基于特征波长建模的近红外光谱技术检测辣椒素含量
2019-02-06吕晓菡蒋锦琳杨静陈建瑛岑海燕傅鸿妃周毅飞
吕晓菡,蒋锦琳,杨静,陈建瑛,岑海燕,傅鸿妃,周毅飞
(1.杭州市农业科学研究院,杭州310024;2.浙江大学生物系统工程与食品科学学院,杭州310058;3.浙江农林大学农业与食品科学学院,杭州311300)
辣椒(Capsicum annuumL.)是一种茄科(Solanaceae)辣椒属(Capsicum)的常异花授粉作物,起源于南美洲,如今已成为世界范围内非常重要的农业经济作物之一,尤其是在中国和韩国[1-5]。随着生活水平的不断提高,人们对辣椒的要求不再停留在抗病性和产量上,辣椒的口感,尤其是其辣度的细化,已成为辣椒育种工作的新热点。评价辣椒的辣味主要是指其辛辣程度,辣度越高,辣椒素类物质含量越高,辣椒越辛辣。辣椒中的辣椒素类物质主要有5 种,分别为辣椒素(capsaicin)、二氢辣椒素(dihydrocapsaicin)、降二氢辣椒素、高辣椒素和高二氢辣椒素[6]。其中辣椒素和二氢辣椒素约占总量的90%,也提供了约90%的辣感和热感,并且起主要作用的是辣椒素[7-8]。目前,检测辣椒中辣椒素的方法除了传统的化学方法外,还有高效液相色谱法、酶联免疫法、荧光光谱法、核磁共振法等[9-14],然而这些方法基本上是费时费力的破坏性检测技术,迄今为止,快速、精准又便捷的检测方法还很少。
随着光谱技术的快速发展,近红外光谱检测技术已经广泛应用于农产品品质与安全的快速无损检测中[15-18]。把近红外光谱技术引入到辣椒素含量的检测中,对辣椒中辣度的快速精准评价有重要意义,对缩短辣椒育种进程有较大的促进作用。杭椒类辣椒是江浙沪地区的传统优势品种,除了具有入口绵软无渣的特点外,嫩果微辣或不辣,老熟果辣味浓也是其另一大特色。根据不同人群的辣味需求,可以在不同时期进行辣椒果实的采收。本文以杭椒类辣椒新鲜果实为研究对象,通过采集新鲜辣椒果实的近红外光谱信息,建立辣椒素含量的近红外光谱预测模型,同时结合特征波长变量优选算法简化模型,为后续开发便携式辣椒品质快速分析仪器提供理论基础和技术支撑。
1 材料与方法
1.1 材料
选取6份杭椒类辣椒种质材料的果实为研究对象,并将其编号为HJ01~HJ06。在相同时期内,对“门椒”“对椒”“四门斗”“八面风”“满天星”等果位上完全开放的花朵进行标记,每个品种标记30 朵。当植株进入盛果期时,每份材料采集60 个果实,共获得360个果实样品,备用。
1.2 光谱采集及辣椒素含量测定
光谱采集系统主要由光谱仪、光源、环形光纤探头、计算机等组成。其中:光谱仪为便携式USB2000+微型光纤光谱仪(Ocean Optics 公司,美国),采用CCD 阵列可见近红外光谱(visible-near infrared spectroscopy, VIS/NIRS)检测器,采样范围为874~1 734 nm,数据点为2 048。光源为50 W的外置卤素灯。自主设计的环形光纤探头通过2条光纤(环形光纤和探测光纤)分别与外置光源和光谱仪连接,其中环形光纤将光源发出的光传输并照射到检测部位,探测光纤将检测器采集到的光返回给光谱仪从而获得样本的光谱信息。本实验采用线扫描的方式,将新鲜辣椒果实放置在铺有不反光黑布的样品台上,距离光谱仪镜头距离为30 cm,扫描完整的辣椒果实3 次,取平均值。在采集完360 个新鲜辣椒果实的光谱信息后,利用高效液相色谱法[《辣椒素的测定 高效液相色谱法》(NY/T 1381—2007)][19]依次检测辣椒素含量。
1.3 辣椒素含量的近红外光谱预测模型的建立
在近红外光谱技术中,偏最小二乘法(partial least squares,PLS)是比较常见的建模方法。由于全波段光谱数据具有较强的共线性,存在大量冗余信息。因此,特征波长的筛选一方面可以简化预测模型,另一方面可以消除不相关和非线性的光谱变量,从而提高模型的稳定性和准确性。本文分别基于全谱和特征波长建立预测模型,并对预测效果进行比较。
1.3.1 全谱建模
PLS 是一种有效的多元统计方法,本质上是一种基于特征变量的回归方法,广泛应用于近红外光谱数据的处理。PLS模型在对量测矩阵进行分解的同时,对响应矩阵也进行正交分解,并在这2个矩阵间建立定量关系,从而使得对多个量测响应的预测成为可能[20-21]。本文中量测矩阵为光谱数据矩阵,量测响应矩阵为辣椒素含量矩阵。
1.3.2 特征波长建模
近红外光谱主要反映有机物质的倍频和合频吸收,不同物质谱带信息重叠严重,使全波段光谱中含有大量冗余信息及噪声,从而影响了模型的预测性能。因此,为了简化模型,提高建模效率,实现仪器开发,需要一种有效的手段来提取全波段中的特征波长,舍去无效的波段信息,提高建模的速度,减少计算量。本文分别采用连续投影算法(successive projection algorithm, SPA)、竞争性自适应重加权采样法(competitive adaptive reweighted sampling,CARS)、无信息变量消除法(uninformation variable elimination,UVE)提取特征波长,其他步骤与全谱建模相同。
SPA能够从光谱信息中充分寻找含有最低限度冗余信息的变量组,使得变量之间的共线性达到最小,同时能大大减少建模所用变量的个数,提高建模的速度和效率[22-23]。CARS 是模拟达尔文进化论中“适者生存”原则,将每个波长变量看成一个个体,通过自适应重加权采样(adaptive reweighted sampling,ARS)技术筛选出PLS 模型中回归系数绝对值较大的波长变量,去掉权重较小的变量,从而获得一系列波长变量子集,然后对每个波长变量子集采用交叉验证建模,根据交互验证均方根误差(cross validation of root mean square error, RMSECV)最小原则,选择最优的波长变量子集[24-25]。UVE 是一种基于PLS 模型回归系数的特征波长选择方法[26-27],通过消除不含信息的变量,最终剩下对化学组分预测的有用变量。
2 结果与分析
2.1 辣椒素含量的数据分析
利用高效液相色谱法检测360个新鲜辣椒果实中的辣椒素含量时,由于小部分样品中辣椒素含量极其微量而未被检出,最终获得341 个样本数据。通过对获得的341 个数据进行分析可知,大部分数据均集中于0.01~0.13 mg/g之间(图1)。为了减少误差,对不在该区域内的数据进行剔除,最终获得275个样本数据(图2)。按照Kennard-Stone算法以2∶1 的比例划分建模集与预测集,二者辣椒样本的辣椒素含量分析见表1。
2.2 光谱反射率曲线
对原始光谱进行预处理后,采用Savitsky-Golay(SG)卷积平滑法,对滤波进行平滑处理,降低噪声对信号的干扰。然而,由于存在系统误差,光谱曲线在首尾端有较大的噪声,会直接影响试验的准确性,因此,对数据处理时只研究波长在975~1 645 nm 波段的光谱数据。新鲜辣椒的近红外光谱曲线如图3所示。

