,然后利用EPNN分类器对可变窗口内的流数据进行概念漂移检测.虽然常用的模型树方法在保证一定精度的条件下能解决流速极快的流数据分类问题,但对噪声的容忍能力较 差[18].而通过局部决策圈(local decision circles,LDCs)强化概率神经网络(probabilistic neural network,PNN)得到的EPNN能有效的解决含噪数据的分类问题[19],该算法已在图像识别[20]和矿物资源探测等[21]很多领域得以应用.窗口技术是处理流数据非常有效的方式,将流数据分成不同的数据块,并对数据块蕴含的概念进行检测[22].然而窗口大小的确定十分困难,因此一些可变窗口技术被提出来,如根据流数据流速设计的可变窗口[23]和基于相位一致性设计的可变窗口等[24].本文中可变窗口的大小由EPNN分类器在流数据上的误分个数确定,且当可变窗口的大小出现异常变化时,可认为检测出概念漂移.该方法实质是性能法,但不同于模型性能的直接检测,该方法是将分类模型性能的改变体现到可变窗口大小的变化上,从而使得该方法对概念漂移更为敏感,更容易检测出概念漂移.当出现概念漂移时,考虑到碾压施工流数据流速缓慢的特点,可直接根据新窗口内的数据重新建立压实质量评价模型,实现模型更新,保证其长期高精度对压实质量进行评价.
综上所述,本文提出了基于K-means的下抽样技术处理不平衡数据,保证分类器分类结果的一致性;提出了基于EPNN和VWT的概念漂移检测方法,实现了对碾压施工流数据概念漂移检测;以检测出现概念漂移为条件而更新压实质量评价模型,保证了其长期高精度地评价压实质量.
2 研究框架
本文研究了基于概念漂移检测的压实质量评价模型的更新问题,研究框架如图1所示.

图1 研究框架
首先,通过压实质量实时监控系统、PDA信息采集系统和现场试坑试验得到的碾压施工样本数据和流数据;针对碾压施工样本数据中存在着数据不平衡的问题,同时考虑到多类中可能包含的多个子概念,提出了基于K-means的下抽样方法来处理该不平衡数据.
其次,针对实际施工中存在着噪声数据的问题,采用抗噪能力较强的EPNN在处理不平衡数据的样本空间中建立起压实质量分类器.EPNN通过LDCs强化之后具有较强的抗噪能力,适合建立压实质量分类模型.
最后,EPNN模型在可变窗口上检测概念漂移.将碾压施工流数据放入到可变窗口中,窗口的大小由EPNN的误分个数决定;当可变窗口的大小超出95%置信区间时,表明该可变窗口大小发生异常变化,窗口内的流数据发生了概念漂移.若未出现概念漂移,则更新系列窗口大小的均值和方差;若出现概念漂移,则用该窗口内的数据创建新的EPNN分类器;同时该数据用于压实质量评价模型的重建,实现模型的更新.
3 压实质量评价模型的概念漂移检测
3.1 碾压施工流数据概念漂移检测数学模型
碾压施工流数据概念漂移检测的数学模型由目标函数、数据集、方法集3部分组成.
(1) 目标函数.该模型的目标函数是以数据集Data和方法集Method为基础来检测碾压施工流数据上是否存在概念漂移的现象,因此目标函数为
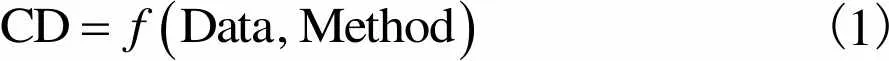
(1)
式中CD是一个布尔变量,当存在概念漂移的时候为true,反之为false.


(2)
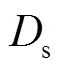

(3)
3.2 基于K-means的下抽样技术处理不平衡碾压施工数据
下抽样技术能够有效地减少多类样本的数量,但是不合理随机下抽样会降低多类样本中包含的建立分类器模型所需的信息.为了避免信息的损失,一些基于欧氏距离的方法如Tomek Link、一致子集等被提了出来[15].考虑到多类中可能包含多个概念集合,本文提出了一种基于K-means的下抽样方法,避免减少多类数据信息的丢失,具体步骤如下.
