基于XML Schema XML文档验证算法
2019-02-20吴家菊纪斌刘振吉陈泉根
吴家菊 纪斌 刘振吉 陈泉根


关键词: XML Schema; XML; 文档验证算法; 语法错误; 错误信息处理; 错误位置追踪
中图分类号: TN911?34; TP311 文献标识码: A 文章编号: 1004?373X(2019)04?0071?05
An XML document validation algorithm based on XML Schema
WU Jiaju, JI Bin, LIU Zhenji, CHEN Quangen
(Institute of Computer Application, China Academy of Engineering Physics, Mianyang 621999, China)
Abstract: The validation mechanism of the XML document is researched, and an XML document validation algorithm based on XML Schema is proposed in this paper. In the algorithm, the data syntax rules, restraint requirement and type requirement are described by using XML Schema, which can not only verify the syntax correctness of the XML document on the basis of XML Schema, but also provide the processing mechanism of syntax error and support error position tracking. The algorithm can output error information in order according to the error occurring sequence if syntax errors exist in the XML document. The algorithm tracks syntax error position by means of mouse clicking after error information processing, so that the data editing personnel can modify the XML document efficiently and improve their own work efficiency. The algorithm was integrated into an XML editor and a series of experiments were carried out, so as to verify the correctness of the algorithm. The results show that the algorithm can achieve the design requirement.
Keywords: XML Schema; XML; document validation algorithm; syntax error; error information processing; error position tracking
0 引 言
XML(Extensible Markup Language)作为一种通用的数据描述和交换语言,在Internet上和企业内部得到了广泛应用,当前在武器装备综合保障领域XML被广泛用于描述综合保障数据[1]。对于已编辑的XML数据,在其应用到综合保障系统或其他应用领域之前,需要对其进行语法验证。XML Schema是W3C Recommendation推荐的标准,可用于设计、约束和验证XML文档。XML Schema文档中明确定义了XML文档中元素的应用规则,比如元素的名称、具有的属性、出现次序、出现次数、数据类型、父元素、子元素等[2?3]。因此基于XML Schema设计的XML文档可以使用XML Schema來验证文档的语法正确性。
自21世纪初XML Schema成为W3C Recommendation推荐标准以来,XML Schema由于其诸多优势正逐步替代DTD(Document Type Definition)成为XML设计、约束和验证的主流方式[4]。国内外有诸多基于XML Schema验证XML文档的研究。余双等学者在中科院软件所开发的OnceStAXParser的基础上设计实现了基于XML Schema的高效XML验证器[5?6]。王伟良等学者首先基于XML Schema构造了其抽象模型(Abstract XML Schema Model, AXSM),然后提出了一种基于XML Schema验证XML文档的方法[7]。许桂艳等学者基于SAX(Simple API for XML)解析实现了一种基于XML Schema验证XML文档的方法[8?9]。其他学者在研究过程中提出了其他的验证方法。这些方法都实现了基于XML Schema验证XML文档,并且能够有效地输出错误信息。随着深入的研究发现,这些方法或基于特定的平台或解析器,或作为独立的系统存在,在跨平台可移植性、轻量化设计、易集成性等方面存有缺陷,并且在实际应用中不支持错误位置追踪。