图1 全部样本的辣椒素含量频率直方图Fig.1 Frequency histogram of the capsaicin content of all the chili pepper samples

图2 剔除异常样本后的辣椒素含量频率直方图Fig.2 Frequency histogram of the capsaicin content of chili pepper samples after removing abnormal samples

表1 建模集和预测集辣椒样本中辣椒素的含量Table 1 Capsaicin content of chili peppers for the modeling and prediction sets mg/g
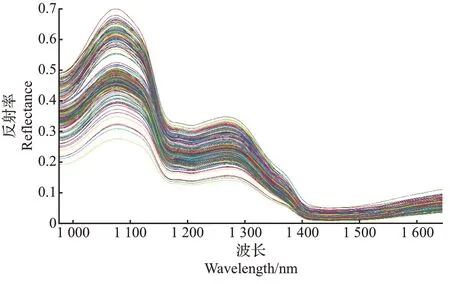
图3 新鲜辣椒果实的平均光谱Fig.3 Average spectra of fresh chili peppers
2.3 光谱数据的处理与分析
2.3.1 基于全谱建模
PLS 建立的模型的各项参数如图4 所示:无论是建模集还是预测集,模型中辣椒素含量的真实值与预测值之间的相关系数均在0.8 以上,这说明模型的预测值和真实值之间具有很好的相关性,也说明所建立的PLS 模型可以很好地预测辣椒样品的辣椒素含量。

图4 PLS模型建模集(A)和预测集(B)的预测结果Fig.4 Predicted results of modeling set (A) and prediction set(B)of PLS model
2.3.2 特征波长的选择
表2 总结了基于SPA、CARS、UVE 3 种方法选择的特征波长。从中可以看出,SPA 选择的特征波长数比其他2 种方法少。与全谱建模的输入变量200 相比,特征波长模型(SPA-PLS、CARS-PLS、UVE-PLS)的输入变量分别减少了97%、96%、96%,这大大简化了模型,提高了运算效率。因此,所选择的特征波长具有良好的应用前景,可代替全光谱进行辣椒素含量预测模型的建立。从表2中还可以看出,所选择的特征波长大部分在1 110~1 500 nm范围内,这主要由C—H键和O—H键的伸缩振动引起[28-29],而这些基团主要与辣椒果实中的辣椒素有关。

