基于特征重用和语义聚合的SAR图像舰船目标检测
2019-02-16李建伟张玉婷
江 源,李建伟,张玉婷
(1.海军研究院特种勤务研究所,北京102400;2.海军参谋部机要局,北京100841)
随着卷积神经网络在计算机视觉任务中取得极大的成功[1-5],SAR图像中目标检测也急须引入此类方法。文献[6]双阶段检测算法Faster R-CNN 用于SAR图像舰船目标检测,并进行了适应性的改进。相比于双阶段检测算法,单阶段检测算法速度更快,但精度会稍差。
2016 年12 月,LIU WEI 等 提 出 了SSD(Single Shot Detector)[7]检测算法,将回归思想和锚框机制结合,通过在不同卷积层的特征图上预测目标区域,生成离散化的多尺度、多比例的锚框坐标。同时,利用小卷积核预测一系列候选框的坐标和每个类别的置信度,既保持了快速性,又保证了边框定位效果。
SSD对输入图像数据的处理流程如图1所示。图中包括骨干网络(采用了16 层的VGG-Net[8]模型,即VGG-16)、前端网络(预测层)和后处理(通过NMS实现)3部分。骨干网络用于特征提取,一般需要加载分类任务中训练好的参数。之后,根据具体任务进行微调;前端网络用于目标预测,一般需要初始化之后从头进行训练;后处理用于去除多余的边框。

图1 SSD处理流程Fig.1 Processing flows of the SSD

图2 SSD前端网络原理示意图Fig.2 Sketch map of the SSD front end network
多尺度特征图包括conv3(表示VGG-16的第4个卷积层得到的特征图,其尺寸为38×38,通道数为512)、conv7(表示SSD 算法中第7 个卷积层得到的特征图,其尺寸为19×19,通道数为1 024)、conv8-2(表示SSD 算法中第8 个卷积层得到的特征图,其尺寸为10×10,通道数为512)、conv9-2(表示SSD 算法中第9个卷积层得到的特征图,其尺寸为5×5,通道数为256)、conv10-2(表示SSD 算法中第10 个卷积层得到的特征图,其尺寸为3×3,通道数为256)和conv11-2(表示SSD 算法中第11 个卷积层得到的特征图,其尺寸为1×1,通道数为256)6 种尺度。在每个尺度的特征图上,产生类似于Faster R-CNN的锚框。原论文中conv3、conv10-2 和conv11-2 有 长 宽 比1、2 和1/2,conv7、conv8-2 和conv9-2 有长宽比1、2、1/2、3 和1/3。SSD 给不同的边框设置不同的长宽比,对于为1 的长宽比,会增加一个尺寸。因此,SSD一共有8 732 个锚框(38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732)。
