基于XGBoost的搜索结果智能排序系统
2019-02-07赵晗孟晓景张春勇
赵晗 孟晓景 张春勇


摘要:针对传统基于模型的搜索引擎排序及特征获取慢、非数值特征处理复杂等问题,提出一种基于XG-Boost的搜索结果智能排序模型。基于XGBoost算法构建排序模型,使用独热编码和Apriori算法对非数值特征进行处理和筛选,利用Redis对用户和商家特征数据进行缓存,通过并行预测的方式加快模型预测商家得分速度,最后利用XGBoost自带的模型评价函数对最终训练出来的模型进行评估,结果显示模型预测准确率为0.76,说明模型给符合用户偏好的商家打出了较高的分数。其中在训练集上的AUC为0.72,在测试集上的AUC为0.69,两者相差不大,表明模型没有出现明显的过拟合现象,而且准确率较高,可用于构建商家排序模型。
关键词:XGBoost;特征缓存;特征筛选;并行预测
DOI:10.11907/rjdk.191138
中图分类号:TP303 文献标识码:A 文章编号:1672-7800(2019)012-0056-05
0引言
搜索引擎的任务是在用户输入一个查询词后返回给用户可能相关的结果。搜索引擎对于不同搜索结果的质量(结果相关性评分)进行判断(预测),返回结果越相关,用户满意度越高,对搜索引擎的依赖度和忠实程度越高,从而为搜索引擎带来更多流量。因此,搜索结果质量是搜索引擎最重要的评价指标之一。
为了返回高质量的排序列表,现代商用搜索引擎(如Google、百度、搜狗等)在对候选结果进行排序时,使用了多种相关性预测方法。其中包括传统基于词频的相关性评分,如TF-IDF、BM25,也包含基于互联网网页链接结构的相关性评分,如PageRank、HITS、TrustRank、BrowseRank、ClickRank等,以及近年来以点击模型为代表,利用用户与搜索引擎的交互信息计算搜索结果相关性评分的方法。
(1)基于词频的相关性评分。这是搜索结果质量最传统的评价方法,该方法评价流程可以概括为:首先选取衡量结果相关性的特征(如TF-IDF和BM25),對获取到的用户查询词和文档进行处理以提取特征,使用特征相似程度代表各个搜索结果与用户查询词之间的相关性。该方法可以快速并且相对准确地从基于内容的搜索结果中提取出用户想要的结果,是最基础的排序策略。但是基于词频的相关性评分并不能完美解决基于内容的结果相关性问题,Lv等指出,当搜索结果的内容长度非常大时,BM25指标会失效。所以,除内容信息之外,搜索引擎应该寻找更多的有效信息去更有效地衡量搜索结果的相关性,这样才能为用户提供更满意的结果排序。
(2)基于链接的相关性评分。由于全文搜索引擎中的搜索结果基本上是网页,而网页中一般都携带有多个超链接,这些超链接使网页之间可以相互连接,构成了一种网格结构,所以搜索引擎的研发者们可用互联网网页的链接结构推断不同结果的重要性、可靠性等,从而对搜索结果的相关性进行更加合理的评估策略。该方法对全文搜索引擎的结果排序相关性估计有极大促进作用,但是不能应用于搜索结果为非网页的搜索引擎上。