为解决当前基于XML Schema验证XML文档研究中存在的缺陷和实现依据错误信息追踪错误位置,本文提出一种跨平台可移植性性好、轻量化设计、易于与其他系统集成的基于XML Schema验证XML文档的算法。该方法基于DOM(Document Object Model)[10]解析,支持依据错误信息追踪错误位置。通过配合使用错误信息,方便XML数据编辑人员找寻文档中语法错误位置,提高了XML数据编辑人员的工作效率。当前该方法已集成到某XML编辑器中,在实践中验证了其可行性。
1 算法设计
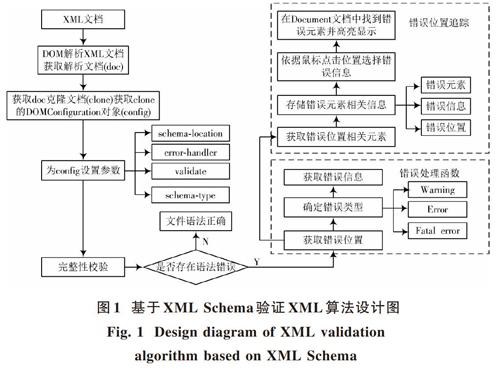
为了实现该算法跨平台可移植性、轻量化设计、易集成性,首先对该算法进行设计。算法设计如图1所示。算法后续描述使用Java编程语言,对于其他编程语言,则只需用该编程语言实现算法的设计。
为了完整地描述该算法的设计思想,算法描述从已编辑并保存的XML文档开始。若将该算法移植或集成到XML编辑器中时,可以省略前两步,直接依据保存已编辑XML数据的Document类型文档获取其克隆文档,然后执行后续的步骤。
2 算法实现
为保存验证过程中语法错误信息,在该算法中定义一个String类型的变量(为方便描述,命名为content。后续对变量命名原因相同)。在发生语法错误时由错误处理函数获取错误信息,并将错误信息更新到content中。最后将content中保存的XML文档所有语法错误信息输出。
2.1 定义错误类
为实现本文后面描述算法的错误位置追踪功能,在该算法中将验证过程中出现的每一个语法错误都实例化为一个错误对象,为此在该算法中定义一个错误类(命名为Error)。Error类的定义过程包括:
1) 在Error中定义两个变量:一个为Node类型的变量(命名为node);一个为int类型的变量(命名为p1)。
2) 在Error中定义构造函数,构造函数有两个传入参数:一个为Node类型,对应于XML文档的解析文档中存在语法错误的节点;另一个为int类型,对应于上述定义的content变量表示的字符串长度。
3) 在构造函数中定义变量赋值语句:将Node类型的传入参数赋值给Error类中定义的node变量;将int类型的传入参数赋值给Error类中定义的p1变量。
此外在该算法中定义一个ArrayList<Error>类型的变量errors。该变量中保存按照验证过程实例化的错误对象,错误对象加入链表的顺序按照验证过程中语法错误顺序。
2.2 DOM解析XML文档
DOM可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构,DOM实际上是以面向对象方式描述的文档模型[11]。使用DOM定义的接口来获得对文档中所有元素进行访问的入口,创建文档,浏览文档结构,添加、修改或删除文档元素和内容[12]。DOM解析XML文档后所生成的文档树会保存在内存中,DOM的这一特性是本算法实现追踪错误发生位置的基础。
为保证验证过程不对源XML文档造成影响,获取了XML解析文档的克隆文档,该验证算法的所有后续操作均在克隆文档中进行。
在本文算法中,DOM解析XML文档以获取解析文档,继而获取解析文档的克隆文档的流程图如图2所示。
首先,用Java语言实现DOM编程接口以获取解析器实例;其次,获取XML文档的URL路径,并将该URL路径作为DOM解析器实例的传入参数;第三,DOM解析器依据传入参数解析XML文档,获取解析文档(命名为doc);第四,解析文档doc调用cloneNode()方法获取doc的克隆文档(命名为clone)。
2.3 对clone执行相关操作
获取clone的DOMConfiguration对象,并为该对象设置相关参数的步骤如下:
1) clone通过调用getDomConfig()方法获取其DOMConfiguration对象(命名为config);
2) config对象调用setParameter(String name, Object value)方法,name值為“schema?type”,value值为“http://www.w3.org/2001/XMLSchema”;
3) config对象调用setParameter(String name, Object value)方法,name值为“schema?location”,value值为XML Schema文档的URL路径;
4) config对象调用setParameter(String name, Object value)方法,name值为“validate”,value值为true;
5) config对象调用setParameter(String name, Object value)方法,name值为“error?handler”,value值为错误处理类的实例化对象。
2.4 定义错误处理类
为处理验证过程中出现的语法错误,获取错误信息以及保存错误信息,在该算法中定义了一个错误处理类(命名为handleError),并在该类中定义错误处理函数。handleError实现DOMErrorHandler接口,错误处理函数的定义过程如下:
1) 错误处理函数有一个DOMError类型的传入参数(err)。
2) 定义一个DOMLocator类型的变量(loc),并将err调用getLocation()方法获取的值赋值给loc;
3) 将验证过程中的语法错误实例化为Error对象,并保存在errors变量中,以备进行错误信息追踪;
4) 判断语法错误类型;
5) 更新错误信息,以备将错误信息输出。
其中语法错误实例化Error对象的过程包括:
依据clone文档的语法错误节点在文档doc中找到对应节点node;调用Error类的构造函数并将node和content.length()作为传入参数,获取Error对象。XML文档第一次出现语法錯误时,在content未更新,因此content.length()=0。