图2 中的预测部分用于预测物体类别的置信度,并通过在特征图上使用小尺寸的卷积核(1×1 和3×3的卷积核)来直接预测物体的边框坐标。由于预测是在6 种不同的尺度进行,且每种尺度具有不同长宽比的锚框,所以能够提高目标检测的精度,而且整个算法可以进行端到端的训练,在速度上也有较大的优势。
在训练之前,需要用匹配策略将锚框分成正负样本。对于训练数据图像产生的每一个真实边框,从各种位置、长宽比和尺度来选择锚框;然后,把与锚框具有最大交并比的和与任意锚框的交并比大于0.5的看成正例进行训练,其余当作负例,之后进行训练。
SAR 图像首先输入到VGG-16 提取特征,形成特征图;接着,通过多个卷积生成6种尺度的额外的特征图,并在这6 种尺度的特征图上生成锚框;之后,预测部分通过在对锚框上使用小尺寸的卷积核(1×1和3×3的卷积核)来直接预测物体的边框坐标和类别的置信度,得到目标位置和类别的预测值;目标位置和类别的预测值送入到损失函数,损失函数根据目标位置和类别的预测值与真实值的误差,分别计算相应的损失,并用损失最小调整神经元参数,使检测达到最优。
为了实现对目标快速准确地检测,本文对经典的单阶段检测算法SSD进行了改进,在前端网络中对卷积特征进行重用,将高低层语义(类别)信息进行聚合,提高了对特征的利用效率(所提方法对SSD 检测算法提取的特征进行了进一步的处理,包括特征和语义聚合,提高了特征利用率)。在通用目标检测数据集PASCAL VOC[9]和SSDD上证明了改进的效果。此外,还根据舰船目标在数据集SSDD 上尺寸和长宽比的分布情况对锚框进行了针对性的设计。所提出的方法能提高对舰船目标的检测效果,且计算量不会增加很多。
本文针对SSD 的前端网络对特征利用不充分的问题,对前端网络进行了改进,包括特征重用和语义聚合算法。特征重用算法对前端网络的特征图按照通道分成2部分,分别进行卷积处理和重新利用(通过与下一层聚合实现),可在进行学习的同时,减小了参数量。语义聚合算法将高层语义信息融入到底层,提高对不同尺寸目标的检测能力。设计了2种新的锚框来适应SSDD 数据集中、舰船目标尺寸小和长宽比大的特点。
1 总体结构
基于特征重用与语义(类别信息)聚合的特征融合算法是对图1 中的前端网络进行的改进,算法结构图如图3所示,包括特征重用(从特征重用1到特征重用4的4个阶段)和语义聚合(语义聚合1到语义聚合5的5个阶段)2部分。特征重用通过对特征图的高效利用,提高了对物体检测的准确率;语义聚合算法通过融合位置信息丰富的底层特征和语义信息丰富的高层特征,提高了区分和定位舰船目标的能力。
图3 的特征重用算法对conv7、conv8-2、conv9-2和conv10-2的特征图都只进行一半的参数学习,另一半改变尺寸后在下一层直接进行聚合。相比于图2的过程,在进行学习的同时,减小了参数量。例如,在特征重用1 中,conv7 的按通道划分的一半特征(512×19×19)通过1×1 和3×3 卷积变成512×10×10,另一半通过池化变成512×10×10,二者通过聚合变成1 024×10×10 ,再通过1×1 卷积将特征图变成512×10×10,如图4所示。
