基于平衡核函数聚类的飞行航迹数据分析方法
2019-02-16李冬梅
唐 静,王 婧,李冬梅
(92830部队,海口571122)
关于航迹的研究,国内外学者已经开始进行并取得了一定的成果,例如基于密度的航迹聚类方法[1]、基于粒子群的航迹聚类[2]、面向目标航迹融合的坐标变换运用技术[3]、对航迹进行加权融合的权值动态分配算法[4]、基于C均值的航迹聚类[5]。但是对大量航迹进行识别和分类的应用研究仍然还处于开始阶段。比如,Noyes[6]提出的模糊逻辑的航迹分类算法,可以区分气象杂波和航迹;文献[7]实现了多航路目标和非航路目标的分类;文献[8]利用基于密集的聚类思想,通过多维目标航迹的聚类,实现对目标行为规律的挖掘分析;文献[9]基于一致性预测原理,通过设计一致性多类分类器,实现对目标行为模式的在线学习与分类识别;文献[10]对不确定性航迹的自适应预测进行了研究;文献[11]对航迹点在坐标转换方面进行了讨论;文献[12]分析了误差对航迹点的干扰;文献[13]基于综合隶属度提出航迹起始关联的穷举法;文献[14]对航迹初值进行修正来提高多尺度聚类滤波的准确性;文献[15]提出来基于假设检验的航迹-航路相关方法。但是现有的研究方法大多按照全局最优来进行参数调节,对航迹数据量大、交连多、非线性特征等特点,要做到尽可能精确的聚类分类十分困难。
支持向量机理论[16]自20 世纪90 年代创立并开始发展,由于具有结构简单、强大的泛化能力和容易实现全局最优结果等优点,被快速应用到模式识别和数据挖掘的领域。支持向量机的核函数是构建适合系统的关键,通过核函数的非线性映射方法,可以将输入的数据映射到高维的特征空间,变化成线性问题进行讨论。这种处理思路使得支持向量机方法在特征提取、主成分分析和分类识别等领域得到广泛应用。因此,研究核函数的构造和设计变得至关重要,其要求是对待分析的数据变化敏感,表现形式具有一定的意义。
本文立足提高飞行航迹数据聚类分析的准确性,基本思路为:在航迹特征数据的预处理阶段,加入一种平衡核函数用于K-均值聚类的处理过程,可以解决高维特征数据带来的奇异性,还能提高交叠样本的聚类性能;设计了一种模糊支持向量机实现航迹的分类。通过实际航迹数据,测试了本文设计的基于平衡核函数航迹聚类和模糊支持向量机分类器有效性。
1 飞行航迹数据的选择和处理
本文分析使用ADS-B 系统的航迹数据进行研究。ADS-B 系统的航迹数据是按照一定时序发送的位置数据的序列,这是一种多维度的数据集[17]。飞行器的航迹自民用空管软件上获取,其软件界面如图1所示,软件中可得到航班飞行航迹点的时间、航班号、经纬度、高度、速度和航向。
航迹的原始数据为:
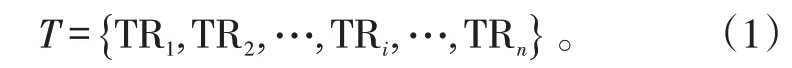
式(1)中:T为航迹集,i∈[1,2,…,n] 是航迹点编号,n为航迹总数;TRi为第i个航迹点序列。

式(2)中:Pij为第i条航迹中第j个多维特征点;j∈[1,2,…,m] ,m为航迹点的总数。
当采用时间、经度、纬度、高度、速度、航向这6 个特征时,得到:
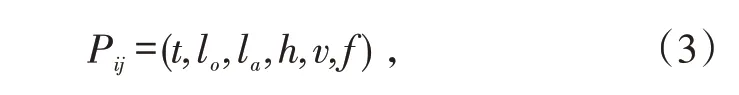
即第i条航迹中第j个多维特征点的特征。然后,对数据进行坐标转换,由于航迹数据是经纬度数据,为便于分析和计算,将数据从大地坐标系转换到直角坐标系,采用墨卡托投影转换,得到航迹数据样本集。