(3)基于搜索引擎与用户交互信息的相关性评分。近些年来,随着大规模数据处理技术及机器学习技术的发展,利用用户与搜索引擎的交互信息计算搜索结果相关性评分的方法逐渐受到关注。由于用户与搜索引擎的交互信息主要是点击信息,所以研究人员提出构建描述用户点击行为的点击模型,尝试利用点击信息对结果相关性进行评价。点击模型尝试利用大规模的用户点击信息去推测用户对搜索结果的点击概率,以达到更好利用点击信息的目的。由于可以有效利用用户交互信息,点击模型得到了学术界广泛关注,在工业界也得到了大规模应用。例如Etsy、雅虎、Airbnb均使用了点击模型,根据客户偏好进行搜索排序工作。
1系统构造
1.1系统设计
排序模块用模型对召回模块获得的搜索结果列表进行排序,以获取质量更高的搜索结果列表。排序模块首先获取缓存特征,其中有用户特征、商家特征以及交叉特征,再用模型对每个结果的特征向量进行打分,最后按分数降序构造最终结果。
1.2缓存设计
Redis是一款开源的高性能NoSQL数据库。为了满足高性能的需求,Redis采用了内存数据集。Redis还具有高效的持久化机制,以保证数据不会丢失,很适合本文排序模块中缓存特征数据的场景,因此本文使用Redis缓存特征以加快模型预测速度。
本文使用的特征包含商家特征、用户特征以及用户商家交叉特征,系统如果直接从数据库中读取数据,则存在速度慢和数据库压力过大的隐患,因此本文将数据库中的特征数据定期(每日)存人缓存之中,既减轻了数据库压力,也提高了系统读取特征的速度,美中不足的是对本文所述的小型服务器而言,数据量太大会提高对内存的要求,不过可以使用Redis集群的方法缓解压力。各种特征在缓存中的存储格式如表1所示。
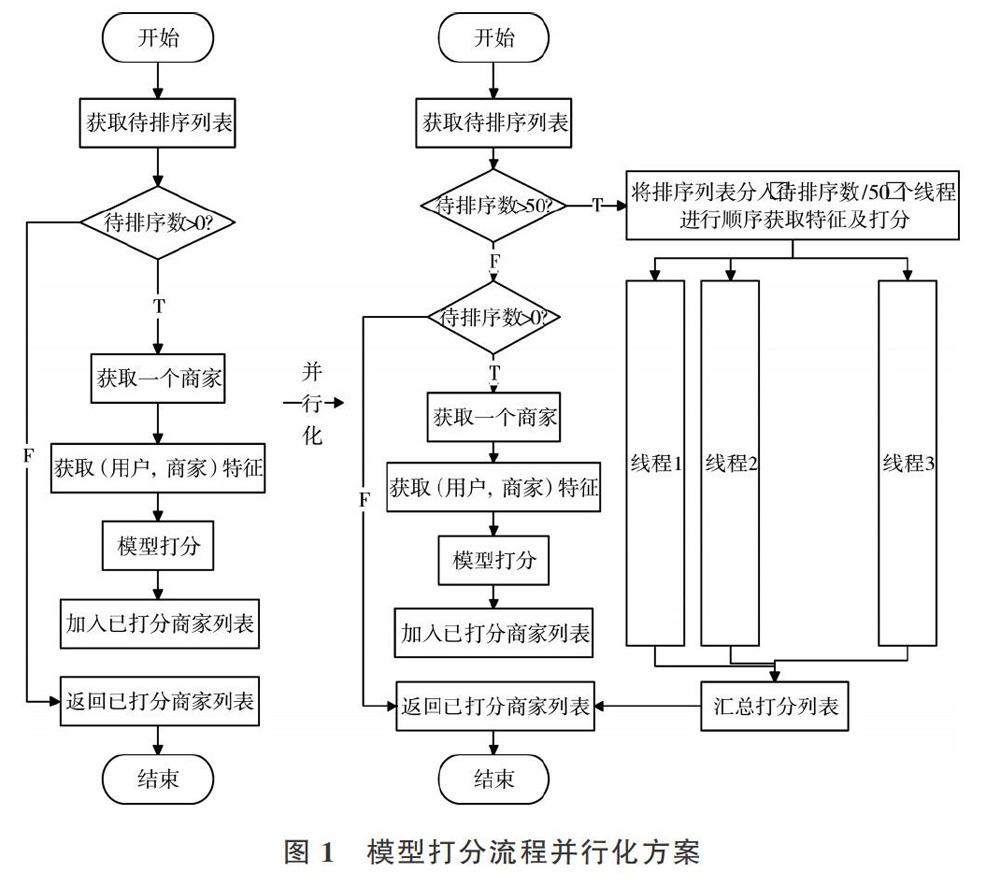
1.3并行预测
商家数量较多时,模型使用串行方式进行打分会造成额外的时间开销,本文将商家分组分到多个线程进行并行打分,最后将结果汇集,可以大幅减少时间开销。例如若候选集中有180家,本系统会将180家商品分成4组,分别是50、50、50、30,分配到4个县城中进行预测操作,可有效节约预测时间,经过并行化后预测耗时平均会下降至串行预测耗时的1/2。具体设计方案如图l所示。
2模型构造
2.1XGBoost
本文使用XGBoost(Extreme Gradient Boosting)训练搜索结果排序模型,XGBoost是GMB(Gradient Boosting Ma-chine)的一个c++实现,其作者是华盛顿大学的陈天奇。XGBoost在Kaggle等算法比赛上的成绩十分亮眼,以其高效的训练速度以及优秀的学习效果获得了机器学习界各类人士的广泛关注,工业界也有很多公司开始使用XG-Boost作广告点击率(click Through Rate,CTR)预估。作为一种提升算法,XGBoost不仅支持分类回归树(classifica-tion and Regression Trees,CART)作为其基分类器,而且还支持线性分类器(如逻辑斯蒂回归和线性回归)作为其基分类器,本文以CART作为XGBoost的基分类器对模型进行训练。
2.2数据介绍