图3的语义聚合算法把语义信息较强且尺寸较小的特征图进行了采样,与上一层的特征进行融合(逐元素相加),如图中语义聚合1 到语义聚合5 的过程。语义聚合通过去卷积(deconvolution)和1×1的卷积实现。例如,在语义聚合1 中,卷积核尺寸为3×3,零填充个数为0,步长为2,通道数为256 的去卷积层,将conv11-2 的特征图从256×1×1 变换到256×3×3,通过逐元素相加操作与conv10-2 相拼接,得到新的特征图,在新的特征图上进行预测。

图3 特征重用和语义聚合算法(在卷积之后会有BN和ReLU)Fig.3 Feature reuse and semantic algorithm(BN and ReLU at after convolution)
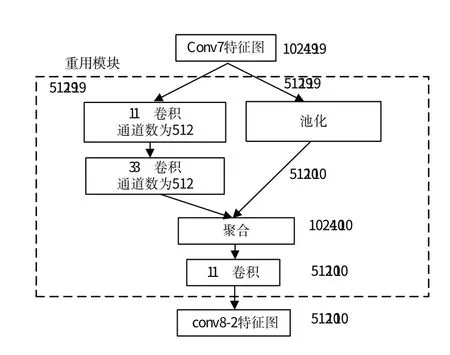
图4 SSD前端网络的特征重用1Fig.4 Feature reuse 1 in the frontend network of SSD
2 特征重用算法
特征重用算法对图1 中的前端网络进行了改进,将特征图按照通道分成2 部分:一部分被卷积处理进行参数学习;另一部分直接输入到下一阶段通过拼接的方式重新利用,这可在进行参数学习的同时,减小参数量和计算量。
特征重用1。图4 描述的是特征重用1 的计算过程。按照通道个数,将特征图conv7(1024×19×19)平均分成2 部分,一部分像原始的SSD 那样被1×1 卷积和3×3卷积处理变成512×10×10。其中,1×1的卷积将特征图的通道数变少,3×3卷积将特征图的尺寸减半;另一部分输入到下一阶段。通过池化,将特征图的尺寸减半,对特征重新利用,特征图变成512×10×10,这可以减小计算负担。两侧得到的特征图具有相同的尺寸和通道个数(都变成了512×10×10),输入到聚合层进行特征图的拼接(得到1024×10×10),1×1卷积用于在改变通道个数的同时,增加非线性操作(得到512×10×10)。特征重用算法在进行学习的同时,减小了参数量。
特征重用2。conv8-2(512×10×10)按通道划分的一半特征(256×10×10)通过1×1和3×3卷积变成256×5×5;另一半通过池化变成256×5×5,通过聚合变成512×5×5,通过1×1 卷积将特征图变成256×5×5,得到新的conv9-2。
特征重用3。conv9-2(256×5×5)按通道划分的一半特征(128×5×5)通过1×1和3×3卷积变成128×3×3,另一半通过池化变成128×3×3,通过聚合变成256×3×3,得到新的特征图conv10-2为256×3×3。