图1 民用空管软件的航迹图Fig.1 Track chart of civil air traffic control software
2 平衡核函数K-均值聚类方法
假设对2 个数据样本进行非线性变换ϕ(),得到映射的内积为核函数k(x,z),即k(x,z)=ϕ(x),ϕ(z) 。其中,特征变换ϕ:x→ϕ(x)为核函数导出的,X和ϕ(x)为输入空间及特征空间。
核算法的主要特点有:
1)可以将非线性问题线性化;
2)核函数可以方便地与不同的算法结合使用;
3)核函数的使用避免了计算特征空间的内积,与维数无关,不会造成“维数灾难”;
4)核函数的引入,适用于高维度问题的分析。
传统的K-均值方法是基于最小距离原则来进行聚类的[18],是一种非监督学习方法。容易导致聚类内外的样本数量相差过大,形成聚类结果失衡,从而影响聚类产生的结果。能不能有一种兼顾内外样本数量的核函数构造方法呢?本文提出了一种新的聚类方法——平衡核函数K-均值法,即合理的构造核函数,在数据被映射到高维的非线性空间之后,进行K-均值聚类同时兼顾聚类之间的样本数的方法。
本文对航迹特征数据进行聚类的步骤如下:
1)获取航迹数据集,对其中的经纬度数据进行墨卡托坐标变换,形成数据样本集;
2)对数据样本集的数据进行高斯核变换,映射到特征空间;
3)按照需要聚合的类别数,设定初始中心,分别求得与中心的差值,在特征空间中完成平衡核函数K-均值聚类;
4)满足条件的xi:当D达到最小的xi所属的聚类就是xi应该属于的聚类;
5)完成样本数据集的聚类。
假设经过归一化变换后的飞行器的航迹数据为{(x1,z1),(x2,z2),…,(xN,zN)},其中zi(i=1,2,…,N)是类别标志,zi∈{1,2,…,c} ,xi∈ℝ(i=1,2,…,N)是第i个样本,c是类别总数。
特征空间F是Φ( )xi,则平衡核函数K-均值聚类在特征空间F的目标函数定义为:
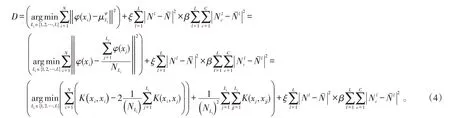
