基于OpenCV的人脸识别课堂考勤系统
2019-02-12金维香
金维香,邢 晨
(浙江水利水电学院 信息工程与艺术设计学院,浙江 杭州 310018)
0 引言
自动化信息技术是一门新兴的科学技术[1],其中人脸识别是属于自动化信息技术中新兴的生物识别技术。人脸识别就是利用计算机分析人脸视频或者图像,并从中提取出有效的个人识别信息,最终判别出来人脸对象的身份,通常也叫做面部识别、人像识别[2-4]。随着科技的进步,人工智能和图像处理的发展,人脸识别技术也愈发成熟[5-6]。通过采集人脸信息、对图片进行处理、检测人脸、识别人脸、录入数据库等过程即可完成一个简单的人脸考勤机制。
大学课堂出勤率低一直是各大高校面临的问题。相比各行各业陆续出现的各类考勤系统,高校课堂目前较多的仍然是采用传统的课堂点名方式。而近年来,也曾有一些新兴方式在某些高校出现:如手机App签到、指纹识别[7]以及校园一卡通刷卡等。虽然这些新的方式较传统点名来说,是一种进步且日趋成熟,但是仍然有不少人为漏洞。比如手机或者校园卡有遗失与忘带的情况,学生也可以携带其他同学的手机与校园卡帮忙考勤;另外指纹识别实现成本较高。本文基于对国内高校点名机制现状的分析,通过人脸检测技术,设计并实现人脸识别课堂考勤系统,进而实现智慧课堂[8-10]。
OpenCV能够直接应用于很多不同领域,其中就包括利用自身算法来进行相关人脸识别技术的开发与实现,是作为第二次开发的理想工具[11]。OpenCV工具库属于轻量级数据库,但是它的效率很高,结合编程语言,可以实现图像处理以及计算机视觉体系处理等功能[12-13]。OpenCV提供了一套物体检测功能,经过训练后能够检测出你需要的物体。该库可以为多个场景检测所需的对象,如人脸、行为姿态、车牌等。
1 人脸识别基本原理
人脸识别技术简而言之是将摄像头识别到的人脸与系统录入的人脸进行特征判断,多方位多角度匹配特征最符合的一个。摄像头先检测人脸是否存在,再对检测识别到的人脸图像进行特征值计算,从而匹配对应的人脸,显示人脸信息。其中人脸检测是人脸识别的重要环节,人脸检测将人脸的特征与人脸图像进行各个区域的特征做对比,相似度达到一定的阈值则判断为人脸。