基于移动端平台的目标检测及其优化
2019-01-30程剑刘海涛张琦珺
文/程剑 刘海涛 张琦珺
目标检测作为图像处理和计算机视觉领域的重要课题,在警戒安防、交通监控、人机交互等工程应用中扮演着重要的角色。受限于光照、角度、遮挡等因素,传统检测算法在复杂的工程环境下表现鲜有出彩。
2014年基于候选区域的深度学习检测算法R-CNN一经提出,其以惊艳的检测效果击败了一众经典算法,一举夺得了目标检测领域的头筹。此后此类算法得到了研究者们的重点关注,短时间内获得飞速长足的发展。先是出现了R-CNN的改进算法Fast R-CNN、Faster R-CNN,后又有基于回归的检测方法,如YOLO、SSD、YOLOv2、DSSD、YOLOv3等,在保证准确率的前提下,也满足了工业实时性的要求。
如今在要求稳定精准快速的目标识别工程项目上,深度学习检测算法已经不可或缺。笼统来说,这些检测算法都需要将输入图像经过深层的卷积神经网络提取出高维特征,再利用这些特征来定位和分类图像中物体。以YOLOv3为例,基础网络和yolo网络共有105层,其中含有大量矩阵卷积操作,浮点计算量相较于经典算法不可同日而语。因此,深度学习算法往往需要运行在高性能的GPU服务器上,这就为实际工程应用带来了不便。往往在项目中,既要满足算法速度和精度的要求,也要考虑到复杂苛刻的工程环境以及系统部署的方便简易性,同时还要兼顾成本和功耗,如何在移动端平台AI芯片上实现实时的深度学习检测算法便显得尤为重要,成为了当下的研究热点。
目前的AI芯片大致可以分为两类。第一类是一种协处理器,独立于主处理器之外,只用来专门计算神经网络前向过程,一般价格低廉且通用性强;第二类则是将CPU、GPU、DSP等都集成到SoC中,这样内部数据在各种计算内核之间的迁移得到优化,整体流程耗时降低,且一般体积更小、功耗更低。
本文以地铁站客流统计为例,在服务器上训练出SSD模型,利用SNPE SDK (Snapdragon Neural Processor Engine SDK)将模型转为Kryo和Adreno支持的dlc(Deep Learning Container)格式,运行于高通骁龙835芯片上。另外对模型做了针对性的优化,降低了在手机上运行时的内存需要和时间损耗,增强了模型的抗虚警能力。实验结果表明,算法检测结果准确,每帧检测耗时约45ms,满足工程应用要求。
1 SSD算法简介
SSD是Wei Liu在ECCV 2016上提出的一种one-stage目标检测算法。区别于R-CNN的先提取候选区域再分类的流程,SSD的整个检测过程只需要一步,在一次前向过程中就能完成预选框选择、预选框特征提取、目标分类、目标定位这些操作。SSD的结构使其便于训练和优化,同时也提高了检测速度。
SSD的网络结构如图1所示,可以看出网络由两个部分构成。左侧的VGG-16为SSD的基础网络,主要负责对图像做卷积操作,加深网络以提高拟合性能。其中的Conv4_3层与右侧增加的5个特征层则每层产生三个输出,直接作用到目标识别。第一个输出是预选框的坐标和回归权值参数第二个输出是经过一次批标准化(batch norm)和卷积后产生的给预选框分类的置信度向量第三个输出同样需要经过一次批标准化和卷积,用于给预选框坐标回归,其中n为预选框的序号,假设该层共产生预选框N个,则。
经过一次网络前向后便能得到上述的输出。由于置信度向量遵循softmax原则,因此有:
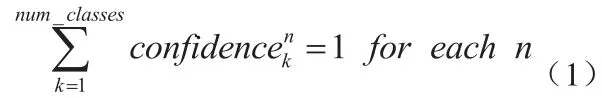
挑选出每个预选框中最大置信度对应的序号k,即为该预选框的类别。再通过预选框坐标和其回归向量,即可计算出真实目标位置,对每一个预选框,计算方法如下式2所示:
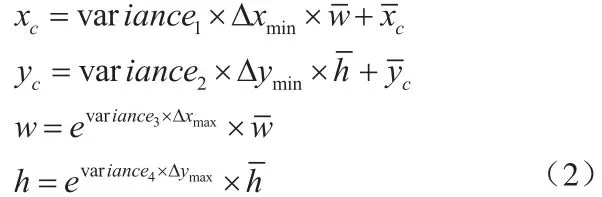
SSD利用了6层特征来生成、调整、分类预选框,最后经过非极大值抑制的筛选即可获得正确的目标位置信息,由于多尺度的特征映射在原图上代表不同感受野,因此SSD的特征金字塔结构使其检出率得到进一步提升。
2 SNPE简介
SNPE是高通公司专门为运行神经网络设计的处理引擎,可以使神经网络模型运行在GPU上,速率比CPU快4倍。用户在训练生成自己的模型后,利用官方提供的SDK转成指定格式方可运行于GPU上。然而目前SNPE只支持Caffe、TensorFlow、Caffe2三种框架,且仅能加速指定的一些层,当用户模型中出现了支持列表之外的层时,可以利用SNPE提供的用户自定义接口予以完善。
SNPE作为一个为集成AI芯片提供神经网络加速服务的引擎,为实现移动端平台的目标检测提供了便利。
3 移动平台的SSD算法实现及优化
3.1 模型生成及算法移植
本文利用SNPE在骁龙835芯片上实现目标检测的开发工作流程如图2所示。
首先在服务器上基于开源的Caffe框架设计并训练一个SSD检测模型。接下来利用SNPE(版本 1.15.0)提供的SDK接口,将模型的网络配置文件和网络权重文件合并后转换为dlc格式,在SNPE上成功加载并在GPU内核上运行。图中虚线以上部分的工作是可以在移动设备之外调试进行的,虚线以下则只能在移动端设备上完成。