依据clone文档的语法错误节点在doc中找到对应节点node的流程图如图3所示。其本质是从当前发生语法错误节点开始向根节点追溯,在追溯过程中依次保存在错误节点之前的兄弟节点个数、在错误节点的父节点之前的兄弟节点个数、在错误节点的父节点的父节点之前的兄弟节点个数…,依次类推,直到到达XML文档的根节点,最后得到一个ArrayList<Integer>类型的变量。然后根据变量中保存的int类型的数据,在doc中从根节点开始向下追溯,直至在doc中找到与clone中错误节点对应的节点。
其中判断语法错误类型的过程包括:
1) err通过调用getSerivity()方法获取当前语法错误类型。
2) 判断该错误类型属于DOMError. SERIT? Y_
WARNING,DOMError.SERI? TY_ERROR,DOMError.SERITY_FATAL_ERROR中的哪一类。
3) 将描述错误类型的相关信息更新到保存错误信息的content变量中。
判断错误类型的流程图如图4所示。该步骤的主要目的是判断错误类型并将描述错误类型的信息更新到content中,以在输出的错误信息中标明该错误属于何种类型。延续上一步在content中更新的表示错误类型的内容,err通过调用getMessage()方法获取详细错误信息,并将错误信息更新到content中,然后在content中已有内容后添加一个换行符,以便将描述不同错误信息分行输出。
2.5 定义错误追踪函数
将错误信息输出的方式有多种,既可以以文本形式输出,也可以定义一个信息输出面板用于输出错误信息。为了达到该算法能够依据错误信息追踪错误位置的目的,在该算法中采用信息输出面板的方式输出错误信息。具体来说是应用GUI编程,首先,定义一个JFrame;然后,在JFrame中嵌入一个JEditorPane;第三,判断content的内容是否为空,若为空,则将content变量的内容设为“XML文档语法正确”;最后,JEditorPane调用setText()方法,将保存错误信息的content作为JEditorPane的内容,这样就可以将保存错误信息的content变量的内容输出。
此外为直观显示错误信息追踪效果,XML文档的解析文档doc同样要以信息输出面板的方式输出。同错误信息输出一样,采用GUI编程,将解析文档doc中的每个元素的名称、属性、内容、子元素、父元素等信息按照XML文档中元素的顺序输出。
错误位置追踪函数本质是一个JEditorPane的鼠标点击事件函数,当鼠标点击在JEditorPane上输出的错误信息时,实现依据错误信息追踪语法错误位置。
鼠标点击事件函数定义过程包括:
1) 函数有一个MouseEvent类型的传入参数(命名为e);
2) 在鼠标点击事件函数中定义三个int类型的变量和一个Node类型的变量;
3) 依据相关变量确定鼠标点击的错误信息并将errors变量中对应于错误信息的error对象给相关变量赋值;
4) 在JEditorPane上依据相关变量选中鼠标位于点击位置的错误信息;
5) 依据相关变量值在doc中找到存在语法错误的节点。
其中:定义的三个int类型变量分别命名为position,p1,p2; Node类型的变量命名为node;position对应于鼠标在JEditorPane的点击位置,取值由JEditorPane调用viewToModel(e.getPoint())方法获取;p1和p2的初始值为0;node的初始值为null。
其中依据相关变量确定鼠标点击的错误信息并将errors变量中对应于错误信息的error对象给相关变量赋值的伪代码如下:
for(Error err : errors){
if(err.p1 > position){
p2 = err.p1;
break;
}
node = err.node;
p1 = err.p1;
}
在JEditorPane上依据相关变量选中该条错误信息的步骤为:
1) 判断p2==0是否为真,若为真,则将content变量表示的字符串的长度值赋值给p2(当鼠标点击JEditorPane显示的最后一条错误信息时,p2==0)。
2) JEditorPane调用setCartPosition(p1)和moveCartPosition(p2)方法选中JEditorPane上位于鼠标点击位置处的错误信息。
上述获取的node为鼠标点击选中的语法错误信息对应的节点,在doc中找到该节点并以高亮的方式显示该节点。
3 实验验证
为验证该算法的正确性、有效性以及是否能够依据错误信息追踪错误位置,将该算法集成到某XML编辑器中。该XML编辑器已编辑的XML数据以Document类型的文档保存。在集成过程中,首先获取该Document类型文档的克隆文档,然后直接执行后续的验证操作。在验证过程中验证结果如图5所示。


从图5可以看出:首先,对于验证过程中的语法错误该算法能够按照错误发生顺序将错误信息输出,并且每条错误信息既包含错误类型又包含导致错误的详细信息;其次,该算法中设计的错误位置追踪功能能够有效地依据鼠标点击位置首先选择位于鼠标点击位置的错误信息,进而在XML文档的DOM解析文档的信息输出面板中找到该错误信息对应的错误节点并高亮显示。为验证该算法验证结果的正确性,选取若干已知存在语法错误的XML文档,将这些XML文档分别在集成了该算法的XML编辑器和诸如XMLSpy等商用成熟软件中进行验证,然后对比验证结果。分析验证结果发现,该算法能够完整、有效地验证XML文档,达到设计要求。
4 结 语