本文的人脸检测采用基于Haar特征的AdaBoost算法,由于Haar特征数量庞大,用常规方式计算其特征值的计算量大、占用资源多、耗时较长,因此,可以借助积分图的方式来计算Haar特征值,可以大大提高计算效率。借助积分图方式进行人脸Haar特征识别的总体思路是将图像中的Haar特征(矩形特征)提取出来并计算出积分图像,得到的积分图像与人脸的积分图像对比,符合人脸特征的区域则被标记起来。
2 OpenCV人脸检测原理
OpenCV目标检测的方法是利用样本的Haar特征进行分类器训练,由弱分类器到强分类器,得到级联boosted分类器(Cascade Classification)。Haar-like算法原理介绍如下。
2.1 Haar-like特征
由三类Haar特征(边缘特征、线性特征、中心特征)组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素之和减去黑色矩形像素之和。Haar特征值反映了图像的灰度变化情况。人的一些脸部特征能简单的由矩形描述,例如:眼睛的颜色要比脸颊颜色要深,鼻梁两侧的颜色比鼻梁的颜色要深,嘴巴的颜色要比周围颜色要深等。但是单个Haar-like特征的分类能力很弱,矩形特征只能描述一些简单的特征图形,还需要利用特定的级联算法将简单Haar-like特征应用于目标的检测。Haar-like特征(见图1)。
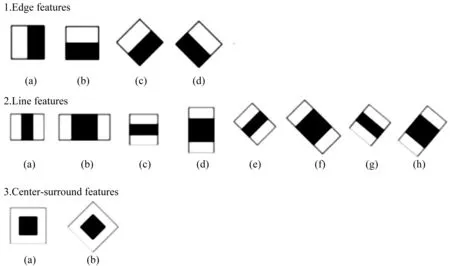
图1 Haar-like特征
2.2 图像积分图
利用图像积分图可以快速得到图像中任意矩形的像素和,大大提高了计算矩形相应特征值的速度,是Haar分类器能够实时检测人脸的保证。积分图像是将图像左上侧的全部像素进行累加计算,并将图像中的每一个像素替换成所求得的和。在Haar-like分类器的训练和检测过程中都需要计算当前子图像特征值,积分图算法求出图像中所有区域像素之和只需要遍历一次,解决了算法的耗时问题。构造的积分图(见图2)。
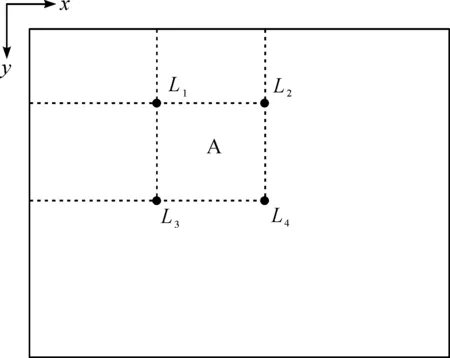
图2 图像积分图
图2中由角标L1、L2、L3、L4四个像素所表示的矩形区域D像素和为:
SumD=L4+L1-L2-L3
2.3 AdaBoost算法