实验选取Kaggle提供的Yelp数据集。本文用到的Yelp数据集是Yelp业务、评论和用户数据的子集,最初出现于Yelp数据集挑战赛,该项活动是一个让学生对Yelp数据进行研究分析并分享研究成果的机会。在数据集中,可以找到4个国家11大都市的商业点评信息。总共有5200000条用户评论、174000家商户信息,并提供JSON和CSV两种格式。本文筛选出商家表、用户表、来访表作为实验数据。
2.3模型训练
本文模型训练流程为数据预处理、特征选取、模型训练和模型调参以及最终模型确定。本文首先对没有到店记录的用户以及没有来访记录的商家进行清洗,对用户单条评分、商家总来访次数等数据进行规范化处理,对城市、商家类别等属性进行独热编码处理以产生更多特征。
2.4基础特征选择
本文根据现有与商家相关的数据,挑选和构造了城市、平均评分、规范来访数、标签、近半年来访数和近一年来访数等6种数据作为基础模型的训练特征,特征的详细类型、值域以及处理方式见表2。
2.4.1商家特征
2.4.2用户特征
本文根据现有与用户相关的数据,挑选和构造了规范访问数、平均评分、平均评论字数、近半年访问数和近一年访问数等5种数据作为基础模型的训练特征,特征的详细类型、值域以及处理方式见表3。
2.4.3交叉特征(用户一商家特征)
本文根据现有与用户和商家的交互信息数据,挑选和构造了以规范化到店数、平均评分、平均评论字数、近半年到店数和近一年到店数等5种数据作为基础模型的训练特征,特征的详细类型、值域以及处理方式见表4。
2.5特征筛选
先验算法(Apriori Algorithm)是一种经典的关联规则学习算法。先验算法需要在数据挖掘过程中通过多次扫描数据库不断寻找候选集,然后进行剪枝操作。先验算法通过对最小支持度阈值的设置,可系统地控制候选项数量无序增长。
本文使用独热编码将非数值型特征转换为数值型特征,经独热编码处理后的特征有上百个,特征非常稀疏,所以本文使用先验算法处理经过独热编码处理后的商家类别特征,目的是挖掘出与用户访问记录(flag)相关的商家类别。本文使用先验算法从100多个商家标签特征中挑选出17个支持度和置信度较高的特征。最终选出的商家分类特征见表5。
2.6模型评价标准
本文使用ROC曲线下方的面积(Area Under the CurveofROC,AUC)作为模型评价指标,AUC一般只能用于二分类模型评价,而本文模型属于回归模型,但是由于将排序模型的预测结果(用户对商家评分)规范化到了区间[0,1]中,所以可以将该问题看作一种特殊的分类问题,故本文训练的回归模型AUC也是可以计算的。
2.7模型调参
选取完特征后,将用户的每条评分记录与选取的特征结合起来,以特征向量为自变量,以规范化后的用户评分为预测变量构建训练集,进行模型训练,同时通过交叉验证的方法对模型进行参数调节。XGBoost参数分为3类:通用参数、Booster参数和学习目标参数。通用参数用于宏观的函数控制,例如选择树模型;Booster参数用来控制模型训练过程中每一步的優化情况;学习目标参数用来控制训练目标的表现情况。本文采用XGBoost回归树(XGBRegressor),在前文所述特征的基础上建立基础模型,在基础模型的基础上使用交叉验证(cross-validation)的方法进行参数调节,调节结果及相应参数含义如表6所示。