步骤1 采用K-means算法对多类数据进行聚类分析.

(4)
步骤2 计算每个类簇中数据的距离信息.

(5)
步骤3 按照每个类簇的距离信息进行数据的抽样,抽样的策略如下.
首先计算出应该从每个类簇中抽取数据的个 数,即

(6)
图2 多类数据样本抽取
Fig.2 Schematic of data sample extraction from multiple classes
3.3 EPNN建立压实质量分类模型
考虑到碾压施工流数据中含有大量的噪声数据,本研究采用具有较强抗噪能力的增强概率神经网络(EPNN)建立压实质量分类模型.与概率神经网络(PNN)一样,EPNN具有4个结构层次,分别是输入层、模式层、求和层和输出层,其结构示意如图3所示.
在日常饲喂中需要做好消毒免疫以及定期驱虫工作,进行感染源的有效控制,避免一系列传染病的发生,减少不必要的损失。
EPNN按照最大相似准则对数据进行分类,同时利用LDCs考虑数据的局部密集性和异质性,从而实现对噪声数据的容忍.EPNN对每个数据所属某一类的概率为
(7)
式中:代表第i类中第j个训练数据;d表示输入向量空间的维度;代表第i类训练数据的个数;代表高斯函数的宽度系数;表示以为中心点r为半径的超球面中 与同属一类的比例. EPNN以所属概率最大进行分类,即
采用的柔爆索由中国兵器工业集团804厂生产,它是一种在航天和兵器工业中普遍使用的火工品。柔爆索的中心为装药药芯,药芯外面包覆有一层铅层,如图2所示。
(8) 图3 EPNN结构示意 Fig.3 Schematic of EPNN structure
同时,以分类准确率和Kappa统计值作为EPNN的性能指标,其公式公别为
(9)
(10)
式中:C代表混淆矩阵;测定分类结果的精度,而Kappa测定分类结果的一致性.
3.4 VWT与概念漂移检测方法
所谓窗口技术,即将一定量数据放在同一个窗口内进行分析.目前大多数概念漂移检测方法采用大小固定的窗口来分析流数据.但是,确定合适的窗口大小十分困难.若窗口过大,则很难检测出概念漂移现象;若窗口过小,其数据又不能包含足够信息用于更新模型.本文采用可变窗口技术解决这个问题.在可变窗口技术中,窗口的大小由已有的分类器与新的流数据之间的某种关系确定.本文采用EPNN模型的误分个数作为这种关系的度量,因此,窗口的大小的表达式为
(11)
式中:为最新的窗口;盛放按顺序到达的数据集;表示被错误分类的数据集;表示数据集的长度.因此,式(11)表达了检测到误分个数为n的数据窗口的大小;同时也可以看出,可变窗口中数据集总是以误分数据结束.一般来说,当未出现概念漂移的情况下,应维持在一个较为稳定的范围内.假设在出现概念漂移之前的,从1到i-1窗口的均值为,方差为,如果第i窗口的大小,表明i窗口中数据在95%置信水平上未出现概念漂移,反之则出现了概念漂移.因此,基于EPNN和VWT的概念漂移检测算法流程下.
同时在实际应用中,当出现概念漂移的时候,新窗口内的碾压施工数据被用于更新EPNN分类器和压实质量评价模型.
算法1 基于EPNN和VWT的碾压施工流数据概念漂移检测方法.
由上式可知,在[0,1]区间上,度量ρπ和度量d(a,b)=|a-b|是等价的,因此关于ρπ的Cauchy-列就是关于d的Cauchy-列。d是[0,1]上的通常度量,[0,1]关于d是完备的,因此Cauchy-列{xn}关于d是收敛的。设{xn}关于d收敛到A,由于度量ρπ和度量d(a,b)=|a-b|是等价的,因此{xn}关于ρπ收敛,且收敛到A。
输入:历史样本数据,K-means的K,EPNN的和LDCs的半径r,误分个数n,接入碾压施工流数据.