AdaBoost算法就是一种基于级联分类模型在Haar特征上构建多个简单的分类器,允许设计者不断加入新的“弱分类器”。首先对每个样本的权值分布进行初始化,如果有N个样本,则将每个训练样本赋予相同的权重1/N,随后训练弱分类器。在具体训练过程中,如果某个样本已经被准确分类,那么在下一个训练集的构造过程中,其权重将会被降低;相反,如果某个样本点没有被准确分类,其权重将会升高。与此同时,得到弱分类器相对应的话语权。在结束对各个弱分类器的训练过程后,分类误差率小的弱分类器拥有较大话语权,在最终的分类函数中起着较大决定作用,而分类误差率大的弱分类器拥有较小的话语权,在最终的分类函数中起着较小决定作用。其次,更新权值后的样本集将被用于训练下一个分类器,整个训练过程不断进行迭代。最后,若干个训练后的弱分类器组合成一个强分类器,而一个级联分类器将多个强分类器连接在一起并进行操作。
由于每一个强分类器对负样本的判别准确度非常高,所以检测到负例样本,便不再继续调用后面的强分类器,减少了大量的检测时间。因为一张图像中的待检测区域大部分都是负例样本,级联分类器在分类器的初期就不会进行很多负例样本的复杂检测,所以级联分类器的速度是非常快的;只有正例样本才会被送到下一个强分类器进行再次检验,这样就保证了最后输出的正例样本的伪正(false positive)的可能性非常低。级联分类模型(见图3)。
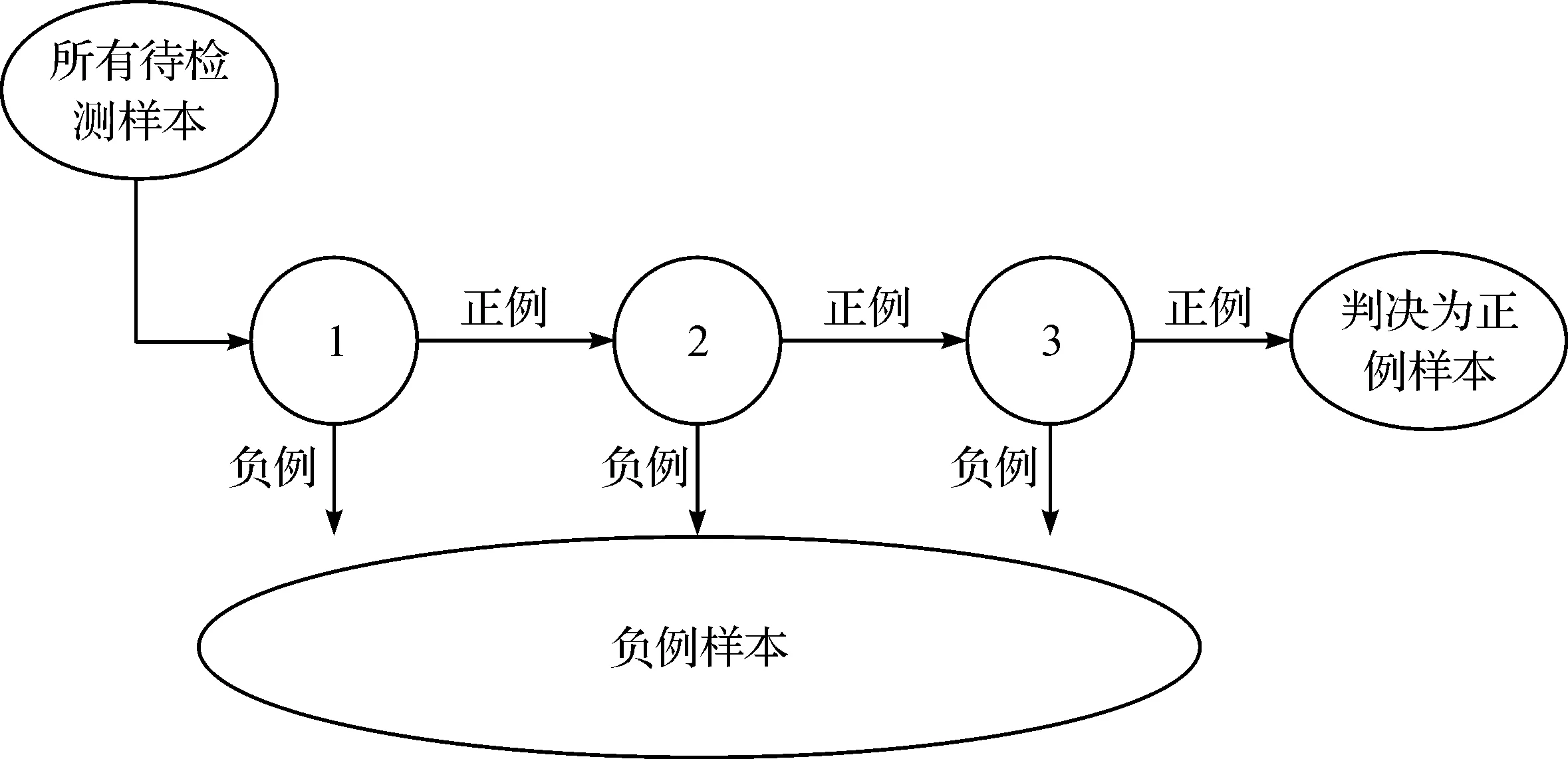
图3 级联分类模型
3 人脸识别系统实现
人脸检测系统大致分为以下步骤进行:
(1)人脸采集:对动态视频中的人脸根据设定值截取相对应数量的图片并保存;
(2)人脸预处理:对采集到的人脸图片进行灰度化、归一化等处理,统一图片大小与色彩对比度;
(3)人脸识别:计算识别到的人脸特征值,并根据特征值与之前系统录入的人脸信息进行匹配;
(4)考勤:识别到的人脸信息返回数据库,将识别到的人脸的实时时间与系统设定时间进行对比,判断是否迟到。
3.1 人脸采集