3实验分析
3.1实验环境介绍
本文实验环境为在一台安装有CentOS 7.0系统的云主机,拥有16G内存,Elasticsearch版本6.2.2,Java版本1.8.0_161,Redis版本4.0.8。
3.2模型评分
本文使用XGBoost自带的模型评价函数对最终训练出来的模型进行结果评估,结果如表7所示,其中模型预测准确率为0.76,说明模型给用户偏好的商家打出了较高的分数。其中在训练集上的AUC为0.72,在测试集上的AUC为0.69,两者相差不大,表明模型没有出现明显的过拟合现象,而且准确率较高,可用于构建商家排序模型。
3.3排序结果对照
为了证明模型对搜索结果的提升效果,本文构造实验对比系统在使用排序模型和不使用排序模型(使用Elastic-search默认的排序分数)情况下的搜索结果。如图2所示,本文用一位在“Hotels & Travel”和“Transportation”标签下有过访问数据的用户的身份进行搜索操作,模拟该用户在多伦多市搜索“subway”。
在不使用模型排序的情况下(图2左界面),Elastic-search召回10个结果,排名前八的都是“Subway”快餐店,而后面的是两个“Subway Station”。在使用模型排序的情况下(图2右界面),由于该用户访问过的商家中没有“FastFood”和“Restaurants”标签,虽然“Subway”快餐店对于t,SUb-way”这个查询词来说是精准匹配,但用户经常与具有“no-tels & Travel”和“Transportation”标签的商家进行交互,所以在模型预测时给“Subway Station”的评分会较高,最终排序模型还是将两个“Subway Station”排在了前面。
虽然本文构建的商家排序模型牺牲了一些文本相关性,但是可以提升迎合用户偏好的搜索结果排名,满足了用户对于搜索结果个性化、地域化、实时化的需求,证明了本文系统的智能性。
4结语
本文构建了基于XGBoost的用户个性化商家排序模型,利用XGBoost训练速度快及模型效果明显的优点,使用XGBoost构造搜索引擎的排序模型。在训练模型时对数据按照规范化、独热编码等方式进行处理以生产特征,通过Apriori算法对稀疏特征进行筛选,利用商家特征、用户特征以及用户与商家交互信息特征训练模型,使用交叉验证的方式进行参数调节和特征选择,同时使用Redis缓存对用户和商家的特征数据进行存储,使用并行的方式加快模型预测分数的速度。
此外在查询分析阶段,本搜索引擎使用分析方法,将Elasticsearch自带的分析器组合使用得到最终的查询分析器,而且该查询分析器的使用范畴仅限于英文,没有对中文的支持。未来研究将加入对中文的支持,并尽可能将查询分析从Elasticsearch中独立出来,独立查询分析模块可以更方便地控制查询分析过程,更便捷地对用户输人的关键词进行语义分析,更方便地使用自然语言处理和人工智能新技术。