输出:是否出现概念漂移.
步骤1 采用基于K-means的下抽样技术处理不样本中平衡数据生成新样本,如式(4)~(6)所示.
步骤2 采用EPNN建立碾压质量分类器.
步骤3 根据历史样本数据,采用EPNN建立起历史可变窗口系列,并求出和.
步骤4 对于接入的碾压施工流数据.
if EPNN分类错误
++;
if
计算新窗口的大小
系统梳理企业对外交易违规问题,全面查摆应招标未招标、违规招标、评标、虚假合同、拆分合同、事后合同等违规问题,对重大风险做出合规风险评估和预警,有针对性的研究制定具体防范措施,从制度机制层面堵塞管理漏洞。突出质量安全环保、资源权属、劳务用工、采购销售等重点领域合规监管,强化合规监管部门和业务部门主体责任和分工。结合企业实际,不定期组织合规专项检查,总结、反馈查处问题,逐渐形成符合企业运行模式的管控措施和机制。
if超出[]
return true;
病死动物无害化处理信息化管理是加速畜牧养殖产业健康发展、确保病死动物不上市销售、严格无害化处理的必然选择,更是加速畜牧养殖产业向现代化方向发展的重要举措[1]。在病死动物无害化处理中,积极应用信息化管理技术能实现精准病死动物无害化处理。病死动物从申报、现场认定以及审核补贴等环节,全部纳入信息化管理系统中,减少了报表打印传递过程,简化了处理手续,操作更容易。
else
1.3.1 胃肠道功能障碍评分标准 按照1995年全国危重病急救医学学术会制定的标准计分[7]:轻度腹胀、肠鸣音减弱,记1分;高度腹胀、肠鸣音近于消失,记2分;麻痹性肠梗阻、应激性溃疡出血,记3分。
更新和
return false;
end if
endif
end if
4 工程应用
某水电工程位于我国西南地区,是世界级高心墙堆石坝.检测该工程的碾压施工流数据中是否存在概念漂移,明确是否应进行压实质量评价模型更新,维持压实质量评价模型长期高精度评价压实质量,对保证该工程质量具有十分重要的意义.以该工程2016年11月初到2017年5月底心墙区的250个施工单元共626条数据为样本展开研究,数据分布如图4所示.
研究表明,不同性格的消费者在化妆品消费行为,选择偏好等方面存在差异。基于化妆品的特点以及女性消费者性格因素对于化妆消费和使用的影响,营销人员在选择营销策略时应充分考虑女性消费者性格特点以及其所处的心理状态。
从图4中可以看出,合格的压实质量数据相较于未达标(约为6∶1)和超标数据(约为5∶1)多出许多,表明碾压施工流数据为不平衡数据,这将造成建立的EPNN分类器朝着多类倾斜,因此需要进行不平衡数据处理.本文中,样本空间中每一类的30%作为测试数据,70%作为分类器的训练数据.因此,共438条数据作为训练样本,188条作为测试样本.采用提出的基于K-means下抽样技术和基于EPNN和VWT的概念漂移检测方法的应用情况详见后续分析.
4.1 基于K-means下抽样技术对EPNN模型精度影响
EPNN中LDCs的半径取训练数据的超球面半径的0.1倍,高斯宽度取0.6.以3.2节中基于K- means的下抽样技术中不同的K值采取的样本建立起不同的EPNN分类器,并以十折交叉(如图5所示方式)中模型的分类准确率(式9)和Kappa统计值(如式(10)所示)作为分类性能指标,不同聚类个数K对EPNN分类的结果影响如表1所示,K=0代表未进行下抽样技术处理的数据.