特征重用4。conv10-2(256×3×3)按通道划分的一半特征(128×3×3)通过1×1和3×3卷积变成128×1×1;另一半通过池化变成128×1×1,通过聚合变成256×1×11,得到新的特征图conv11-2为256×1×1。
3 语义聚合算法
语义聚合算法对图1 中的前端网络进行了改进。由于底层特征具有准确的位置信息,高层特征具有丰富的语义信息,因而为了同时实现对目标的准确识别和位置定位,这里将不同层级的特征进行语义聚合。
图5是SSD的前端网络采用语义聚合的前端网络示意图(图中VGG-16用于特征提取)。图5 a)是SSD的网络结果,它构成了一种层级的特征结构,并在各层进行预测,利用不同层级的特征进行预测可以提高对不同尺度目标的适应性。图5 b)是基于语义聚合的SSD 的结构,它在SSD 层级结构的基础上,对不同层级的特征进行了语义聚合,对每层引入从上到下的语义信息(类别信息),使每层能够同时具有丰富的类别和位置信息,便于对目标的分类和定位,底层的特征图融入了高层语义信息的同时,也会提高对小尺寸目标的适应能力。相比于图像金字塔结构,这种语义聚合算法不需要大量计算量和存储量去保持中间特征,只需简单的聚合操作即可实现。

a)SSD的前端网络a)Front end network for SSD
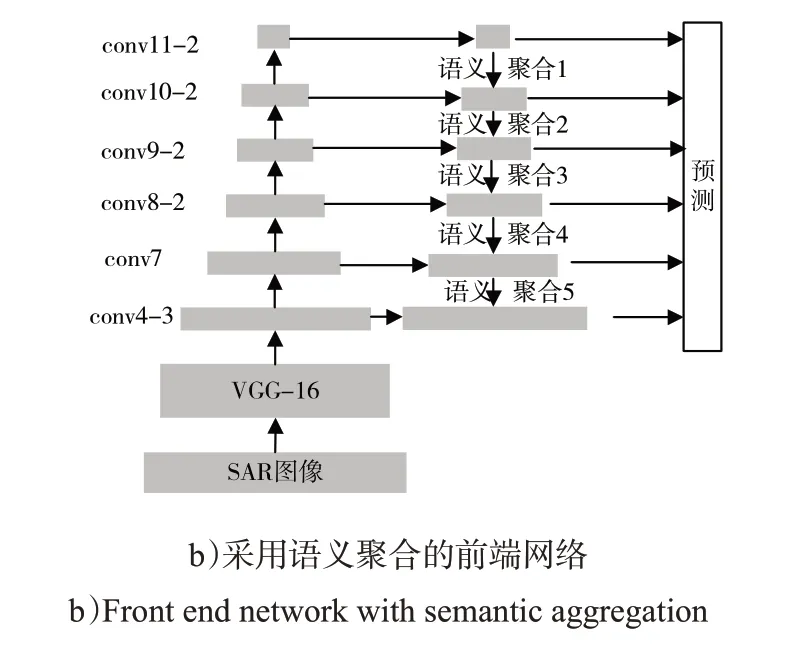
图5 SSD和基于语义聚合的SSDFig.5 SSD and SSD based on semantic aggregation
语义聚合算法包括5个阶段,如图3所示。
语义聚合1。卷积核尺寸为3×3,零填充个数为0,步长为2,通道数为256的去卷积层将conv11-2的特征图从256×1×1 变换到256×3×3,通过逐元素相加操作与conv10-2相聚合。
语义聚合2。卷积核尺寸为3×3,零填充个数为1,步长为2,通道数为256 的去卷积层将特征图从256×3×3 变换到256×5×5,通过逐元素相加操作与conv9-2相聚合。
语义聚合3。卷积核尺寸为1×1,零填充个数为1,步长为2,通道数为512的卷积层将特征图通道数从256增加到512。卷积核尺寸为3×3,零填充个数为1,步长为2通道数为256的去卷积层将特征图从512×5×5 变换到512×10×10,通过逐元素相加操作与conv7-2相聚合。
语义聚合4。卷积核尺寸为1×1,零填充个数为1,步长为2,通道数为1024 的卷积层将特征图通道数从512增加到1 024。卷积核尺寸为3×3,零填充个数为1,步长为2,通道数为1 024 的去卷积层将特征图从512×10×10变换到1 024×19×19,通过逐元素相加操作与conv7相聚合。