可以看到,在式(4)中,第1 部分类似一般用到的核K-均值方法,当第1 部分最小化时,聚类是收敛的。聚类个数用L表示,Li是第i个样本所属聚类的类标,是F特征空间中属于第Li个聚类类型中的样本平均值,NLi为第Li个聚类中的样本总数,K(⋅,⋅)是核函数。
式(4)中,第2部分设计可反映出类与类之间及聚类之内样本数是否平衡,ξ和β是加权系数,Nl为第l个聚类之内的样本总数,Nˉ为平均值,用来表示属于第c类的第l个聚类中的样本数,第l个聚类之内的各类样本数的平均值用表示。即当D达到最小的xi所属的聚类就是xi应该属于的聚类。第2 部分的设计是平衡核函数K-均值聚类的核心。与传统的K-均值聚类相比,在聚类时,式(4)中第1 部分也会引起第2 部分的变化,这样就在全局动态聚类的过程中使D最小化。
这样聚类处理之后得到的数据在特征空间中分布会满足距离相近的样本聚集在同一类中,距离远的样本不会出现在同一类中,有效避免了样本交叠严重的情况。
3 模糊支持向量机的多分类器设计
在数据完成特征提取和归一化的标准处理后,本文设计了一种基于模糊支持向量机的多分类器进行分类,用模糊隶属度来去除数据中偏差较大的点对分类器的影响。
基于模糊支持向量机的飞行航迹分类基本构想如图2所示。
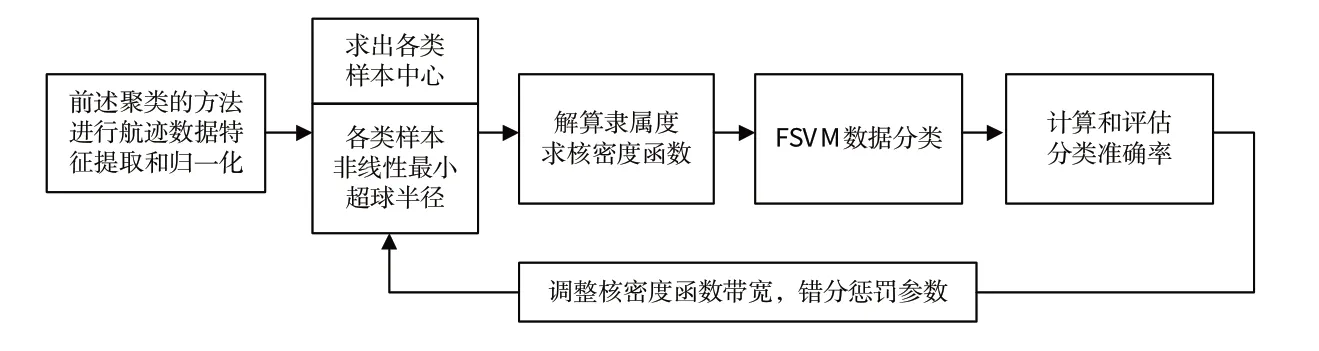
图2 基于模糊支持向量机的飞行航迹分类步骤Fig.2 Flight track classification steps based on fuzzy SVM
假设训练样本集为:
(x1,y1,μ(x1)),(x2,y2,μ(x2)),…,(xn,yn,μ(xn)) ,xi∈ℝN,yi∈{- 1,1},0 <μ(xi)≤1。设原始空间ℝN到高维特征空间Z的映射关系为z=ϕ(x)。该样本隶属于某类的可靠程度用模糊隶属度μ(xi)来表示,支持向量机中设置的目标函数中的分类误差项用ξi来表示,加权误差项是μ(xi)ξi。如下目标函数的最优解即是需要找到的最优超分类平面。