图4 数据分布 Fig.4 Data distribution
从表1中可以看出:比较未进行下抽样和进行了下抽样建立的分类器,虽然未进行下抽样的分类器在精度上比一些进行了下抽样的分类器(如K=2和K=6)要高,但它的Kappa值却远低于进行了下抽样的分类器,这表明分类器朝着多类倾斜,没有较好的一致性;同时比较进行了下抽样的分类器发现,当聚类个数为4的时候,EPNN性能最佳,这也从侧面反映了多类数据中可能包含有4个子概念,且Kappa值和呈现出较好的一致性;因此该聚类个数下的样本被用来建立EPNN分类器.通过上述方式,438条训练样本压缩至216条.
图5 碾压施工流数据分类器K折交叉验证精度计算结构 Fig.5 Calculation structure of K-fold cross validation precision for compaction stream data classifier
表1 不同聚类个数K对EPNN模型精度的影响
Tab.2 Influenceofdifferent clustering Numbers K on the precision of EPNN model K/%Kappa值 089.940.7531 191.600.8744 289.240.8380 392.400.8856 495.580.9335 590.360.8551 688.400.8255 791.530.8724 890.760.8611 990.690.8600 1093.900.9082
4.2 EPNN模型的分类精度对比
为了验证EPNN模型的分类精度,常用的分类算法如随机森林(RF)、支持向量机(SVM)、人工神经网络(ANN)和概率神经网络(PNN)等被用来作为对比.通过下抽样得到的216条数据分别建立EPNN分类器、RF分类器、SVR分类器、ANN分类器和PNN分类器,对比它们的对于测试数据集的和Kappa值,结果如表2所示.混淆矩阵中,第1行表示未达标数据,第2行表示超标数据,第3行表示合格数据.
表2 不同模型的分类效果对比
Tab.2 Comparisonofclassification effects of different models 分类器混淆矩阵/%Kappa值 EPNN95.740.8921 RF91.490.8191 SVR73.400.5092 ANN90.430.7995 PNN90.960.8092
从表2中可以看出,EPNN分类器具有更好的分类精度和一致性,究其原因是因为碾压施工样本数据中含有噪声数据,而引入了LDCs技术的EPNN在抗噪方便表现出优良的性能.
枞阳县电商扶贫主体企业潜山和沐电子商务有限公司枞阳运营中心总经理李小多介绍,公司正在谋划注册统一的商标,积极寻求规模化、专业化生产路径,打造属于枞阳县的特色品牌,让电商扶贫走得更远。
4.3 碾压施工流数据概念漂移检测
从2017年6月初到2018年5月底,由于现场施工运行的逐渐稳定,施工进度得以加快,共获取到心墙区1274个施工单元的3200条完整的碾压施工数据.这段时间内的碾压施工数据按照流数据的方式进入训练好的EPNN分类器,设置可变窗口容纳的误分个数为5,其窗口大小变化如图6所示,窗口内分类器的和Kappa值如图7所示.
从图6和图7中可以看出:当碾压施工流数据进入第6个可变窗口的时候,其窗口的宽度小于(由前5个窗口确定的均值,方差),此时EPNN分类器的性能下降,由0.95的下降到0.92,Kappa值由0.92下降至0.77,因此可认为该窗口内施工流数据上出现了概念漂移的现象.同时可以看出,精度的下降并没有窗口大小变化明显,因此本文将窗口大小作为衡量模型性能下降的方式,能更容易检测出是否存在概念漂移.有趣的是,在第19个可变窗口到第20个可变窗口时,再次出现概念漂移,可窗口大小恢复到102.8水平,恢复到0.95水平,Kappa值恢复到0.92水平,可认为出现的新的概念与前5个窗口中流数据包含的概念相同.考虑到外界条件变化(如碾压设备的更换、季节的变迁、料场的更替以及碾压方案的变更等)是引起概念漂移的主要因素,结合该工程实际施工状态和碾压施工流数据出现概念漂移的时效性,季节的变迁是本研究中出现周期性概念漂移的主要原因.然而在未来的实际施工中并不知道出现了何种概念,同时考虑到碾压施工流数据流速慢的特点,只需要在出现概念漂移的时候,对压实质量评价模型进行更新即可.