语义聚合5。卷积核尺寸为1×1,零填充个数为1,步长为2,通道数为512的卷积层将特征图通道数从1 024 降低到512。卷积核尺寸为4×4,零填充个数为1,步长为2,通道数为512 的去卷积层将特征图从1 024×19×19 变换到512×38×38。通过逐元素相加操作与conv3相聚合。
4 改进的锚框设计
SSD的前端网络会在6种尺度的特征图上分别产生锚框,产生的锚框作为默认的候选区域,用于目标位置和类别的预测。锚框具有多种尺寸和长宽比,但SSDD 中舰船目标的尺寸和长宽比与PASCAL VOC中的目标不同,所以需要统计SSDD 中舰船目标包围框的尺寸和长宽比,以针对性地改进检测算法的锚框。
原SSD 论文中最小尺寸为0.2,最大尺寸为0.9,0.2 和0.9 都是相对于原图像尺寸的比例,第k个尺寸按照下式进行平均取值:
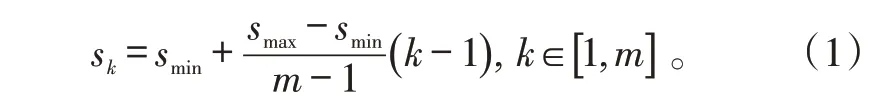
式(1)中:smin表示最小的尺寸;smax表示最大的尺寸;m表示层数,这里是6。
由SSDD数据集中舰船目标包围框长度和宽度统计结果,将最大尺度从0.9 改成0.3,最小尺度从0.2 改成0.06。长宽比最大最小值从2和0.5改成了4和0.4。
原SSD 论文中,conv3、conv10-2 和conv11-2 有长宽比1、2 和1/2。conv7、conv8-2、conv9-2 有长宽比1、2、1/2、3和1/3。因而SSD一共有8 732 锚框,如表1所示。
根据SSDD 数据集中舰船包围框长宽统计结果,设计锚框见表2、3。表2 中将所有的长宽比为2 的改成3,保持总的锚框不变,个数同样是8 732 个。
表3 将conv3 和conv7 中的长宽比为2 的改成3,在conv8-2 和conv9-2 增加长宽比4,在conv10-2 和conv11-2增加长宽比3。得到的锚框个数是38×38×4+19×19×6+10×10×9+5×5×8+3×3×6+1×1×6=9102。
通过以上改进之后,特征图上产生的锚框会更适合数据集SSDD 中的舰船目标,这会在实验部分进行验证。锚框个数增加会提高目标检测的准确率,但同时也会增加计算量,因而在设计锚框时需要充分权衡锚框个数与计算量之间的矛盾。

表1 原SSD论文中的锚框Tab.1 Anchor box in the original SSD

表2 改进的锚框设计(保持锚框个数不变)Tab.2 Improved anchor designing(keep the number of anchor frames unchanged)

表3 改进的锚框设计(增加锚框个数)Tab.3 Improved anchor designing(increase the number of anchor frames)
5 实验及分析
5.1 在PASCAL VOC数据集上的检测效果