为了实现基于XML Schema验证XML文档算法的可移植性性、轻量化设计、易集成以及支持错误追踪,本文提出一种基于XML Schema验证XML文档的算法。该算法基于DOM解析XML文档,为保证验证过程不影响源XML文档,验证操作在XML文档的DOM解析文档的克隆文档上进行。为验证该算法能否准确、有效地验证XML文档以及能否实现错误位置追踪,将该算法集成到某XML编辑器中,经过一系列的试验验证,该算法达到了设计要求。下一步将在该算法的基础上实现语法错误信息汉化输出。
注:本文通讯作者为纪斌。
参考文献
[1] 徐宗昌.裝备IETM技术标准实施指南[M].北京:国防工业出版社,2012.
XU Zongchang. Implementary guide of equipment IETM technical standard [M]. Beijing: National Defense Industry Press, 2012.
[2] W3C. W3C XML Schema definition language (XSD) 1.1 Part 1: Structures [EB/OL]. [2012?04?05]. https://www.w3.org/TR/xmlschema11?1/.
[3] W3C. W3C XML Schema definition language (XSD) 1.1 Part 2: Datatypes [EB/OL]. [2012?04?05]. https://www.w3.org/TR/xmlschema11?2/.
[4] 曹风华.一种XML解析器技术的研究与实现[J].微型机与应用,2011,30(21):6?10.
CAO Fenghua. Research and implementation of an XML parser technology [J]. Microcomputer & its applications, 2011, 30(21): 6?10.
[5] 余双,曹冬磊,戴蓓洁,等.高效XML验证技术的实现[J].计算机工程与设计,2008,29(4):937?941.
YU Shuang, CAO Donglei, DAI Beijie, et al. Research on high performance implementation of XML validation [J]. Computer engineering and design, 2008, 29(4): 937?941.
[6] REN X, CAO D, JIN B. An efficient STAX based XML parser [C]// Proceedings of the 11th Joint International Computer Conference. [S.l.: s.n.], 2005: 203?207.
[7] 王伟良,施佺,曹渠江.基于XML Schema抽象模型的XML模式验证方法[J].计算机应用与软件,2007,24(3):41?43.
WANG Weiliang, SHI Quan, CAO Qujiang. A method for XML document schema validation with abstract XML schema model [J]. Computer applications and software, 2007, 24(3): 41?43.
[8] 许桂艳,张建,李淼,等.基于XML Schema的知识描述与模式验证[J].计算机系统应用,2008,17(9):33?37.
XU Guiyan, ZHANG Jian, LI Miao, et al. Knowledge representation and pattern validation based on XML Schema [J]. Computer systems & applications, 2008, 17(9): 33?37.
[9] PAN Y, ZHANG Y, CHIU K. Hybrid parallelism for XML SAX parsing [C]// Proceedings of IEEE International Conference on Web Service. Beijing: IEEE, 2008: 505?512.
[10] MA J, ZHANG S, HU T, et al. Parallel speculative Dom?based XML parser [C]// Proceedings of 14th International Conference on High Performance Computing and Communication & 9th International Conference on Embedded Software and Systems. Liverpool: IEEE, 2012: 33?40.
[11] Jeremy Keith, Jeffrey Sambells.JavaScript DOM編程艺术[M].北京:人民邮电出版社,2011.
KEITH J, SAMBELLS J. DOM scripting: Web design with JavaScript and the document object model [M]. Beijing: Posts & Telecom Press, 2011.
[12] W3C. XML DOM [EB/OL]. [2018?02?26]. http://www.w3school.com.cn/xmldom/dom_intro.asp.