4.4 模型更新对比分析
考虑到碾压施工流数据流速较慢的特点,没必要采用适用于流速极高、频繁发生概念漂移的流数据的模型树作为压实质量评价模型,仅以发生概念漂移为更新模型的先决条件.本文采用文献[3]中CFA-SVR模型作为压实质量评价评价模型,该模型基于结构风险最小化原则,具有较高的精度和较强的泛化能力.同样,以本文经过下抽样的数据集建立压实质量评价模型,图8展示更新模型与不更新模型的实际值与输出值残差对比.
从图8中可知,当出现概念漂移的时而更新的压实质量评价模型,残差值维持在0.1167±0.1127水平;未更新的压实质量评价模型的残差维持在0.4805±0.4608水平,其中,符合概念的流数据残差数据在0.1242±0.1250,不符合概念的流数据残差为1.1110±1.0549.由此可见,采用概念漂移检测的方式进行模型的更新能够将压实质量评价模型维持在较高的一个水平上.
图6 可变窗口大小变化 Fig.6 Variation of variable window size
图7 和Kappa值变化 Fig.7 Changes of the and Kappa
图8 压实质量模型更新与未更新残差对比 Fig.8 Residual comparison between the updated and the nonupdated compaction quality model
5 结 论
本文提出了基于概念漂移检测的压实质量评价模型更新方法,主要取得如下的研究成果.
毛泽东心中的“中国梦”,既是强国梦,也是富民梦,梦想有一天把国家建设成世界上最发达、最文明的国家,人民改造成为世界上最先进、最文明的人。虽然有时急于求成,忽视了客观规律,但是这中间透出了的是民族精神和民族力量。干事业就是要得“一股子劲”!抚今追昔,毛泽东为梦的奋斗给我们留下的是一种精神、一种信念、一种激励和一种希望。如今的中国日益强大,人民生活和民族素质不断提高,毛泽东当年的梦想有的已经变为现实,但人类追梦的过程永无止境,我们现在正聚气凝神为全面建成小康社会而努力奋斗,只要我们坚持毛泽东思想和中国特色社会主义理论体系,坚定不移走中国特色社会主义道路,现代化和民族复兴的“中国梦”一定能够实现!
(1) 提出了基于K-means的下抽样方法处理碾压施工流数据中的不平衡数据.该方法不仅保证了多类数据建模信息的相对完整,同时也考虑了多类中可能包含的多个子概念.工程应用表明,经过该方法处理后的样本训练出的分类器具有更好的一致性.
(2) 提出了基于EPNN和VWT的碾压施工流数据概念漂移检测方法.对于含噪的碾压施工流数据,EPNN相较于常用的分类器具有更高的和Kappa值;同时以EPNN模型的误分个数来确定可变窗口的大小,并根据可变窗口大小的变化能更容易确定流数据是否出现概念漂移.工程应用表明,该方法能有效地检测碾压施工流数据上的概念漂移.
(3) 检测到概念漂移作为压实质量评价模型更新的先决条件,成功地解决了何时更新压实质量评价模型的问题.工程应用表明,更新模型能够维持更好压实质量评价模型的精度,而未更新的模型在不符合概念的流数据上表现出较差的评价精度.
本文采用的概念漂移检测的思想对于土建工程中模型更新研究具有重要的借鉴意义,同时在未来的研究中,应开展对碾压施工流数据中概念重复学习的研究.
参考文献:
[1] Meehan C L,Cacciola D V,Tehrani F S,et al. Assessing soil compaction using continuous compaction control and location-specific in situ tests[J]. Automation in Construction,2017,73:31-44.
[2] 刘东海,王光烽. 实时监控下土石坝碾压质量全仓面评估[J]. 水利学报,2010,41(6):720-726.