本文提出了特征重用和语义聚合算法用于改进经典的SSD 检测算法。现对其在PASCAL VOC 数据集上检测效果进行实验验证。实验过程中采用的是预训练之后的VGG-16 模型,用NVIDA 1080 GPU 进行训练,初始学习率为0.001,最大迭代次数120 000,学习策略在[80 000,100 000,1 200 000]多步下降,采用动量为0.9 的SGD 优化,其他参数与原SSD 论文一致。图6是训练损失曲线,可看到算法收敛的很好。

图6 基于特征重用和语义聚合的SSD的训练损失曲线Fig.6 SSD training loss curve based on feature reuse and semantic aggregation
对于300×300 像素的图像,在数据集PASCAL VOC 2007 和2012 的训练数据进行训练,在VOC2007的测试集进行测试,结果达到了79.0%的mAP,速度达到了51.5FPS(在单个GTX1080显卡)。通过实验发现,它能提升对小尺寸目标的检测效果,并有较好的定位精度。结果显示,改进之后的检测算法能够在精度与速度之间进行较好的权衡,它比其他改进版本的SSD效果都要好,例如FSSD、DSSD和StairNet[10-15]。
图7是3种不同检测算法在训练过程中的精度对比。图中SSD 是指最新版本的代码实现的结果,FSSD 是文献[13]提出的改进算法。从图7 中可以看到,改进方法能够快速的收敛,且最终mAP 也是3 种检测算法中最高的。

图7 检测算法性能对比Fig.7 Performance comparison of detection algorithm
表4、5是相关检测算法的检测结果。“07+12”代表训练和验证数据集是VOC2007和VOC2012组合而成的,Faster 代表Faster R-CNN 检测算法,R-101 代表ResNet-101。从表4、5 发现,所提的方法相比于SSD及其改进版本具有最高的mAP,它还会比一些双阶段的检测算法(如表中的Faster R-CNN)效果都要好。
表6 是不同检测算法在PASCAL VOC2007 测试集上的结果。从表6 可以看出,所提出的检测算法准确率和速度上能够得到较好的权衡,它在VOC2007测试数据集上能够达到79.0%的mAP且速度是51.5FPS(单个GTX 1080 显卡),这是特征重用和语义聚合算法所起到的作用。
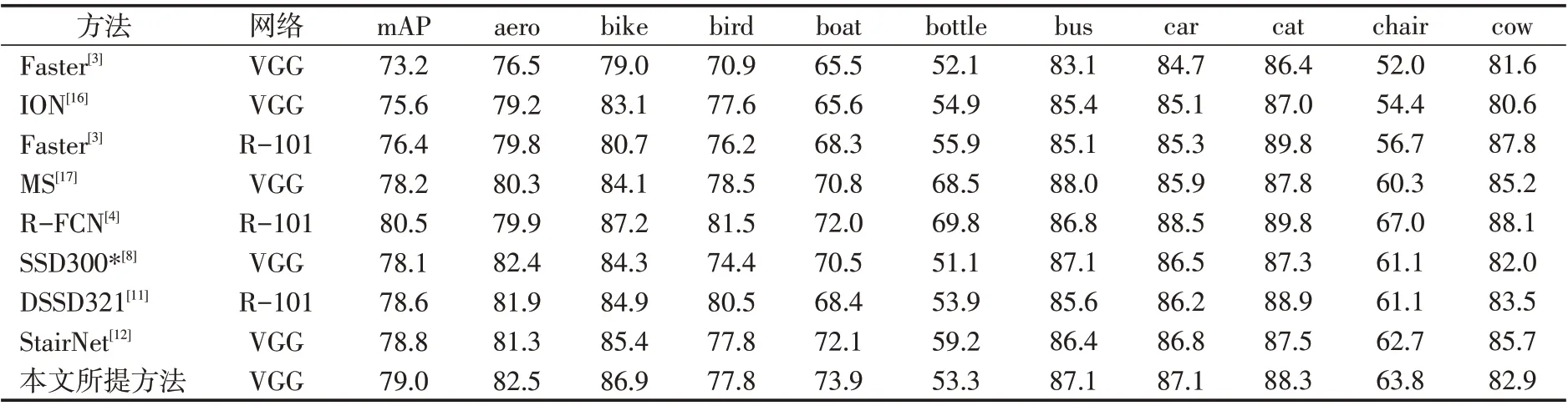
表4 PASCAL VOC2007测试集上的结果(第1部分)Tab.4 PASCAL VOC2007 results in detail(part 1)
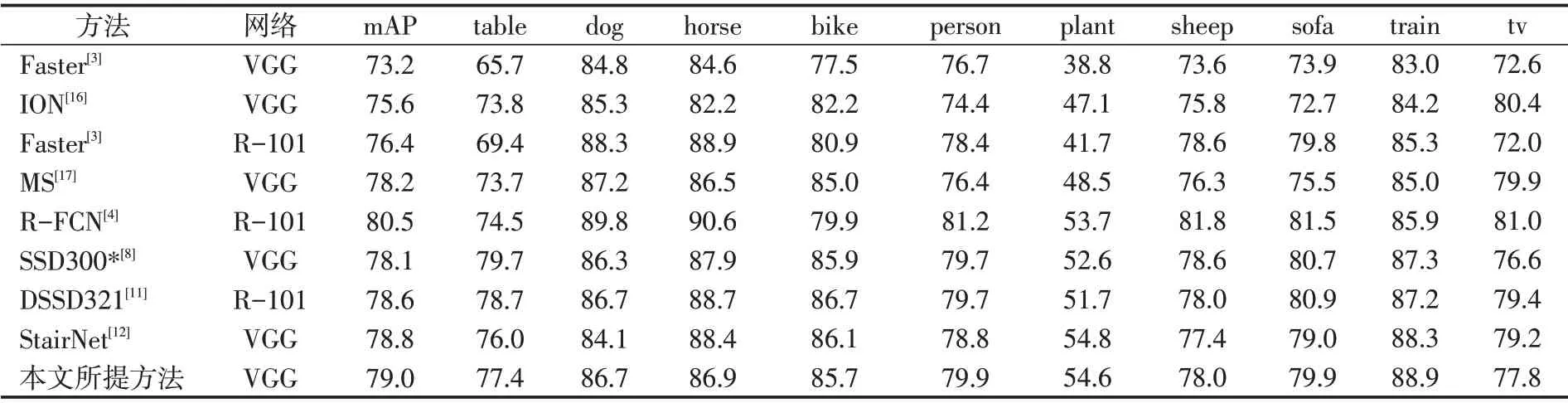