通过调用摄像头捕捉人脸并截取100张图片进行标号,将图片保存在指定文件夹下,因为该文件涉及较多人员信息且涉及个人隐私,所以在实现过程中将其进行加密处理。在采集过程中为了排除其他干扰,选择颜色单一的背景、灯光较强的场地进行人脸采集。在采集人脸时,为提高人脸识别准确性,首先将面部完全暴露于摄像头前,便于摄像头采集,其次保证人脸信息的完整度,进行人脸不同部位、不同面部表情的数据采集,包括人脸正面,人脸侧面、笑脸、闭眼等。
3.2 图片预处理
在将采集的人脸图像用于训练之前,需要将采集到的人脸信息进行灰度化、归一化等预处理,保证人脸图片的尺寸与色彩对比度保持统一。使用OpenCV内置函数cv2.face.LBPHFaceRecognizer_create()将LBP特征图像分成m个局部块,并提取每个局部块的直方图,然后将这些直方图依次连接在一起形成LBP特征并完成统计。若未对图片进行预处理,可能导致Harr特征值计算结果的误差,最终匹配到错误的人脸信息。图4展示了采集到的并处理过的部分人脸样本。

图4 部分人脸信息
3.3 人脸识别
采集被检测对象的人脸图像或视频,提取并计算其人脸Harr特征值,与之前处理过的人脸进行匹配,找到最为相似的人脸,最后在视频或图像中显示检测到的匹配人脸的名字。人脸识别简单流程(见图5),实际运行效果(见图6),通过实际系统运行发现,该系统亦可以实现多人识别功能,既出现在视野中的人脸均可以被识别出并作出姓名标记。因考虑到此次被拍摄者信息安全及隐私等问题,均使用姓名拼音首字母大写代替姓名。

图5 人脸识别流程

图6 人脸识别
3.4 课堂考勤
使用Python语言与本地数据库进行连接,将识别到的人脸信息返回至数据库,并根据检测到的人脸的实时时间将该学生的签到信息与系统设定的签到时间做对比,判断是否迟到。该表格数据包括学生学号、姓名、打卡时间、是否迟到等判断。其余信息可结合具体需求进行相关设置。课堂签到结果(见图7)。
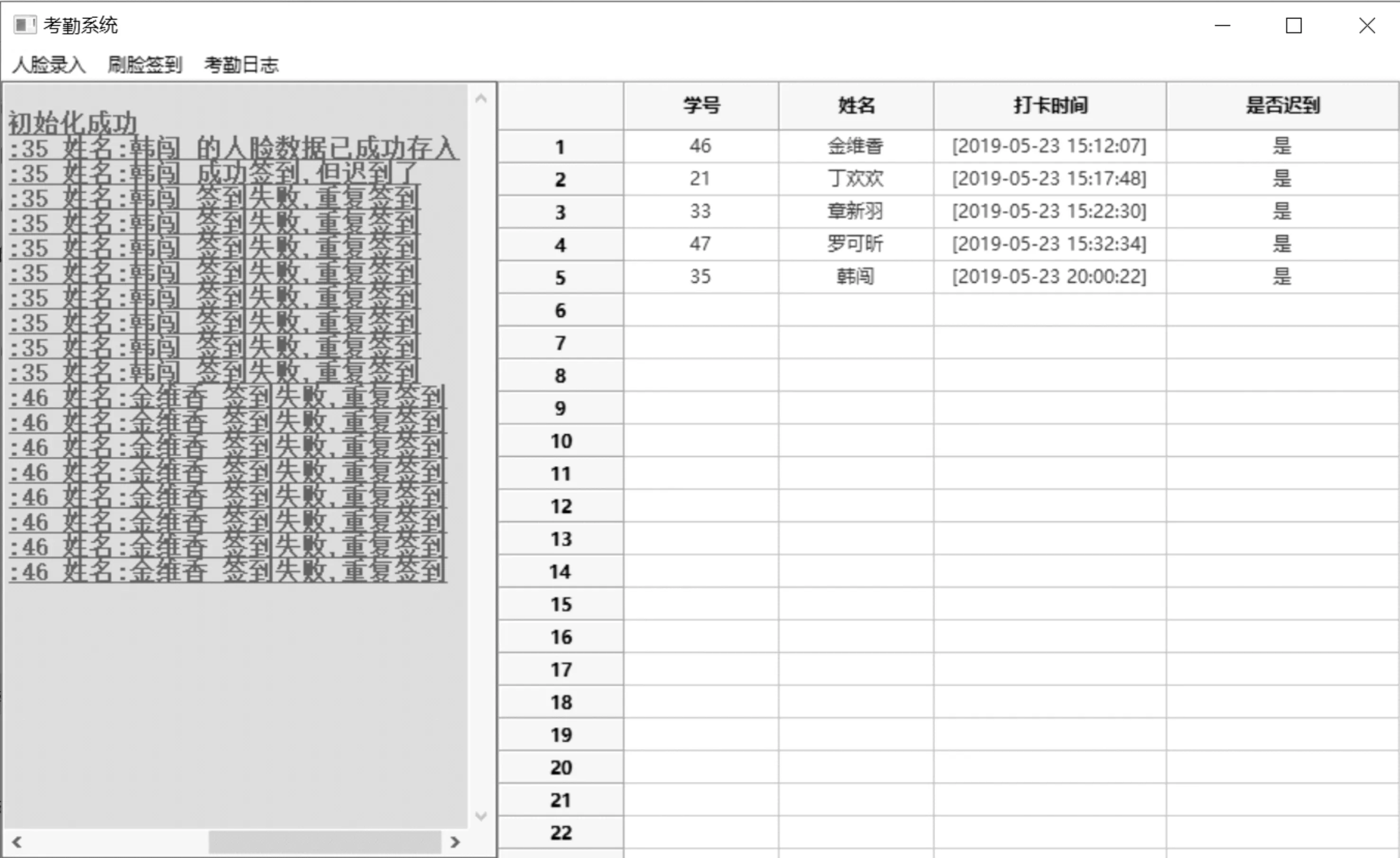
图7 签到结果数据表
4 结论
本文利用OpenCV与Python语言实现了基于人脸识别的大学课堂考勤系统,经过测试,该系统实现了通过识别学生人脸完成课堂签到,完成了对学生考勤的全面化、自动化、简易化管理,省去了教师点名的时间,方便了同学的签到,大大提高课堂管理效率。此外,该技术可适用于其他需人员打卡场地,具有较为实际的使用价值。