Liu Donghai,Wang Guangfeng. Compaction quality evaluation of the entire rolled unit of earth dam based on real-time monitoring[J]. Journal of Hydraulic Engineering,2010,41(6):720-726(in Chinese).
[3] Wang Jiajun,Zhong Denghua,Wu Binping,et al. Evaluation of compaction quality based on SVR with CFA:Case study on compaction quality of earth-rock dam[J]. Journal of Computing in Civil Engineering,2018,32(3):05018001.
[4] 金澈清,钱卫宁,周傲英. 流数据分析与管理综述[J]. 软件学报,2004,15(8):1172-1181.
Jin Cheqing,Qian Weining,Zhou Aoying. Analysis and management of streaming data:A survey[J]. Journal of Software,2004,15(8):1172-1181(in Chinese).
[5] 文益民,强保华,范志刚. 概念漂移数据流分类研究综述[J]. 智能系统学报,2013,8(2):95-104.
Wen Yimin,Qiang Baohua,Fan Zhigang. A survey of the classification of data streams with concept drift[J]. CAAI Transactions on Intelligent Systems,2013,8(2):95-104(in Chinese).
[6] Nishida K,Yamauchi K. Detecting concept drift using statistical testing[C]//International Conference on Discovery Science. Berlin,Germany,2007:264-269.
[7] 陈小东,孙力娟,韩 崇,等. 基于模糊聚类的数据流概念漂移检测算法[J]. 计算机科学,2016,43(4):219-223.
Chen Xiaodong,Sun Lijuan,Han Chong,et al. Detecting concept drift of data stream based on fuzzy clustering[J]. Computer Science,2016,43(4):219-223(in Chinese).
[8] Katakis I,Tsoumakas G,Vlahavas I. Tracking recurring contexts using ensemble classifiers:An application to email filtering[J]. Knowledge and Information Systems,2010,22(3):371-391.
[9] 张 杰,赵 峰. 流数据概念漂移的检测算法[J]. 控制与决策,2013,28(1):29-35.
Zhang Jie,Zhao Feng. Detecting algorithm of concept drift from stream data[J]. Control and Decision,2013,28(1):29-35(in Chinese).
[10] 张育培,柴玉梅,王黎明. 基于鞅的数据流概念漂移检测方法[J]. 小型微型计算机系统,2013,34(8):1787-1792.
Zhang Yupei,Cai Yumei,Wang Liming. Method of concept drifting detection based on martingale in data stream[J]. Journal of Chinese Computer Systems,2013,34(8):1787-1792(in Chinese).
[11] Liu Donghai,Li Zilong,Lian Zhenhong. Compaction quality assessment of earth-rock dam materials using roller-integrated compaction monitoring technology[J]. Automation in Construction,2014,44:234-246.
[12] Zhong Denghua,Cui Bo,Liu Donghai,et al. Theoretical research on construction quality real-time monitoring and system integration of core rockfill dam[J]. Science in China Series E:Technological Sciences,2009,52(11):3406-3412.
[13] Zhong Denghua,Liu Donghai,Cui Bo. Real-time compaction quality monitoring of high core rockfill dam[J]. Science China Technological Sciences,2011,54(7):1906-1913.
[14] Chawla N V,Bowyer K W,Hall L O,et al. SMOTE:Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research,2002,16(1):321-357.
[15] Batista G E,Prati R C,Monard M C. A study of the behavior of several methods for balancing machine learn- ing training data[J]. ACM SIGKDD Explorations Newsletter,2004,6(1):20-29.
[16] Duan K,Keerthi S S,Poo A N. Evaluation of simple performance measures for tuning SVM hyperparameters [J]. Neurocomputing,2003,51(2):41-59.
[17] 林智勇. 基于核方法的不平衡数据学习[D]. 广州:算机科学与工程学院,华南理工大学,2009.
Lin Zhiyong. Imbalanced Data Learning Based on Kernel Methods[D]. Guangzhou:School of Computer Science and Engineering,South China University of Technology,2009(in Chinese).