表5 PASCAL VOC2007测试集上的结果(第2部分)Tab.5 PASCAL VOC2007 results in detail(part 2)
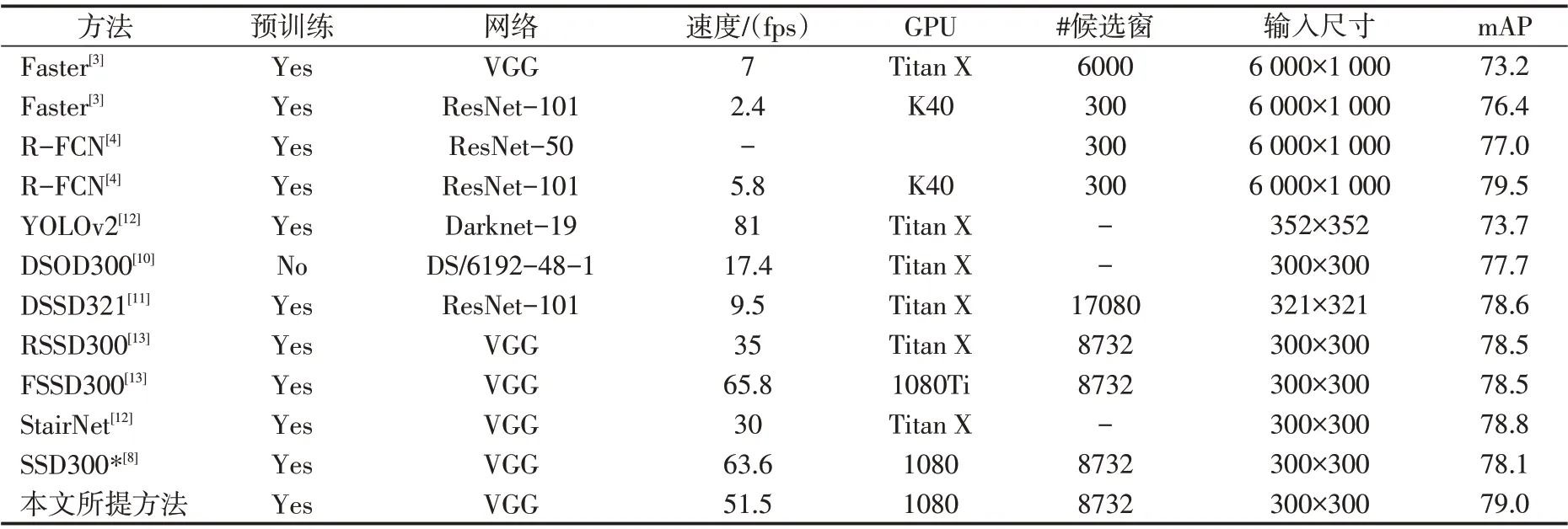
表6 不同检测算法PASCAL VOC2007测试集上的结果Tab.6 PASCAL VOC2007 test detection results of different detectors
5.2 在SSDD数据集检测效果
表7是所提出的改进算法(特征重用和语义聚合)在数据集SSDD上的效果。其中,SSD1代表只使用语义聚合不使用特征重用,SSD2 代表只使用特征重用不使用语义聚合,Proposed 代表特征重用和语义聚合都使用,表中用的都是表1的锚框配置。
从表7可发现,SSD在SSDD上的AP为77.81%,当只使用语义聚合不使用特征重用时,AP 提升了1.24%,当只使用特征重用不使用语义聚合时,AP 提升了1.77%,二者都用时,AP 提升了2.11%。通过统计单张图像处理时间发现没有得到显著的提高,平均每幅图像处理时间从17 ms(SSD)增加到了23 ms(本文所提方法)。

表7 在数据集SSDD上特征重用和语义聚合的效果Tab.7 SSDD effect of feature reuse and semantic aggregation
SSD在不同锚框下的检测性能见表8。从表中可以看到,通过改进锚框,检测性能也到了提升,尤其是利用了表3 中的锚框配置,不过在增加锚框数量的同时也会增加算法的计算量,这是须要做好权衡的。所提的特征重用和语义聚合算法和表3的组合可以得到81.43%的AP,检测的准确率得到了较大提升。

表8 不同锚框下检测效果Tab.8 Effect of different anchors frames
5.3 实验结果分析
图8是给出的改进算法(包括特征重用、语义聚合和表3 的锚框)的检测效果,从图中可以看出相比于Faster R-CNN,SSD更加适合检测大尺寸的目标,对于靠岸的舰船基本上都能检测到,如图8 a)、b)所示,密集排列在码头的舰船目标都能区分开来,如图8 c)所示,甚至是一些在船坞上不是在海里的舰船目标,如图8 d)所示,都能成功的检测到。这对于以CFAR 为主的传统检测方法是较难实现的,因为如果利用传统方法进行检测,在进行海陆分割的过程中极易把舰船目标看成陆地而漏检,即使不漏掉,在对图像进行建模时,也难以建立准确的模型拟合所有的图像像素分布,这也会导致出现很多漏警和虚警。而SSD算法能够端到端的对这些复杂背景的目标进行训练和检测,能够适应这些复杂场景,表现出了较大的优势[18]。但SSD检测算法对小尺寸的目标检测效果要比Faster RCNN要差一些,如图8 e)、f)所示。