表2 基于3种方法选择的特征波长Table 2 Optimal wavelengths selected by three methods
2.3.3 基于特征波长建模
为了简化模型,提高建模效果,实现仪器开发,利用SPA、CARS、UVE 提取特征波长,所建立的模型的各项参数如图5~7所示。从中可以看出,基于特征波长建立的模型预测结果与基于全谱建立的模型预测结果相当。无论是建模集,还是预测集,所有模型中辣椒素含量的真实值与预测值之间的相关系数均在0.8 以上,这说明模型的预测值和真实值之间具有很好的相关性,也说明用SPA、CARS、UVE 提取特征波长建立的模型也可以很好地预测辣椒果实中的辣椒素含量。其中,CARSPLS 模型的预测效果最好,预测集相关系数和均方根误差分别为0.838 6和0.014 8 mg/g。

图5 SPA-PLS模型建模集(A)和预测集(B)的预测结果Fig.5 Predicted results of modeling set (A) and prediction set(B)of SPA-PLS model
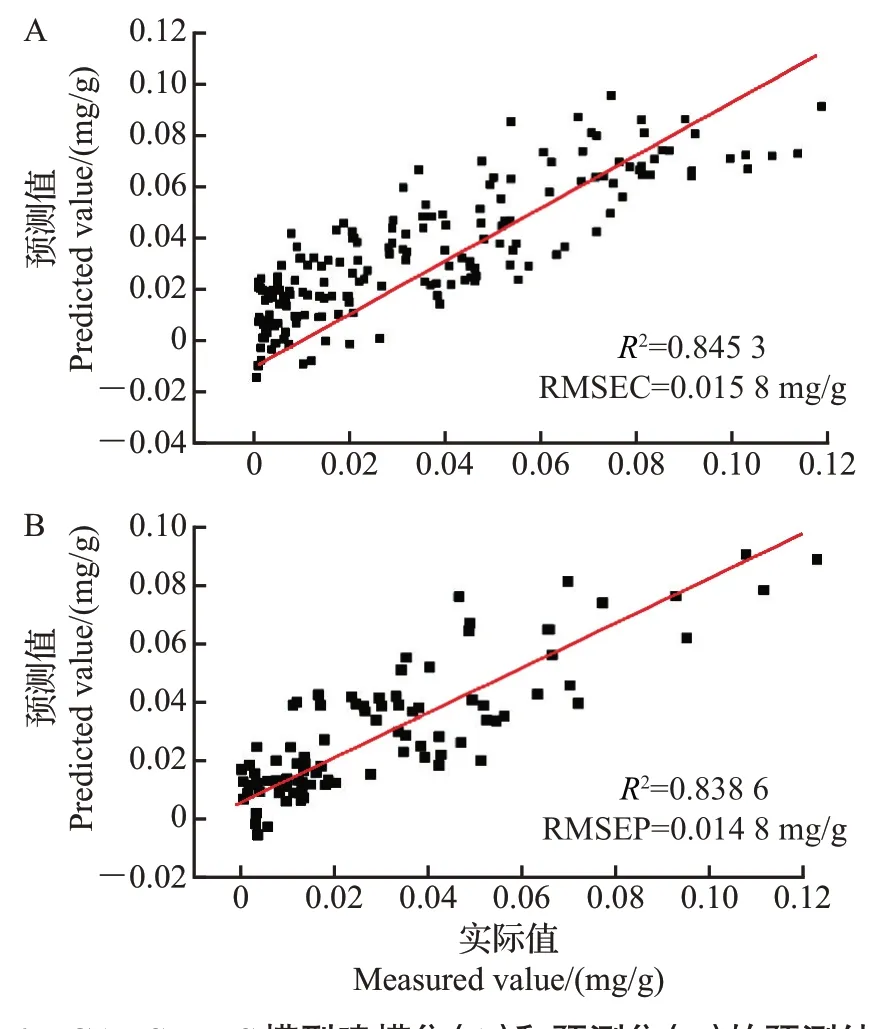
图6 CARS-PLS模型建模集(A)和预测集(B)的预测结果Fig.6 Predicted results of modeling set (A) and prediction set(B)of CARS-PLS model

图7 UVE-PLS模型建模集(A)和预测集(B)的预测结果Fig.7 Predicted results of modeling set (A) and prediction set(B)of UVE-PLS model
3 结论
本文主要研究了近红外光谱技术与高效液相色谱法相结合对杭椒类辣椒新鲜果实中辣椒素含量进行快速检测的可行性。试验共获得了275个新鲜辣椒果实的近红外光谱和辣椒素含量信息,按照Kennard-Stone 算法以2∶1 的比例划分建模集与预测集,分别采用全谱建模和提取特征波长建模(SPA、CARS、UVE)2 种方式建立预测模型。结果发现:无论是基于全谱建模,还是基于特征波长建模,其建模集和预测集的相关系数均达到0.8以上,这不仅说明所有模型的预测值和真实值之间具有很好的相关性,而且说明基于特征波长建立的模型也能取得较好的预测效果。此外,SPA、CARS、UVE 3 种算法选择的波长数分别为6、8、8,与全谱波段200 相比,大大减少了变量数,简化了模型,提高了模型的运算速率。本研究表明,基于特征波长建模的近红外光谱技术对于辣椒果实中辣椒素含量的检测是可行的,实现了对新鲜辣椒果实的无损准确预测。这不仅为开发便携式新鲜辣椒果实无损检测设备做好了前期准备工作,也为辣椒精准育种中辣度的进一步细化提供了参考。