[18] Wibisono A,Jatmiko W,Wisesa H A,et al. Traffic big data prediction and visualization using fast incremental model trees-drift detection(FIMT-DD)[J]. Knowledge-Based Systems,2016,93:33-46.
[19] Ahmadlou M,Adeli H. Enhanced probabilistic neural network with local decision circles:A robust classifier[J]. Integrated Computer-Aided Engineering,2010,17(17):197-210.
[20] Olmeda D,Premebida C,Nunes U,et al. Pedestrian detection in far infrared images[J]. Integrated Computer-Aided Engineering,2013,20(4):347-360.
[21] Esposito S,Iervolino I,D′Onofrio A,et al. Simulation-based seismic risk assessment of gas distribution networks[J]. Computer-Aided Civil and Infrastructure Engineering,2015,30(7):508-523.
[22] Veksler O. Fast Variable window for stereo correspon-dence using integral images[C]// IEEE Computer Soci-ety Conference on Computer Vision & Pattern Recognition. Madison,USA,2003:556-561.
[23] 郭永水,牛建伟,覃少华,等. 基于可变窗口的流媒体缓存算法研究与实现[J]. 计算机工程与应用,2004,40(35):41-43,63.
Guo Yongshui,Niu Jianwei,Qin Shaohua,et al. Research and implementation of streaming data media caching algorithm based on variable window[J]. Computer Engineering and Applications,2004,40(35):41-43,63(in Chinese).
[24] 郭龙源,孙长银,张国云,等. 基于相位一致性的可变窗口立体匹配算法[J]. 计算机科学,2015,42(增1):13-15.
Guo Longyuan,Sun Changyin,Zhang Guoyun,et al. Variable window stereo matching based on phase con-gruency[J]. Computer Science,2015,42(Suppl1):13-15(in Chinese).
Method of Updating Compaction Quality Evaluation Model of Earth-Rock Dam Using Concept Drift Detection
Wang Jiajun,Zhong Denghua,Wu Binping,Liu Minghui,Zhang Zongliang
((State Key Laboratory of Civil Engineering Simulation and Safety,Tianjin University,Tianjin 300350,China)
Abstract:Updating the compaction quality assessment model of earth-rock dams is important to ensure long-term and high-precision evaluation of the compaction quality. However,there is a lack of research on the update of the compaction quality model.In this study,based on the idea of concept drift detection in stream data,as well as the characteristics of construction stream data such as slow velocity,existing noise data,and unbalanced data,a method of detecting concept drift and updating the compaction quality assessment model is proposed. First,a down sampling technology based on K-means is designed to address the unbalanced data. Second,a concept drift detection method based on enhanced probabilistic neural network(EPNN)and variable window technique(VWT)is proposed. The compaction quality assessment model is updated if a concept drift is detected. The engineering application shows that the down sampling method based on K-means ensures high consistency of classifier. The method based on EPNN and VWT can effectively detect the concept drift of compaction stream data.
Keywords:compaction quality assessment model;compaction data stream;concept drift detection;enhanced probabilistic neural network;variable window technology;model updating
DOI:10.11784/tdxbz201807009
中图分类号:TK448.21
文献标志码:A
文章编号:0493-2137(2019)05-0492-09
收稿日期:2018-07-04;
修回日期:2018-08-28.
作者简介:王佳俊(1991— ),男,博士研究生,jiajun_2014_bs@tju.edu.cn.
通信作者:吴斌平,wubinping@tju.edu.cn.
基金项目:国家自然科学基金雅砻江联合基金资助项目(U1765205);国家自然科学基金创新群体基金资助项目(51621092);国家自然科学基金资助项目(51339003).
Supported by the Joint Funds of the National Natural Science Foundation of China(No. U1765205),the Science Fund for Creative Research Groups of the National Natural Science Foundation of China(No. 51621092),the National Natural Science Foundation of China (No. 51339003).
(责任编辑:王晓燕)