式(5)中:线性分类项,函数yi的权系数用w表示,设置惩罚因子C为常数,需要事先指定。
由式(5)可以看出,xi可看作不重要的样本忽略,因为μ(xi)会减小ξi的影响。
这时得到的是最优分类面,其判别函数表示为:

式中:K(xi,x)为核函数,本文采用常用的高斯核。

本文设计的模糊支持向量机中使用的隶属度函数应用核密度函数的估计方法来构造。

从该函数的形式可以看出,μ(xi)是无穷、连续可微的,c为类中心,核密度倒数用k代表。当数据距离数据中心距离较远时,隶属度就会越小,越减小误分类的可能。这时本分类方法的一个优点。
其分类的计算框架如图3所示。

图3 分类识别的计算框架Fig.3 Algorithmic framework of classification and recognition
4 实际航迹数据的应用分析
为研究本文所提出方法的有效性和实用性,做以下2个方面的验证:
1)验证是否可以用前面所述的平衡核函数方法来聚类航迹数据集合以形成正确的航迹类别;
2)在已经获得的类别数据基础上,用模糊支持向量机的方法来对不同飞行航迹进行分类,验证模糊支持向量机算法框架应用的有效性。
以我国海南岛北部的海口美兰机场为中心的附近区域的飞行器航迹数据为研究对象,只分析以美兰机场为到达机场的国内和国际航班的航路区域周围的民用航空器的航迹数据,由于沿各种航路飞来的航班在进近区航迹大致相似,为简化问题,这里不考虑机场进近区内(这里按美兰机场为中心50 km 的圆形范围)的航迹变化,只考虑进近区域之外的飞行航迹作为参与分析的数据。
此外,飞行器在实际的飞行过程中,受到天气、飞行器本身、气流等因素的影响,实际飞行航迹要复杂混乱得多。如果通过本文提出的聚类方法可以应用于飞行航迹类别的识别,则为下一步未知类别的航迹识别提供了思路。
在进行平衡核函数聚类算法的验证分析时,为说明方法的有效性,除本文使用的方法之外,还和传统的K-均值聚类方法进行对比。本文方法中的参数设置 分 别 为:L=2 ,ε=0.001 ,T=100 ,ξ=0.35 ,β=0.2,核函数选为高斯核函数。以美兰机场为到达机场的2条航路,每条航路选择60条10 min 内每隔5 s给出的航迹点形成数据集,给出本文方法和传统的K-均值聚类方法在特征空间中的聚类分布结果,图4 是传统的K-均值聚类方法,图5是本文方法。图中横纵坐标的0 点为特征空间中的中心原点,横坐标为与某一类数据中心与原点在特征空间的距离度量,纵坐标的数字为与该类数据中心的距离度量。
由图4、5 可以得出看出,本文提出的方法是一种可行的方法。从聚类性能上看,平衡核函数聚类的算法聚类结果更加紧密,更加集中,聚类后的样本数据分布只占到原有传统K 均值聚类的50%。本文提出的平衡核函数聚类方法明显优于传统的K-均值聚类方法。可以判别出不同类型航路的飞行航迹。
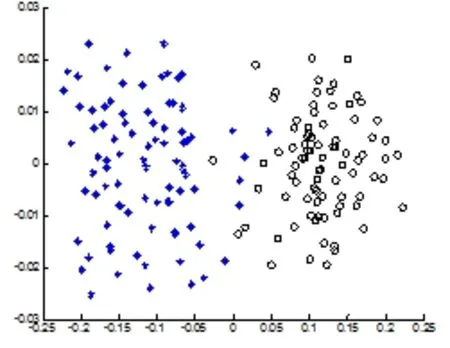
图4 传统K均值聚类Fig.4 Traditional K-MEANS clustering

图5 平衡核函数聚类算法Fig.5 Balanced kernel function clustering algorithm
在聚类获得航路数据集基础上,再使用不同类别的飞行航迹数据,采用本文设计的模糊支持向量机进行识别分类,观察分类的准确率。同样,为了验证效果,调整使用不同的核密度函数带宽和错分惩罚参数,与标准支持向量机分类器的分类结果进行比较。
本文选取6条航路,每条航路作为一个类别,在每条航路经过的航迹中选择280 条航迹,取10 min 内每隔5 s 得出的航迹点形成数据集进行聚类,然后选择这6 条航路上每一类航路的其他70 条航迹进行识别验证,如果能得到正确的分类结果记为“1”,错误记为“0”,用识别的正确率来表示识别率,根据正确率的定义:

其中:TP为实际为正例且被分类器划分为正例的实例数;TN为实际为负例且被分类器划分为负例的实例数;P为正例;N为负例。得到识别率:

重复进行10次以上的步骤,得到的平均识别率如表1所示。
结果分析可以发现,本方法的识别效果要优于标准SVM进行分类的结果,而且,通过改变不同的核密度函数带宽和惩罚参数,对航迹数据识别的结果也会发生变化。

表1 航路数据在不同参数下的平均识别率Tab.1 Average recognition rate of track data under different parameters
5 结论
本文立足提高飞行航迹数据聚类分析的准确性,在航迹特征数据的预处理阶段,使用一种平衡核函数用于K-均值聚类,能有效提高交叠样本的聚类性能;设计了一种模糊支持向量机实现航迹数据的分类。通过实际航迹数据测试了基于平衡核函数航迹聚类和模糊支持向量机分类器的有效性。下一步可以继续研究不同的核密度函数带宽和惩罚参数对识别结果的影响规律,可以提高飞行航迹数据的识别效果。