为了进一步研究检测算法在数据集SSDD上的表现,这里给出了一些检测的失败案例,如图9所示。从图中可以看出SSD对小尺寸目标的检测效果较差(如图9 a)、b)、e)所示),甚至是一些在大片海域里的小尺寸舰船目标SSD都无法检测到,如图9 c)、d)所示,此时小尺寸目标全部漏掉,这说明SSD算法相对于Faster R-CNN 对小尺寸目标的检测能力特别差。当目标尺寸小,且所处环境背景复杂时也很难检测到目标,如图9 e)、f)所示,这是因为强散射目标对小尺寸目标有干扰作用。
之所以SSD 相比于Faster R-CNN 对小尺寸目标检测效果差,是因为以Faster R-CNN为代表的双阶段检测算法包括候选区域生成和边框分类及调整2个过程。


图8 SSD部分检测结果示例Fig.8 Some results of SSD

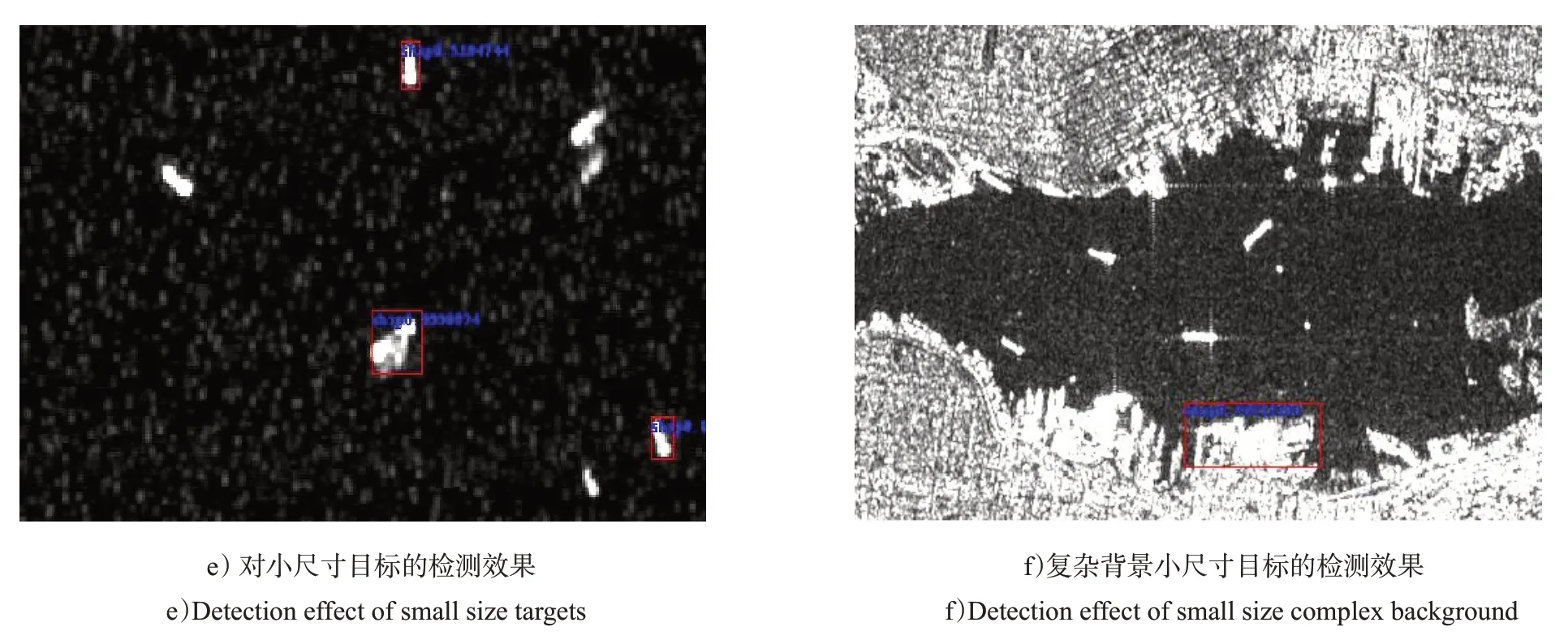
图9 SSD在数据集SSDD上的部分检测失败案例Fig.9 Some failure cases of SSD on SSDD
Faster R-CNN经过第2个过程使对边框的分类和定位更加准确,而SSD 只有一个过程,而且这个过程只相当于Faster R-CNN的第1步RPN。SSD的预测结果是从特征图的锚框对应的特征直接得到的,而Faster R-CNN 会对上面步骤得到的特征图进过RoI 池化之后进一步的处理。所以,对小尺寸的目标检测的更准确。另一方面,如果SSD检测算法中所有的锚框都没覆盖某个舰船,这时候它就不会被检测到,而当较大的锚框包含了某个舰船,这样就会使目标特征微弱,其包含目标的概率也不高。Faster R-CNN检测算法的RoI池化会对舰船的候选框进行多个子区域的划分,这样小尺寸的目标的特征会被放大,其特征会更明显,所以对小目标的效果会更好。SSD在计算速度上具有较大的优势,同时还能适应较多的复杂背景[19]。
6 结论
本文首先介绍了SSD 检测算法的原理和检测流程;然后,针对SSD 检测算法在SAR 图像舰船目标检测时对前端网络特征利用不充分的问题,提出了基于特征重用和语义聚合的SAR 图像舰船目标检测算法。特征重用算法将特征图按照通道分成2 部分:一部分被卷积处理进行参数学习,另一部分直接输入到下一阶段通过拼接的方式重新利用,这可在进行参数学习的同时减小参数量和计算量。语义聚合算法通过融合位置信息丰富的底层特征和语义信息丰富的高层特征,提高了区分和定位舰船目标的能力;之后,根据SSDD 中舰船目标尺寸和长宽比的不同,将锚框的尺寸减小,长宽比增大,提升了对SSDD中舰船目标的适应性;最后,在以上方法和策略的基础上,提出了基于特征重用和语义聚合的SAR 图像舰船目标检测算法,通过CNN 网络结构的构建、网络模型的训练,SAR图像舰船目标检测3个步骤,完成对实测SAR图像舰船目标的检测。在数据集PASCAL VOC 和SSDD中分别达到79.0%和81.43%的检测准确率。