图1:SSD卷积神经网络结构
正如第2节所说,SNPE作为一个问世不久的产品,目前功能尚不完善,还不支持对某些类型层的加速,本文生成的SSD模型中的“detection_out”层便不被支持。为了让模型得以顺利移植,本文在网络中截去了这一层,并在SNPE之外单独实现。“detection_out”层是整个网络的输出层,其层类型为“DetectionOutput”。该层获取三个输入:预选框分类的置信度向量;预选框坐标回归向量;预选框的坐标和回归权值参数。将这三个参数按照式2计算,即可得到真实目标的位置和类别信息,所以想要在网络构架外重新实现该层,也需要同样从网络获得这三个向量。因此我们在网络最后新增一个concat层,连接“mbox_соnf_flаttеn”层和“mbox_loc”层,这样整个模型在SNPE上做完前向之后,便可以得到上述的前两个向量。至于第三个向量预选框的坐标则只和输入图像尺寸以及网络结构相关,所以可以事先确定好,解析真实值时直接调用即可。
3.2 网络模型优化
上小节讨论了如何在移动端设备移植运行目标检测算法,但由于SSD算法本身为服务器端设计,模型的尺寸结构相对于移动端设备而言太大,过于冗余复杂的结构会导致模型体积变大、输出维数变高、运行时间变长等问题。为了使算法得以高效运行,本文对生成的SSD模型分别从基础网络选型和预选框筛选这两个方面作了优化。
3.2.1 基础网络选型
正如第1节所论述,SSD模型结构由两部分组成:基础网络和附加网络。附加网络是SSD的核心所在,实现了其特征金字塔等特性,所以一般其结构不予更改,而基础网络则只是负责提取特征所用,因此可以选用各种经典或新近的卷积神经网络,例如VGG-16、Resnet、Densenet等,基础网络的选择直接影响到了SSD的性能和计算复杂度。本文选用了Mobilenet[9]作为基础网络,顾名思义,该网络设计初衷就是为了能在移动端便捷使用。Mobilenet与一般的卷积神经网络不同,其基本单元是深度级可分离卷积,在相同权值参数数量的情况下,能减少数倍的计算量。自2017年首次发表之后,迄今论文应用量已逾900。

图2:移动平台检测算法开发流程
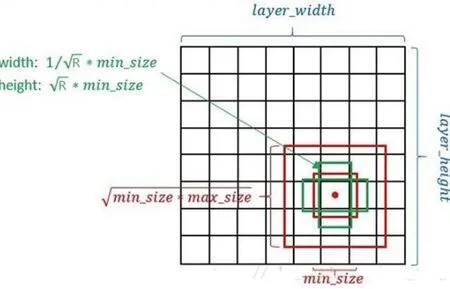
图3:SSD选取预选框的规则
3.2.2 预选框筛选
从式2可以看出,真实目标的位置信息是通过对预选框作坐标偏移得来的,因此预选框设置的合理准确与否直接影响到了最终结果。SSD的特征层生成预选框的规则如图3所示。

图4:地铁客流统计待检图

以本文选用的Mobilenet为例。Mobilenet共计28层,我们利用了其中的6层特征用来目标检测,假设输入图尺寸为300×300,这6层特征层尺寸分别是 19×19、10×10、5×5、3×3、2×2 和 1×1,而除了第一层没有且只有1个外,其余5层都有且为2。由式3可计算得预选框数目为(1083+600+150+54+24+6),共1917个。图4为地铁站客流统计项目的一张待检图,可以看出该场景人群比较密集,人与人之间存在大幅重叠情况,因此只能通过检测人头来确定流量。
本文中,算法的主要目的是检测站台内出现的人头数目,因此对于待检目标的尺寸和位置已经有了先验知识。我们知道人头在整幅图像中所占比例偏小,大多数近似正方形状,且不会出现在图中左上方划线的区域,同时考虑到特征层越深,负责检出越大目标的原则,本文对SSD的后5层预选框作了削减,删去了所有同时也删去了中心点位于划线区域里的预选框,预选框数目从1917变为了922,约减少为原本的一半。经过筛取之后,模型的concat层的输出维数大大降低,后续对预选框的选择、调整和非极大值抑制等处理也减少了资源开销,同时由于对预选框的位置做了限制,不应该出现目标的地方产生虚警的概率便大大降低,这些都为模型能在移动端平台快速高效准确的运行产生积极影响。
4 算法效果
4.1 运行环境
本文算法运行于骁龙835芯片,详细配置信息如下:

4.2 检测指标
测试数据集为200张类似于图4的地铁站台监控图。在上述测试条件下,算法平均每帧耗时约45ms,而mAP(mean Average Precision)达到了0.723。
5 结论
相比较于传统经典算法,基于深度学习的目标检测算法在精确性、鲁棒性、泛化性等方面更有优势,但深度学习算法往往需要运行在计算能力强大的服务器上,考虑到实际工程项目中对场地、资金预算、功耗的苛刻要求,深度学习目标检测算法反而应用场景不多。本文实现了在移动端平台的深度学习目标检测算法,经数据集测试每帧处理速度约45ms,mAP为0.723,满足一般实时性和精确性要求,对相关领域方面的研究具有一定启发意义。
